我是一名資料分析師,試圖通過機器學習提高我的知識。
我已經完成了時間序列資料集的模型,其中每個點相隔 1 天,沒有間隙。我嘗試的特定模型型別是使用 tensorflow 的 keras 的多層自回歸雙向 LSTM,請參見下面的模型特定代碼:
model = keras.Sequential()
model.add(Bidirectional(LSTM(
units = 128,
input_shape = (X_train.shape[1], X_train.shape[2]),
return_sequences=True)))
model.add(Bidirectional(LSTM(
units = 64,
input_shape = (X_train.shape[1], X_train.shape[2]),
return_sequences=True)))
model.add(Bidirectional(LSTM(
units = 32,
input_shape = (X_train.shape[1], X_train.shape[2]),
return_sequences=True)))
model.add(Bidirectional(LSTM(
units = 16,
input_shape = (X_train.shape[1], X_train.shape[2]),
return_sequences=False)))
model.add(keras.layers.Dense(16))
model.add(keras.layers.Dropout(rate = 0.5))
model.add(keras.layers.Dense(1))
model.compile(loss='mean_squared_error', optimizer='Adam')
history = model.fit(
X_train, y_train,
epochs = 100,
batch_size = 128,
validation_split = 0.2,
shuffle = False
)
print(model.summary())
我被告知,對于這個特定的學習任務來說,這可能是一個高級員工的過度殺傷力,但我想添加它以實作完全透明。請參閱下面的摘要:
Layer (type) Output Shape Param #
=================================================================
bidirectional (Bidirectiona (None, 50, 256) 133120
l)
bidirectional_1 (Bidirectio (None, 50, 128) 164352
nal)
bidirectional_2 (Bidirectio (None, 50, 64) 41216
nal)
bidirectional_3 (Bidirectio (None, 32) 10368
nal)
dense (Dense) (None, 16) 528
dropout (Dropout) (None, 16) 0
dense_1 (Dense) (None, 1) 17
=================================================================
Total params: 349,601
Trainable params: 349,601
Non-trainable params: 0
_________________________________________________________________
模型報告損失值(在 100 個 epoch 之后,使用均方誤差):
損失:0.0040 - val_loss:0.0050(過擬合)
使用從上述包中派生的 RMSE:math.sqrt(mean_squared_error(y_train,train_predict))和math.sqrt(mean_squared_error(y_test,test_predict))使用sklearn.metrics以及內置函式mean_squared_error。
火車 RMSE:28.795422522129595
測驗 RMSE:34.17014386085355
對于圖形表示:

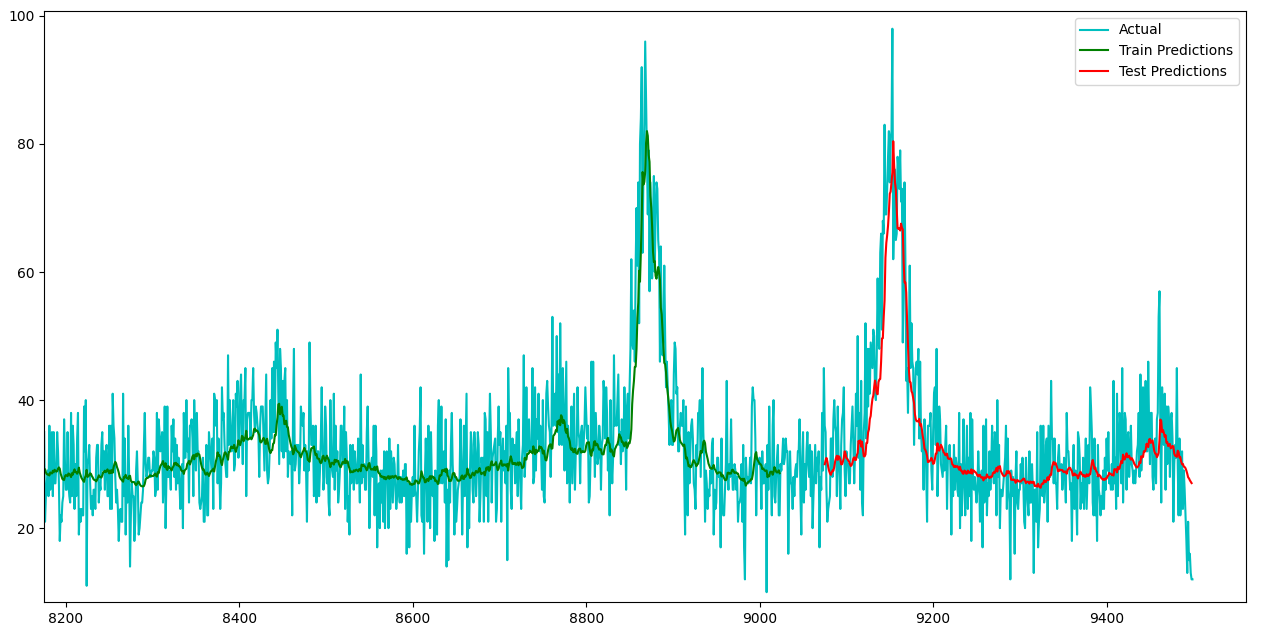
我終于到達了我的問題;如何更好地擬合我的模型以更接近地表示資料中的噪聲,因為我認為這是導致高 RMSE 值的原因。我研究了注意力機制,希望能夠突出資料中的特定峰和谷,但似乎這些最適合用于面向影像/文本預測的模型。我可以嘗試在更多的時期進行訓練,但模型已經稍微過擬合了,所以這會進一步激怒這個特定的問題。
我知道這是一個相當開放的問題,但我最好嘗試“展示我的作業”,并提前感謝您。
uj5u.com熱心網友回復:
對于這項任務,這看起來確實是一個巨大的矯枉過正。首先減少 LSTM 層的數量,并在 LSTM 層之間和每個 LSTM 內添加 dropout。
uj5u.com熱心網友回復:
你只有那個信號作為輸入,你試圖預測它的值?請記住,噪聲很可能實際上只是噪聲,并且無法僅從該資料中預測它。
注意聽起來并不像,除非你有一些理由認為尋找其他時間步長回來的路上可以幫助你預測發生的事情將是有益的現在。許多系統都具有馬爾可夫屬性:如果您現在了解狀態,那么歷史上的任何事情都無關緊要。
信號具有明顯的周期性,您可以通過像我在這里對一天中的時間和一年中的時間所做的那樣包含 sin 和 cos 特征,使模型更容易學習:
https://www.tensorflow.org/tutorials/structured_data/time_series
您也可以嘗試其他功能,例如 diff 或 EMA,或其中一些 ARIMA 風格的功能。但從根本上說,如果它是有效的噪聲,更好的功能將無濟于事,它們只會幫助您更快地訓練到相同的錯誤級別。
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/409757.html
標籤: