我正在嘗試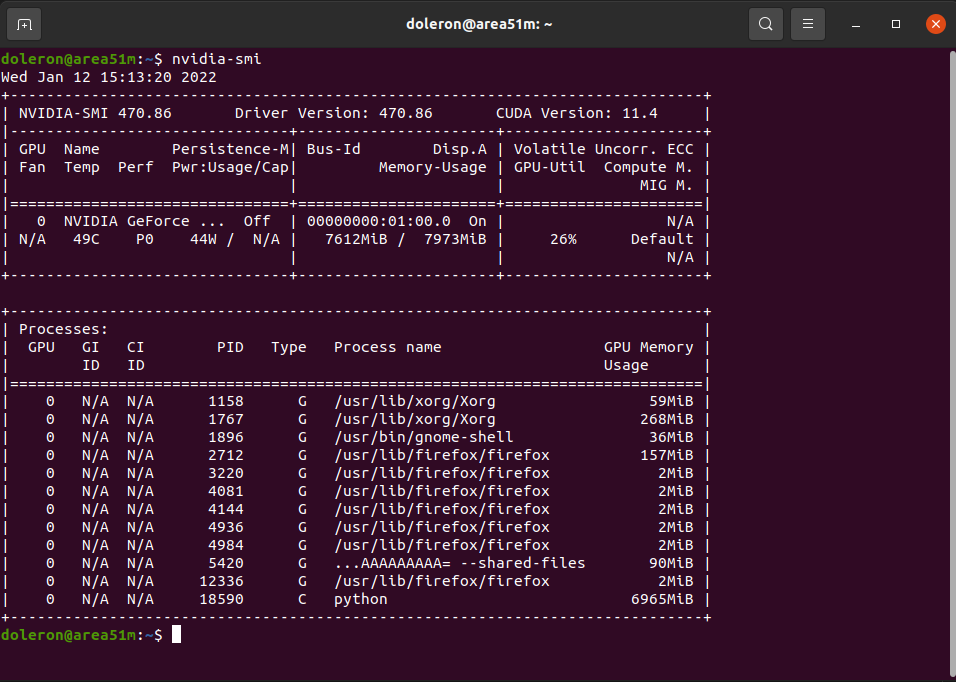
在沒有快取的情況下訓練期間的 GPU 使用情況:
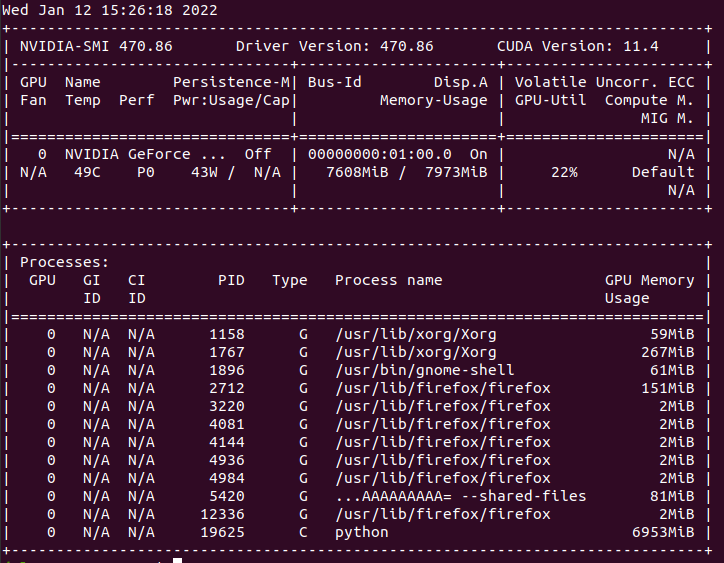
使用快取進行訓練期間的系統統計資訊(記憶體、CPU 等):
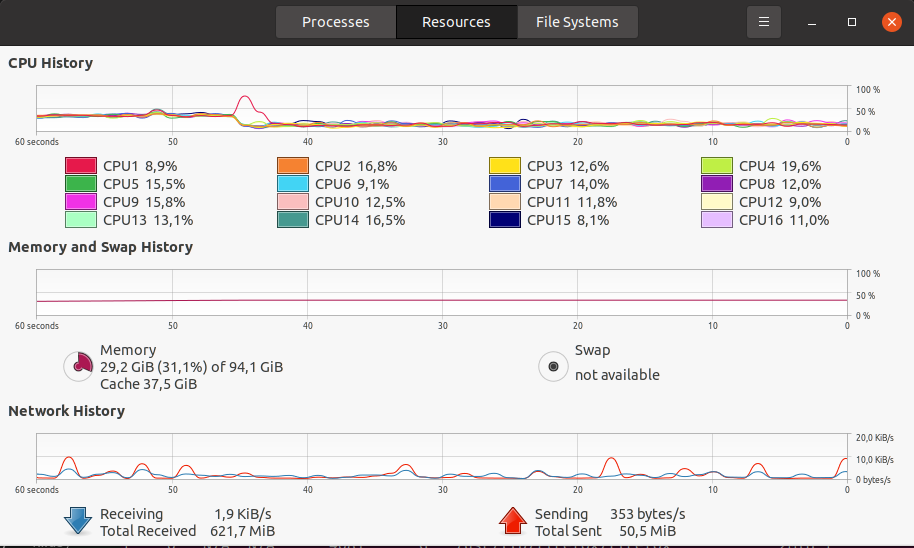
無快取訓練期間的系統統計資訊(記憶體、CPU 等):
uj5u.com熱心網友回復:
只是使用 Google Colab 的一個小觀察。根據檔案:
注意:要最終確定快取,必須對輸入資料集進行整體迭代。否則,后續迭代將不會使用快取資料。
和
注意:快取將在資料集的每次迭代期間產生完全相同的元素。如果您希望隨機化迭代順序,請確保在呼叫快取后呼叫 shuffle。
在事先使用快取和迭代資料集時,我確實注意到了一些差異。這是一個例子。
準備資料:
import random
import struct
import tensorflow as tf
import numpy as np
RAW_N = 2 20*20 1
bytess = random.sample(range(1, 5000), RAW_N*4)
with open('mydata.bin', 'wb') as f:
f.write(struct.pack('1612i', *bytess))
def decode_and_prepare(register):
register = tf.io.decode_raw(register, out_type=tf.float32)
inputs = register[2:402]
label = tf.random.uniform(()) register[402:]
return inputs, label
raw_dataset = tf.data.FixedLengthRecordDataset(filenames=['/content/mydata.bin']*7000, record_bytes=RAW_N*4)
raw_dataset = raw_dataset.map(decode_and_prepare)
在沒有快取和事先迭代的情況下訓練模型:
total_data_entries = len(list(raw_dataset.map(lambda x, y: (x, y))))
train_ds = raw_dataset.shuffle(buffer_size=total_data_entries).batch(32).prefetch(tf.data.AUTOTUNE)
inputs = tf.keras.layers.Input((400,))
x = tf.keras.layers.Dense(200, activation='relu', kernel_initializer='normal')(inputs)
x = tf.keras.layers.Dense(100, activation='relu', kernel_initializer='normal')(x)
outputs = tf.keras.layers.Dense(1, kernel_initializer='normal')(x)
model = tf.keras.Model(inputs, outputs)
model.compile(optimizer='adam', loss='mse')
model.fit(train_ds, epochs=5)
Epoch 1/5
875/875 [==============================] - 4s 3ms/step - loss: 0.1425
Epoch 2/5
875/875 [==============================] - 4s 3ms/step - loss: 0.0841
Epoch 3/5
875/875 [==============================] - 4s 3ms/step - loss: 0.0840
Epoch 4/5
875/875 [==============================] - 4s 3ms/step - loss: 0.0840
Epoch 5/5
875/875 [==============================] - 4s 3ms/step - loss: 0.0840
<keras.callbacks.History at 0x7fc41be037d0>
具有快取但沒有迭代的訓練模型:
total_data_entries = len(list(raw_dataset.map(lambda x, y: (x, y))))
train_ds = raw_dataset.shuffle(buffer_size=total_data_entries).cache().batch(32).prefetch(tf.data.AUTOTUNE)
