我是 Scala 的新手,我正在嘗試讀取一個包含嵌套檔案的 json 檔案,我將其轉換為 spark 表,以便訪問它們的內部值,這些值回傳以下模式。
root
|-- id: array (nullable = true)
| |-- element: long (containsNull = true)
|-- column1: array (nullable = true)
| |-- element: double (containsNull = true)
|-- column2: array (nullable = true)
| |-- element: double (containsNull = true)
|-- column3: array (nullable = true)
| |-- element: double (containsNull = true)
|-- column4: array (nullable = true)
| |-- element: double (containsNull = true)
-------------------- -------------------- -------------------- -------------------- --------------------
| id | column1 | column2 | column3 | column4 |
-------------------- -------------------- -------------------- -------------------- --------------------
|[1163903, 1135067...|[3.7049873, 3.084...|[3.8597548, 4.188...|[1.6563705, 1.609...|[3.6857932, 3.190...|
-------------------- -------------------- -------------------- -------------------- --------------------
這不是我所期望的,我試圖爆炸所有的列,但也沒有回傳我所期望的,
val exploded = selectedAttributes.columns.foldLeft(selectedAttributes)((selectedAttributes, column) => selectedAttributes.withColumn(column, explode(col(column))))
| id | column1 | column2 | column3 | column4 |
------- ----------------- ------------------- ------------------- ----------------
|1163903| 3.7049873| 3.8597548| 1.6563705| 3.6857932|
|1163903| 3.7049873| 3.8597548| 1.6563705| 3.190083|
|1163903| 3.7049873| 3.8597548| 1.6563705| 1.990814|
|1163903| 3.7049873| 3.8597548| 1.6563705| 2.319732|
|1163903| 3.7049873| 3.8597548| 1.6563705| 3.3546507|
|1163903| 3.7049873| 3.8597548| 1.6563705| 2.370629|
|1163903| 3.7049873| 3.8597548| 1.6563705| null|
所以我決定在驅動程式中收集資訊(我認為這不是最好的解決方案)并通過自己呼叫 zip 函式并創建資料集來創建資料框,但也不起作用。
像這樣的東西:
val zipFeatures = id zip column1 zip column4 zip column2 zip column3
case class dataset(id: Int, column1: Double, column2: Double, column3: Double, column4: Double)
val rowsOfFeatures = zipFeatures map {
case ((((id, column1), column2), column3), column4) =>
dataset(id, column1, column2, column3, column4)
}
spark.createDataset(rowsOfFeatures).toDF()
這給了我一個更好的結果,但是,我認為我無法將所有這些資訊保存到驅動程式中。
這是預期的輸出:
|id |column1 | column2 | column3 | column4 |
|1163903| 3.7049873| 3.8597548| 1.6563705| 3.6857932|
|1135067| 3.0849733| 4.1883473| 1.6097081| 3.190083|
|1136137| 3.415591| 3.12623| 1.7889535| 1.990814|
| 1873| 2.6446266| 3.9076807| 2.0752525| 2.319732|
|1130327| 3.85075| 4.857642| 2.192937| 3.3546507|
| 1879| 2.7091007| 3.8000894| 2.0292222| 2.370629|
| 86684| 4.414381| 3.9849327| null| null|
| 66284| 3.3164778| 4.774783| 1.9173387| 3.1792257|
| 1652| 3.0772924| 3.4006166| 1.7305527| 2.9725764|
|1128385| 4.321163| 3.835489| null| null|
任何幫助將不勝感激!
