我正在為 3 年的資料創建一個堆疊圖,使用geom_area. 它作業得很好,除了我希望按照顏色順序排列圖例。我在下面提到示例資料和代碼:
#sample dataset
df <- structure(list(
Topic = c("Topic_A", "Topic_A", "Topic_A", "Topic_A", "Topic_A", "Topic_A", "Topic_A", "Topic_A", "Topic_A", "Topic_A", "Topic_A", "Topic_A", "Topic_B", "Topic_B", "Topic_B", "Topic_B", "Topic_B", "Topic_B", "Topic_B", "Topic_B", "Topic_B", "Topic_B", "Topic_B", "Topic_B", "Topic_C", "Topic_C", "Topic_C", "Topic_C", "Topic_C", "Topic_C", "Topic_C", "Topic_C", "Topic_C", "Topic_C", "Topic_C", "Topic_D", "Topic_D", "Topic_D", "Topic_D", "Topic_D", "Topic_D", "Topic_D", "Topic_D", "Topic_D", "Topic_D", "Topic_D", "Topic_E", "Topic_E", "Topic_E", "Topic_E", "Topic_E", "Topic_E", "Topic_E", "Topic_E", "Topic_E", "Topic_E", "Topic_E", "Topic_E", "Topic_F", "Topic_F", "Topic_F", "Topic_F", "Topic_F", "Topic_F", "Topic_F", "Topic_F", "Topic_F", "Topic_F", "Topic_F", "Topic_G", "Topic_G", "Topic_G", "Topic_G", "Topic_G", "Topic_G", "Topic_G", "Topic_G", "Topic_G", "Topic_G", "Topic_G", "Topic_G", "Topic_H", "Topic_H", "Topic_H", "Topic_H", "Topic_H", "Topic_H", "Topic_H", "Topic_H", "Topic_H", "Topic_H", "Topic_H", "Topic_H", "Topic_I", "Topic_I", "Topic_I", "Topic_I", "Topic_I", "Topic_I", "Topic_I"), Frequency = c(22L, 27L, 68L, 34L, 60L, 13L, 23L, 11L, 12L, 23L, 19L, 22L, 9L, 36L, 127L, 83L, 37L, 19L, 31L, 19L, 32L, 25L, 20L, 17L, 19L, 22L, 48L, 32L, 36L, 71L, 37L, 12L, 10L, 37L, 48L, 11L, 15L, 10L, 9L, 19L, 19L, 14L, 22L, 51L, 14L, 33L, 22L, 36L, 16L, 10L, 31L, 36L, 15L, 10L, 20L, 23L, 21L, 14L, 20L, 17L, 18L, 22L, 9L, 14L, 37L, 18L, 14L, 15L, 17L, 47L, 28L, 34L, 68L, 227L, 22L, 25L, 8L, 11L, 5L, 2L, 4L, 34L, 8L, 21L, 4L, 5L, 33L, 19L, 12L, 18L, 22L, 23L, 38L, 96L, 112L, 53L, 87L, 103L, 58L, 44L),
Timestamp = structure(c(17897, 17928, 17957, 17988, 18018, 18048, 18079, 18109, 18169, 18200, 18230, 18233, 18262, 18302, 18323, 18353, 18383, 18414, 18444, 18475, 18535, 18566, 18596, 18599, 18628, 18660, 18713, 18744, 18770, 18799, 18827, 18856, 18884, 18913, 18944, 18628, 18660, 18713, 18744, 18770, 18799, 18827, 18856, 18884, 18913, 18944, 18262, 18302, 18323, 18353, 18383, 18414, 18444, 18475, 18535, 18566, 18596, 18599, 18628, 18660, 18713, 18744, 18770, 18799, 18827, 18856, 18884, 18913, 18944, 17897, 17928, 17957, 17988, 18018, 18048, 18079, 18109, 18169, 18200, 18230, 18233, 18262, 18302, 18323, 18353, 18383, 18414, 18444, 18475, 18535, 18566, 18596, 18599, 17897, 17928, 17957, 17988, 18018, 18048, 18079), class = "Date")
