我正在嘗試格式化一個包含 40 個不同年齡-種族-性別階層的表格,以輸入到 R-INLA 中,并注意到包含所有階層很重要(即使它們不在一個縣中)。這些應該是零。但是,此時我的表僅包含非空的分層記錄。我可以通過查看我的地層變數并找到系列 1 到 40 中的中斷(在下圖中用紅色 x 標記)來確定每個縣缺少地層的地方。
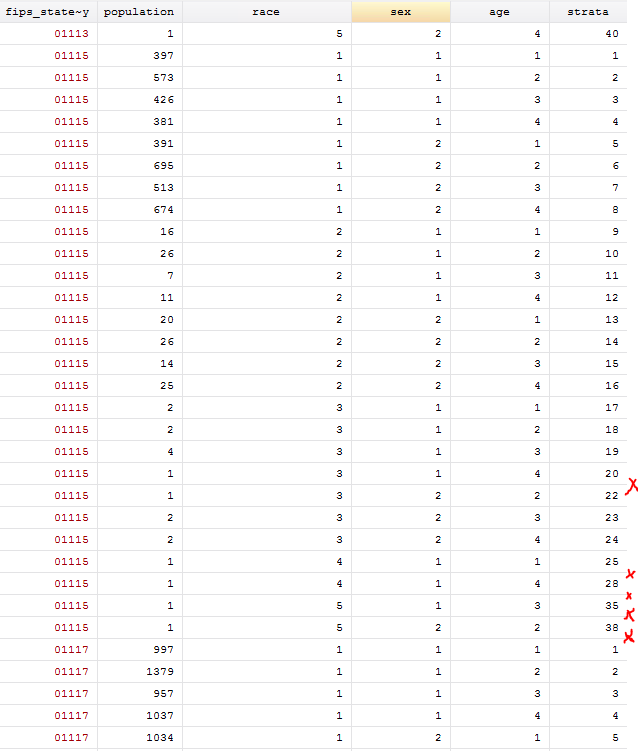
在這些地方(用紅色 x 標記)我需要添加缺失的行并填寫相應的縣代碼、階層代碼、人口=0,以及階層的正確對應的種族、性別、年齡代碼。
如果我能找到一種方法,在影像中帶有紅色 X 的空間中添加一個空行,并將地層代碼(和縣代碼)正確分配給這些空/缺失的行,我就可以填充其余的行使用以下代碼的值:
重新編碼種族 = 1 & 性別 = 1 & 年齡 =4 如果地層 = 4 ...等
我想知道是否有一種方法可以使用if考慮到每個縣代碼應該有四十層這一事實的陳述句來添加缺失的行。如果這也能填充正確的縣代碼和地層代碼,那將是理想的!
Dataex 樣本資料:
* Example generated by -dataex-. To install: ssc install dataex
clear
input float OID str5 fips_statecounty double population byte(race sex age) float strata
1 "" 672 1 1 1 1
2 "" 1048 1 1 2 2
3 "" 883 1 1 3 3
4 "" 1129 1 1 4 4
5 "" 574 1 2 1 5
6 "" 986 1 2 2 6
7 "" 899 1 2 3 7
8 "" 1820 1 2 4 8
9 "" 96 2 1 1 9
10 "" 142 2 1 2 10
11 "" 81 2 1 3 11
12 "" 99 2 1 4 12
13 "" 71 2 2 1 13
14 "" 125 2 2 2 14
15 "" 103 2 2 3 15
16 "" 162 2 2 4 16
17 "" 31 3 1 1 17
18 "" 32 3 1 2 18
19 "" 18 3 1 3 19
20 "" 31 3 1 4 20
21 "" 22 3 2 1 21
22 "" 28 3 2 2 22
23 "" 28 3 2 3 23
24 "" 44 3 2 4 24
25 "" 20 4 1 1 25
26 "" 24 4 1 2 26
27 "" 21 4 1 3 27
28 "" 43 4 1 4 28
29 "" 19 4 2 1 29
30 "" 26 4 2 2 30
31 "" 24 4 2 3 31
32 "" 58 4 2 4 32
33 "" 6 5 1 1 33
34 "" 11 5 1 2 34
35 "" 13 5 1 3 35
36 "" 7 5 1 4 36
37 "" 7 5 2 1 37
38 "" 9 5 2 2 38
39 "" 10 5 2 3 39
40 "" 11 5 2 4 40
41 "01001" 239 1 1 1 1
42 "01001" 464 1 1 2 2
43 "01001" 314 1 1 3 3
44 "01001" 232 1 1 4 4
45 "01001" 284 1 2 1 5
46 "01001" 580 1 2 2 6
47 "01001" 392 1 2 3 7
48 "01001" 440 1 2 4 8
49 "01001" 41 2 1 1 9
50 "01001" 38 2 1 2 10
51 "01001" 23 2 1 3 11
52 "01001" 26 2 1 4 12
53 "01001" 34 2 2 1 13
54 "01001" 52 2 2 2 14
55 "01001" 40 2 2 3 15
56 "01001" 50 2 2 4 16
57 "01001" 4 3 1 1 17
58 "01001" 2 3 1 2 18
59 "01001" 3 3 1 3 19
60 "01001" 6 3 2 1 21
61 "01001" 4 3 2 2 22
62 "01001" 6 3 2 3 23
63 "01001" 4 3 2 4 24
64 "01001" 1 4 1 4 28
65 "01003" 1424 1 1 1 1
66 "01003" 2415 1 1 2 2
67 "01003" 1680 1 1 3 3
68 "01003" 1823 1 1 4 4
69 "01003" 1545 1 2 1 5
70 "01003" 2592 1 2 2 6
71 "01003" 1916 1 2 3 7
72 "01003" 2527 1 2 4 8
73 "01003" 68 2 1 1 9
74 "01003" 82 2 1 2 10
75 "01003" 52 2 1 3 11
76 "01003" 54 2 1 4 12
77 "01003" 72 2 2 1 13
78 "01003" 129 2 2 2 14
79 "01003" 81 2 2 3 15
80 "01003" 106 2 2 4 16
81 "01003" 10 3 1 1 17
82 "01003" 14 3 1 2 18
83 "01003" 8 3 1 3 19
84 "01003" 4 3 1 4 20
85 "01003" 8 3 2 1 21
86 "01003" 14 3 2 2 22
87 "01003" 17 3 2 3 23
88 "01003" 10 3 2 4 24
89 "01003" 4 4 1 1 25
90 "01003" 1 4 1 3 27
91 "01003" 2 4 1 4 28
92 "01003" 2 4 2 1 29
93 "01003" 3 4 2 2 30
94 "01003" 4 4 2 3 31
95 "01003" 10 4 2 4 32
96 "01003" 5 5 1 1 33
97 "01003" 4 5 1 2 34
98 "01003" 3 5 1 3 35
99 "01003" 5 5 1 4 36
100 "01003" 5 5 2 2 38
end
label values race race
label values sex sex
uj5u.com熱心網友回復:
我對你上一個問題的回答
嵌套 for 回圈:錯誤變數已定義
詳細介紹了如何創建包含所有層的最小資料集。因此,您應該只merge使用您的主資料集,并用您的其他軟體期望的任何內容替換缺失層上的缺失,看起來為零。
此時最明顯的復雜性是您需要考慮一個county變數。我看不到有關您的資料集中有多少個縣的任何資訊,這可能會影響實用性。您應該能夠將準備作業分解為:首先,準備一個僅包含識別符號的最小縣資料集;然后merge是完整的地層資料集。
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/408131.html
標籤: