幾天前我在這里問了一個類似的問題,這很有幫助!我想要構建的一個新挑戰是進一步開發正則運算式模式以在此迭代中查找特定格式,我認為我已經使用正則運算式 101 來構建/測驗正則運算式代碼解決了這個問題,但是當在 Python 中應用時收到“模式不包含組” '。下面是一個測驗 df,以及通過 StackOverflow 提供的僅適用于數字的結果應該是什么樣的影像/代碼。
df = pd.DataFrame([["{1} | | Had a Greeter welcome clients {1.0} | | Take measures to ensure a safe and organized distribution {1.000} | | Protected confidentiality of clients (on social media, pictures, in conversation, own congregation members receiving assistance, etc.)",
"{1.00} | | Chairs for clients to sit in while waiting {1.0000} | | Take measures to ensure a safe and organized distribution"],
["{1 } | Financial literacy/budgeting {1 } | | Monetary/Bill Support {1} | | Mental Health Services/Counseling",
"{1}| | Clothing Assistance {1 } | | Healthcare {1} | | Mental Health Services/Counseling {1} | | Spiritual Support {1} | | Job Skills Training"]
] , columns = ['CF1', 'CF2'])
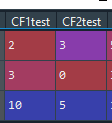
這是僅適用于數字的迭代代碼。我用我的新正則運算式模式更改了模式搜索,但它不起作用。
原始代碼: (df.stack().str.extractall('(\d )')[0] .groupby(level=[0,1]).sum().unstack())
新代碼(無法識別模式): (df.stack().str.extractall(r'(?<=\{)[\d \.\ ] (?=\})')[0].astype(int) .groupby(level=[0,1]).sum().unstack())
**在測驗 df 中,您將看到我只想捕獲“{}”之間的數字,并且在我想要捕獲和求和的數字后面有小數和空格的混合。新模式在應用程式中不起作用,因此任何幫助都會很棒!**
uj5u.com熱心網友回復:
您的(?<=\{)[\d \.\ ] (?=\})正則運算式不包含捕獲組,而Series.str.extractall需要至少一個捕獲組來輸出值。
你需要使用
(df.stack().str.extractall(r'\{\s*(\d (?:\.\d )?)\s*}')[0].astype(float) .groupby(level=[0,1]).sum().unstack())
輸出:
CF1 CF2
0 3.0 2.0
1 3.0 5.0
在\{\s*(\d (?:\.\d )?)\s*}正則運算式匹配
\{- 一個{字符\s*- 零個或多個空格(\d (?:\.\d )?)- 第 1 組(注意該組捕獲的值將是該extractall方法的輸出,它至少需要一個捕獲組):一位或多位數字,然后可選出現 a.和一位或多位數字\s*- 零個或多個空格}- 一個}字符。
請參閱正則運算式演示。
uj5u.com熱心網友回復:
您可以使用'\{([\d.] )\}':
(df.stack().str.extractall(r'\{([\d.] )\}')[0]
.astype(float).groupby(level=[0,1]).sum().unstack())
輸出:
CF1 CF2
0 3.0 2.0
1 1.0 4.0
僅作為整數:
(df.stack().str.extractall(r'\{(\d )(?:\.\d )?\}')[0]
.astype(int).groupby(level=[0,1]).sum().unstack())
輸出:
CF1 CF2
0 3 2
1 1 4
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/372046.html
下一篇:將資料從文本檔案轉換為元組