一、bash 基礎
1.變數累加
name=${name}yes #以此例較佳!
echo $a$b
2.上個執行指令的回傳值 echo $?
[dmtsai@study ~]# echo $SHELL
/bin/bash #可順利顯示!沒有錯誤!
[dmtsai@study ~]# echo $?
0 <#因為沒問題,所以回傳值為 0
[dmtsai@study ~]# 12name=VBird
bash: 12name=VBird: command not found... #發生錯誤了!bash回報有問題
[dmtsai@study ~]# echo $?
127 #因為有問題,回傳錯誤代碼(非為0)
*使用?判斷變數值
[root@localhost ddd]# unset str
[root@localhost ddd]# str=string1
[root@localhost ddd]# echo ${str}
string1 #此時能讀到
[root@localhost ddd]# unset str
[root@localhost ddd]# echo ${str?無此變數} #判斷是否有str,有則列印沒有則輸出;;使用echo ${str:-"不存在"}
-bash: str: 無此變數
#echo;在 Linux 下用 > 和 >> 表示,> 表示輸出到一個新檔案中,而 >> 則表示輸出到 現有檔案的末尾,
3.鍵盤讀取read
[dmtsai@study ~]# read [-spt] variable
選項與引數:
-p :后面可以接提示字符!
-t :后面可以接等待的“秒數!”這個比較有趣~不會一直等待使用者啦!
-s :隱藏鍵盤輸入
#eg:
[root@localhost ~]# read -p"input contents" -t10
input contents #-t默認30秒

4.declare / typeset
* declare/typeset
[dmtsai@study ~]# declare [-aixr] variable
選項與引數:
-a :將后面名為 variable 的變數定義成為陣列 (array) 型別
-i :將后面名為 variable 的變數定義成為整數數字 (integer) 型別
-x :用法與 export 一樣,就是將后面的 variable 變成環境變數;
-r :將變數設定成為 readonly 型別,該變數不可被更改內容,也不能 unset
范例一:讓變數 sum 進行 100+300+50 的加總結果
[dmtsai@study ~]# sum=100+300+50
[dmtsai@study ~]# echo ${sum}
100+300+50 以文本列印
[dmtsai@study ~]# declare -i sum=100+300+50
[dmtsai@study ~]# echo ${sum}
450 #-i以數字計算
5.與檔案系統及程式的限制關系: ulimit
#檔案太大無法在系統生成的問題:1.檢查ulimit 2.使用split進行檔案磁區 大檔案分成小檔案
[dmtsai@study ~]# ulimit [-SHacdfltu] [配額]
選項與引數:
-H :hard limit ,嚴格的設定,必定不能超過這個設定的數值;
-S :soft limit ,警告的設定,可以超過這個設定值,但是若超過則有警告訊息,
在設定上,通常 soft 會比 hard 小,舉例來說,soft 可設定為 80 而 hard
設定為 100,那么你可以使用到 90 (因為沒有超過 100),但介于 80~100 之間時,
系統會有警告訊息通知你!
-a :后面不接任何選項與引數,可列出所有的限制額度;
-c :當某些程式發生錯誤時,系統可能會將該程式在記憶體中的資訊寫成檔案(除錯用),
這種檔案就被稱為核心檔案(core file),此為限制每個核心檔案的最大容量,
-f :此 shell 可以創建的最大檔案大小(一般可能設定為 2GB)單位為 KBytes
-d :程式可使用的最大斷裂記憶體(segment)容量;
-l :可用于鎖定 (lock) 的記憶體量
-t :可使用的最大 CPU 時間 (單位為秒)
-u :單一使用者可以使用的最大程式(process)數量,
6.自定義命名 alias/unalias
alias lm='ls -al | less' #檔案多的情況下,可以分頁顯示*,也可以使用關鍵字搜索;但是*匹配也可以
7.history/HISTSIZE
history如何顯示時間、IP等資訊
[root@localhost a5_dtx]# HISTSIZE=5 #可以登出重新寫入.bash_profile 或者用history -w強制寫入
[root@localhost a5_dtx]# echo ${HISTSIZE}
5
[root@localhost a5_dtx]# history
700 echo ${HISTSIZE}
701 history
702 HISTSIZE=5
703 echo ${HISTSIZE}
704 history
8.關于行程被掛起
