所以我從字典中創建了一個資料框來執行時間序列練習。當我創建資料框(我在 Google Colab 中這樣做)時,單元格運行正常。但是當我這樣做時full_df.head()。我得到StopIteration錯誤。有誰知道為什么會這樣?
這就是我所擁有的:
df = pd.read_csv('all_stocks_5yr.csv', usecols=["close", "Name"])
gp = df.groupby("Name")
my_dict = {}
for record in gp:
if record[0] in my_dict:
my_dict[record[0]].append(record)
else:
my_dict[record[0]] = [record]
full_df = pd.DataFrame.from_dict(my_dict, orient='index')
full_df.head() #This is where I get the error.
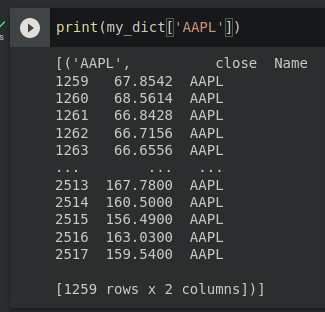
uj5u.com熱心網友回復:
它不起作用,因為您試圖將元組分配為單列。
對結果的回圈.groupby生成一對(key, sub_df),其中key是此組名。這sub_df是一個包含所有列和與給定關聯的所有值的 DataFrame key。您的回圈為key字典中的每個創建一個單元素串列(其中 element 是提到的元組)。
這個字典將代表一個只有一列的資料幀(因為字典中的每個條目都是一個單元素串列),每行包含字串和資料幀的元組。Pandas 不知道如何將其轉換為正確的 DataFrame。
如果我正確理解意圖,那么您希望在索引中包含名稱并在每一行中關閉值。為此,最好使用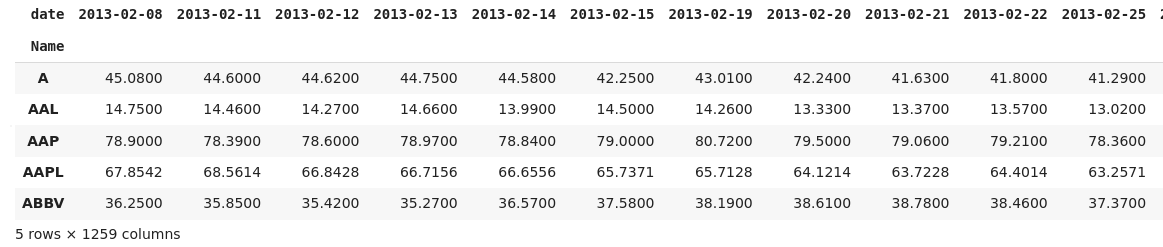
如果您無權訪問該date列,則可以使用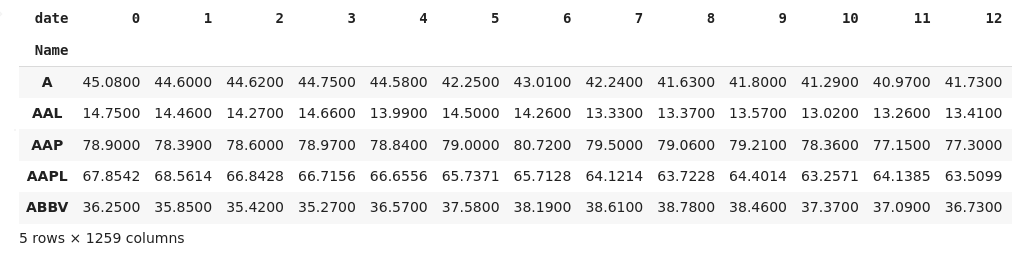
編輯:
如果你想使用字典,那么你需要小心你把什么作為一個值。由于df.groupby('Name')元組的回傳可迭代,那么我們可以將其解包為key, group. 這group也是一個 DataFrame,因此我們需要選擇列(在本例中為“關閉”)。我們需要將選定的列轉換為 Numpy 陣列(或重置索引),否則groupPandas 將使用該索引作為新 DataFrame 中的列名。代碼示例:
my_dict = {key: group['close'].to_numpy() for key, group in df.groupby('Name')}
full_df = pd.DataFrame.from_dict(my_dict, orient='index')
full_df.head()
回傳:
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/366693.html
上一篇:滾動視窗對資料幀沒有影響
下一篇:通過for回圈創建嵌套字典