我在資料框中有 100k 條記錄
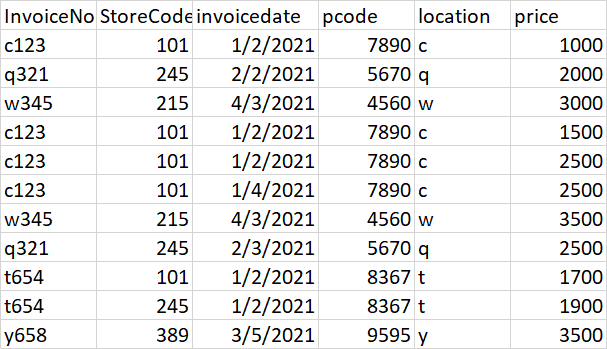
并想與商店一起找出同一發票和不同發票的同一產品的不同價格。提到的資料的資料片段
預期產出
uj5u.com熱心網友回復:
目前尚不清楚如何確定產品是否相同,但是您可以使用此代碼并更改子集值以僅保留資料框中的唯一行:
df = df.drop_duplicates(subset=['InvoiceCo', 'pcode', 'price'], keep="last").sort_values(by=['StoreCode'])
uj5u.com熱心網友回復:
您可以使用groupby按多列對資料框進行分組。
讓我們首先創建您的 DataFrame:
import pandas as pd
InvoiceNo = pd.Series(data=["c123","q321","w345", "c123", "c123", "c123", "w345", "q321", "t654", "t654", "t658"])
StoreCode = pd.Series(data=[101,245,215,101,101,101,215,245,101,245,389])
price = pd.Series(data=[1000,2000,3000,1500,2500,2500,3500,2500,1700,1900,3500])
pcode = pd.Series(data=[7890,5670,4560,7890,7890,7890,4560,
5670,8367,8367,9595])
InvoiceNo.name = 'InvoiceNo'
StoreCode.name= 'StoreCode'
price.name= 'price'
pcode.name="pcode"
df = pd.concat([pd.DataFrame(InvoiceNo),pd.DataFrame(StoreCode),pd.DataFrame(price),pd.DataFrame(pcode)], axis=1)
標準的掩碼(盡管對于給出的示例片段來說這不是必需的)
mask_invoice = df['InvoiceNo'].duplicated(keep=False)
mask_store = df["StoreCode"].duplicated(keep=False)
mask_pcode = df["pcode"].duplicated(keep=False)
df_masked = df[mask_pcode & mask_store & mask_invoice]
現在我們已經洗掉了 pcode、StoreCode 和 InvoiceNo 的單個條目。
InvoiceNo StoreCode price pcode
0 c123 101 1000 7890
1 q321 245 2000 5670
2 w345 215 3000 4560
3 c123 101 1500 7890
4 c123 101 2500 7890
5 c123 101 2500 7890
6 w345 215 3500 4560
7 q321 245 2500 5670
8 t654 101 1700 8367
9 t654 245 1900 8367
用多列對資料框進行分組:
dfg = df_masked.groupby(by=["StoreCode", "InvoiceNo"])
df_output = pd.DataFrame()
for group, data in dfg:
data.drop_duplicates(subset=["InvoiceNo", "StoreCode", "price"] ,inplace=True, ignore_index=True)
if len(data) >1:
df_output = pd.concat([df_output, data], ignore_index=True)
data.drop_duplicates 消除了分組資料中的重復行——在這種情況下,“c123”的價格為 2500。
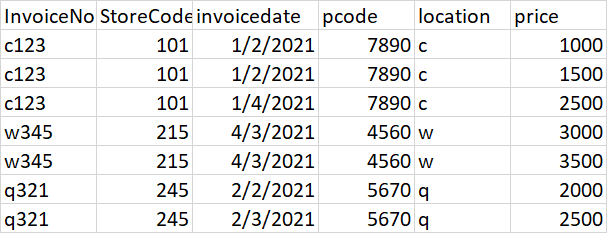
最終輸出:
print(df_output)
>> InvoiceNo StoreCode price pcode
0 c123 101 1000 7890
1 c123 101 1500 7890
2 c123 101 2500 7890
3 w345 215 3000 4560
4 w345 215 3500 4560
5 q321 245 2000 5670
6 q321 245 2500 5670
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/412120.html
標籤:
上一篇:如何強制asyncio任務運行?
下一篇:“find_element_by_name('name')”和“find_element(By.NAME,'name')”有什么區別?