jobs -l #查看掛起行程
fg 關鍵字 #喚起行程,或者fg [NUM]
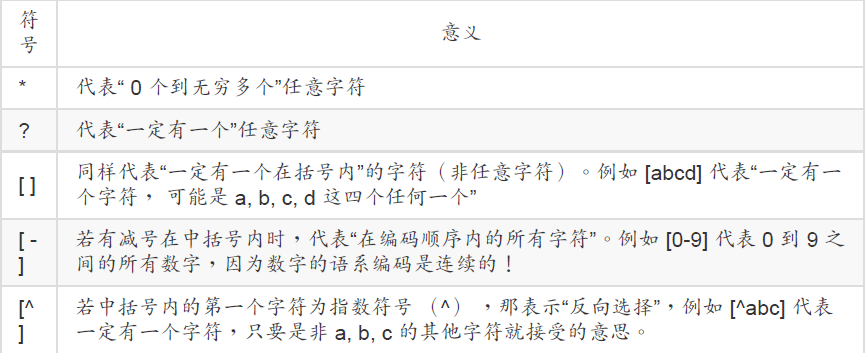
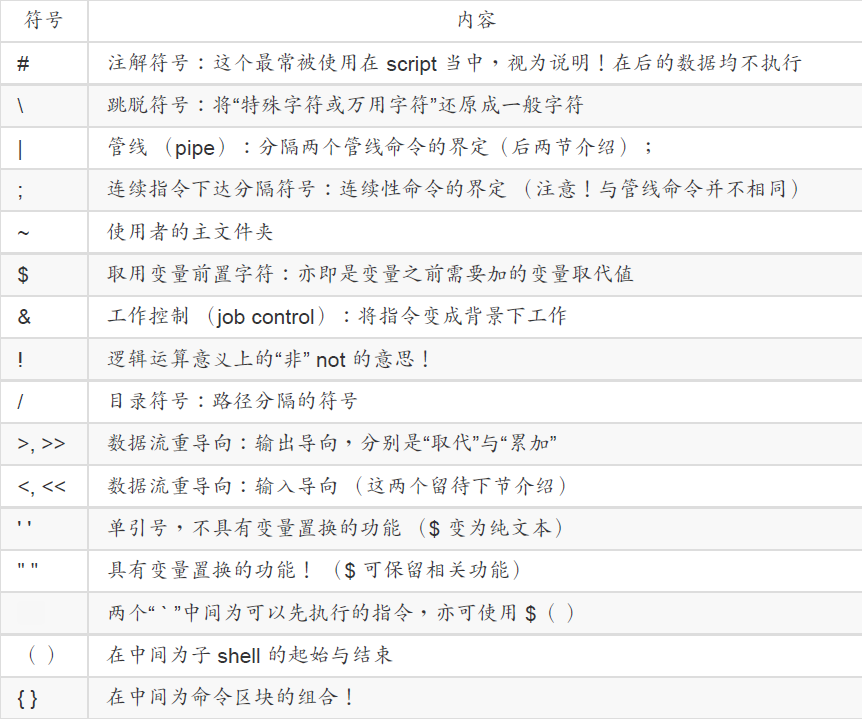
9.萬用字符(wildcard)與特殊符號
10.命令執行的判斷依據: ; , &&, ||
* cmd1;cmd2 不判斷直接執行
* cmd1&&cmd2 指令1正確($?=0)的情況下執行指令2;批量執行腳本神器 超級方便
* cmd1||cmd2 指令1正確則不執行指令2,指令1不正確則執行指令2
ls /etc/profile111 && echo "exist" || echo "not exist" && touch /etc/profile111
11.統計行數、字符等:wc
[dmtsai@study ~]# wc [-lwm]
選項與引數:
-l :僅列出行;
-w :僅列出多少字(英文單字);
-m :多少字符;
#eg1: 檢測是否存在mysql行程,存在回傳0,不存在回傳1
[root@localhost ddd]# ps aux|grep mysql|grep -v 'color' && echo "process mysql exist" || echo "process mysql not exist"
process mysql not exist
#eg2:檢測是否存在mysql行程,存在回傳1,不存在回傳0
[root@localhost ddd]# ps aux|grep mysql|grep -v 'color'|wc -l && echo "process mysql not exist" || echo "process mysql exist"
0
process mysql exist
12.快捷鍵補充
* ctrl+r:搜索歷史輸入命令 避免history的低效率
* ctrl+u/k:向前/后 洗掉指令串
* ctrl+a/e:代替home/end鍵,到指令串的最前或者最后
* ctrl+s/q:凍結/解凍前端
13.cut指令
[dmtsai@study ~]# cut -d'分隔字符' -f fields filename#用于有特定分隔字符
[dmtsai@study ~]# cut -c 字符區間 filename #用于排列整齊的訊息 對列處理
選項與引數:
-d :后面接分隔字符,與 -f 一起使用;
-f :依據 -d 的分隔字符將一段訊息磁區成為數段,用 -f 取出第幾段的意思;
-c :以字符 (characters) 的單位取出固定字符區間;
#eg:
[root@localhost ddd]# cat test.txt
1:2:3:4:5:6:a:b:c:d:e:f
[root@localhost ddd]# cat test.txt | cut -d ':' -f 2,3
2:3 #以:為分隔符,取出第2至3段;;;或者cut filename
[root@localhost ddd]# cat test.txt | cut -c 2-5
:2:3 #取出第2到5個的字符;2-表示取出第二個以及之后的字符
14.字符轉換命令: tr, col, join, paste, expand
# 目前使用頻率低 僅做記錄
[dmtsai@study ~]# tr [-ds] SET1 ...
選項與引數:
-d :洗掉訊息當中的 SET1 這個字串;
-s :取代掉重復的字符!
[dmtsai@study ~]# col [-xb]
選項與引數:
-x :將 tab 鍵轉換成對等的空白鍵
[dmtsai@study ~]# join [-ti12] file1 file2
選項與引數:
-t :join 默認以空白字符分隔資料,并且比對“第一個欄位”的資料,
如果兩個檔案相同,則將兩筆資料聯成一行,且第一個欄位放在第一個!
-i :忽略大小寫的差異;
-1 :這個是數字的 1 ,代表“第一個檔案要用那個欄位來分析”的意思;
-2 :代表“第二個檔案要用那個欄位來分析”的意思,
[dmtsai@study ~]# paste [-d] file1 file2
選項與引數:
-d :后面可以接分隔字符,默認是以 [tab] 來分隔的!
- :如果 file 部分寫成 - ,表示來自 standard input 的資料的意思,
[dmtsai@study ~]# expand [-t] file
選項與引數:
-t :后面可以接數字,一般來說,一個 tab 按鍵可以用 8 個空白鍵取代,
我們也可以自行定義一個 [tab] 按鍵代表多少個字符呢!
[dmtsai@study ~]# split [-bl] file PREFIX
選項與引數:
-b :后面可接欲磁區成的檔案大小,可加單位,例如 b, k, m 等;
-l :以行數來進行磁區,
PREFIX :代表前置字符的意思,可作為磁區檔案的前導文字,
15.管線命令(pipe)
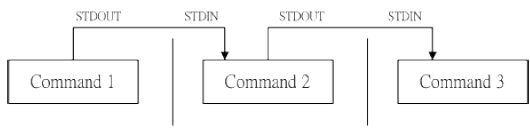
那么如果這群資料必需要經過幾道手續之后才能得到我們所想要的格式,應該如何來設定?
