我對 python 和 pandas 很陌生,我想按某些列對現有的兩個資料框進行排序,并創建第三個資料框,其中僅包含容差內的值匹配。換句話說,我有 df1 和 df2,我希望 df3 包含 df2 的行和列,這些行和列在 df1 中的值的容差范圍內:
兩個資料框:
df1=pd.DataFrame([[0.221,2.233,7.84554,10.222],[0.222,2.000,7.8666,10.000],
[0.220,2.230,7.8500,10.005]],columns=('rt','mz','mz2','abundance'))
[資料框 1]
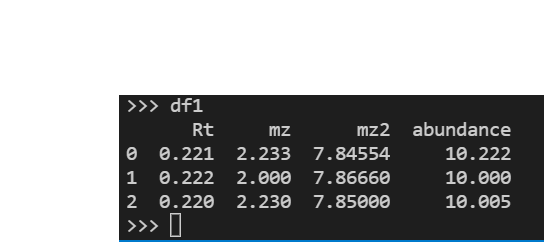
df2=pd.DataFrame([[0.219,2.233,7.84500,10.221],[0.220,7.8669,10.003],[0.229,2.238,7.8508,10.009]],columns=('rt','mz','mz2','abundance'))
[資料框 2]
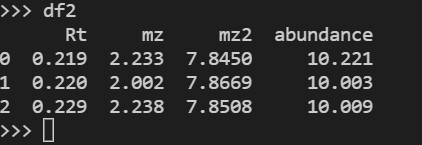
預期輸出:
df3=pd.DataFrame([[0.219,2.233,7.84500,10.221],[0.220,2.002,7.8669,10.003]],columns=('Rt','mz','mz2','abundance'))
[資料框 3]
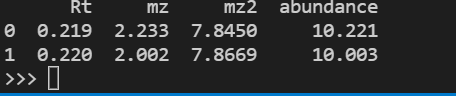
我嘗試過 forloops 和過濾器,但由于我是新手,沒有什么對我有用。但在這里,我正在嘗試什么:
import pandas as pd
import numpy as np
p=[]
d=np.array(p)
#print(d.dtype)
def count(df2, l, r):
l=[(df1['Rt']-0.001)]
r=[(df1['Rt'] 0.001)]
for x in df2['Rt']:
# condition check
if x>= l and x<= r:
print(x)
d.append(x)
其中 p 和 d 是相應的資料框和將填充的陣列(如果需要制作陣列?)。我敢打賭,問題在于函式不應該包含 forloop。
理想情況下,這可以使用另一個資料幀的 180 列值對資料幀的約 13,000 行進行排序。
先感謝您!
uj5u.com熱心網友回復:
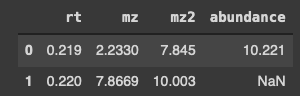
這是您要找的嗎?:
min = df1.rt.min()-0.001
max = df1.rt.max() 0.001
df3 = df2[(df2.rt >= min) & (df2.rt <= max)]
>>> df3
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/400542.html