我在電子表格中有數千個化學式的串列,我想計算每個化學式中每個化學元素出現的次數。這里給出了一些例子:
- CH 3 NO 3
- CSe 2
- C 2 Cl 2
- C 2 Cl 2 O 2
- C 4 H 6 COOH
- (C 6 H 5 ) 2 P(CH 2 ) 6 P(C 6 H 5 ) 2
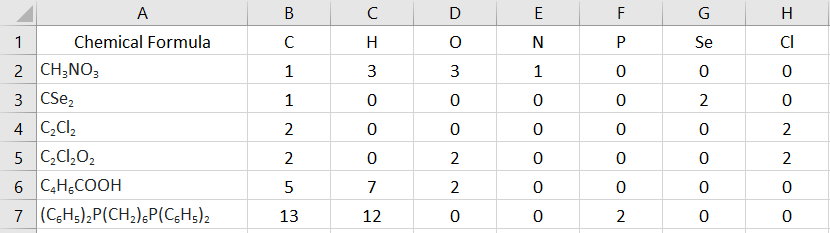
我發現@PEH(
Private RegEx As RegExp
Function CountElements(ChemFormulaRange As Variant, ElementRange As Variant) As Variant
'define variables
Dim RetValRange() As Long
Dim RetVal As Long
Dim ChemFormula As String
Dim npoints As Long
Dim i As Long
Dim mpoints As Long
Dim j As Long
' Connvert input ranges to variant arrays
If TypeName(ChemFormulaRange) = "Range" Then ChemFormulaRange = ChemFormulaRange.Value
If TypeName(ElementRange) = "Range" Then ElementRange = ElementRange.Value
'parameter
npoints = UBound(ChemFormulaRange, 1) - LBound(ChemFormulaRange, 1) 1
mpoints = UBound(ElementRange, 2) - LBound(ElementRange, 2) 1
'dimension array
ReDim RetValRange(1 To npoints, 1 To mpoints)
If RegEx Is Nothing Then
Set RegEx = New RegExp
' apply the properties
End If
'calculate all values
For j = 1 To mpoints
Element = ElementRange(1, j)
For i = 1 To npoints
RetVal = 0
ChemFormula = ChemFormulaRange(i, 1)
Call ChemRegex(ChemFormula, Element, RetVal, RegEx)
RetValRange(i, j) = RetVal
Next i
Next j
'output answer
CountElements = RetValRange
End Function
Private Sub ChemRegex(ChemFormula, Element, RetVal, RegEx)
'ChemRegex created by PEH (CC BY-SA 4.0) https://stackoverflow.com/a/46091904/17194644
With RegEx
.Global = True
.MultiLine = True
.IgnoreCase = False
End With
'first pattern matches every element once
RegEx.Pattern = "([A][cglmrstu]|[B][aehikr]?|[C][adeflmnorsu]?|[D][bsy]|[E][rsu]|[F][elmr]?|[G][ade]|[H][efgos]?|[I][nr]?|[K][r]?|[L][airuv]|[M][cdgnot]|[N][abdehiop]?|[O][gs]?|[P][abdmortu]?|[R][abefghnu]|[S][bcegimnr]?|[T][abcehilms]|[U]|[V]|[W]|[X][e]|[Y][b]?|[Z][nr])([0-9]*)"
Dim Matches As MatchCollection
Set Matches = RegEx.Execute(ChemFormula)
Dim m As Match
For Each m In Matches
If m.SubMatches(0) = Element Then
RetVal = RetVal IIf(Not m.SubMatches(1) = vbNullString, m.SubMatches(1), 1)
End If
Next m
End Sub
uj5u.com熱心網友回復:
看起來您像我上次建議的那樣修改了代碼以重用 RegExp 物件,實際上我希望這能顯著提高性能。但是,我應該更好地解釋如何實作,但請參閱下面的示例。
在示例中,我還采用了您的第二個 RegExp 模式,但重新設計了其余的模式。這個例子對我來說似乎對你的樣本資料有用,但這就是我測驗過的!
Option Explicit
Private regEx As RegExp
Private regEx2 As RegExp
Sub Test()
' formulas in A2:A7 and elements in B1:H1 (see OP's screenshot), return results in B2:H7
Range("B2:H7").Value = CountElements(Range("A2:A7").Value, Range("B1:H1"))
End Sub
Function CountElements(ChemFormulaRange As Variant, ElementRange As Variant) As Variant
Dim RetValRange() As Long
Dim RetVal As Long
Dim ChemFormula As String
Dim i As Long, j As Long
Dim mpoints As Long, npoints As Long
Dim Element As String
If regEx Is Nothing Then
Set regEx = New RegExp
With regEx
.Global = True
'.MultiLine = True ' ? only if working with multilines
.IgnoreCase = False
'first pattern matches every element once
.Pattern = "([A][cglmrstu]|[B][aehikr]?|[C][adeflmnorsu]?|[D][bsy]|[E][rsu]|[F][elmr]?|[G][ade]|[H][efgos]?|[I][nr]?|[K][r]?|[L][airuv]|[M][cdgnot]|[N][abdehiop]?|[O][gs]?|[P][abdmortu]?|[R][abefghnu]|[S][bcegimnr]?|[T][abcehilms]|[U]|[V]|[W]|[X][e]|[Y][b]?|[Z][nr])([0-9]*)"
End With
Set regEx2 = New RegExp
With regEx2
.Global = True
'.MultiLine = True ?
