我無法弄清楚如何在 python 中使用 matplotlib 將我的資料轉換為曲面圖的 X、Y 和 Z 軸。資料來自一個包含 5 個字母單詞串列的檔案,我的程式運行該檔案并計算每個字母在單詞的每個位置出現的次數。它存盤在 5 個不同的字典中,每個位置一個。我在想我必須使用 .keys() 和 .values() 方法,但我并不積極。
我進入了 excel 并制作了圖表來展示我正在嘗試做的事情的一個例子。
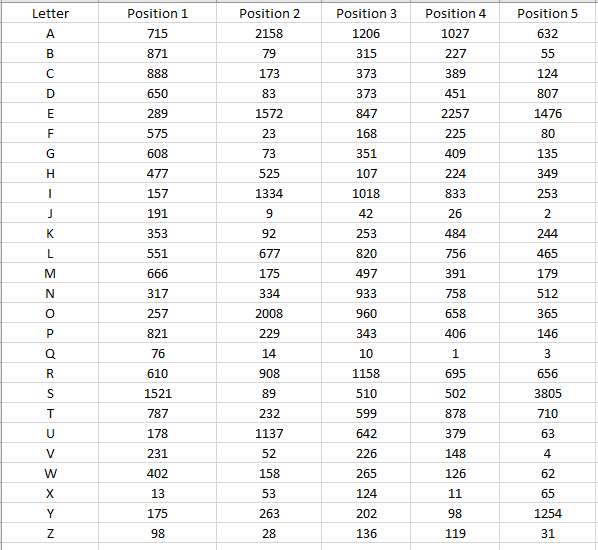
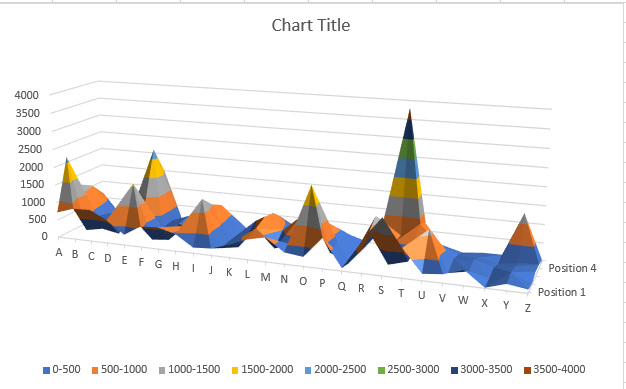
這是我到目前為止的代碼:
import string
import matplotlib.pyplot as plt
from mpl_toolkits import mplot3d
import numpy as np
#Creates a list of the alphabet in uppercase
alphabet = string.ascii_uppercase
letter_list = list(alphabet)
#Creates dictionary for lettercount. Keys = A-Z, Values = 0
lettercount = {i: 0 for i in letter_list}
#Creates dictonaries for position frequency. Keys = A-Z, Values = 0
position1_freq = {i: 0 for i in letter_list}
position2_freq = {i: 0 for i in letter_list}
position3_freq = {i: 0 for i in letter_list}
position4_freq = {i: 0 for i in letter_list}
position5_freq = {i: 0 for i in letter_list}
with open("answers.txt") as f:
for i in f:
i = i.rstrip()
for word in i.split(" "):
for letter in range(len(word)):
#Iterates through alphabet
for j in letter_list:
#If the letter in the word = j it will add 1 to lettercount and depending on what value the indicie letter is, 1 will be added to the proper position frequency
if word[letter] == j:
lettercount[j] = 1
if letter == 0:
position1_freq[j] = 1
if letter == 1:
position2_freq[j] = 1
if letter == 2:
position3_freq[j] = 1
if letter == 3:
position4_freq[j] = 1
if letter == 4:
position5_freq[j] = 1
#Sorts the lettercount dictionary to be high to low
sort_lettercount = sorted(lettercount.items(), key = lambda x: x[1], reverse= True)
fig = plt.figure()
ax = plt.axes(projection = '3d')
plt.show()
uj5u.com熱心網友回復:
這是一個完整的例子。我使用了串列和字典理解,因為它們在 python 中很常見(很好習慣!)和Counter標準庫中的類。因此,如果您不習慣代碼可能會有點難以閱讀,但這種風格在 python 中很常見,所以我建議學習它而不是使用顯式的 for 回圈。Counter物件是一種字典,因此可以將其視為字典。:)
然后我使用.values(). 計數器上的函式以提取結果。我將它放入一個 numpy 陣列中,因為這是 matplotlib 需要的。
最后,在 matplotlib 中創建 3d 圖有點做作。Matplotlib 對于分類資料(例如在 X 軸上有字母),也不適用于具有水平色帶的 3d 圖(例如在您的 excel 示例中)。
無論如何,這里是:
from string import ascii_uppercase
from collections import Counter
# a dictionary with all ascii lettters as keys, and only zeros as values
zero_counts = {c:0 for c in ascii_uppercase}
with open('answers.txt') as f:
# read the file into a list, remove trailing newlines and make sure all is uppercase
lines = [line.strip().upper() for line in f.readlines()]
# transpose the list, so that instead of having N 5-letter words, we now have 5 N-letter words
list_of_chars_per_pos = zip(*lines)
# for each of these 5 "words", count the number of occurrances of each letter
# then add these occurences into a copy of the "zero" dictionary from before
# so now we have 5 dictionaries holding the count for letter 0,1,2,3 and 4
char_counts_per_pos = [zero_counts | Counter(chars) for chars in list_of_chars_per_pos]
# matplotlib only works with numpy data structures, so lets change into that!
import numpy as np
x = np.arange(len(ascii_uppercase)) # the x axis will correspond to the letters
y = np.arange(5) # the y axis will be the positions
X,Y = np.meshgrid(x,y) # create 2D arrays with the X and Y coordinates
# here we extract the data from the dictionaries using the .values() method
Z = np.array([list(dictionary.values()) for dictionary in char_counts_per_pos])
# now create the plot! create 3d axes on a new figure and draw the plot
# there is quite a bit of customization that can be done to the plot to make it look
# in whatever way you like.
import matplotlib.pyplot as plt
from matplotlib.ticker import MaxNLocator, FixedLocator
fig = plt.figure()
ax = fig.add_subplot(projection='3d')
surf= ax.plot_surface(X=X,Y=Y,Z=Z)
ax.xaxis.set_major_locator(FixedLocator(x))
ax.set_xticklabels(ascii_uppercase)
ax.set_box_aspect((26,5,5))
ax.zaxis.set_major_locator(MaxNLocator(integer=True))
ax.set_zlabel("Counts")
ax.set_ylabel("Position")
# finally, show the plot. :)
plt.show()
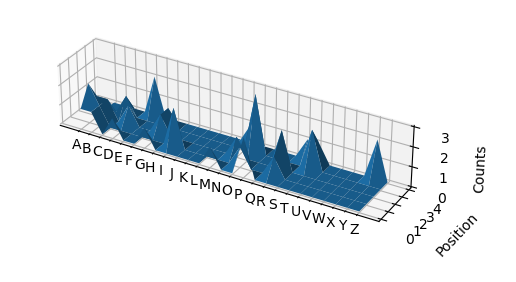
通過在以下文本檔案上運行它answers.txt
abbot
mince
grate
dodos
piggy
baron
party
我明白情節
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/461690.html
標籤:Python matplotlib