前言
直接儲存器訪問(Direct Memory Access,DMA),允許一些設備獨立地訪問資料,而不需要經過 CPU 介入處理,因此在訪問大量資料時,使用 DMA 可以節約可觀的 CPU 處理時間,在 STM32 中一般的 DMA 傳輸方向:記憶體->記憶體、外設->記憶體、記憶體->外設,這里的外設可以是 UART、SPI 等資料收發設備,
通用異步收發傳輸器(Universal Asynchronous Receiver/Transmitter,UART),在嵌入式開發中一般稱為串口,通常用于中、低速通信場景,波特率低有 6400 bps,高能達到 4~5 Mbps,波特率低于 115200 bps 而且資料量不大場景中一般用不到 DMA 收發資料,因為 STM32 芯片的主頻有幾十到上百兆赫茲,低速串口這點中斷回應就灑灑水而已,但當收發資料量很大,或波特率提高到 Mbps 數量級時就很有使用 DMA 的必要了,這時再使用阻塞方式或中斷方式收發資料,都會占用過多的 CPU 時間,影響其他任務的執行,
對于 STM32 中使用 DMA 收發資料,網路上有很多例程和博客,作為學習 DMA 的使用都沒問題,但它們中的大部分都是基礎的使用,在高速、大資料量的場景中很容易出現資料例外,對于一個高速、可靠的串口收發程式而言,DMA 是必須的,而雙緩沖區、空閑中斷以及 FIFO 資料緩沖區也是非常重要的成分,這也是本文將要解決的問題,
STM32CubeMX 配置
本文使用的開發平臺:
- STM32F407(RoboMaster C 型板)
- STM32CubeMX 6.3.0
- STM32Cube FW_F4 V1.26.2
- CLion
- GNU C/C++ Compiler
首先使能高速外部時鐘
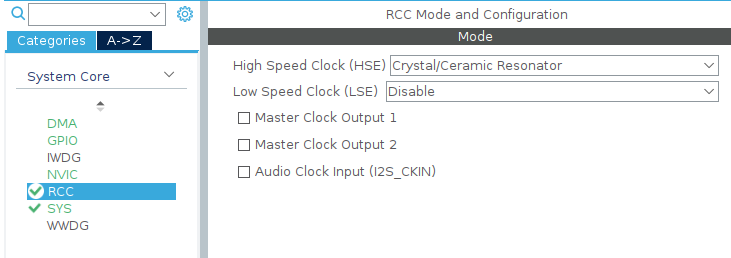
然后設定時鐘樹,1 處是外部晶振的頻率,按自己所用晶振的實際頻率填寫;2 處一般填寫自己所用芯片的最大頻率,我這里用的 F407 就是 168 MHz,填入后回車,其他地方的數值都會自動計算出來,非常方便,
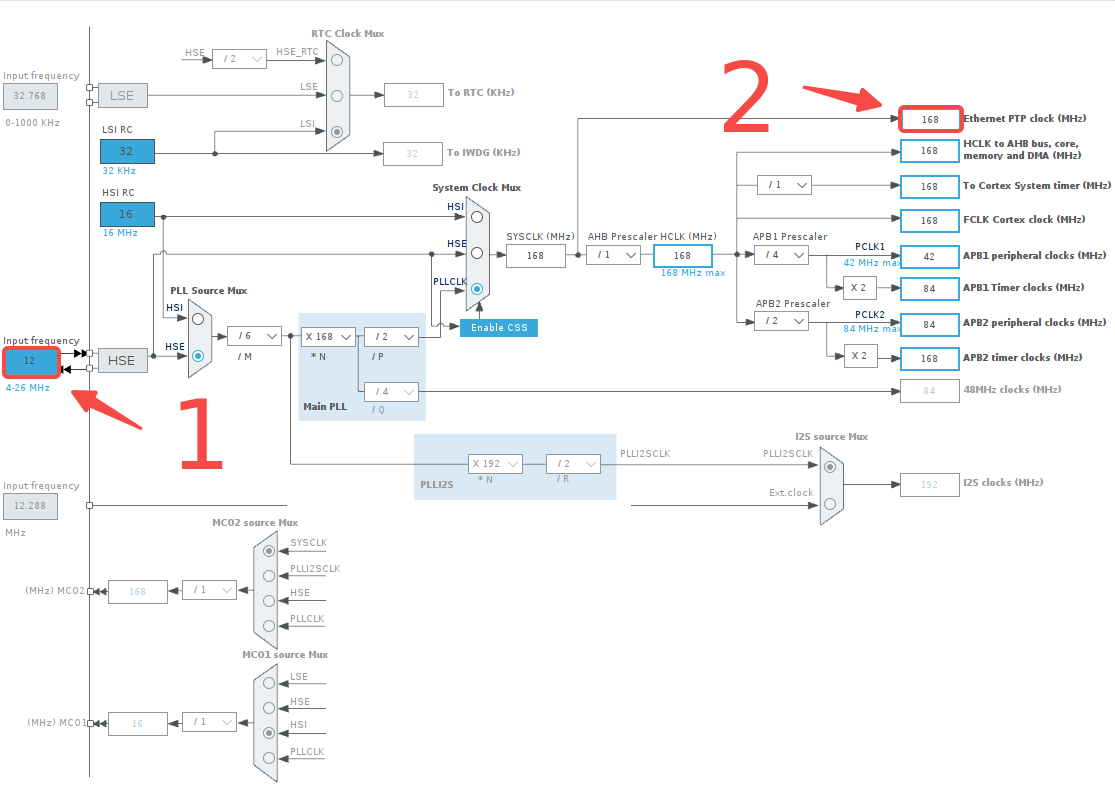
接下來配置串口:
-
選擇一個串口;
-
設定模式為 Asynchronous(異步);
-
設定波特率、幀長度、奇偶校驗以及停止位長度;
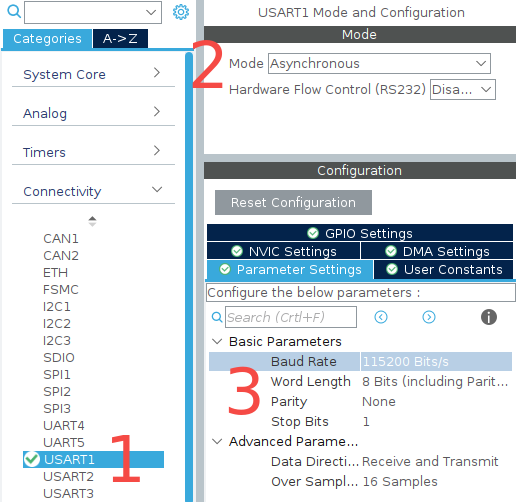
-
點擊 Add 添加接收和發送的 DMA 配置,注意在 RX 中將 DMA 模式改為 Circular,這樣 DMA 接收只用開啟一次,緩沖區滿后 DMA 會自動重置到緩沖區起始位置,不再需要每次接收完成后重新開啟 DMA;
-
開啟串口總中斷;

-
選擇正確的 GPIO 引腳,在 CubeMX 默認選擇的引腳大多數都正確的情況下,這很容易被忽略,出 BUG 再查的時候很難想到是這里的問題,一定要核對好,
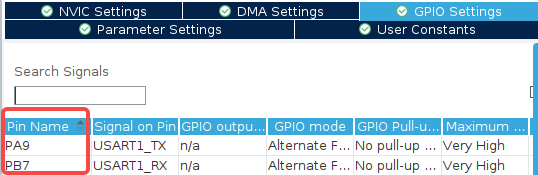
其他如除錯介面、作業系統以及工程管理等設定不在贅述,一頓常規操作后可 GENERATE CODE,
串口 DMA 接收
串口收到資料之后,DMA 會逐位元組搬運到 RX_Buf 中,搬運到一定的數量時,就會產生中斷(空閑中斷、半滿中斷、全滿中斷),程式會進入回呼函式以處理資料,處理資料這一步在本文中是將資料寫入 FIFO 中供應用讀取,將在后文介紹,先來看資料接收的流程圖,
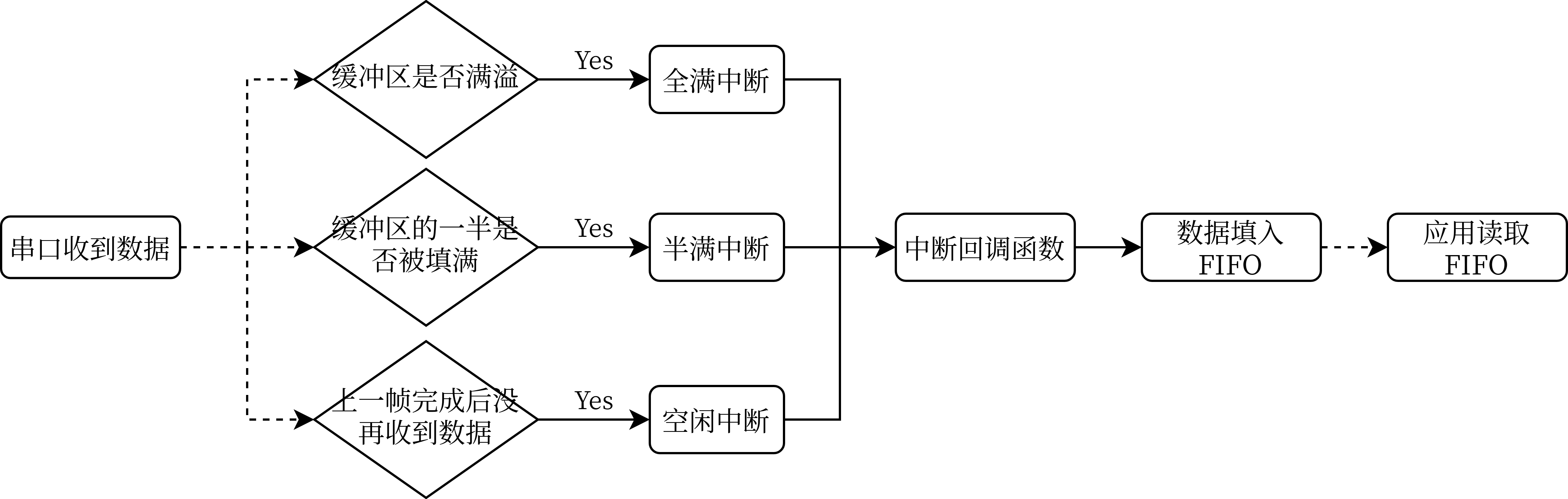
全滿中斷和半滿中斷都很好理解,就是串口 DMA 的緩沖區填充了一半和填滿時產生的中斷,而空閑中斷是串口在上一幀資料接收完成之后在一個位元組的時間內沒有接收到資料時產生的中斷,即總線進入了空閑狀態,這對于接收不定長資料十分方便,
現在網路上大部分教程都使用了全滿中斷加空閑中斷的方式來接收資料,不過這存在了一定的風險:DMA 可以獨立于 CPU 傳輸資料,這意味著 CPU 和 DMA 有可能同時訪問緩沖區,導致 CPU 處理其中的資料到中途時 DMA 繼續傳輸資料把之前的緩沖區覆寫掉,造成了資料丟失,所以更合理的做法是借助半滿中斷實作乒乓快取,
一個緩沖區實作的乒乓快取
乒乓快取是指一個快取寫入資料時,設備從另一個快取讀取資料進行處理;資料寫入完成后,兩邊交換快取,再分別寫入和讀取資料,這樣給設備留足了處理資料的時間,避免緩沖區中舊資料還沒讀取完又被新資料覆寫掉的情況,但是出現了一個小問題,就是 STM32 大部分型號的串口 DMA 只有一個緩沖區,要怎么實作乒乓快取呢?
