我有一個 CSV 檔案,其中包含來自世界不同地區的潮汐上升幅度資料,我撰寫了一個代碼來過濾從該 CSV 檔案中讀取的資料,代碼如下所示:
import pandas as pd
import numpy as np
df1=pd.read_csv("Tide Prediction.csv")
df1.columns = df1.iloc[0] #To replace the header with the first row
df1 = df1[1:]
df2=df1.rename(columns={df1.columns[3]: "location"})
dict = {'UTC': 'time',
'degrees_east': 'longitude',
'degress_west': 'latitude'}
df2['degrees_north'] = df2['degrees_north'].astype(float, errors = 'raise')
df2['degrees_east'] = df2['degrees_east'].astype(float, errors = 'raise')
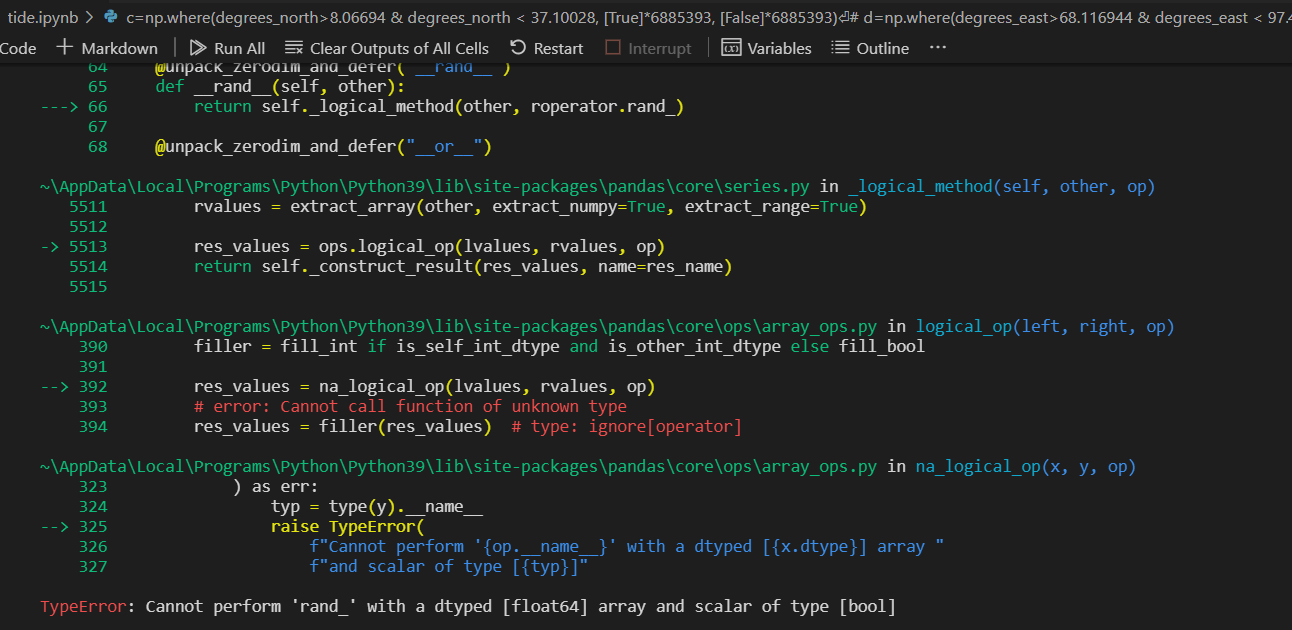
c=np.where(degrees_north>8.06694 & degrees_north < 37.10028, [True]*6885393, [False]*6885393)
但這給了我一個錯誤
uj5u.com熱心網友回復:
這里np.where沒有必要,因為如果只比較,相同的輸出,只需要添加()條件:
c=(degrees_north>8.06694) & (degrees_north < 37.10028)
c=np.where((degrees_north>8.06694) & (degrees_north < 37.10028), True, False)
uj5u.com熱心網友回復:
您可以使用between:
假設以下資料框
df = pd.DataFrame({'degrees_north': [8, 9, 37, 38]})
print(df)
# Output:
degrees_north
0 8
1 9
2 37
3 38
>>> df['degrees_north'].between(8.06694, 37.10028, inclusive='neither')
0 False
1 True
2 True
3 False
Name: degrees_north, dtype: bool
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/377532.html