為了可視化,我需要按每個 x 唯一值對長格式 DataFrame 進行切片。我的實際資料集有 20 個個體的約 90 個變數,所以我想分成 9 個單獨的 df,其中包含每個變數的所有 20 個個體的條目。
我創建了這個簡單的示例來幫助解釋:
df = pd.DataFrame({'ID':[1,1,1,2,2,2,3,3,3,4,4,4],
'Period':[1,2,3,1,2,3,1,2,3,1,2,3,],
'Food':['Ham','Ham','Ham','Cheese','Cheese','Cheese','Egg','Egg','Egg','Bacon','Bacon','Bacon',]})
df
''' ******* PSUEDOCODE *******
df1 = unique entries [:2]
df2 = unique entries [2:4] '''
# desired outcome:
df1 = pd.DataFrame({'ID':[1,1,1,2,2,2,],
'Period':[1,2,3,1,2,3,],
'Food':['Ham','Ham','Ham','Cheese','Cheese','Cheese',]})
df2 = pd.DataFrame({'ID':[3,3,3,4,4,4],
'Period':[1,2,3,1,2,3,],
'Food':['Egg','Egg','Egg','Bacon','Bacon','Bacon',]})
print(df1)
print(df2)
在這種情況下,DataFrame 將在df['Food']列中每 2 組唯一條目的末尾拆分以創建df1和df2。最好的情況是為每 x 個唯一條目創建一個新 DataFrame 的回圈。鑒于缺乏我能找到的資訊,不幸的是,我正在努力為此撰寫好的偽代碼。
uj5u.com熱心網友回復:
可能的解決方案如下:
import pandas as pd
df = pd.DataFrame({'ID':[1,1,1,2,2,2,3,3,3,4,4,4],
'Period':[1,2,3,1,2,3,1,2,3,1,2,3,],
'Food':['Ham','Ham','Ham','Cheese','Cheese','Cheese','Egg','Egg','Egg','Bacon','Bacon','Bacon',]})
dfs = [y for x, y in df.groupby('Food', as_index=False)]
可以通過串列索引(見下文)或使用回圈訪問分隔的 dfs:
dfs[0]
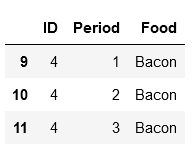
dfs[1]
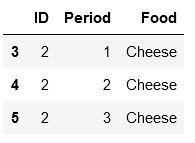
and etc.
uj5u.com熱心網友回復:
讓我們嘗試factorize一下groupby
n = 2
d = {x : y for x , y in df.groupby(df.Food.factorize()[0]//n)}
d[0]
Out[132]:
ID Period Food
0 1 1 Ham
1 1 2 Ham
2 1 3 Ham
3 2 1 Cheese
4 2 2 Cheese
5 2 3 Cheese
d[1]
Out[133]:
ID Period Food
6 3 1 Egg
7 3 2 Egg
8 3 3 Egg
9 4 1 Bacon
10 4 2 Bacon
11 4 3 Bacon
uj5u.com熱心網友回復:
我們可以使用groupby ngroup創建floordiv組;然后用另一個groupby來分開:
out = [x for _, x in df.groupby(df.groupby('Food', sort=False).ngroup().floordiv(2))]
輸出:
[ ID Period Food
0 1 1 Ham
1 1 2 Ham
2 1 3 Ham
3 2 1 Cheese
4 2 2 Cheese
5 2 3 Cheese,
ID Period Food
6 3 1 Egg
7 3 2 Egg
8 3 3 Egg
9 4 1 Bacon
10 4 2 Bacon
11 4 3 Bacon]
uj5u.com熱心網友回復:
據我了解,這可能會有所幫助:
for x in df['ID'].unique():
print(df[df['ID']==x], '\n')
for x in df['Food'].unique():
print(df[df['Food']==x], '\n')
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/444443.html
上一篇:根據作為引數接收的值轉換數字
下一篇:使用過濾器合并Pandas