我有:
haves = pd.DataFrame({'Product':['R123','R234'],
'Price':[1.18,0.23],
'CS_Medium':[1, 0],
'CS_Small':[0, 1],
'SC_A':[1,0],
'SC_B':[0,1],
'SC_C':[0,0]})
print(haves)

給定一個列串列,如下所示:
list_of_starts_with = ["CS_", "SC_"]
我想到達這里:
wants = pd.DataFrame({'Product':['R123','R234'],
'Price':[1.18,0.23],
'CS':['Medium', 'Small'],
'SC':['A', 'B'],})
print(wants)
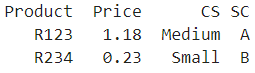
我知道wide_to_long但不認為它適用于這里?
uj5u.com熱心網友回復:
我們可以將“SC”和“CS”列值轉換為布爾掩碼來過濾列名;然后join它回到原來的DataFrame:
msk = haves.columns.str.contains('_')
s = haves.loc[:, msk].astype(bool)
s = s.apply(lambda x: dict(s.columns[x].str.split('_')), axis=1)
out = haves.loc[:, ~msk].join(pd.DataFrame(s.tolist(), index=s.index))
輸出:
Product Price CS SC
0 R123 1.18 Medium A
1 R234 0.23 Small B
uj5u.com熱心網友回復:
根據列串列(假設starts_with足以識別它們),可以批量進行更改:
def preprocess_column_names(list_of_starts_with, column_names):
"Returns a list of tuples (merged_column_name, options, columns)"
columns_to_transform = []
for starts_with in list_of_starts_with:
len_of_start = len(starts_with)
columns = [col for col in column_names if col.startswith(starts_with)]
options = [col[len_of_start:] for col in columns]
merged_column_name = starts_with[:-1] # Assuming that the last char is not needed
columns_to_transform.append((merged_column_name, options, columns))
return columns_to_transform
def merge_columns(df, merged_column_name, options, columns):
for col, option in zip(columns, options):
df.loc[df[col] == 1, merged_column_name] = option
return df.drop(columns=columns)
def merge_all(df, columns_to_transform):
for merged_column_name, options, columns in columns_to_transform:
df = merge_columns(df, merged_column_name, options, columns)
return df
并運行:
columns_to_transform = preprocess_column_names(list_of_starts_with, haves.columns)
wants = merge_all(haves, columns_to_transform)
如果您的列名并不奇怪(例如Index_in list_of_starts_with),上面的代碼應該可以以合理的性能解決問題。
uj5u.com熱心網友回復:
一種選擇是將資料轉換為長格式,過濾值為 1 的行,然后轉換回寬格式。我們可以將pivot_longerfrompyjanitor用于wide to long 部分,并pivot回傳到wide 形式:
# pip install pyjanitor
import pandas as pd
import janitor
( haves
.pivot_longer(index=["Product", "Price"],
names_to=("main", "other"),
names_sep="_")
.query("value==1")
.pivot(index=["Product", "Price"],
columns="main",
values="other")
.rename_axis(columns=None)
.reset_index()
)
Product Price CS SC
0 R123 1.18 Medium A
1 R234 0.23 Small B
您可以完全避免pyjanitor,通過在重塑之前對列進行轉換(它仍然涉及從寬到長,然后從長到寬):
index = [col for col in haves
if not col.startswith(tuple(list_of_starts_with))]
temp = haves.set_index(index)
temp.columns = (temp
.columns.str.split("_", expand=True)
.set_names(["main", "other"])
# reshape to get final dataframe
(temp
.stack(["main", "other"])
.loc[lambda df: df == 1]
.reset_index("other")
.drop(columns=0)
.unstack()
.droplevel(0, 1)
.rename_axis(columns=None)
.reset_index()
)
Product Price CS SC
0 R123 1.18 Medium A
1 R234 0.23 Small B
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/431721.html