沒錯,半滿中斷,現在,一個緩沖區能拆成兩個來用了,

看這圖我們再來理解一下上面提到的三個中斷:接受緩沖區的前半段填滿后觸發半滿中斷,后半段填滿后觸發全滿中斷;而這兩個中斷都沒有觸發,但是資料包已經結束且后續沒有資料時,觸發空閑中斷,舉個例子:向這個緩沖區大小為 20 的程式傳送一個大小為 25 的資料包,它會產生三次中斷,如下圖所示,
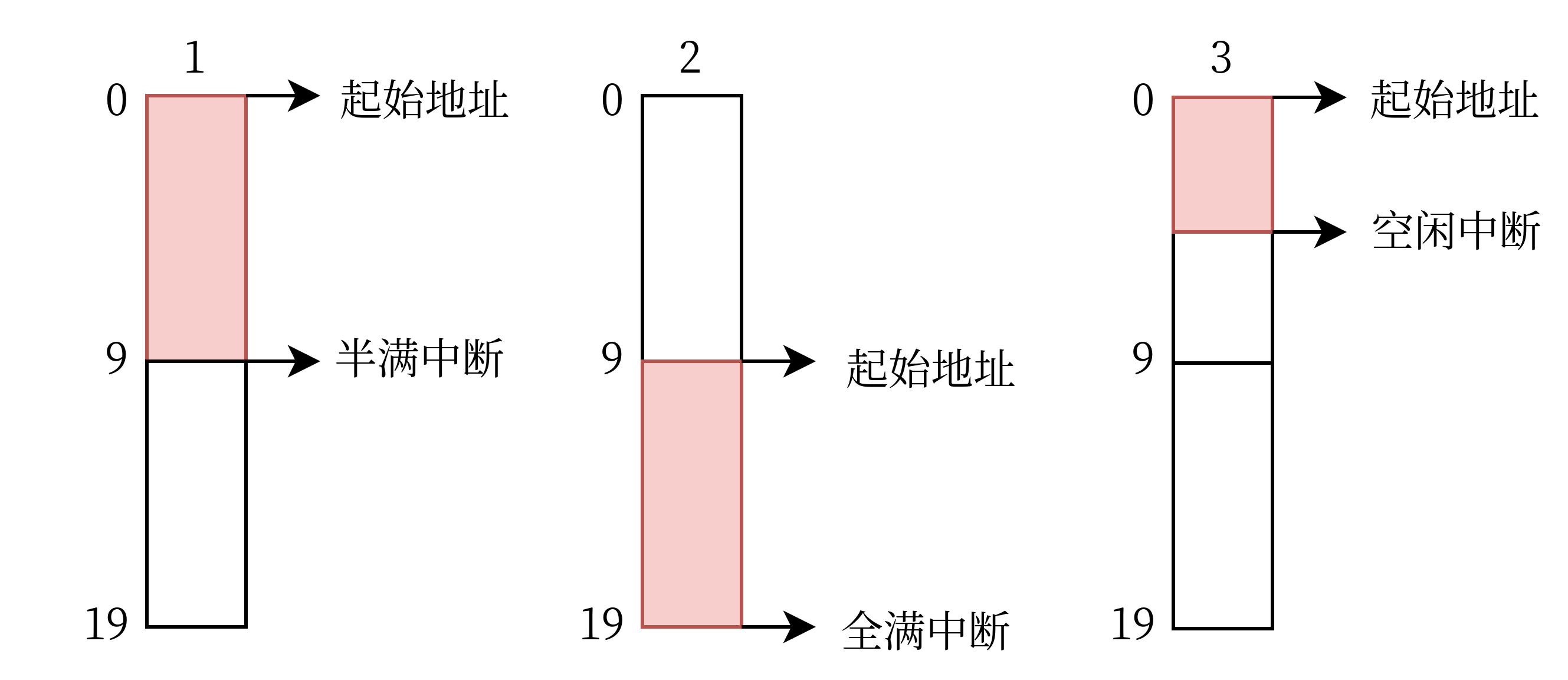
程式實作
原理介紹完成,感謝 ST 提供了 HAL 庫,接下來再使用 C 語言實作它們就很簡單了,
首先開啟串口 DMA 接收,
#define RX_BUF_SIZE 20
uint8_t USART1_Rx_buf[RX_BUF_SIZE];
HAL_UARTEx_ReceiveToIdle_DMA(&huart1, USART1_Rx_buf, RX_BUF_SIZE);
然后撰寫回呼函式,在回呼函式里把 USART1_Rx_buf 中的資料搬運到 FIFO 中,
void HAL_UARTEx_RxEventCallback(UART_HandleTypeDef *huart, uint16_t Size)
{
static uint8_t Rx_buf_pos; //本次回呼接收的資料在緩沖區的起點
static uint8_t Rx_length; //本次回呼接收資料的長度
Rx_length = Size - Rx_buf_pos;
fifo_s_puts(&uart_rx_fifo, &USART1_Rx_buf[Rx_buf_pos], Rx_length); //資料填入 FIFO
Rx_buf_pos += Rx_length;
if (Rx_buf_pos >= RX_BUF_SIZE) Rx_buf_pos = 0; //緩沖區用完后,回傳 0 處重新開始
}
