我正在嘗試創建一個接受多重替換的字串替換器。
想法是它將掃描字串以查找子字串并將這些子字串替換為另一個子字串。
例如,我應該能夠要求它將每個“foo”替換為“bar”。這樣做是微不足道的。
當我嘗試為此功能添加多個替換時,問題就開始了。因為如果我要求它將“foo”替換為“bar”,將“bar”替換為“biz”,按順序運行這些替換將導致“foo”變為“biz”,而這種行為是無意的。
我嘗試將字串拆分為單詞并在每個單詞中運行每個替換函式。但是,這也不是防彈的,因為仍然會導致意外行為,因為您可以要求它替換不是整個單詞的子字串。另外,我發現這非常低效。
我正在考慮以某種方式在整個字串中運行每個替換器一次,然后存盤這些更改并合并它們。但是我認為我過度設計了。
在網上搜索給了我關于如何將 string.replace 與正則運算式一起使用的微不足道的結果,它并沒有解決我的問題。
這是一個已經解決的問題嗎?是否有一種演算法可以在這里有效地用于這種字串操作?
uj5u.com熱心網友回復:
如果在搜索要替換的所有出現的子字串時修改字串,最終會修改字串的不正確狀態。一個簡單的方法可能是首先獲取所有要更新的索引的串列,然后遍歷索引并進行替換。這樣,索引"bar"就已經計算過了,即使您"bar"稍后替換任何子字串也不會受到影響。
添加一個粗略的 Python 實作給你一個想法:
import re
string = "foo bar biz"
replacements = [("foo", "bar"), ("bar", "biz")]
replacement_indexes = []
offset = 0
for item in replacements:
replacement_indexes.append([m.start() for m in re.finditer(item[0], string)])
temp = list(string)
for i in range(len(replacement_indexes)):
old, new, indexes = replacements[i][0], replacements[i][1], replacement_indexes[i]
for index in indexes:
temp[offset index:offset index len(old)] = list(new)
offset = len(new)-len(old)
print(''.join(temp)) # "bar biz biz"
uj5u.com熱心網友回復:
這是我將采取的方法。
我從我的文本和替換集開始:
string text = "alpha foo beta bar delta";
Dictionary<string, string> replacements = new()
{
{ "foo", "bar" },
{ "bar", "biz" },
};
現在,我創建了一組“打開”或不“打開”的部件。打開的部分可以替換其文本。
var parts = new List<(string text, bool open)>
{
(text: text, open: true)
};
現在我遍歷每個更換并建立一個新的零件清單。如果零件是打開的,我可以進行更換,如果它是關閉的,只需將其原封不動地添加。正是這最后一點防止了替換的雙重映射。
以下是主要邏輯:
foreach (var replacement in replacements)
{
var parts2 = new List<(string text, bool open)>();
foreach (var part in parts)
{
if (part.open)
{
bool skip = true;
foreach (var split in part.text.Split(new[] { replacement.Key }, StringSplitOptions.None))
{
if (skip)
{
skip = false;
}
else
{
parts2.Add((text: replacement.Value, open: false));
}
parts2.Add((text: split, open: true));
}
}
else
{
parts2.Add(part);
}
}
parts = parts2;
}
這會產生以下結果:
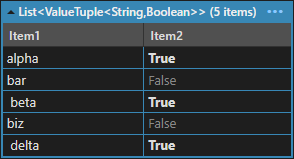
現在只需要重新加入備份:
string result = String.Concat(parts.Select(p => p.text));
這給出了:
alpha bar beta biz delta
按照要求。
uj5u.com熱心網友回復:
假設您給定的字串是
str = "Mary had fourteen little lambs"
并且所需的替換由以下哈希(又名哈希圖)給出:
h = { "Mary"=>"Butch", "four"=>"three", "little"=>"wee", "lambs"=>"hippos" }
表示我們想用 替換"Mary"(無論它出現在字串中的什么位置,如果有的話)"Butch",依此類推。因此,我們希望回傳以下字串:
"Butch had fourteen wee hippos"
請注意,我們不想'fourteen'被替換為' 并且我們希望保留和'threeteen之間的額外空格。'fourteen''wee'
首先將散列的鍵收集h到一個陣列(或串列)中:
keys = h.keys
#=> ["Mary", "four", "little", "lambs"]
大多數語言都有一個方法或函式,sub或者gsub像下面這樣作業:
str.gsub(/\w /) do |word|
if keys.include?(word)
h[word]
else
word
end
end
#=> "Butch had fourteen wee hippos"
正則運算式/\w /(r'\w '例如在 Python 中)盡可能多地匹配一個或多個單詞字符(即貪婪匹配)。單詞字符是字母、數字和下劃線 ( '_')。因此,它將依次匹配'Mary'、'had'、和。'fourteen''little''lambs'
每個匹配的單詞都被傳遞給“塊”do |word| ...end并由變數保存word。塊計算然后計算并回傳要替換word原始字串副本中的值的字串。當然,不同的語言使用不同的結構和格式來做到這一點。
傳遞給塊的第一個單詞gsub是'Mary'。然后執行以下計算:
if keys.include?("Mary") # true
# so replace "Mary" with:
h[word] #=> "Butch
else # not executed
# not executed
end
Next, gsub passes the word 'had' to the block and assigns that string to the variable word. The following calculation is then performed:
if keys.include?("had") # false
# not executed
else
# so replace "had" with:
"had"
# that is, leave "had" unchanged
end
Similar calculations are made for each word matched by the regular expression.
