我想將多頭 DataFrame 保存為 Excel 檔案。以下是示例代碼:
import pandas as pd
import numpy as np
header = pd.MultiIndex.from_product([['location1','location2'],
['S1','S2','S3']],
names=['loc','S'])
df = pd.DataFrame(np.random.randn(5, 6),
index=['a','b','c','d','e'],
columns=header)
df.to_excel('result.xlsx')
excel檔案中有兩個問題,如下所示:
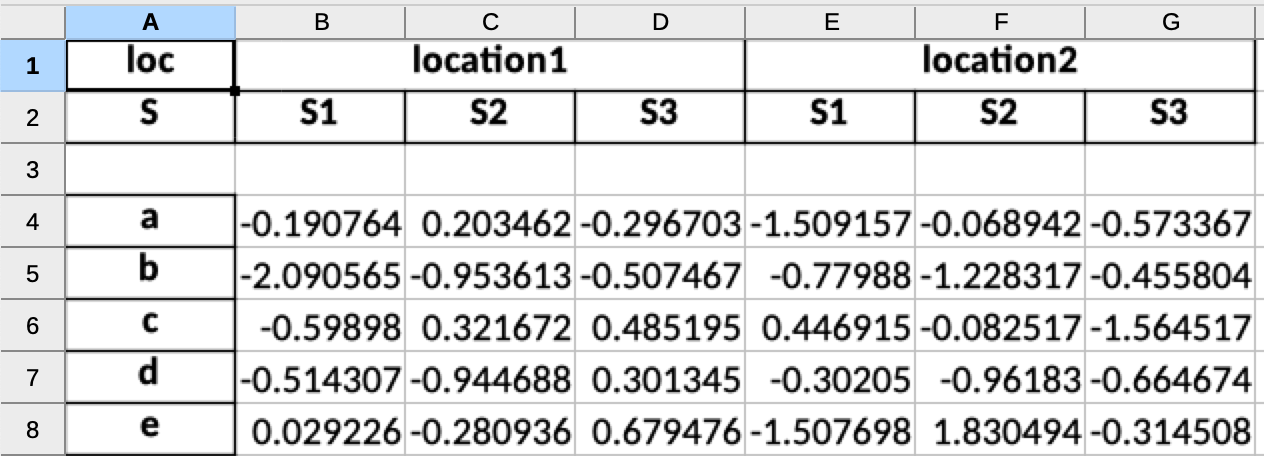
問題 1:
標題下有一個空行。請讓我知道如何避免 Pandas 在 Excel 檔案中寫入/插入空行。
問題 2:
我想保存沒有索引的 DataFrame。但是,當我設定時index=False,出現以下錯誤:
df.to_excel('result.xlsx', index=False)
錯誤:
NotImplementedError: Writing to Excel with MultiIndex columns and no index ('index'=False) is not yet implemented.
uj5u.com熱心網友回復:
您可以創建 2 個資料幀 - 只有標題和默認標題,并使用startrow引數將兩者寫入同一張表:
header = df.columns.to_frame(index=False)
header.loc[header['loc'].duplicated(), 'loc'] = ''
header = header.T
print (header)
0 1 2 3 4 5
loc location1 location2
S S1 S2 S3 S1 S2 S3
df1 = df.set_axis(range(len(df.columns)), axis=1)
print (df1)
0 1 2 3 4 5
a -1.603958 1.067986 0.474493 -0.352657 -2.198830 -2.028590
b -0.989817 -0.621200 0.010686 -0.248616 1.121244 0.727779
c -0.851071 -0.593429 -1.398475 0.281235 -0.261898 -0.568850
d 1.414492 -1.309289 -0.581249 -0.718679 -0.307876 0.535318
e -2.108857 -1.870788 1.079796 0.478511 0.613011 -0.441136
with pd.ExcelWriter('output.xlsx') as writer:
header.to_excel(writer, sheet_name='Sheet_name_1', header=False, index=False)
df1.to_excel(writer, sheet_name='Sheet_name_1', header=False, index=False, startrow=2)
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/389516.html
上一篇:從列中提取某些單詞
下一篇:如何按列對資料框進行分組?