inputs = tf.keras.layers.Input((400,))
x = tf.keras.layers.Dense(200, activation='relu', kernel_initializer='normal')(inputs)
x = tf.keras.layers.Dense(100, activation='relu', kernel_initializer='normal')(x)
outputs = tf.keras.layers.Dense(1, kernel_initializer='normal')(x)
model = tf.keras.Model(inputs, outputs)
model.compile(optimizer='adam', loss='mse')
model.fit(train_ds, epochs=5)
Epoch 1/5
875/875 [==============================] - 4s 2ms/step - loss: 0.1428
Epoch 2/5
875/875 [==============================] - 2s 2ms/step - loss: 0.0841
Epoch 3/5
875/875 [==============================] - 2s 2ms/step - loss: 0.0840
Epoch 4/5
875/875 [==============================] - 2s 2ms/step - loss: 0.0840
Epoch 5/5
875/875 [==============================] - 2s 3ms/step - loss: 0.0840
<keras.callbacks.History at 0x7fc41fa87810>
具有快取和迭代的訓練模型:
total_data_entries = len(list(raw_dataset.map(lambda x, y: (x, y))))
train_ds = raw_dataset.shuffle(buffer_size=total_data_entries).cache().batch(32).prefetch(tf.data.AUTOTUNE)
_ = list(train_ds.as_numpy_iterator()) # iterate dataset beforehand
inputs = tf.keras.layers.Input((400,))
x = tf.keras.layers.Dense(200, activation='relu', kernel_initializer='normal')(inputs)
x = tf.keras.layers.Dense(100, activation='relu', kernel_initializer='normal')(x)
outputs = tf.keras.layers.Dense(1, kernel_initializer='normal')(x)
model = tf.keras.Model(inputs, outputs)
model.compile(optimizer='adam', loss='mse')
model.fit(train_ds, epochs=5)
Epoch 1/5
875/875 [==============================] - 3s 3ms/step - loss: 0.1427
Epoch 2/5
875/875 [==============================] - 2s 2ms/step - loss: 0.0841
Epoch 3/5
875/875 [==============================] - 2s 2ms/step - loss: 0.0840
Epoch 4/5
875/875 [==============================] - 2s 2ms/step - loss: 0.0840
Epoch 5/5
875/875 [==============================] - 2s 2ms/step - loss: 0.0840
<keras.callbacks.History at 0x7fc41ac9c850>
結論:資料集的快取和之前的迭代似乎對訓練有影響,但在這個例子中只使用了 7000 個檔案。
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/409754.html
標籤:
上一篇:Tensorflow安裝說明中列出的CUDA版本是可以/應該安裝的最高版本還是最低版本?
下一篇:rank1張量的20個元素的切片然后重塑拋出“重塑的輸入是具有10272個值的張量,但請求的形狀需要20的倍數”