這個回呼函式本身是弱函式,需要自己把它重寫一遍,它有兩個傳入的引數,第一個引數無須多言,第二個引數 Size 則是指整個緩沖區中已經被使用的大小,它有一個很神奇的地方,上文提到的三個中斷都會進入這里,所以要寫的代碼只有這么幾行了,
但是這帶來一個問題,如何區分這三個中斷呢?答案就是不用區分,只需要每次計算接收資料的起始地址和資料長度就能完成接收,所以我定義了兩個靜態變數:本次接收資料的長度 = 緩沖區被使用的總大小 - 本次回呼接收的資料在緩沖區中的起始位置;而起始位置從 0 開始,每次回呼加上本次接收資料的長度就好,
串口 DMA 發送
串口 DMA 的發送比接收簡單了許多,只需要把資料從發送資料的 FIFO 復制到發送緩沖區中,然后呼叫 HAL 庫發送函式就完成了:
const uint8_t TX_FIFO_SIZE = 100;
static uint8_t buf[TX_FIFO_SIZE]; //發送緩沖區
uint8_t len = fifo_s_used(&uart_tx_fifo); //待發送資料長度
fifo_s_gets(&uart_tx_fifo, (char *)buf, len); //從 FIFO 取資料
HAL_UART_Transmit_DMA(&huart1, buf, len); //發送
FIFO 佇列
先進先出(First In, First Out,FIFO)可能看起來很陌生,但如果叫它佇列應該就很熟悉了,在本文中 FIFO 被用來作為 DMA 收發緩沖區(RX_Buf、TX_Buf)與應用程式之間的緩沖區,說起來抽象,看看下圖展示的接收狀態資料流向,發送時的資料流向相反,
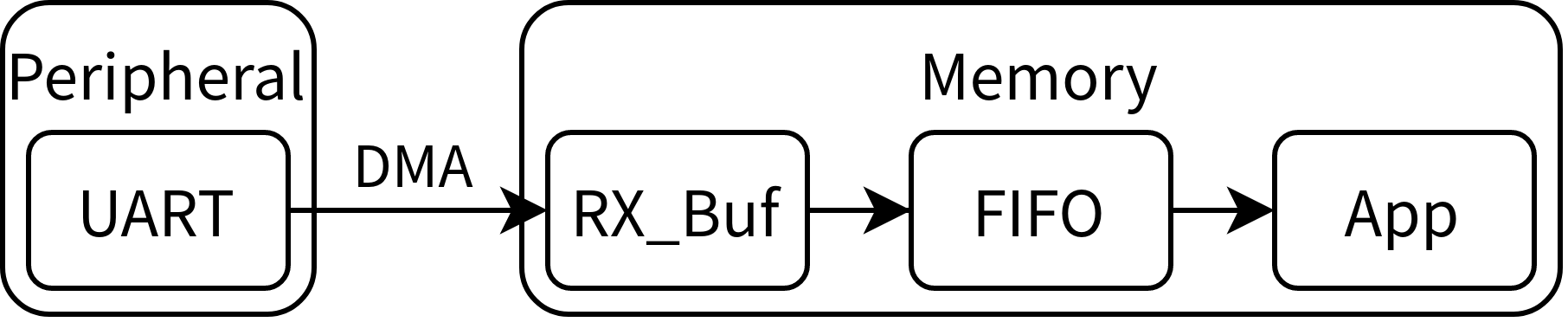
串口接收資料時,DMA 從串口暫存器搬運資料到記憶體中開辟的接識訓沖區 RX_Buf,并產生中斷(半滿中斷、全滿中斷、空閑中斷);在中斷的回呼函式里把 RX_Buf 中的資料送到 FIFO 中,應用程式中只需要檢測 FIFO 是否為空,非空即可讀取資料,