這就牽涉到管線命令的問題了 (pipe) ,管線命令使用的是“ | ”這個界定符號!
其實這個管線命令“ | ”僅能處理經由前面一個指令傳來的正確資訊,也就是 standard output 的資訊,對于 stdandard error 并沒有直接處理的能力,那么整體的管線命令可以使用下圖表示
16.引數代換: xargs
# 很多指令其實并不支持管線命令,可使用xargs以指引stdin
[dmtsai@study ~]# xargs [-0epn] command
選項與引數:
-0 :如果輸入的 stdin 含有特殊字符,例如 `, \, 空白鍵等等字符時,這個 -0 引數
可以將他還原成一般字符,這個引數可以用于特殊狀態喔!
-e :這個是 EOF (end of file) 的意思,后面可以接一個字串,當 xargs 分析到這個字串時,
就會停止繼續作業!
-p :在執行每個指令的 argument 時,都會詢問使用者的意思;
-n :后面接次數,每次 command 指令執行時,要使用幾個引數的意思,
當 xargs 后面沒有接任何的指令時,默認是以 echo 來進行輸出喔!
ps -ef | grep java | grep -v "grep" | awk '{print $2}' | xargs kill
17.關于減號的用途:-
[root@localhost ddd]# tar zcvf - test.txt | tar zxvf - mysql
#將test.txt打包,但是不是記錄到檔案 而是傳送到stdout;經過管線之后 把tar zcvf - test.txt傳送給tar zxvf -;這里的-,就是取用前面一個指令的stdout
18.資料流重導向
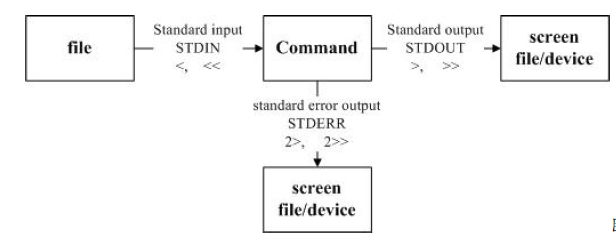
(1)指令執行程序的資料傳輸情況
(2)standard output 與 standard error output
標準輸出指的是“指令執行所回傳的正確的訊息”,而標準錯誤輸出可理解為“指令執行失敗后,所回傳的錯誤訊息”;用資料重導向可以將standard output (簡稱 stdout) 與 standard error output (簡稱 stderr)分別傳送到其他的檔案或設備
1. 標準輸入 (stdin) :代碼為 0 ,使用 < 或 << ;
2. 標準輸出 (stdout):代碼為 1 ,使用 > 或 >> ;
3. 標準錯誤輸出(stderr):代碼為 2 ,使用 2> 或 2>> ;
ll / > ~/rootfile 將根目錄下的目錄寫進rootfile這個檔案;或者用1>
1> :以覆寫的方法將“正確的資料”輸出到指定的檔案或設備上;
1>>:以累加的方法將“正確的資料”輸出到指定的檔案或設備上;
2> :以覆寫的方法將“錯誤的資料”輸出到指定的檔案或設備上;
2>>:以累加的方法將“錯誤的資料”輸出到指定的檔案或設備上;
#將stdout和stderr存到不同的檔案;螢屏不會列印資訊
find /home -name .bashrc > list_right 2> list_error
(3)/dev/null設備和特殊寫法
#只顯示正確資訊
find /home -name .bashrc 2> /dev/null
#怎么把正確和錯誤資訊同時寫進檔案
find /home -name .bashrc >list 2>list #錯誤 可能會交叉寫入該檔案內,造成次序的錯亂,雖檔案會產生 但是里面的資料排列是亂的
find /home -name .bashrc >list 2>&1 #正確 對于空檔案就>/dev/null 2>&1 前半部分正常輸出,2表示stderr 表示2的輸出重定向等同于1
find /home -name .bashrc >list #正確
#>/dev/null 2>&1 將錯誤資訊重定向到1 ;; 1>&2將正確資訊重定向到2
(4)standard input <和<<
將原本由鍵盤輸入的資料,改由檔案內容來取代
#由于加入>在cat后,所以那個catfile會被主動的創建,檔案內容即鍵盤輸入;使用C+D結束;也可以用cat >>catfile進行鍵盤累加
cat > catfile
#用stdin取代鍵盤的輸入以創建新檔案的簡單流程
cat > catfile < ~/.bashrc #將bashrc的檔案內容寫進catfile
#用cat直接由鍵盤寫入catfile中, 且當由鍵盤輸入eof時,結束輸入
cat > catfile << "eof" #<<可以終止輸入
#!/bin/bash
cat >> aa.msg << EOF
test.line1
test.line2 #向aa.msg檔案夾輸入以上兩個文本;>>追加 >覆寫
EOF
二、正則運算式(Regular Expression)與檔案格式化處理
揭開正則運算式的神秘面紗
正則運算式30分鐘入門教程
正則在線校驗1 正則在線校驗2(多使用這兩個網址練習)
1.grep的一些進階
-c 統計關鍵字次數;也可以用|wc -l代替
-v 排除相關行
-w 只顯示全字符合的列
-i 忽略字符大小寫的差別
-o 只輸出檔案中匹配到的部分
-n 顯示列號
--color 關鍵字顯示顏色;實際grep已經用alias設定為‘grep --color=auto’
2.正則相關
* 利用[]搜索集合字符
* 利用''搜尋特定字符
#eg: grep -n '[^g]oo' regular_express.txt ==搜尋oo且oo前面沒有g;但比如gooole 是符合搜索條件的
grep -n '[^a-z]oo' regular_express.txt
* 行首與行尾字符 ^ $
^ -1.表示否定
[^a]表示“匹配除了a的任意字符”,
[^a-zA-Z0-9]表示“找到一個非字母也非數字的字符”,
[\^abc]表示“找到一個插入符或者a或者b或者c”,用[/abc]也Ok 但是需避免轉義字符?
