我試圖了解在分析基因表達資料時如何使用線性建模作為 t 檢驗的替代方法。對于單個基因,我在第 1 組(n=10)和第 2 組(n=10)中共有 20 個基因表達值的資料框。
gexp = data.frame(expression = c(2.7,0.4,1.8,0.8,1.9,5.4,5.7,2.8,2.0,4.0,3.9,2.8,3.1,2.1,1.9,6.4,7.5,3.6,6.6,5.4),
group = c(rep(1, 10), rep(2, 10)))
資料可以使用ggplot如下所示(框)繪制:
plot <- gexp %>%
ggplot(aes(x = group, y = expression))
geom_boxplot()
geom_point()
plot
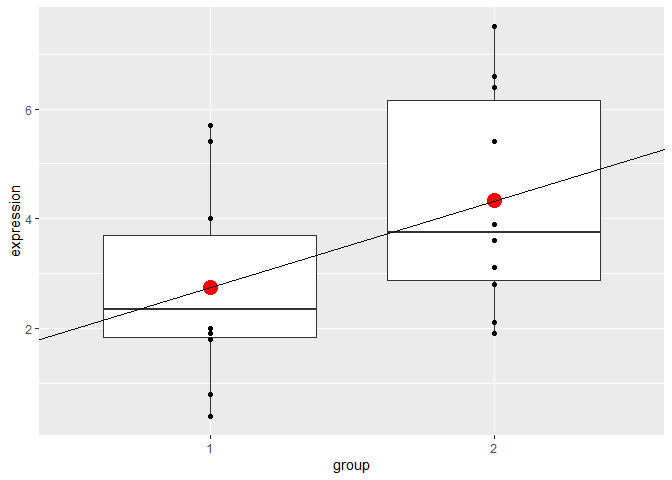
我希望使用回歸公式對第 1 組和第 2 組中的運算式進行建模:Y = Beta0 (Beta1 x X) e 其中 Y 是我要建模的運算式,X 表示分別編碼為 0 和 1 的兩組. 因此,組 1 中的運算式(當 x = 0 時)等于 Beta0;第 2 組中的運算式(當 x = 1 時)等于 Beta0 Beta1。如果這是建模的:
mod1 <- lm(expression ~ group, data = gexp)
mod1
上面的代碼輸出截距為 2.75,斜率為 1.58。我不明白的是線性模型的可視化。我將不勝感激以下代碼的清晰解釋:
plot
geom_point(data = data.frame(x = c(1, 2), y = c(2.75, 4.33)),
aes(x = x, y = y),
colour = "red", size = 5)
geom_abline(intercept = coefficients(mod1)[1] - coefficients(mod1)[2],
slope = coefficients(mod1)[2])
我明白為什么data.frame選擇這些值(4.33 的值是截距 Beta0 和斜率 Beta1 的總和),但這是geom_abline我不明白的論點。為什么截距計算如圖所示?在我使用它的文本中,' ...我們需要在繪制線性模型時從截距中減去斜率,因為第 1 組和第 2 組在模型中被編碼為 0 和 1,但在數字。' 我不遵循這一點,并會感謝您的解釋,但不會過于技術化。
uj5u.com熱心網友回復:
group如果變數被編碼為一個因素,我相信你的代碼是正確的。
library(ggplot2)
gexp = data.frame(expression = c(2.7,0.4,1.8,0.8,1.9,5.4,5.7,2.8,2.0,4.0,3.9,2.8,3.1,2.1,1.9,6.4,7.5,3.6,6.6,5.4),
group = factor(c(rep(1, 10), rep(2, 10))))
plot <-
ggplot(gexp, aes(x = group, y = expression))
geom_boxplot()
geom_point()
mod1 <- lm(expression ~ group, data = gexp)
plot
geom_point(data = data.frame(x = c(1, 2), y = c(2.75, 4.33)),
aes(x = x, y = y),
colour = "red", size = 5)
geom_abline(intercept = coefficients(mod1)[1] - coefficients(mod1)[2],
slope = coefficients(mod1)[2])
由reprex 包創建于 2022-03-30 (v2.0.1)
要了解指定線性模型時因子和整數之間的區別,您可以查看模型矩陣。
model.matrix(y ~ f, data = data.frame(f = 1:3, y = 1))
#> (Intercept) f
#> 1 1 1
#> 2 1 2
#> 3 1 3
#> attr(,"assign")
#> [1] 0 1
model.matrix(y ~ f, data = data.frame(f = factor(1:3), y = 1))
#> (Intercept) f2 f3
#> 1 1 0 0
#> 2 1 1 0
#> 3 1 0 1
#> attr(,"assign")
#> [1] 0 1 1
#> attr(,"contrasts")
#> attr(,"contrasts")$f
#> [1] "contr.treatment"
由reprex 包創建于 2022-03-30 (v2.0.1)
In the first model matrix, what you specify is what you get: you're modelling something as a function of the intercept and the f variable. In this model, you account for that f = 2 is twice as much as f = 1.
This works a little bit differently when f is a factor. A k-level factor gets split up in k-1 dummy variables, where each dummy variable encodes with 1 or 0 whether it deviates from the reference level (the first factor level). By modelling it in this way, you don't consider that the 2nd factor level might be twice the 1st factor level.
Because in ggplot2, the first factor level is displayed at position = 1 and not at position = 0 (how it is modelled), your calculated intercept is off. You need to subtract 1 * slope from the calculated intercept to get it to display right in ggplot2.
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/452994.html