這看起來似乎有些畫蛇添足,已經有了一個 DMA 接識訓沖區,直接從這個 RX_Buf 里讀取資料豈不美哉?這里存在的問題就是,對 RX_Buf 的處理只能在 DMA 產生的中斷的回呼函式里進行;而中斷的回呼函式雖然阻塞住也不影響串口接收資料和 DMA 繼續搬運資料到 RX_Buf中,但是 RX_Buf 的大小始終是有限的,后來的資料會把以前的資料覆寫掉,所以只要資料一來就需要立即處理完成,不及時就會丟資料,FIFO 雖然也會有滿溢的問題,不過出現概率更小,處理起來相對簡單一些,
使用 FIFO 的另一個理由是它把應用層與驅動層隔離開來,App 中不用管 RX_Buf 在什么情況下會獲得幾個資料,只管從 FIFO 中讀資料;串口 DMA 的中斷回呼函式也有了固定的寫法,只管把資料壓入 FIFO,在資料不定長、資料量大的場景中,FIFO 無疑是非常必要的組分,
但是細心的朋友可能在上面 STM32CubeMX 配置串口 DMA 的圖中發現也有一個 “fifo”,這與上文敘述的 FIFO 有什么區別呢?這也是我有過的困惑,稍作說明,
FIFO 與 DMA 的 FIFO 不是同一個 FIFO
DMA 中也有 FIFO,不過它的作用是在串口暫存器與記憶體緩沖區之間再加入一個 FIFO 緩沖區,資料流向如下,

由于串口暫存器只能儲存一個位元組,所以開啟直接模式的 DMA 每個位元組都要搬運一次資料到記憶體緩沖區中,而 DMA 的 FIFO 實際效果簡單來說就是攢一批資料一起發送出去,可以減少軟體開銷和 AHB 總線上資料傳輸的次數,適合資料連續不斷且系統中還有其他開銷較大的任務這種場景使用,不過也是由于 DMA 的 FIFO 必須攢一批才能發送,攢不夠就不發了,所以也有一些局限性,本文沒有使用 DMA 的 FIFO,而是使用直接模式,