-2.表示限定開頭
/[(^\s+)(\s+$)]/g
(^cat)$
(^cat$)
^(cat)$
^(cat$)
#eg:grep -n '^$' filename ==列印空白行
#eg:grep -v '#' /etc/rsyslog.conf | grep -v '^$'
* 任意一個字符. 與重復字符*(!!!和萬用字符的含義不一樣)
#text: "Open Source" is a good mechanism to develop programs.
#重點:“o”代表的是:“擁有空字符或一個 o 以上的字符”,因此'o*'會把列印所有字符;oo*:第一個肯定存在,第二個是可有可無的多個o,所有凡是含有o,oo,ooo等都會 列印出來
#eg:grep -n 'g..d' regular_express.txt ==搜索g和d之間是兩個字符條件的
#eg:grep -n 'g.*g' regular_express.txt ==.* 就代表零個或多個任意字符,匹配開頭是g結尾也是g的字串
#eg:grep -n 'g*g' regular_express.txt ==代表匹配一個以及多個連續的g
* 限定連續 RE 字符范圍 {}
-1.若為 {n} 則是連續n個的前一個RE字符
-2.若是 {n,} 則是連續n個以上的前一個RE字符
#{ 與 } 的符號在 shell 是有特殊意義(命令塊)的,因此, 我們必須要使用跳脫字符 \ 來讓他失去特殊意義才行 也適用其他特殊字符
#eg:grep -n 'go\{2,5\}g' regular_express.txt ==g后2到5個o,再接一個g的字串
#eg:grep -n 'go\{2,\}g' regular_express.txt ==g后2個及以上的o,再接一個g的字串
3.sed工具
[dmtsai@study ~]$ sed [-nefr] [動作]
選項與引數:
-n :使用安靜(silent)模式,在一般 sed 的用法中,所有來自 STDIN 的資料一般都會被列出到螢屏上,但如果加上 -n 引數后,則只有經過 sed 特殊處理的那一行(或者動作)才會被列出來,
-e :直接在命令列界面上進行 sed 的動作編輯;
-f :直接將 sed 的動作寫在一個檔案內, -f filename 則可以執行 filename 內的 sed 動作;
-r :sed 的動作支持的是延伸型正則運算式的語法,(默認是基礎正則運算式語法)
-i :直接修改讀取的檔案內容,而不是由螢屏輸出,
動作說明: [n1[,n2]]function
n1,n2 :不見得會存在,一般代表“選擇進行動作的行數”,舉例來說,如果我的動作是需要在 10 到 20 行之間進行的,則“ 10,20[動作行為] ”
function 有下面這些咚咚:
a :新增, a 的后面可以接字串,而這些字串會在新的一行出現(目前的下一行)~
c :取代, c 的后面可以接字串,這些字串可以取代 n1,n2 之間的行!
d :洗掉,因為是洗掉啊,所以 d 后面通常不接任何咚咚;
i :插入, i 的后面可以接字串,而這些字串會在新的一行出現(目前的上一行);
p :列印,亦即將某個選擇的資料印出,通常 p 會與引數 sed -n 一起運行~
s :取代,可以直接進行取代的作業哩!通常這個 s 的動作可以搭配正則運算式
* 以行為單位的新增/洗掉功能
#eg:
[root@localhost ddd]# nl /etc/passwd | sed '2,5d' =='2,3d'洗掉2-3行;'2d':洗掉第二行;'3,$d':洗掉3到最后一行
1 root:x:0:0:root:/root:/bin/bash
6 sync:x:5:0:sync:/sbin:/bin/sync
#eg:
[root@localhost ddd]# nl /etc/passwd | sed '2a drink tea' ==在第二行后加列印;如果是第二行之前用''2i drink tea'
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
drink tea
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
#eg:
[root@localhost ddd]# nl /etc/passwd | sed '2a line1\nline2' ==在第二行之后連續列印兩行資料,可以用\n或者\+enter;如果想新增line1\nline2 就加跳脫字符'2a line1\\nline2'
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
line1
line2
* 以行為單位的取代與顯示功能
#eg:
[root@localhost ddd]# nl /etc/passwd | sed '2c No line2 number' ==替代第二行資料
1 root:x:0:0:root:/root:/bin/bash
No line2 number
#eg:
[root@localhost ddd]# nl /etc/passwd | sed -n '2,3p' ==列印2-3行,也可以用head -n 3 /etc/passwd| tail -n 2;另使用-n
2 bin:x:1:1:bin:/bin:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
* 部分資料的搜索并取代的功能
#sed 's/要被取代的字串/新的字串/g'
#eg:
#sed 's/^.*inet //g' ==洗掉inet以及之前的列印
#sed 's/#.*$//g' ==洗掉#及其注釋的內容 #開始到行尾($)
#sed '/^$/d' ==洗掉空白行,用/轉義
#sed -i 's/\.$/\!/g' ==把每一行行尾若為.則換成!在a動作增加的這種情況下 $表示最后一行,s替換的這種模式下,用的是正則,$表示行尾,
#sed -i '$a # This is a test' ==最后一行加上列印;;首行必須有資料 才能插入;; 也可以echo "text" >> file
4.延伸正則運算式
#eg:去除空白行和首行為#的行列
-1.grep -v '^$' regular_express.txt | grep -v '^#' ==管線命令
-2.egrep -v '^$|^#' regular_express.txt ==延伸型的正則運算式;egrep也可以使用grep -E替代
- 延伸型正則運算式的幾個特殊符號

5.檔案的格式化與相關處理
不需要重新以vim去編輯,通過資料流重導向配合下面介紹的printf功能,以及awk指令
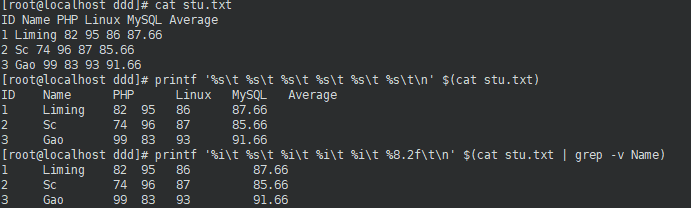
5.1格式化列印:printf
[dmtsai@study ~]$ printf '列印格式' 實際內容
選項與引數:
關于格式方面的幾個特殊樣式:
\a 警告聲音輸出
\b 倒退鍵(backspace)
\f 清除螢屏 (form feed)
\n 輸出新的一行
\r 亦即 Enter 按鍵
\t 水平的 [tab] 按鍵
\v 垂直的 [tab] 按鍵
\xNN NN 為兩位數的數字,可以轉換數字成為字符,
關于 C 程式語言內,常見的變數格式
%ns 那個 n 是數字, s 代表 string ,亦即多少個字符;
%ni 那個 n 是數字, i 代表 integer ,亦即多少整數碼數;
%N.nf 那個 n 與 N 都是數字, f 代表 floating (浮點),如果有小數碼數,
假設我共要十個位數,但小數點有兩位,即為 %10.2f 啰!
