如下所示是一個資料框,其中有一列col2中有許多 nan,我只想填充col1字典 dict_map 中的作為鍵的 nan 值并將這些值映射到 col2 中。
可重現的代碼:
import pandas as pd
import numpy as np
dict_map = {'a':45,'b':23,'c':97,'z': -1}
df = pd.DataFrame()
df['tag'] = [1,2,3,4,5,6,7,8,9,10,11]
df['col1'] = ['a','b','c','b','a','a','z','c','b','c','b']
df['col2'] = [np.nan,909,34,56,np.nan,45,np.nan,11,61,np.nan,np.nan]
df['_'] = df['col1'].map(dict_map)
預期產出
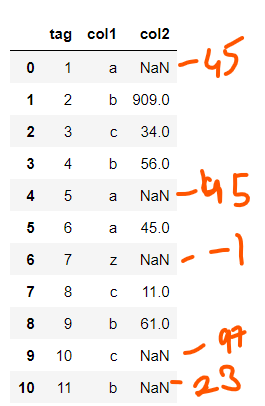
方法之一是:
df['col3'] = np.where(df['col2'].isna(),df['_'],df['col2'])
df
只是想知道任何其他使用函式和映射函式的方法,我們可以對此進行優化。
uj5u.com熱心網友回復:
col1您可以使用您的映射,dict_map然后將其用作 的輸入fillna,如下所示
df['col3'] = df['col2'].fillna(df['col1'].map(dict_map))
uj5u.com熱心網友回復:
只需使用即可獲得相同的結果list comprehension,這是一個非常 Python 的解決方案,我相信它具有更好的性能。
我們只是讀取col2并將值復制到col3if it not NaN。然后,如果是,我們查看Col1,獲取 ,dict key然后使用來自 的相應值dict_map。
df['col3'] = [df['col2'][idx] if not np.isnan(df['col2'][idx]) else dict_map[df['col1'][idx]] for idx in df.index.tolist()]
輸出:
df
tag col1 col2 col3
0 1 a NaN 45.0
1 2 b 909.0 909.0
2 3 c 34.0 34.0
3 4 b 56.0 56.0
4 5 a NaN 45.0
5 6 a 45.0 45.0
6 7 z NaN -1.0
7 8 c 11.0 11.0
8 9 b 61.0 61.0
9 10 c NaN 97.0
10 11 b NaN 23.0
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/431230.html
標籤:Python 熊猫 数据框 python-2.7 字典
下一篇:C 自動decltype模板