移植 FIFO
說了這么半天終于到寫代碼的時候了,我沒有自己實作一個 FIFO 環形緩沖區,而是移植了 RoboMaster AI 機器人的韌體中使用的 FIFO,
-
在上述 ropo 中復制
fifo.c與fifo.h檔案到自己的工程中, -
在
fifo.h中洗掉#include "sys.h",并在上邊鏈接里找到sys.h,將以下幾行互斥鎖的實作復制到fifo.h中,并額外包含頭檔案cmsis_gcc.h:#include <cmsis_gcc.h> #define MUTEX_DECLARE(mutex) unsigned long mutex #define MUTEX_INIT(mutex) do{mutex = 0;}while(0) #define MUTEX_LOCK(mutex) do{__disable_irq();}while(0) #define MUTEX_UNLOCK(mutex) do{__enable_irq();}while(0) -
這個 FIFO 庫中的動態創建佇列的實作使用了
malloc,如果使用了作業系統,應該自己改成作業系統的記憶體管理 API,不過本文沒有使用動態的方式創建佇列,
使用 FIFO
在串口 DMA 接收和串口 DMA 發送兩節已經介紹過了,這里再貼一下使用方法,
fifo_s_puts(&uart_rx_fifo, &USART1_Rx_buf[Rx_buf_pos], Rx_length); //資料填入 FIFO
uint8_t len = fifo_s_used(&uart_tx_fifo); //待發送資料長度
fifo_s_gets(&uart_tx_fifo, (char *)buf, len); //從 FIFO 取資料
壓力測驗
這樣的一套收發流程當然沒必要在低速環境(115200 bps)使用,但是它到底能用在波特率多高的場景下,穩定性如何,仍然是疑問,所以我們需要對它測驗一下,