- eg:參考此鏈接
5.2 awk
#awk運行模式:awk '條件型別1{動作1} 條件型別2{動作2} ...' filename print、printf,print會自動換行不用\n
#awk處理流程:awk 的處理流程是:
-1. 讀入第一行,并將第一行的資料填入 $0, $1, $2.... 等變數當中;
-2. 依據 "條件型別" 的限制,判斷是否需要進行后面的 "動作";
-3. 做完所有的動作與條件型別;
-4. 若還有后續的“行”的資料,則重復上面 1~3 的步驟,直到所有的資料都讀完為止,
#awk變數名稱:
-1.NF:每一行($0)擁有的欄位總數;$NF表示列印最后一個欄位的值
-2.NR:目前 awk 所處理的是“第幾行”資料
-3.FS:目前的分隔字符,默認是空白鍵
#awk邏輯運算子:
> 大于 < 小于
>= 大于等于 <= 小于等于
== 等于 !== 不等于
#eg:
[root@localhost ddd]# last -n 2
root pts/0 192.168.15.1 Sun Apr 24 21:30 still logged in
root pts/1 192.168.15.1 Sat Apr 23 22:12 - 19:45 (21:33)
[root@localhost ddd]# last -n 2 | awk '{print $1 "\t" $3}' ==出去第一、三列 中間用tab符 每一行用\n換行;$n(n!=0)代表第n列 $0代表每行
root 192.168.15.1
root 192.168.15.1
#eg:awk '{ print NR "\t" NF "\t" $0}' /etc/passwd ==輸出每行的行號,每行的列數,對應的完整行內容;
#eg:cat /etc/passwd | awk 'BEGIN {FS=":"} $3<10 {print $1 "\t" $3}' ==用:為分隔符,第三列值<10,列印第一、三列;因為FS僅能在第二行及之后生效 所 以預設了awk的變數 使用BEGIN關鍵字
#eg:
#所有 awk 的動作,亦即在 {} 內的動作,如果有需要多個指令輔助時,可利用分號“;”間隔
[root@localhost ddd]# cat pay.txt
Name 1st 2nd 3th
VBird 23000 24000 25000
DMTsai 21000 20000 23000
Bird2 43000 42000 41000
[root@localhost ddd]# cat pay.txt | awk 'NR==1{printf "%10s %10s %10s %10s %10s\n",$1,$2,$3,$4,"Total" } ; NR>=2{total = $2 + $3 + $4 ; printf "%10s %10d %10d %10d %10.2f\n", $1, $2, $3, $4, total}'
Name 1st 2nd 3th Total
VBird 23000 24000 25000 72000.00
DMTsai 21000 20000 23000 64000.00
Bird2 43000 42000 41000 126000.00
[root@localhost ddd]# cat pay.txt | awk '{if(NR==1) printf "%10s %10s %10s %10s %10s\n",$1,$2,$3,$4,"Total"} ; NR>=2{total = $2 + $3 + $4 ; printf "%10s %10d %10d %10d %10.2f\n", $1, $2, $3, $4, total}' ==awk也支持if陳述句
Name 1st 2nd 3th Total
VBird 23000 24000 25000 72000.00
DMTsai 21000 20000 23000 64000.00
Bird2 43000 42000 41000 126000.00
6.檔案比對工具
1.diff:以行為單位比對,通常用在同一檔案的(或軟體)的新舊版本差異上,也可以用做目錄的比對;可以把新舊的版本差異 制作為補丁檔案,再由補丁檔案更新舊檔案即可;可以友echo $?輸出
2.cmp:主要是以位元組為單位比對
3.patch:版本的更新與還原 與diff一起使用
三、學習Shell Scripts
1.What is Shell Scripts
將一些 shell 的語法與指令(含外部指令)寫在里面, 搭配正則運算式、管線命令與資料流重導向等功能,以達到我們所想要的處理目的,
關于init(SystemV)和Systemd的介紹
關于換行符的介紹
1.關于編碼:Dos和Windows采用回車+換行CR/LF表示下一行;而UNIX/Linux采用換行符LF表示下一行
2.scripts添加資訊:功能、版本、作者資訊、修改記錄、需要的環境變數;最好使用vim
3.除錯:bash -x [filename]
4.超出運算式遞回:https://stackoverflow.com/questions/30404863/expression-recursion-level-exceeded
5.filename=$ {fileuser:-"filename"} 若變數fileuser為空 ,則回傳"filename".若變數 fileuser 有值,則回傳其當前值;以確保變數一直有值
6.善于使用$? || 以及&&進行判斷前一個指令回傳至對于后一個指令是否要進行的依據;也可以使用test指令
#根據日期創建檔案
#!/usr/bin/sh
read -p "please input filename: " fileuser
filename=${fileuser:-"filename"} #檢查fileuser是否存在
#獲取日期
date1=$(date --date='1 days ago' +%Y%m%d) #一天前
date0=$(date +%Y%m%d) #今天
#組態檔名
file1=${filename}_${date1}
file0=${filename}_${date0}