.IgnoreCase = False
'second patternd finds parenthesis and multiplies elements within
.Pattern = "(\((. ?)\)([0-9]) ) ?"
End With
End If
' Convert input ranges to variant arrays
If TypeName(ChemFormulaRange) = "Range" Then ChemFormulaRange = ChemFormulaRange.Value
If TypeName(ElementRange) = "Range" Then ElementRange = ElementRange.Value
'parameter
npoints = UBound(ChemFormulaRange, 1) - LBound(ChemFormulaRange, 1) 1
mpoints = UBound(ElementRange, 2) - LBound(ElementRange, 2) 1
'dimension arrays
ReDim RetValRange(1 To npoints, 1 To mpoints)
'calculate all values
For i = 1 To npoints
ChemFormula = ChemFormulaRange(i, 1)
For j = 1 To mpoints
RetVal = 0
Element = ElementRange(1, j)
Call ChemRegex(ChemFormula, Element, RetVal)
RetValRange(i, j) = RetVal
Next
Next
'output answer
CountElements = RetValRange
' Set regEx = Nothing: Set regEx2 = Nothing
End Function
Private Sub ChemRegex(ChemFormula, Element, RetVal)
Dim Matches As MatchCollection, Matches2 As MatchCollection
Dim m As Match, m2 As Match
Set Matches = regEx.Execute(ChemFormula)
For Each m In Matches
If m.SubMatches(0) = Element Then
RetVal = RetVal IIf(Not m.SubMatches(1) = vbNullString, m.SubMatches(1), 1)
End If
Next m
If InStr(1, ChemFormula, "(") Then ' if the formula includes elements within parentheses
Set Matches2 = regEx2.Execute(ChemFormula)
For Each m2 In Matches2
Set Matches = regEx.Execute(m2.Value)
For Each m In Matches
If m.SubMatches(0) = Element Then
If m.SubMatches(1) = vbNullString Then
RetVal = RetVal m2.SubMatches(2) - 1
Else
RetVal = RetVal m.SubMatches(1) * (m2.SubMatches(2) - 1)
End If
End If
Next
Next m2
End If
End Sub
這當然可以通過按照 CDP1802 的建議在一個 RegExp 執行中測驗所有元素來進一步改進,但我會把它留給你!
uj5u.com熱心網友回復:
通過在一次正則運算式執行中提取所有元素而不是一次只提取一個元素,您可能會獲得性能改進。
Option Explicit
Sub Demo()
Dim lastrow As Long, lastcol As Long
Dim c As Long, r As Long, d As Object
Dim f As String, el As String, ar
Set d = CreateObject("Scripting.Dictionary")
With Sheet1
lastrow = .Cells(.Rows.Count, "A").End(xlUp).Row
lastcol = .Cells(1, .Columns.Count).End(xlToLeft).Column
ar = .Cells(1, 1).Resize(lastrow, lastcol)
For r = 2 To lastrow
f = ar(r, 1)
Call parse(d, f)
For c = 2 To lastcol
el = ar(1, c)
If d.exists(el) Then
ar(r, c) = d(el)
End If
Next
d.RemoveAll
Next
.Cells(1, 1).Resize(lastrow, lastcol) = ar
End With
MsgBox "Done"
End Sub
Sub parse(ByRef dict, s As String)
Dim regex As Object
Set regex = CreateObject("VBScript.RegExp")
With regex
.Global = False
.Pattern = "[(]([^)] )[)](\d )"
End With
' expand bracket into multiple entries
Dim m, matches, sm, n As Long, el As String
Do While regex.test(s)
Set m = regex.Execute(s)
For n = 1 To m(0).submatches(1)
s = s & " " & m(0).submatches(0)
Next
s = regex.Replace(s, "")
Loop
' count elements
regex.Pattern = "(" & Symbols & ")([0-9]*)"
regex.Global = True
If regex.test(s) Then
Set matches = regex.Execute(s)
For Each m In matches
el = m.submatches(0)
n = Val(m.submatches(1))
If n = 0 Then n = 1
dict(el) = dict(el) n
Next
End If
End Sub
Function Symbols() As String
Symbols = "A[cglmrstu]|" & _
"B[aehikr]?|" & _
"C[adeflmnorsu]?|" & _
"D[bsy]|" & _
"E[rsu]|" & _
"F[elmr]?|" & _
"G[ade]|" & _
"H[efgos]?|" & _
"I[nr]?|" & _
"K[r]?|" & _
"L[airuv]|" & _
"M[cdgnot]|" & _
"N[abdehiop]?|" & _
"O[gs]?|" & _
"P[abdmortu]?|" & _
"R[abefghnu]|" & _
"S[bcegimnr]?|" & _
"T[abcehilms]|" & _
"[UVW]|" & _
"X[e]|" & _
"Y[b]?|" & _
"Z[nr]"
End Function
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/380749.html