We see that punctuation and other non-word characters is not a problem:
str = "Mary, had fourteen little lambs!"
str.gsub(/\w /) do |word|
if keys.include?(word)
h[word]
else
word
end
end
#=> "Butch, had fourteen wee hippos!"
We can see that gsub does not perform replacements sequentially:
h = { "foo"=>"bar", "bar"=>"baz" }
keys = h.keys
#=> ["foo", "bar"]
"foo bar".gsub(/\w /) do |word|
if keys.include?(word)
h[word]
else
word
end
end
#=> "bar baz"
Note that a linear search of keys is required to evaluate
keys.include?("Mary")
This could be relatively time-consuming if keys has many elements.
In most languages this can be sped up by making keys a set (an unordered collection of unique elements). Determining whether a set contains a given element is quite fast, comparable to determining if a hash has a given key.
An alternative formulation is to write
str.gsub(/\b(?:Mary|four|little|lambs)\b/) { |word| h[word] }
#=> "Butch had fourteen wee hippos"
where the regular expression is constructed programmatically from h.keys. This regular expression reads, "match one of the four words indicated, preceded and followed by a word boundary (\b). The trailing word boundary prevents 'four' from matching 'fourteen'. Since gsub is now only considering the replacement of those four words the block can be simplified to { |word| h[word] }.
Again, this preserves punctuation and extra spaces.
If for some reason we wanted to be able to replace parts of words (e.g., to replace 'fourteen' with 'threeteen'), simply remove the word boundaries from the regular expression:
str.gsub(/Mary|four|little|lambs/) { |word| h[word] }
#=> "Butch had threeteen wee hippos"
Naturally, different languages provide variations of this approach. In Ruby, for example, one could write:
g = Hash.new { |h,k| k }.merge(h)
The creates a hash g that has the same key-value pairs as h but has the additional property that if g does not have a key k, g[k] (the value of key k) returns k. That allows us to write simply:
str.gsub(/\w /, g)
#=> "Butch had fourteen wee hippos"
See the second version of String#gsub.
A different approach (which I will show is problematic) is to construct an array (or list) of words from the string, replace those words as appropriate and then rejoin the resulting words to form a string. For example,
words = str.split
#=> ["Mary", "had", "fourteen", "little", "lambs"]
arr = words.map do |word|
if keys.include?(word)
h[word]
else
word
end
end
["Butch", "had", "fourteen", "wee", "hippos"]
arr.join(' ')
#=> "Butch had fourteen wee hippos"
This produces similar results except the extra spaces have been removed.
Now suppose the string contained punctuation:
str = "Mary, had fourteen little lambs!"
words = str.split
#=> ["Mary,", "had", "fourteen", "little", "lambs!"]
arr = words.map do |word|
if keys.include?(word)
h[word]
else
word
end
end
#=> ["Mary,", "had", "fourteen", "wee", "lambs!"]
arr.join(' ')
#=> "Mary, had fourteen wee lambs!"
We could deal with punctuation by writing
words = str.scan(/\w /)
#=> ["Mary", "had", "fourteen", "little", "lambs"]
arr = words.map do |word|
if keys.include?(word)
h[word]
else
word
end
end
#=> ["Butch", "had", "fourteen", "wee", "hippos"]
這里str.scan回傳一個包含正則運算式的所有匹配項/\w /(一個或多個單詞字符)的陣列。明顯的問題是所有標點符號都丟失了arr.join(' ')。
uj5u.com熱心網友回復:
您可以通過使用正則運算式以簡單的方式實作:
import re
replaces = {'foo' : 'bar', 'alfa' : 'beta', 'bar': 'biz'}
original_string = 'foo bar, alfa foo. bar other.'
expected_string = 'bar biz, beta bar. biz other.'
replaced = re.compile(r'\w ').sub(lambda m: replaces[m.group()] if m.group() in replaces else m.group(), original_string)
assert replaced == expected_string
我還沒有檢查過性能,但我相信它可能比使用“嵌套 for 回圈”更快。
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/446397.html
上一篇:如何更改C中的函式引數?
下一篇:基于柏林噪聲的點隨機分布?