#創建檔案
touch "${file1}.log"
touch "${file0}.log"
#數值運算;可以用$((運算式))來定義運算式;
#!/usr/bin/sh
read -p "input first number: " first_num
read -p "input second number: " sec_num
total=$((first_num * sec_num))
echo -e "${first_num}*${sec_num}=${total}"
#另計算含有小數的資料時,可以用bc協助 比如echo "2.2+3.4"|bc
2.script的執行差異
- 利用bash(sh)來下達腳本時,改script是在子程式的bash內執行的,會使用一個新的bash環境;所以是script內的變數在bash環境下無效

- 利用source執行腳本,在父程式中執行,script中的變數會在bash中生效;source ~/.filename.sh

3.利用test指令的測驗功能
主要進行數值、字串和檔案三個方面的檢測
1.數值檢測
#eg: test 1 -eq 2 && echo "yes" || echo "no"
-eq:值 1 等于值 2
-ge : 值 1 大于或等于值 2
-gt : 值 1 大于值 2
-le : 值 1 小于或等于值 2
-lt : 值 1 小于值 2
-ne : 值 1 不等于值 2
2.比較文本
#eg: test "string1" = "string2" && echo "yes" || echo "no" ==判斷兩個字串是否相等
#eg: test -n "string1" && echo "yes" || echo "no" ==判斷字串長度是否大于0
==:字串 1 匹配字串 2;;等號兩邊要有空格!!!
!= : 字串 1 與字串 2 不匹配
-n:字串長度大于0
-z:字串長度等于 0
3.比較檔案
-ef:檔案具有相同的設備和 inode 編號(它們是同一個檔案)
-nt : 第一個檔案比第二個檔案新
-ot:第一個檔案比第二個檔案舊
-d:檔案存在并且是目錄(directory)
-e : 檔案存在
-f : 檔案存在并且是檔案(file)
-r:檔案存在且可讀
-s:檔案存在且大小大于零
-w:檔案存在且可寫
-x:檔案存在且可執行
`優化1:[ "$a" == "$b" ] 優化 [ x"$a" == x"$b" ]:這種辦法避免了$b為空的情況下 bash報錯
`優化2:[ x"$1" == x"1" ] 避免引數為空bash版本不兼容報錯;但是也可以[ "$1" == ""]
4.多個條件判斷
# -a表示and,-o表示or
#eg:test 4 -eq 4 -a "string1" == "string2" && echo "yes" || echo "no" == -a條件同時滿足
#eg: test 4 -eq 4 -o "string1" == "string2" && echo "yes" || echo "no" == -o條件之一滿足
#檢測檔案是否存在
#!/usr/bin/sh
# Program:
# User input a filename, program will check the flowing:
# 1.) exist? 2.) file/directory? 3.) file permissions
# 1\. 讓使用者輸入檔案名,并且判斷使用者是否真的有輸入字串?
echo -e "Please input a filename, I will check the filename's type and permission. \n\n"
read -p "Input a filename : " filename
test -z ${filename} && echo "You MUST input a filename." && exit 0 #判斷字串長度是否為0 或用[ -z "${filename}"" ]判斷
# 2\. 判斷檔案是否存在?若不存在則顯示訊息并結束腳本
test ! -e ${filename} && echo "The filename '${filename}' DO NOT exist" && exit 0
# 3\. 開始判斷檔案型別與屬性
test -f ${filename} && filetype="regulare file"
test -d ${filename} && filetype="directory"
test -r ${filename} && perm="readable"
test -w ${filename} && perm="${perm} writable"
test -x ${filename} && perm="${perm} executable"
# 4\. 開始輸出資訊!
echo "The filename: ${filename} is a ${filetype}"
echo "And the permissions for you are : ${perm}"
5.利用判斷符號[]
- 必須要注意中括號的兩端需要有空白字符來分隔
- 中括號內字符需要使用雙引號
#eg:[ -z "${HOME}" ] ==判斷$HOME是否為空 要雙引號!
#eg:[ 4 -eq 4 ] && [ "string1" = "string2" ] && echo "yes" || echo "no"
#!/usr/bin/sh
read -p "input (Y/N): " yn
[ "$yn" == "N" ] || [ "$yn" == "n" ] && echo "NO, interrupert" && exit 0 #或者用-o連接也可以,[ "${yn}" == "N" -o "${yn}" == "n" ]
[ "$yn" == "Y" ] || [ "$yn" == "y" ] && echo "Yes, contine" && exit 0
4.Shell Scripts的默認變數 ($0,$1...)
