我在決議檔案時遇到問題。我的代碼通過 Total: if its value 大于 20.0 來決議檔案并回傳資料。我需要將搜索關鍵字更改為 Tokens eth: 值大于 20.0 并輸出分隔符 ======== 之間的所有資料,另外將所有排序值寫入 sort.txt 檔案。如果有專業的幫助,我將不勝感激)
代碼:
outlist = []
flag = False
def dump(list_, flag_):
if list_ and flag_:
print('\n'.join(list_))
return [], False
with open('total.txt') as file:
for line in map(str.strip, file):
if line.startswith('='):
outlist, flag = dump(outlist, flag)
else:
tokens = line.split()
if len(tokens) == 3 and tokens[1] == 'Total:':
try:
flag = float(tokens[2][:-1]) > 20.0
except ValueError:
pass
outlist.append(line)
dump(outlist, flag)
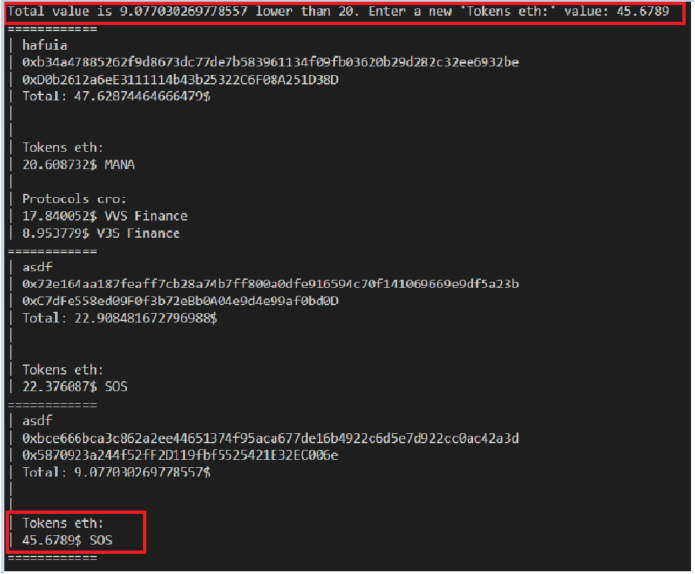
總計.txt
============
| hafuia
| 0xb34a47885262f9d8673dc77de7b583961134f09fb03620b29d282c32ee6932be
| 0xD0b2612a6eE3111114b43b25322C6F08A251D38D
| Total: 47.62874464666479$
|
|
| Tokens eth:
| 20.608732$ MANA
|
| Protocols cro:
| 17.840052$ VVS Finance
| 8.953779$ V3S Finance
============
| asdf
| 0x72e164aa187feaff7cb28a74b7ff800a0dfe916594c70f141069669e9df5a23b
| 0xC7dFe558ed09F0f3b72eBb0A04e9d4e99af0bd0D
| Total: 22.908481672796988$
|
|
| Tokens eth:
| 22.376087$ SOS
============
| asdf
| 0xbce666bca3c862a2ee44651374f95aca677de16b4922c6d5e7d922cc0ac42a3d
| 0x5870923a244f52fF2D119fbf5525421E32EC006e
| Total: 9.077030269778557$
|
|
| Tokens eth:
| 8.942218$ SOS
============
uj5u.com熱心網友回復:
這就是您可以決議檔案的方式。
def parse_output(filename):
outlist = []
with open(filename) as file:
new_block = False
to_write = False
lines_arr = []
for line in map(str.strip, file):
if line.startswith('======='):
new_block = not new_block
if new_block:
if to_write:
outlist.append(lines_arr)
lines_arr = []
new_block = False
to_write = False
else:
lines_arr.append(line)
if 'Total:' in line:
num = float(line.split()[-1][:-1])
if num > 20:
to_write = True
return outlist
def write_output(outlist, filename):
for block in outlist:
for line in block:
with open(filename, 'a') as out_file:
out_file.write(line '\n')
with open(filename, 'a') as out_file:
out_file.write('=======' '\n')
if __name__ == '__main__':
write_output(parse_output('total.txt'), 'output.txt')
我錯過了分類錢包的事情。對于排序,在將陣列附加到 outlist 時,您可以使用另一個陣列進行排序,或者將數字添加到陣列中,對輸出進行排序,并在寫入時跳過第一個元素。
uj5u.com熱心網友回復:
這寫的方式很容易得到fe。地址也是如此。使用簡單的 lambda 函式進行排序。
from pprint import pprint
wallet_splitter = "============"
wallet_content_start = "Tokens eth:"
wallet_line_start = "|"
with open("totals.txt") as infile:
wallets = infile.read().split(wallet_splitter)
print(wallets)
wallets_above_20 = []
for wallet in wallets:
total = 0
separate = []
contents = False
for line in wallet.splitlines():
if wallet_content_start in line:
contents = True
elif contents:
if "$" in line:
separate.append(line.replace(wallet_line_start, "").split("$")[0])
total = float(separate[-1])
else:
contents = False
for amount in separate:
if float(amount) > 20:
wallets_above_20.append({
"total": total,
"data": wallet
})
pprint(sorted(wallets_above_20, key = lambda i: i['total'],reverse=True))
uj5u.com熱心網友回復:
這是另一種簡單的可擴展方法,您可以使用它來實作您所需要的。注釋將解釋代碼。
# Create a simple representational object with data for every record.
class RateObject:
# You can change the delimiter to whatever you want.
def __init__(self, text_lines: list, delimiter="Tokens eth:"):
self.text_lines = text_lines
index = [i for i, x in enumerate(text_lines) if delimiter in x][0]
# Get the value from delimiter line
self.value = self._get_value(index)
# Override this method, to change the way you extract the value. From same line or different line etc.
def _get_value(self, delimiter_index: int):
# Case of Tokens eth:
value = self.text_lines[delimiter_index 1]
value = value.strip()
# A bad parsing for numbers, can be improved may be!
number = "".join([x for x in value if x.isdigit() or x == "."])
if number:
return float(number)
else:
# Assume 0 for unknown values
return 0.0
def __str__(self):
# Return the lines as it is
return "".join(self.text_lines)
def __repr__(self):
return "".join(self.text_lines)
# read the source file
with open("src.txt", "r") as src:
line_texts = src.readlines()
# Split the lines into sections, using the delimiter ========
splitters = [index for index, text in enumerate(line_texts) if text == "============\n"]
# Create a list of RateObjects
raw_objects = [RateObject(lt) for lt in [line_texts[splitters[i]:splitters[i 1]] for i in range(len(splitters) - 1)]]
# Filter the objects, to get only the ones with value > 20
selected_objects = list(filter(lambda x: x.value > 20.0, raw_objects))
# Sort the objects by value
sorted_objects = sorted(selected_objects, key=lambda x: x.value, reverse=True)
# print(selected_objects)
# print(sorted_objects)
# Write the sorted objects to a file
with open("sorted.txt", "w") as dst:
dst.write("\n".join([str(x) for x in sorted_objects]))
uj5u.com熱心網友回復:
這是一個簡單的基于生成器的方法。
def items(file):
"""
Generator to yield items from filename
whose "Tokens eth:" is above 20.0
"""
with open(file) as lines:
item = []
tokens = 0
capture = False
for line in lines:
if line == "============\n":
if tokens > 20.0:
yield tokens, item
item = []
tokens = 0
continue
if capture:
tokens = float(line.strip().split()[-2].rstrip("$"))
capture = False
if line.startswith("| Tokens eth:"):
# Set flag to capture next line when we get to it
capture = True
item.append(line)
def main():
import sys
print("============")
for tokens, item in sorted(list(items(sys.argv[1]))):
print("".join(item), end="")
print("============")
if __name__ == "__main__":
main()
為簡單起見,我讓生成器也執行過濾,但如果您想讓它可重用,在呼叫者一側洗掉總數較低的專案很容易。
演示:
查看代碼運行后的輸出。
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/458901.html
上一篇:File(".").getAbsolutePath()是如何在后臺解決的?
下一篇:C ,從檔案寫入地圖