我有如下資料:
qty_min qty_max region_min region_max subj region
11 1 10 10 ab UK
21 1 nan 20 ab UK
nan nan nan 30 ab UK
nan 2 nan 34 bc US
nan 2 20 nan bc US
10 nan nan nan bc TZ
11 nan nan 47 de TZ
13 3 109 31 de TZ
df = pd.read_clipboard()
print(df)
我想fillna()在每一列中:qty_min, qty_max, region_min,region_max基于一個模式。
例如:如果有NaNinqty_min和列,qty_max我們需要fillna()使用and groupby。subjffill().bfill()
同樣,如果有NaN, region_max,region_min我們需要fillna()使用groupbyofregion和ffill().bfill()
所以,我嘗試了以下方法:
df['qty_min'] = df.groupby(['subj'], sort=False)['qty_min'].apply(lambda x: x.ffill().bfill())
df['qty_max'] = df.groupby(['subj'], sort=False)['qty_max'].apply(lambda x: x.ffill().bfill())
df['region_min'] = df.groupby(['region'], sort=False)['region_min'].apply(lambda x: x.ffill().bfill())
df['region_max'] = df.groupby(['region'], sort=False)['region_max'].apply(lambda x: x.ffill().bfill())
如您所見,這并不優雅。此外,我在實際資料中有 20 多個這樣的列,我想使用相同的方式(groupby列和ffill.bfill())填充它們
我在dict下面手動創建了一個類似的標識來識別相應groupby的填充列NaN。
我愿意修改我們存盤這些資訊的方式。您可以使用任何簡單的資料結構。
fillna_dict= {
"subj": ['qty_min','qty_max'],
"region": ['region_min','region_max']
}
有沒有優雅而有效的方法來做到這一點?
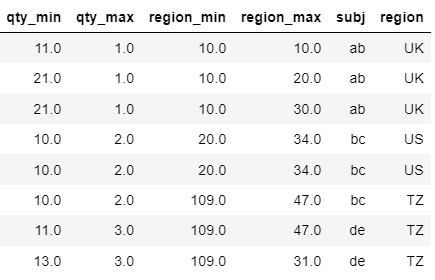
我希望我的輸出如下所示:
uj5u.com熱心網友回復:
由于您有單獨的條件,因此您需要有幾行。
您要做的是重構代碼以重用組和單個函式:
f = lambda x: x.ffill().bfill()
g1 = df.groupby(['subj'], sort=False)
g2 = df.groupby(['region'], sort=False)
df['qty_min'] = g1['qty_min'].apply(f)
df['qty_max'] = g1['qty_max'].apply(f)
df['region_min'] = g2['region_min'].apply(f)
df['region_max'] = g2['region_max'].apply(f)
使用你的字典:
f = lambda x: x.ffill().bfill()
fillna_dict= {
"subj": ['qty_min','qty_max'],
"region": ['region_min','region_max']
}
for k, cols in fillna_dict.items():
df[cols] = df.groupby(df[k])[cols].apply(f)
輸出:
qty_min qty_max region_min region_max subj region
0 11.0 1.0 10.0 10.0 ab UK
1 21.0 1.0 10.0 20.0 ab UK
2 21.0 1.0 10.0 30.0 ab UK
3 10.0 2.0 20.0 34.0 bc US
4 10.0 2.0 20.0 34.0 bc US
5 10.0 2.0 109.0 47.0 bc TZ
6 11.0 3.0 109.0 47.0 de TZ
7 13.0 3.0 109.0 31.0 de TZ
uj5u.com熱心網友回復:
嘗試在函式中執行此操作:
for k,v in fillna_dict.items():
df[v] = df.groupby([k], sort=False)[v].apply(lambda x: x.ffill().bfill())
輸出:
qty_min qty_max region_min region_max subj region
0 11.0 1.0 10.0 10.0 ab UK
1 21.0 1.0 10.0 20.0 ab UK
2 21.0 1.0 10.0 30.0 ab UK
3 10.0 2.0 20.0 34.0 bc US
4 10.0 2.0 20.0 34.0 bc US
5 10.0 2.0 109.0 47.0 bc TZ
6 11.0 3.0 109.0 47.0 de TZ
7 13.0 3.0 109.0 31.0 de TZ
uj5u.com熱心網友回復:
重組你的字典并嘗試:
fillna_dict= {"qty_min": "subj",
"qty_max": "subj",
"region_min": "region",
"region_max": "region"
}
df[list(fillna_dict.keys())] = df[list(fillna_dict.keys())].apply(lambda x: df.groupby(fillna_dict[x.name], sort=False)[x.name].ffill().bfill())
>>> df
qty_min qty_max region_min region_max subj region
0 11.0 1.0 10.0 10.0 ab UK
1 21.0 1.0 10.0 20.0 ab UK
2 21.0 1.0 10.0 30.0 ab UK
3 10.0 2.0 20.0 34.0 bc US
4 10.0 2.0 20.0 34.0 bc US
5 10.0 2.0 109.0 47.0 bc TZ
6 11.0 3.0 109.0 47.0 de TZ
7 13.0 3.0 109.0 31.0 de TZ
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/434072.html
標籤:Python 熊猫 数据框 麻木的 熊猫-groupby