/path/to/scriptname opt1 opt2 opt3 opt4
$0 $1 $2 $3 $4
$0代表腳本檔案名,接著的第一個引數就是$1
$# :代表后接的引數“個數”,以上表為例這里顯示為4;
$@ :代表“ "$1" "$2" "$3" "$4" ”之意,每個變數是獨立的(用雙引號括起來);和$*不同 記憶$@即可
$* :代表“ "$1<u>c</u>$2<u>c</u>$3<u>c</u>$4" ”,其中 <u>c</u> 為分隔字符,默認為空白鍵, 所以本例中代表“ "$1 $2 $3 $4" ”之意,
# shift:造成引數變數號碼偏移
#!/bin/bash
echo "the script name is $0" #列印檔案名
[ "$#" -lt 2 ] && echo "less than 2" && exit 0 #利用[]判斷
echo "the whole(\$@) is $@" #列印全部引數內容
echo "the 1st parameter(\$1) is $1" #列印第一個引數
[root@localhost bin]# sh test.sh a b
the script name is test.sh
the whole($@) is a b
the 1st parameter($1) is a
5.條件判斷式
5.1.利用if ....then
單層、簡單的條件判斷式
if [ 條件判斷式 ]; then
當條件判斷式成立時,可以進行的指令作業內容;
fi <==將 if 反過來寫,就成為 fi 啦!結束 if 之意!
#eg: [ "${yn}" == "Y" -o "${yn}" == "y" ] 可替換為 [ "${yn}" == "Y" ] || [ "${yn}" == "y" ]
#!/usr/bin/sh
read -p "input (Y/N): " yn
if [ "$yn" == "N" ] || [ "$yn" == "n" ] ; then
echo "NO, interrupert"
exit 0 #執行完需退出 不然會執行最后一行列印
fi
if [ "$yn" == "Y" ] || [ "$yn" == "y" ] ; then
echo "Yes, contine"
exit 0
fi
echo "Only y or n accepted" && exit 0
多重、復雜條件判斷式
# 多個條件判斷 (if ... elif ... elif ... else) 分多種不同情況執行
if [ 條件判斷式一 ]; then
當條件判斷式一成立時,可以進行的指令作業內容;
elif [ 條件判斷式二 ]; then
當條件判斷式二成立時,可以進行的指令作業內容;
else
當條件判斷式一與二均不成立時,可以進行的指令作業內容;
fi
#檢測鍵盤輸入
#!/usr/bin/sh
read -p "input (Y/N): " yn
if [ "$yn" == "N" ] || [ "$yn" == "n" ] ;then
echo "NO, interrupert" && exit 0
elif [ "$yn" == "Y" ] || [ "$yn" == "y" ] ;then
echo "Yes, contine" && exit 0
else
echo "Only y or n accepted" && exit 0
fi
#檢測行程
#!/usr/bin/sh
process_chk_file=/home/ddd/process_chk.txt
netstat -antp > ${process_chk_file}
process_port=$(grep ":22" ${process_chk_file}) #可使用$(...)進行參考;等號兩邊不能有空格;簡單賦值的時候不需要$(...)
if [ "${process_port}" = "" ] ; then #空字符""
echo "Error,process SSH not runnning"
else
echo "Log,process SSH is running"
fi
5.2.利用case...in...esac判斷
case $變數名稱 in
模式1)
command1
command2
;; #每個類別結尾使用兩個連續的分號來處理
模式2)
command1
command2
;;
*) #最后一個變數內容都會用 * 來代表所有其他值
command1
command2
;;
esac
#!/usr/bin/sh
read -p "input a num:" aNum
case $aNum in
1) echo 'You select 1'
;;
2) echo 'You select 2'
;;
*) echo 'You do not select a number between 1 to 4'
;;
esac
5.3.利用function功能
#!/usr/bin/sh
function printit(){
echo -n "ur choice is "
}
case ${1} in
"one")
printit; echo ${1} | tr 'a-z' 'A-Z' #呼叫;轉換大小寫
;;
*) echo 'over'
;;
esac
6.回圈loop
6.1 while do done, until do done (不定回圈)
while [ "${yn}" != "yes" -a "${yn}" != "YES" ]
do
read -p "Please input yes/YES to stop this program: " yn
done
until [ "${yn}" == "yes" -o "${yn}" == "YES" ]
do
read -p "Please input yes/YES to stop this program: " yn
done
s=0 # 這是加總的數值變數
i=0 # 這是累計的數值,亦即是 1, 2, 3....
while [ "${i}" != "100" ]
do
i=$(($i+1)) # 每次 i 都會增加 1
s=$(($s+$i)) # 每次都會加總一次!
done
6.2 for...in...do...done (固定回圈)
for var in con1 con2 con3 ...
do
程式段
done
for animal in dog cat elephant
do
echo "There are ${animal}s.... "
done
#檢測服務器狀態
#usr/bin/sh
network="192.168.15"
ping_chk_file=/home/ddd/ping_chk_file_$(date +%Y%m%d).txt
[ ! -e "$ping_chk_file" ] && touch ${ping_chk_file} #檢測檔案 不存在則創建
#cat /dev/null > ${ping_chk_file} #檔案置空
[ ! -s "$ping_chk_file" ] && echo "# ping-check" >> ${ping_chk_file} #檔案為空則添加首行 可以為下文的sed -i服務;
echo "excuting"
for sitenu in $(seq 120 130) #seq 連續
do
ping -c 1 -w 1 ${network}.${sitenu} >/dev/null && result=0 || result=1 #免除界面列印
if [ "$result" = 0 ] ; then
echo "$(date "+%Y-%m-%d %H:%M:%S"): server ${network}.${sitenu} is UP" >> ${ping_chk_file} #方便簡單
# sed -i '$a server ${network}.${sitenu} is UP' ${ping_chk_file} #高級,但需要首行有資料才能處理
else
echo "$(date "+%Y-%m-%d %H:%M:%S"): server ${network}.${sitenu} is DOWN" >> ${ping_chk_file}
# sed -i '$a server ${network}.${sitenu} is DOWN' ${ping_chk_file}
fi
done
#檢測檔案權限
#usr/bin/sh
read -p "Please input a directory: " dir
if [ "${dir}" == "" -o ! -d "${dir}" ] ; then #經常用吧
echo "The ${dir} is NOT exist in your system."