uj5u.com熱心網友回復:
如果您使用的是 spark 2.4 或更高版本,則可以使用 arrays_zip 函式和explode 函式來獲得您想要的結果,如下所示:
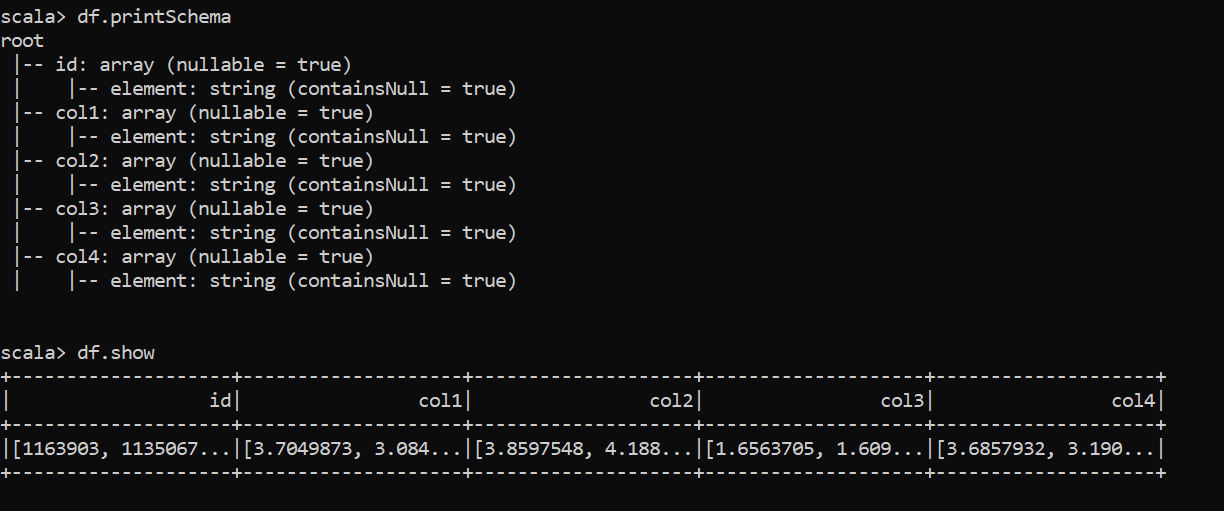
// 使用下面的代碼創建了一個類似的資料框
val columnNames = List("id","col1","col2","col3","col4")
val arr = Seq((Array("1163903","1135067","1136137","1873","1130327","1879","86684","66284","1652","1128385"),Array("3.7049873","3.0849733", "3.415591","2.6446266","3.85075","2.7091007","4.414381","3.3164778","3.0772924","4.321163"),Array("3.8597548","4.1883473","3.12623","3.9076807","4.857642","3.8000894","3.9849327","4.774783","3.4006166","3.835489"),Array("1.6563705","1.6097081","1.7889535","2.0752525","2.192937","2.0292222","","1.9173387","1.7305527"),Array("3.6857932","3.190083","1.990814","2.319732","3.3546507","2.370629","","3.1792257","2.9725764")))
val df = sc.parallelize(arr).toDF( columnNames: _*)
df.printSchema
df.show
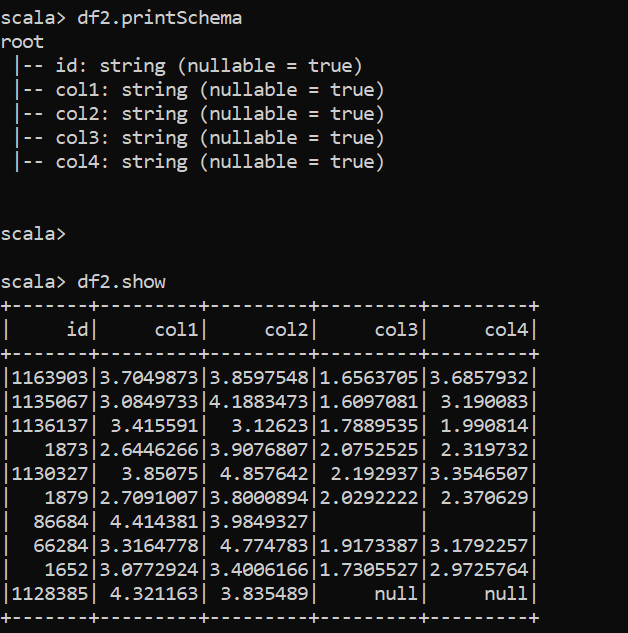
// 使用arrays_zip 和explode 函式來得到你想要的結果,如下所示
val df2 = df.withColumn("newCol",arrays_zip(col("id"),col("col1"),col("col2"),col("col3"),col("col4"))).withColumn("newCol",explode(col("newCol"))).selectExpr("newCol.id as id", "newCol.col1 as col1", "newCol.col2 as col2", "newCol.col3 as col3", "newCol.col4 as col4")
df2.printSchema
df2.show
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/440176.html
標籤:数组 斯卡拉 阿帕奇火花 apache-spark-sql
下一篇:在Scala中對集合值求和