我有這樣的檔案
InputFile.txt
JOB JOB_A
Source C://files/InputFile
Resource 0 AC
User Guest
ExitCode 0 Success
EndJob
JOB JOB_B
Source C://files/
Resource 1 AD
User Current
ExitCode 1 Fail
EndJob
JOB JOB_C
Source C://files/Input/
Resource 3 AE
User Guest2
ExitCode 0 Success
EndJob
我必須將上述檔案轉換為 csv 檔案,如下所示
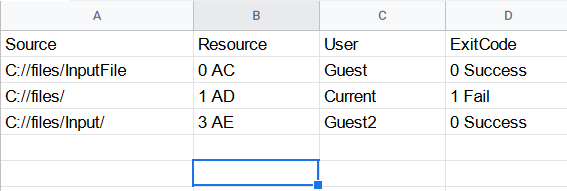
如何使用 shell 腳本轉換它?
uj5u.com熱心網友回復:
我用過awk。分隔符是一個制表符,因為它比 CSV 格式的逗號更常見。如果你想要昏迷,你可以簡單地改變\t-> ,。
cat InputFile.txt | \
awk '
BEGIN{print "Source\tResource\tUser\tExitCode"}
/^JOB/{i=0}
/^\s/{
i ;
match($0,/\s*[a-zA-Z]* /);
a[i]=substr($0,RLENGTH RPOS)}
/^EndJob/{for(i=1;i<5;i ) printf "%s\t",a[i];print ""}'
- 第一行
BEGIN寫標題。 - 第二行匹配
/JOB/并且僅將迭代器設定i為零。 - 第三行匹配行首的空白并
a用值填充陣列(它依賴于嚴格的計數和行的順序)。 - awk 腳本的第四部分匹配
EndJob并列印存盤的值。
輸出:
| 資源 | 資源 | 用戶 | 退出代碼 |
|---|---|---|---|
| C://檔案/輸入檔案 | 0 交流電 | 客人 | 0 成功 |
| C://檔案/ | 1 公元 | 當前的 | 1 失敗 |
| C://檔案/輸入/ | 3 次 | 客人2 | 0 成功 |
使用關聯陣列的腳本:
您可以更改腳本,以便使用 $1(第一條記錄)行中的嚴格 Source、Resource、User 和 ExitCode 值,但它會更長一些,并且此輸入檔案不需要它。
cat InputFile.txt | \
awk '
BEGIN{
h[1]="Source";
h[2]="Resource";
h[3]="User";
h[4]="ExitCode";
for(i=1;i<5;i ) printf "%s\t",h[i];print ""}
/^\s/{
i ;
match($0,/\s*[a-zA-Z]* /);
a[$1]=substr($0,RLENGTH RPOS)}
/^EndJob/{for(i=1;i<5;i ) printf "%s\t",a[h[i]];print ""}'
uj5u.com熱心網友回復:
with sed ...不知道InputFile.txt中的順序是否總是與Source,Resource,User,ExitCode相同,但如果是
declare delimiter=";"
sed -Ez "s/[^\n]*(Source|Resource|User) ([^\n]*)\n/\2${delimiter}/g;s/[ \t]*ExitCode //g;s/[^\n]*JOB[^\n]*\n//gi;s/^/Source${delimiter}Resource${delimiter}User${delimiter}ExitCode\n/" < InputFile.txt > output.csv
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/432241.html