我選用了 PL2303、FT232 兩種芯片的串口模塊進行測驗,
PL2303
PL2303 資料手冊支持的串口波特率為 75 bps 到 6 Mbps,不過我測驗之后最大的波特率約為 970000 bps,再大就沒法收到資料了,遠遠達不到預期值,希望有好心人告訴我這是怎么一回事,
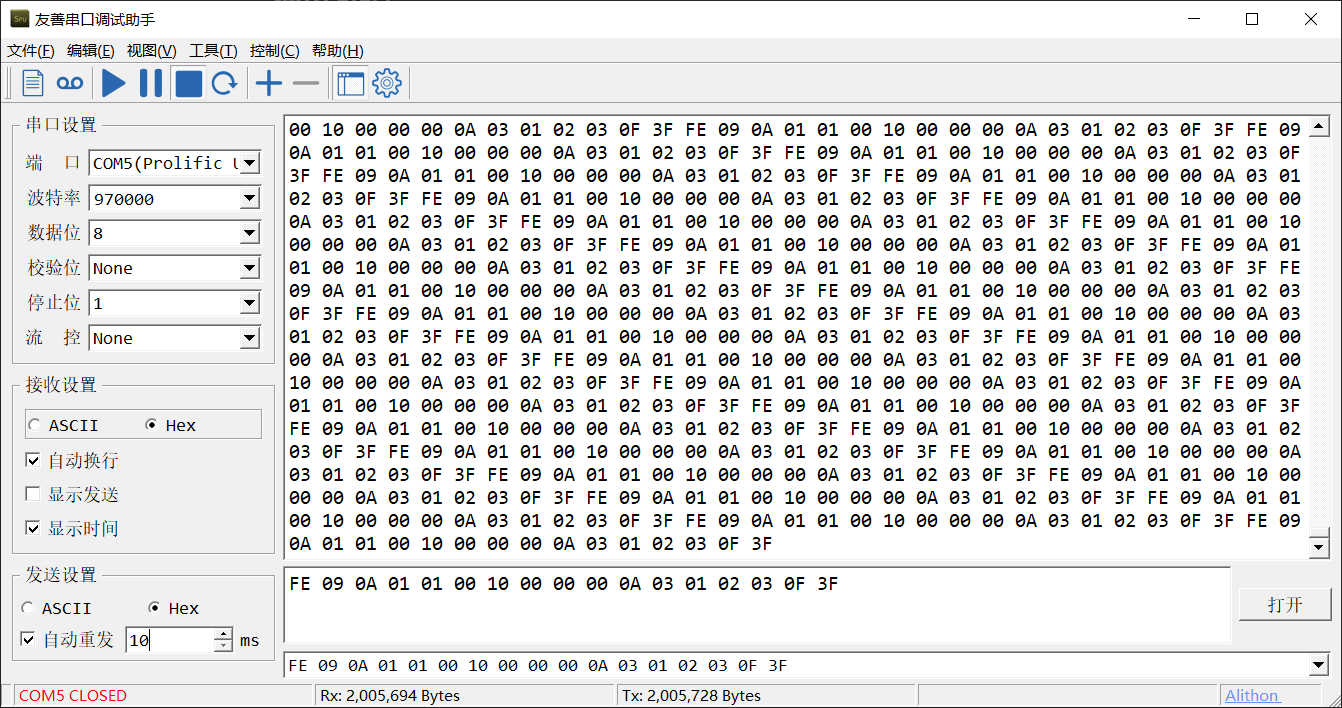
然后測驗一下通信穩定性,我以最小自動重發間隔 10 ms 向單片機發送 17 Bytes 的資料包,單片機再回傳所有資料,測驗運行了 58 分鐘,發送了 1958.69 KB 資料,接收到了 1958.69 KB,沒有丟包,穩定性過關,而截圖中 Tx 比 Rx 的值大是因為停止的時候發送了資料包沒有接收,在運行的全程序中兩個資料始終相等,
PL2303 還有個小問題是它在 Win10 上的驅動有問題,需要自己下載安裝老版本的驅動才能使用,
FT232
FT232 資料手冊有如下描述:
- 資料傳輸速率為300波特(baud)到3兆波特 (RS422/RS485和TTL電平)以及300波特到1兆波特(RS232)
我手上這個使用了 FT232 芯片的串口模塊實測最大波特率為 2 Mbps,終于達到了預期,
而 2 Mbps 下的穩定性測驗效果也很好,運行了 66 分鐘,沒有丟包,
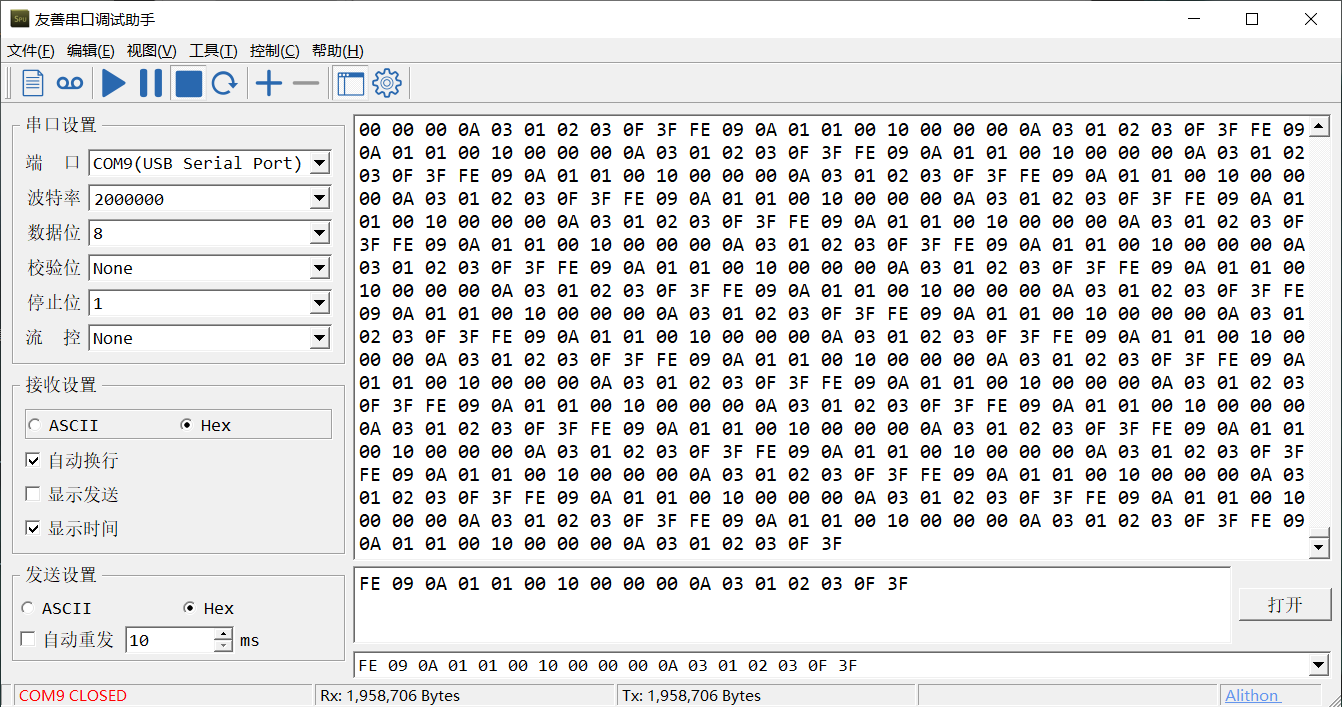
然后使用邏輯分析儀簡單測驗了 2 Mbps 下通信實際延遲,測驗方法為發送一個 17 Bytes 的資料包,單片機接收到后再用串口回傳所有資料:
-
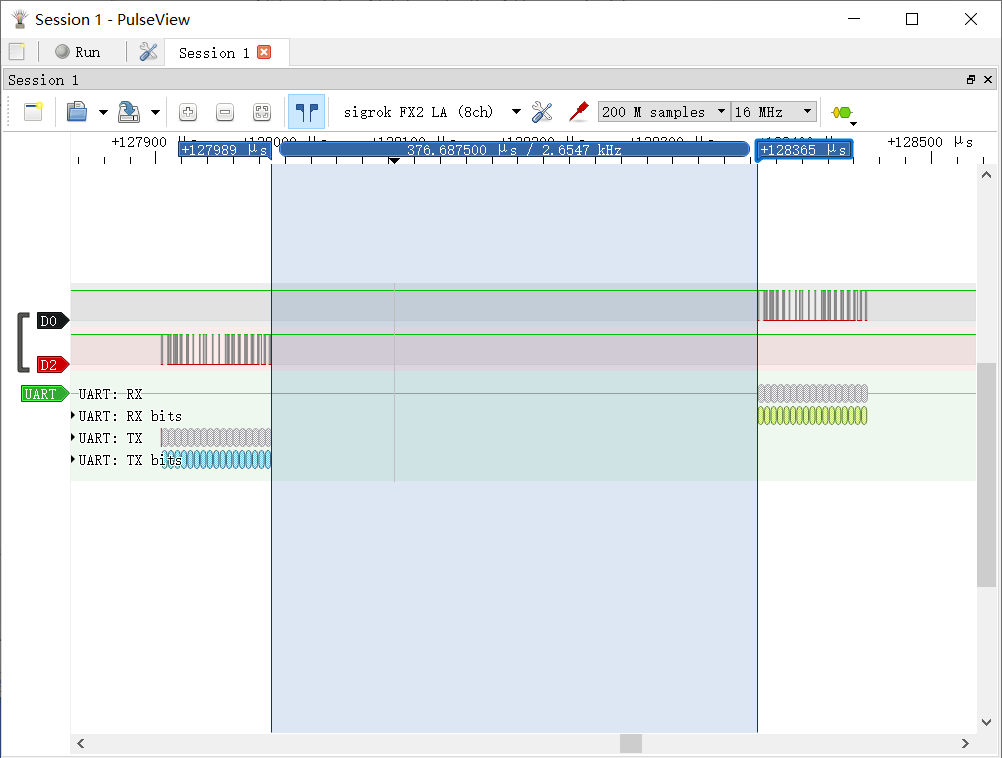
轉發延遲在 400 μs 左右,在我的程式里這段時間主要由檢測 FIFO 是否為空的頻率決定,目前理論值是 1000 Hz,
-
