如何去除相應最大值/最小值之間的較小最大值和較大最小值?我總是希望最大值跟隨最小值,反之亦然,最小值跟隨最大值。
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from scipy.signal import argrelextrema
# Generate a noisy AR(1) sample
np.random.seed(0)
rs = np.random.randn(200)
xs = [0]
for r in rs:
xs.append(xs[-1] * 0.9 r)
df = pd.DataFrame(xs, columns=['data'])
n = 5 # number of points to be checked before and after
# Find local peaks
df['min'] = df.iloc[argrelextrema(df.data.values, np.less_equal,
order=n)[0]]['data']
df['max'] = df.iloc[argrelextrema(df.data.values, np.greater_equal,
order=n)[0]]['data']
# Plot results
plt.scatter(df.index, df['min'], c='r')
plt.scatter(df.index, df['max'], c='g')
plt.plot(df.index, df['data'])
plt.show()
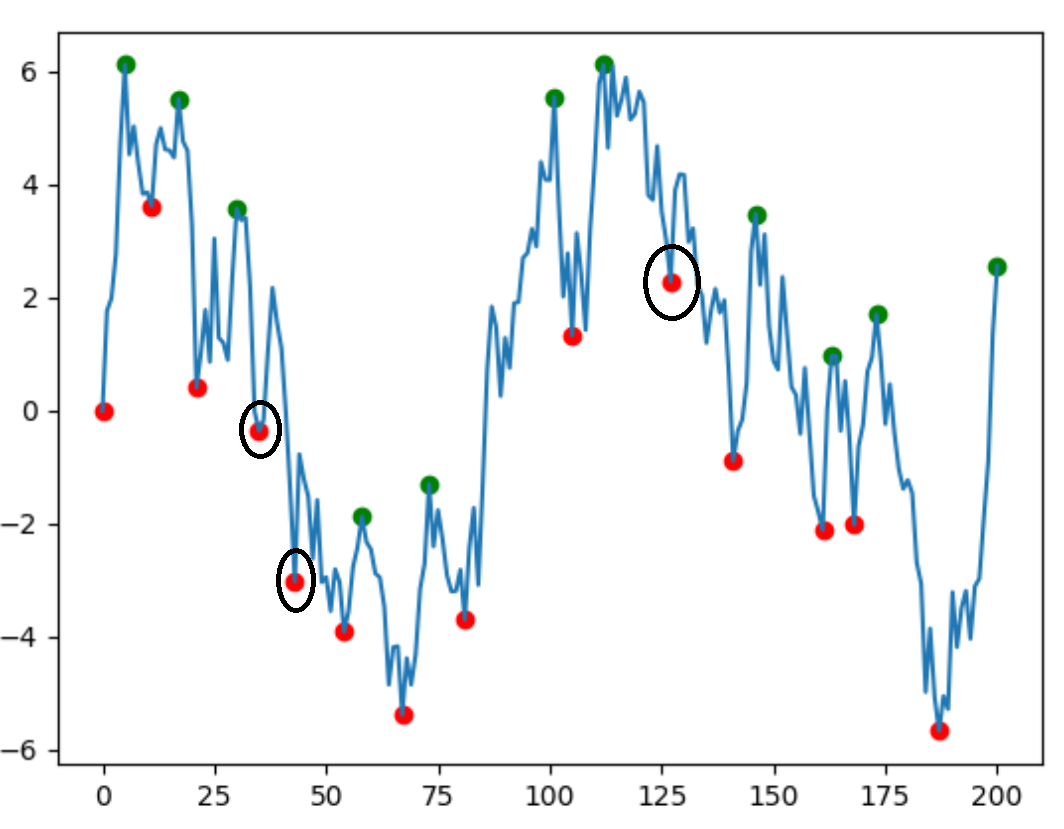
uj5u.com熱心網友回復:
你可以做這樣的事情。我們將 df 分組為連續最大值之間的部分,然后對于每個部分只取最小的最小值。然后我們按 min 分組,只為每個部分取最高的 max:
max_grouper = (~df['max'].isna()).cumsum()
df['min2'] = (df.groupby(max_grouper, group_keys = False)
.apply (lambda g: g['min'].where(g['min'] == g['min'].min()))
)
min_grouper = (~df['min2'].isna()).cumsum()
df['max2'] = (df.groupby(min_grouper, group_keys = False)
.apply (lambda g: g['max'].where(g['max'] == g['max'].max()))
)
我將“修剪”的最小值和最大值放入“min2”和“max2”列。我們使用黃色和藍色繪制它們,同時保留原始的紅色和綠色:
plt.scatter(df.index, df['min'], c='r')
plt.scatter(df.index, df['max'], c='g')
plt.scatter(df.index, df['min2'], c='y')
plt.scatter(df.index, df['max2'], c='b')
plt.plot(df.index, df['data'])
plt.show()
輸出:
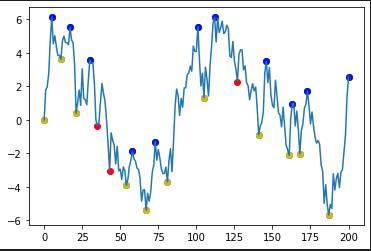
紅色的是“min2”中不存在的那些。在這種情況下,沒有洗掉“最大”點
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/443600.html