exit 1
fi
# 2\. 開始測驗檔案啰~
filelist=$(ls ${dir}) # 列出所有在該目錄下的檔案名稱;注意格式 參考賦值
for filename in ${filelist}
do
perm=""
test -r "${dir}/${filename}" && perm="${perm} readable"
test -w "${dir}/${filename}" && perm="${perm} writable"
test -x "${dir}/${filename}" && perm="${perm} executable"
echo "The file ${dir}/${filename}'s permission is ${perm} "
done
6.5 for...do...done 的數值處理
for (( 初始值; 限制值; 執行步階 ))
do
程式段
done
這種語法適合于數值方式的運算當中,在 for 后面的括號內的三串內容意義為:
初始值:某個變數在回圈當中的起始值,直接以類似 i=1 設定好;
限制值:當變數的值在這個限制值的范圍內,就繼續進行回圈,例如 i<=100;
執行步階:每作一次回圈時,變數的變化量,例如 i=i+1,
#usr/bin/sh
read -p "input a num " nu
s=0
for((i=1; i<=${nu}; i++))
do
s=$((${s}+${i}))
done
echo "sum is ${s}"
7.shell script的追蹤與debug
sh [-nvx] scripts.sh
選項與引數:
-n :不要執行 script,僅查詢語法的問題;
-v :再執行 sccript 前,先將 scripts 的內容輸出到螢屏上;
-x :將使用到的 script 內容顯示到螢屏上,這是很有用的引數!
四、補充
1.列印進度條
#!/bin/sh
b=''
for ((i=0;$i<=100;i+=2))
do
printf "progress:[%-50s]%s%%\r" $b $i #[]內左靠齊50個$b,%s給$i,%%轉義列印%,\r收到回車再換行
sleep 0.02
b=#$b
done
echo
2.檔案描述符(參考第一章18小節)
用途
/dev/null 是一個特殊的設備檔案,它丟棄一切寫入其中的資料 可以將它 視為一個黑洞, 它等效于只寫檔案, 寫入其中的所有內容都會消失, 嘗試從中讀取或輸出不會有任何結果,同樣,/dev/null 在命令列和腳本中都非常有用/dev/null通常被用于丟棄不需要的輸出流,或作為用于輸入流的空檔案,這些操作通常由重定向完成,任何你想丟棄的資料都可以寫入其中
丟棄標準輸出、丟棄標準錯誤輸出
在寫shell腳本的時候,只想通過命令的結果執行后面的邏輯,而不想命令執行程序中有一大堆中間結果輸出,這時候可以把命令執行程序中的輸入全部寫入 /dev/null
#丟棄標準輸出
#!/bin/bash
command -v $1 >/dev/null #command -v 命令名 是查找指定命令名的命令是否存在,如果存在,輸出指定命令名的路徑,否則,不做任何輸出;執行./a.sh top 則不列印路徑
if [[ $? -eq 0 ]]; then
echo "command $1 exist..."
else
echo "command $1 not exist..."
fi
#丟棄標準錯誤輸出
#!/bin/bash
rm $1 >/dev/null 2>$1 #或用2>/dev/null替代 丟棄標準錯誤輸出
清空檔案內容
cat /dev/null > t.txt
3.行程檢測
#!/bin/bash
# 如果此機器不存在這個,則配置為1
aboss5_flag=0
aboss2_flag=1
tomcat_flag=0
mycat_flag=0
# procmgr start
procmgr_ids=`ps -ef | grep procmgr | grep -v "grep" | awk '{print $2}'`
for id in $procmgr_ids
do
pathDir=`ls -al /proc/$id/cwd | awk '{print $NF}'` #取出id
echo [$id]:[$pathDir]
if [[ "$pathDir" == *"aboss5"* ]]; then #兩層[]為匹配正則*
aboss5_flag=1
echo "[NOTE] aboss5 procmgr is already started."
elif [[ "$pathDir" == *"aboss2"* ]]; then
aboss2_flag=1
echo "[NOTE] aboss2 procmgr is already started."
fi
done
4.關于雙方括號
雙方括號的用法說明
其他括號的用法說明
- 支持字符匹配
#!/usr/bin/sh
#匹配結果和不帶""沒差
if [[ $1 == "s"* ]]; then
echo "s*"
elif [[ $1 == *"s" ]]; then
echo "*s"
elif [[ $1 == *"s"* ]] ;then
echo "*s*"
else
echo "none"
fi
if [[ $1 == *"s"* ]]; #帶雙引號 雙* 進行元字符匹配;和下例沒差
if [[ $1 == s* ]]; #不帶雙引號,匹配s*的字串
if [[ $1 =~ sa* ]]; #=~進行正則匹配 匹配s/sa...等
-
支持&& -a -o多個條件連接處理
if [[ "a" == "a" && 2 -gt1 ]]
5.注釋
1. #單行注釋
2. :`多行注釋`
3. << BLOCK
多行注釋
BLOCK
6.引號
對于列印文本 單引號和雙引號沒有區別;列印輸出一個已定義的變數,則需要使用雙引號
#!/usr/bin/sh
read -sp "num:" num #-s支持靜默不在界面列印
echo -e "\\n $num" #-e支持轉義字符
7.關于日期格式化
[root@localhost scripts]# date +%Y-%m-%d" "%H:%M:%S
2022-05-06 00:14:42
+%Y 年 2022
m 月 01
d 日 01
H 時 二十四小時制
M 分
S 秒
8.sleep
sleep 1d 2h 3m 30s 默認是秒 也可用作定時執行 不規范
五、案例
https://blog.csdn.net/u010230971/article/details/80335522
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/475314.html
標籤:Linux
上一篇:JFrame型別的方法setColor(Color)未定義
下一篇:說說最近linux運維那些事