我有以下字串
https://test.com/fi/wp-content
https://test.com/fr
https://test.com/es
https://test.com/
https://test.com/wp-content/
https://test.com/image.png
https://test.com/de/wp-content/themes
https://test.com/es
https://test.com/fr
https://test.com/no
https://test.com/da
https://test.com/en
https://test.com/de
https://test.com/nl/wp-content
https://test.com/fi
到目前為止,我有以下正則運算式
/\btest.com.*\.*(?<!fr|es|da|no|en|de|nl|fi)$/gm
我想匹配以下(圖1)

我快到了,但我的正則運算式匹配我表達后的所有內容(圖 2):
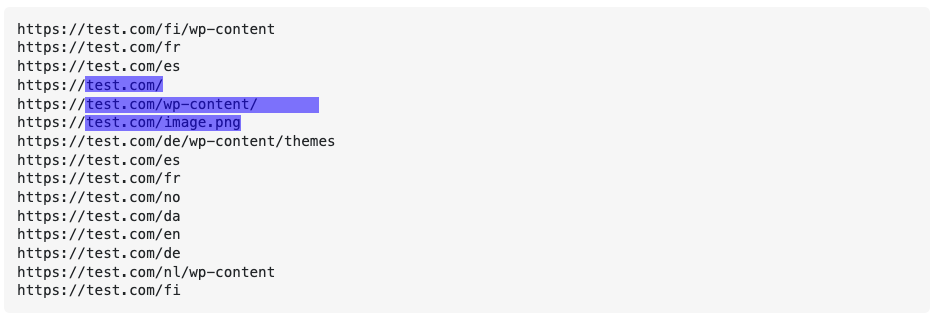
我似乎可以弄清楚如何讓我的正則運算式結束以使其產生匹配,如圖 1 所示。這是一個 regex101:https ://regex101.com/r/Tv0AjJ/1
uj5u.com熱心網友回復:
目前這部分.*(?<!fr|es|da|no|en|de|nl|fi)$匹配到字串的末尾,并斷言左邊的不是任何替代方案,這就是為什么/es不匹配但匹配的原因.png。
您可以使用負前瞻直接匹配/并斷言不正確的任何替代方案(?!
注意轉義點。
\btest\.com\/(?!fr|es|d[ae]|no|en|nl|fi)
正則運算式演示
如果您不想要部分匹配,您可以將備選方案本身再次分組,然后加上單詞邊界\b,或者如 Wiktor Stribi?ew 在評論中提到的正斜杠或字串結尾(?:\/|$)
具有相同字符的替代可以組合在一個字符類中d[ae]
\btest\.com\/(?!(?:fr|es|d[ae]|no|en|nl|fi)\b)
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/432363.html
標籤:正则表达式