我無法在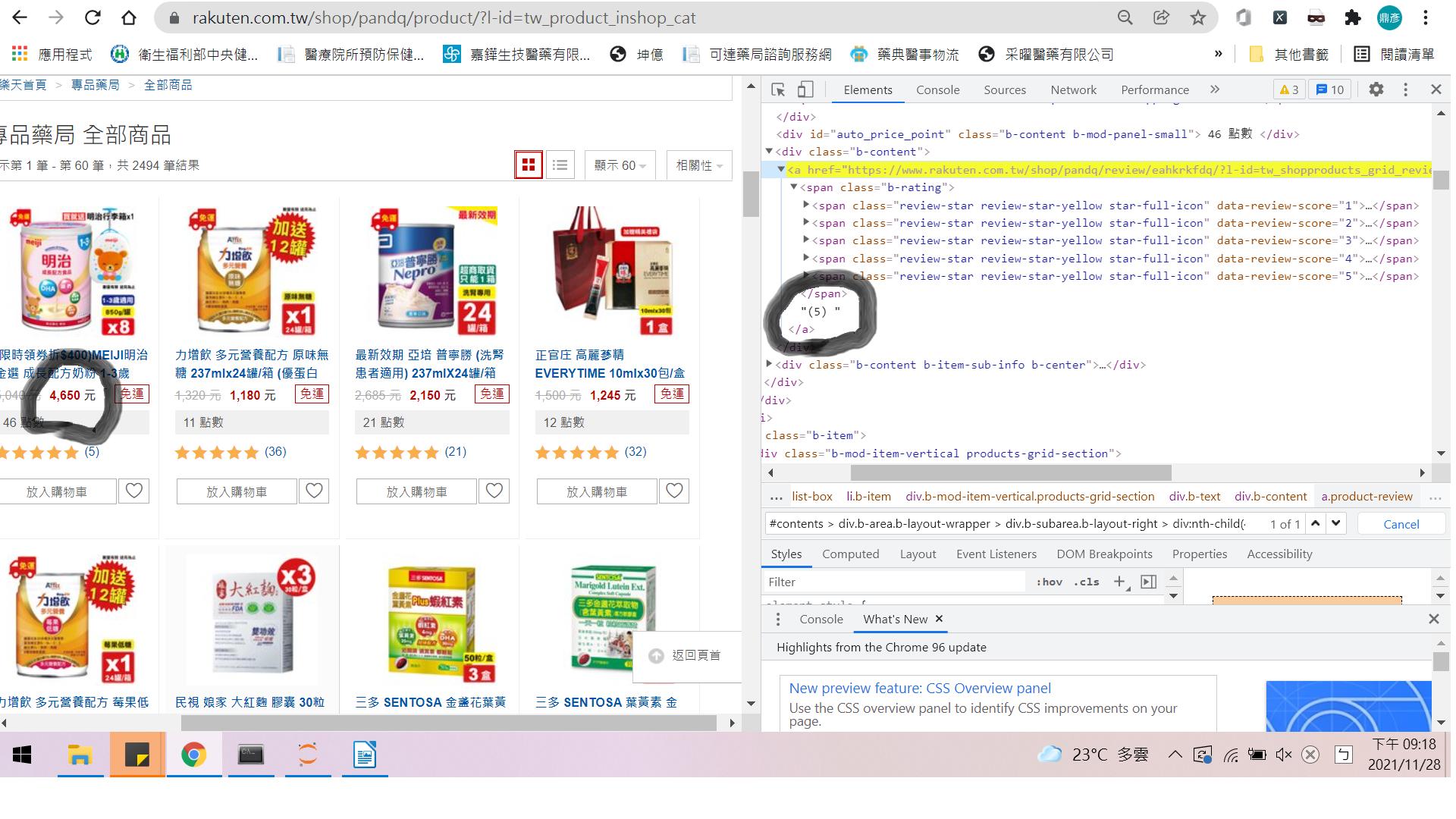
import time
import requests
!pip install beautifulsoup4
import bs4
!pip install lxml
from bs4 import BeautifulSoup
import pandas as pd
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36'}
products =[]
for i in range(1,2): # Iterate from page 1 to the last page
url = "https://www.rakuten.com.tw/shop/pandq/product/?l-id=tw_shop_inshop_cat&p={}".format(i)
r = requests.get(url, headers = headers)
soup = bs4.BeautifulSoup(r.text,"lxml")
Soup = soup.find_all("div",class_='b-mod-item-vertical products-grid-section')
for product in Soup:
productcount = product.find_all("div",class_='b-content')
print(productcount)
uj5u.com熱心網友回復:
發生什么了?
元素的選擇不是那么正確,所以你不會得到預期的結果。
怎么修?
由于您的螢屏截圖顯示了不同的內容price/rating我將專注于評級。
首先選擇所有專案:
soup.select('.b-item')
然后迭代結果集并選擇<a>包含 的rating:
item.select_one('.product-review')
去掉所有特殊字符:
item.select_one('.product-review').get_text(strip=True).strip('(|)')
例子
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'}
r = requests.get('https://www.rakuten.com.tw/shop/pandq/product/?l-id=tw_shop_inshop_cat&p=1',headers=headers)
soup = BeautifulSoup(r.content, 'lxml')
for item in soup.select('.b-item'):
rating = item.select_one('.product-review').get_text(strip=True).strip('(|)') if item.select_one('.product-review') else None
print(rating)
輸出
5
36
21
32
8
...
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/369844.html
上一篇:在Class范圍內考慮什么?