我有這個資料框:
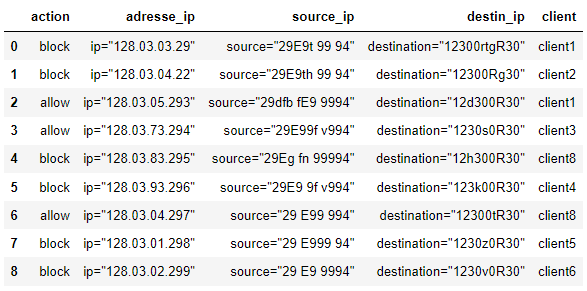
我想在 Block 動作和 Alow 動作中提取客戶端同時存在的行,所以我想要這些行:0、2、4 和 6。
使用行索引的解決方案,我不能使用它,因為我有數百萬行。
uj5u.com熱心網友回復:
如果action列僅包含、阻止和允許值,您可以在client那時對資料框進行分組,計算唯一操作的數量。
例如:
df.groupby("client")["action"].nunique()
如果提取的值大于 1,則特定客戶端同時擁有塊并允許值。
uj5u.com熱心網友回復:
使用groupby,filter和nunique:
indexes = df.groupby('client')['action'].filter(lambda x: x.nunique() >= 2).index
filtered = df.loc[indexes]
輸出:
>>> indexes.tolist()
[0, 2, 4, 6]
>>> filtered
action client
0 block client1
2 allow client1
4 block client8
6 allow client8
uj5u.com熱心網友回復:
這是您的問題的答案,它主要依賴于 Python 邏輯而不是 Pandas 邏輯。
它還包括timeit與主要基于 Pandas 的方法的性能比較,這似乎表明對于超過 100,000 行的所選示例,Python 邏輯的速度要快 50 倍以上。
import pandas as pd
# Sample data
n = 100000
recordData = [['allow' if i < n // 2 else 'block', 'ip="128.03.03.29"', 'source="29E9t 99 94"', 'destination="12300rtgR30"', 'client' f'{i}'] for i in range(n)]
nDual = 20000
recordData = [['block'] recordData[i % n][1:] for i in range(1, 7 * nDual 1, 7)]
df = pd.DataFrame(data=recordData, columns=['action', 'adresse_ip', 'source_ip', 'destin_ip', 'client'])
print(f"Sample dataframe of length {len(df)}:")
print(df)
import timeit
def foo(df):
# Selection
blocks = {*list(df['client'][df['action'] == 'block'])}
allows = {*list(df['client'][df['action'] == 'allow'])}
duals = blocks & allows
rowsWithDuals = df[df['client'].apply(lambda x: x in duals)]
# Diagnostics
print(f"Number of rows for clients with dual actions: {len(rowsWithDuals)}")
return rowsWithDuals
print("\nPrimarily Python approach:")
t = timeit.timeit(lambda: foo(df), number = 1)
print(f"timeit: {t}")
def bar(df):
indexes = df.groupby('client')['action'].filter(lambda x: x.nunique() >= 2).index
filtered = df.loc[indexes]
print(f"Number of rows for clients with dual actions: {len(filtered)}")
return filtered
print("\nPrimarily Pandas approach:")
t = timeit.timeit(lambda: bar(df), number = 1)
print(f"timeit: {t}")
輸出是:
Sample dataframe of length 120000:
action adresse_ip source_ip destin_ip client
0 allow ip="128.03.03.29" source="29E9t 99 94" destination="12300rtgR30" client0
1 allow ip="128.03.03.29" source="29E9t 99 94" destination="12300rtgR30" client1
2 allow ip="128.03.03.29" source="29E9t 99 94" destination="12300rtgR30" client2
3 allow ip="128.03.03.29" source="29E9t 99 94" destination="12300rtgR30" client3
4 allow ip="128.03.03.29" source="29E9t 99 94" destination="12300rtgR30" client4
... ... ... ... ... ...
119995 block ip="128.03.03.29" source="29E9t 99 94" destination="12300rtgR30" client39966
119996 block ip="128.03.03.29" source="29E9t 99 94" destination="12300rtgR30" client39973
119997 block ip="128.03.03.29" source="29E9t 99 94" destination="12300rtgR30" client39980
119998 block ip="128.03.03.29" source="29E9t 99 94" destination="12300rtgR30" client39987
119999 block ip="128.03.03.29" source="29E9t 99 94" destination="12300rtgR30" client39994
[120000 rows x 5 columns]
Primarily Python approach:
Number of rows for clients with dual actions: 25714
timeit: 0.04522189999988768
Primarily Pandas approach:
Number of rows for clients with dual actions: 25714
timeit: 3.1578059000021312
這似乎表明主要使用 Python(不是 Pandas)方法對于大型資料集更可取。
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/443594.html
上一篇:使用for回圈將std,mean列附加到DataFrame
下一篇:基于另一列條件的列日志