單個 17 Bytes 的資料包時長為 84 μs,收發程序全長約 0.5 ms,
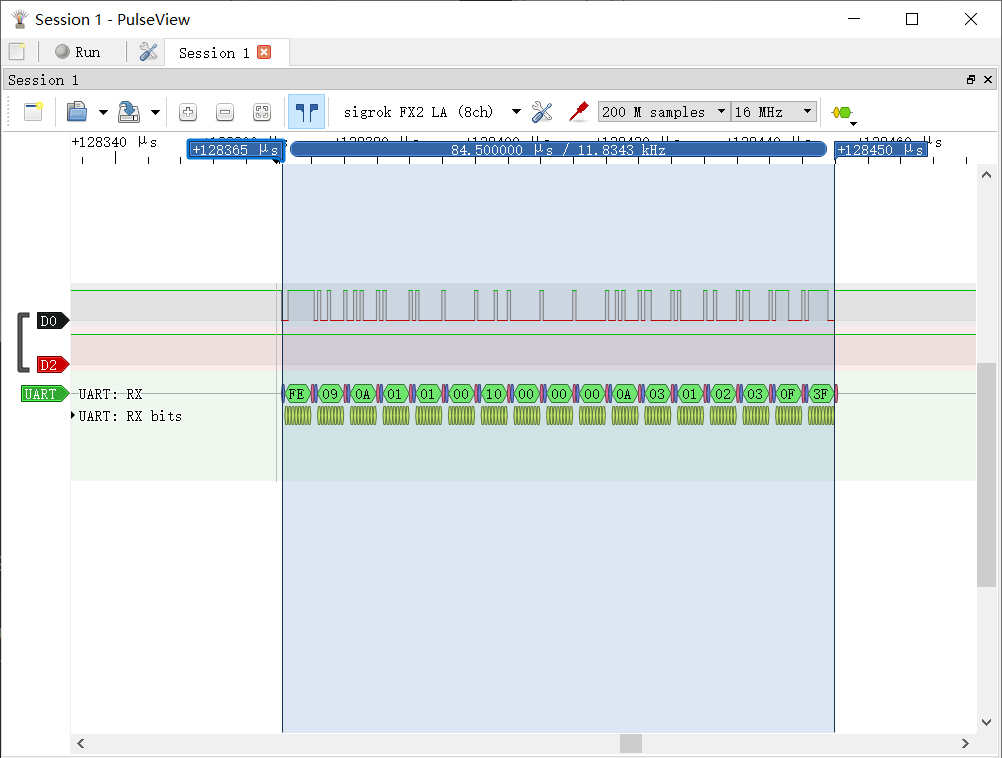
再對比一下 115200 bps 下的通信,單個 17 Bytes 資料包長度約 1500 μs,資料包的整個收發程序約 3100 μs,
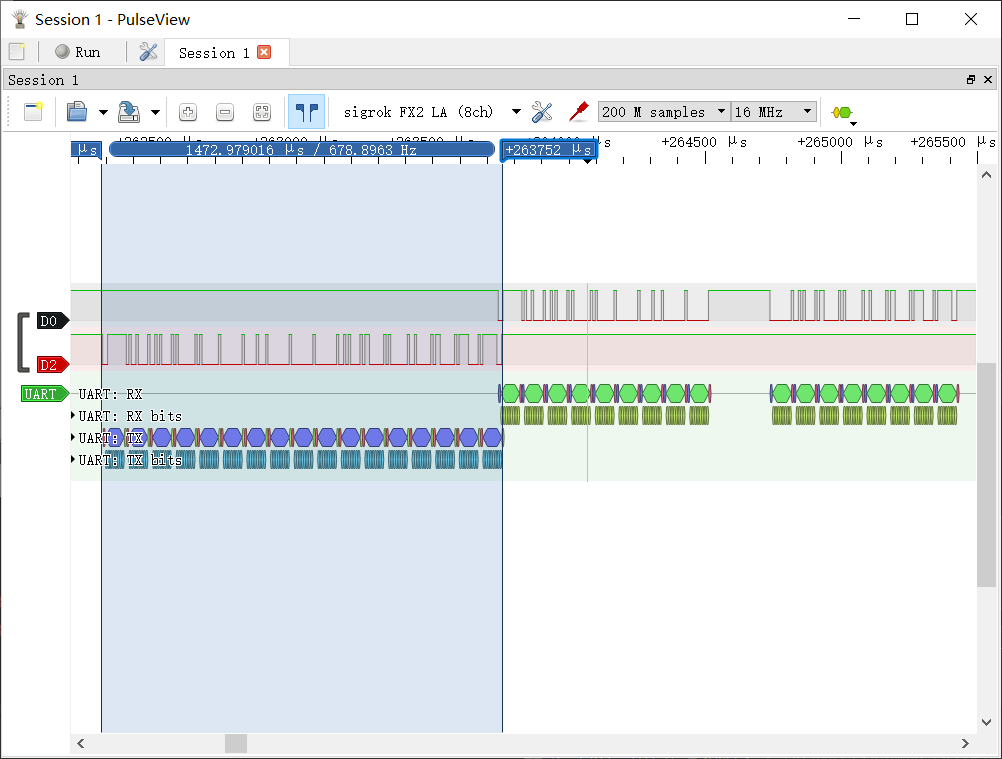
根據網上的博客,STM32F407 支持到 10.5 Mbps,但是這點我沒在手冊上查到,但是 2 Mbps 肯定不是它的極限,單片機與電腦相連的話,受限于串口模塊,2 Mbps 基本是天花板了,但是單片機與單片機間的串口通信,仍有潛力可以挖掘,
參考
acuity. (2020, September 3). 一個嚴謹的STM32串口DMA發送&接收(1.5Mbps波特率)機制_只要思想不滑坡,想法總比問題多,-CSDN博客_dma接收. https://blog.csdn.net/qq_20553613/article/details/108367512
STMicroelectronics. (2021, June). Description of STM32F4 HAL and Low-Layer Drivers. https://www.st.com/content/ccc/resource/technical/document/user_manual/2f/71/ba/b8/75/54/47/cf/DM00105879.pdf/files/DM00105879.pdf/jcr:content/translations/en.DM00105879.pdf
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/428433.html
標籤:其他
上一篇:C語言中static關鍵字詳解