如何比較 2 個資料框并洗掉具有相似值的行?
df = pd.read_csv('trace_id.csv')
df1 = pd.read_csv('people.csv')
combinedf = pd.concat([df, df1], axis=1)
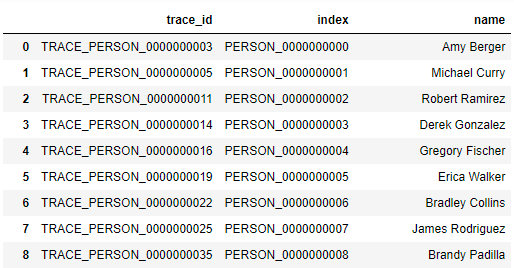
df 包含列“trace_id”,df1 包含列“index”和“name”。請注意,trace_id 和 index 的值非常相似,分別為“TRACE_PERSON_0000000003”和“PERSON_0000000003”。如何洗掉具有相似 trace_id 和索引值的行。
示例:trace_id = 'TRACE_PERSON_0000000003' 和 index = 'PERSON_0000000003',它的 trace_id、索引和名稱都將被洗掉。在 trace_id 列中找不到“PERSON_0000000000”,因此“PERSON_0000000000”和“Amy Berger”將保留在資料框中。
uj5u.com熱心網友回復:
沒有示例資料很難確定,但您可以:
TRACE_從trace_id列中洗掉df- 在修剪后的
trace_idand上合并index,傳遞indicator=True以獲取名為的合并指示符列_merge - 排除行
_merge == 'both'
df = pd.read_csv('trace_id.csv')
df1 = pd.read_csv('people.csv')
# Delete "TRACE_" from `trace_id` column
df['trace_id_trimmed'] = df['trace_id'].str.replace('TRACE_', '')
# Outer merge with indicator column
merged = df.merge(df1,
how='outer',
left_on='trace_id_trimmed',
right_on='index',
indicator=True)
# Exclude rows where merge key was found in both DataFrames
merged = merged[merged['_merge'] != 'both'].copy()
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/431712.html
上一篇:帶有陣列的列,其中所有月份都在從開始日期開始的x年數中-Pyspark
下一篇:將集合字典轉換為熊貓資料框