我有一個登陸 S3 存盤桶,它將每天接收一些資料,按日期磁區:
s3:/my_bucket/date=2020-01-01/my_data.txt
s3:/my_bucket/date=2020-01-02/my_data.txt
s3:/my_bucket/date=2020-01-03/my_data.txt
我確實使用 SQL 創建了第一個在日期列上磁區的測驗 Delta 表,然后我做了:
COPY INTO delta.my_table FROM (SELECT date, value FROM 's3:/my_bucket/') FILEFORMAT = TEXT
一切都運行良好,然后......今天我在那個桶上有一個新的 partitionFolder:
s3:/my_bucket/date=2020-01-04/my_data.txt
我不知道如何僅“復制到”新檔案夾,并保留日期磁區值。基本上,我不能重復使用相同的 sql 陳述句來復制,因為它會復制以前的檔案(其他日期,已經在 delta 表中)。
我確實嘗試過像這樣直接指定檔案夾路徑:
COPY INTO delta.my_table FROM (SELECT date, value FROM 's3:/my_bucket/date=2020-01-04') FILEFORMAT = TEXT
但 Delta/Spark 無法獲取“日期列”,因為它是直接讀取檔案而不是包含日期列資訊的子檔案夾。
SQL AnalysisException: cannot resolve 'date' given input columns: [value];
我想在子檔案夾上添加一些“模式”匹配,例如
COPY INTO delta.my_table FROM (SELECT date, value FROM 's3:/my_bucket/') FILEFORMAT = TEXT
P?TTERN = 'date=2020-01-04/*'
但同樣的錯誤,spark 無法理解這個檔案夾是一個新磁區。
我的問題很簡單,是否可以從增量磁區 s3 存盤桶中使用“COPY INTO”(如我的示例)。
PS:我的 Delta 表是一個外部表,它鏈接到另一個 s3 存盤桶。
s3:/my_bucket/應該只是著陸區并且應該是不可變的。
uj5u.com熱心網友回復:
COPY INTO 是冪等操作 - 它不會從已處理的檔案中加載資料,至少在您明確要求它之前COPY_OPTIONS(force=true)(請參閱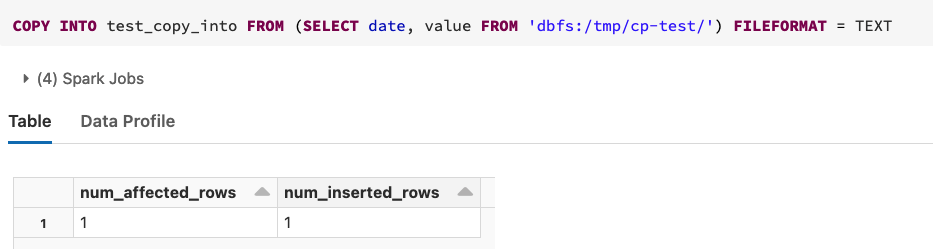
- 檢查您是否已加載資料:
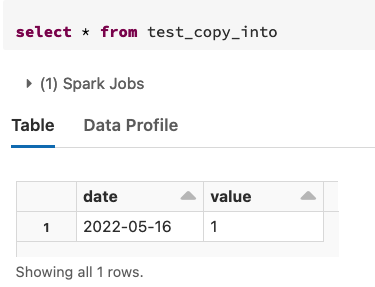
- 創建一個包含 content
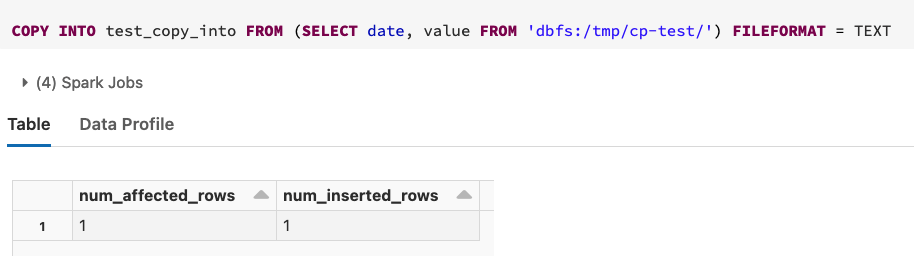
2的檔案,將其上傳到 filedbfs:/tmp/cp-test/date=2022-05-17/1.txt,然后也將其匯入 - 您會看到我們只匯入了一行,盡管那里有舊檔案:
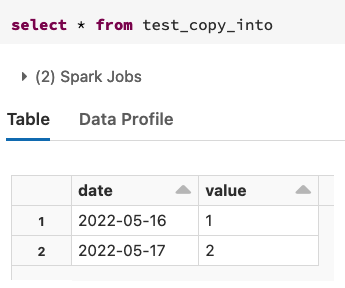
- 如果我們查看資料,我們會發現我們只有 2 行,因為它應該是:
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/477855.html
標籤:阿帕奇火花 亚马逊-s3 数据块 三角洲湖 数据块-sql