), row.names = c(5L, 10L, 15L, 20L, 25L, 30L, 35L, 40L, 45L, 50L, 55L, 60L, 61L, 66L, 71L, 76L, 81L, 86L, 91L, 96L, 101L, 106L, 111L, 116L, 122L, 127L, 132L, 137L, 142L, 147L, 152L, 157L, 162L, 167L, 172L, 124L, 129L, 134L, 139L, 144L, 149L, 154L, 159L, 164L, 169L, 174L, 62L, 67L, 72L, 77L, 82L, 87L, 92L, 97L, 102L, 107L, 112L, 117L, 125L, 130L, 135L, 140L, 145L, 150L, 155L, 160L, 165L, 170L, 175L, 3L, 8L, 13L, 18L, 23L, 28L, 33L, 38L, 43L, 48L, 53L, 58L, 63L, 68L, 73L, 78L, 83L, 88L, 93L, 98L, 103L, 108L, 113L, 118L, 1L, 6L, 11L, 16L, 21L, 26L, 31L), class = "data.frame")
下面是我用來制作情節的簡單代碼:
ggplot(df, aes(x=Timestamp, y=Frequency, fill=Topic))
scale_x_date(date_breaks = '1 month', date_labels = "%b-%y")
geom_area(alpha=0.6 , size=1, colour="black", position = position_fill())
scale_fill_discrete(guide = guide_legend()) #, breaks = df_q$Topic #to sort legends
theme(legend.position="bottom", legend.box = "horizontal")
ggtitle("Questionable")
xlab("Month")
guides(fill = guide_legend(nrow = 1))
我得到以下輸出:
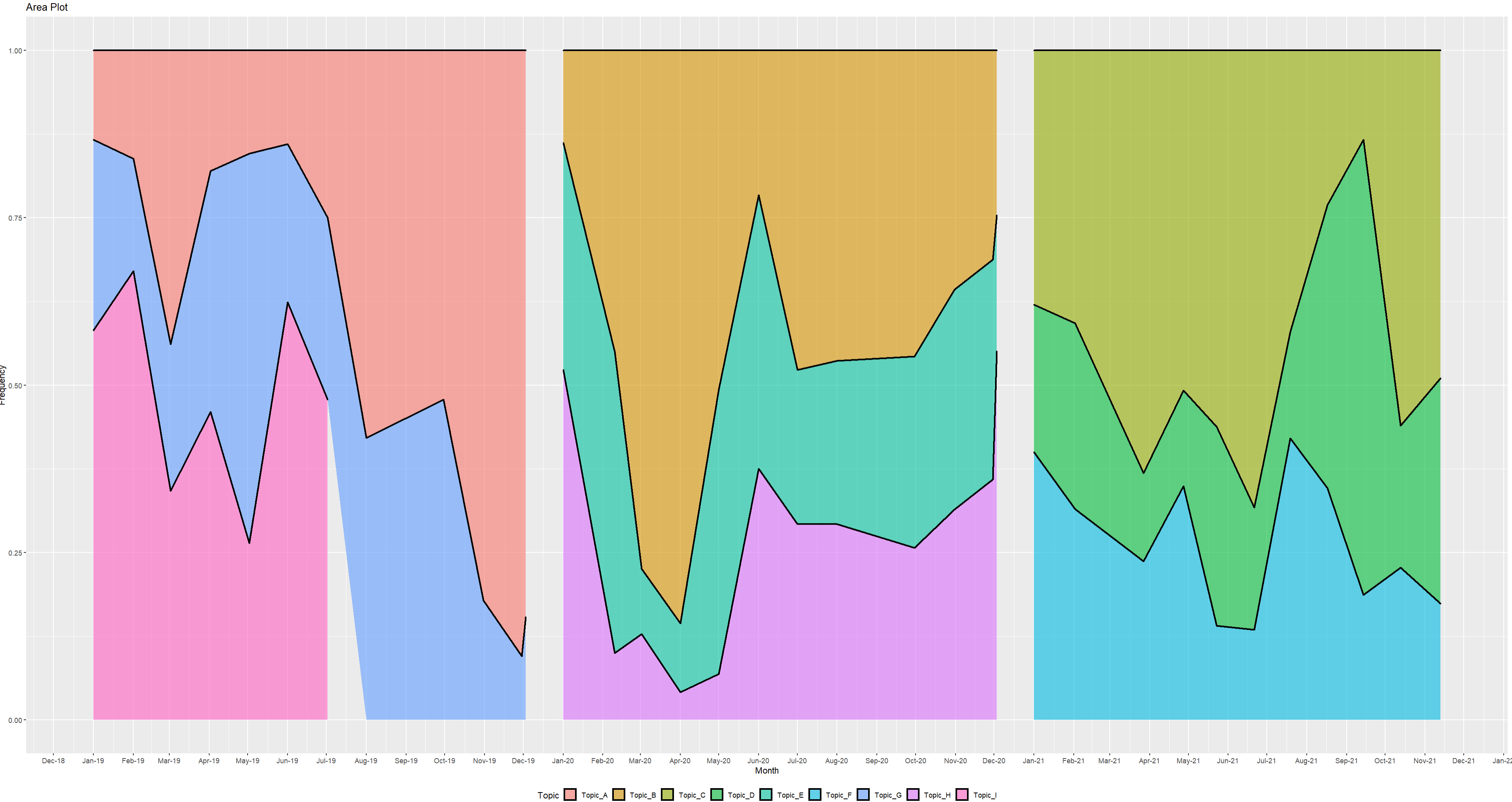
是否可以按照從左(2019)到右(2021)和從上到下的顏色順序對圖例進行排序(忽略主題順序)?例如,橙色(2019 年的頂級顏色)應該是圖例中的第一個,藍色第二個等等。很高興知道每個傳奇人物是否有辦法在其相應年份的下方輕松區分每一年的主題。
uj5u.com熱心網友回復:
只需使用 limits 引數手動指定順序scale_fill
library(ggplot2)
df <- structure(list(
Topic = c("Topic_A", "Topic_A", "Topic_A", "Topic_A", "Topic_A", "Topic_A", "Topic_A", "Topic_A", "Topic_A", "Topic_A", "Topic_A", "Topic_A", "Topic_B", "Topic_B", "Topic_B", "Topic_B", "Topic_B", "Topic_B", "Topic_B", "Topic_B", "Topic_B", "Topic_B", "Topic_B", "Topic_B", "Topic_C", "Topic_C", "Topic_C", "Topic_C", "Topic_C", "Topic_C", "Topic_C", "Topic_C", "Topic_C", "Topic_C", "Topic_C", "Topic_D", "Topic_D", "Topic_D", "Topic_D", "Topic_D", "Topic_D", "Topic_D", "Topic_D", "Topic_D", "Topic_D", "Topic_D", "Topic_E", "Topic_E", "Topic_E", "Topic_E", "Topic_E", "Topic_E", "Topic_E", "Topic_E", "Topic_E", "Topic_E", "Topic_E", "Topic_E", "Topic_F", "Topic_F", "Topic_F", "Topic_F", "Topic_F", "Topic_F", "Topic_F", "Topic_F", "Topic_F", "Topic_F", "Topic_F", "Topic_G", "Topic_G", "Topic_G", "Topic_G", "Topic_G", "Topic_G", "Topic_G", "Topic_G", "Topic_G", "Topic_G", "Topic_G", "Topic_G", "Topic_H", "Topic_H", "Topic_H", "Topic_H", "Topic_H", "Topic_H", "Topic_H", "Topic_H", "Topic_H", "Topic_H", "Topic_H", "Topic_H", "Topic_I", "Topic_I", "Topic_I", "Topic_I", "Topic_I", "Topic_I", "Topic_I"), Frequency = c(22L, 27L, 68L, 34L, 60L, 13L, 23L, 11L, 12L, 23L, 19L, 22L, 9L, 36L, 127L, 83L, 37L, 19L, 31L, 19L, 32L, 25L, 20L, 17L, 19L, 22L, 48L, 32L, 36L, 71L, 37L, 12L, 10L, 37L, 48L, 11L, 15L, 10L, 9L, 19L, 19L, 14L, 22L, 51L, 14L, 33L, 22L, 36L, 16L, 10L, 31L, 36L, 15L, 10L, 20L, 23L, 21L, 14L, 20L, 17L, 18L, 22L, 9L, 14L, 37L, 18L, 14L, 15L, 17L, 47L, 28L, 34L, 68L, 227L, 22L, 25L, 8L, 11L, 5L, 2L, 4L, 34L, 8L, 21L, 4L, 5L, 33L, 19L, 12L, 18L, 22L, 23L, 38L, 96L, 112L, 53L, 87L, 103L, 58L, 44L),
Timestamp = structure(c(17897, 17928, 17957, 17988, 18018, 18048, 18079, 18109, 18169, 18200, 18230, 18233, 18262, 18302, 18323, 18353, 18383, 18414, 18444, 18475, 18535, 18566, 18596, 18599, 18628, 18660, 18713, 18744, 18770, 18799, 18827, 18856, 18884, 18913, 18944, 18628, 18660, 18713, 18744, 18770, 18799, 18827, 18856, 18884, 18913, 18944, 18262, 18302, 18323, 18353, 18383, 18414, 18444, 18475, 18535, 18566, 18596, 18599, 18628, 18660, 18713, 18744, 18770, 18799, 18827, 18856, 18884, 18913, 18944, 17897, 17928, 17957, 17988, 18018, 18048, 18079, 18109, 18169, 18200, 18230, 18233, 18262, 18302, 18323, 18353, 18383, 18414, 18444, 18475, 18535, 18566, 18596, 18599, 17897, 17928, 17957, 17988, 18018, 18048, 18079), class = "Date")
), row.names = c(5L, 10L, 15L, 20L, 25L, 30L, 35L, 40L, 45L, 50L, 55L, 60L, 61L, 66L, 71L, 76L, 81L, 86L, 91L, 96L, 101L, 106L, 111L, 116L, 122L, 127L, 132L, 137L, 142L, 147L, 152L, 157L, 162L, 167L, 172L, 124L, 129L, 134L, 139L, 144L, 149L, 154L, 159L, 164L, 169L, 174L, 62L, 67L, 72L, 77L, 82L, 87L, 92L, 97L, 102L, 107L, 112L, 117L, 125L, 130L, 135L, 140L, 145L, 150L, 155L, 160L, 165L, 170L, 175L, 3L, 8L, 13L, 18L, 23L, 28L, 33L, 38L, 43L, 48L, 53L, 58L, 63L, 68L, 73L, 78L, 83L, 88L, 93L, 98L, 103L, 108L, 113L, 118L, 1L, 6L, 11L, 16L, 21L, 26L, 31L), class = "data.frame")
ggplot(df, aes(x=Timestamp, y=Frequency, fill=Topic))
scale_x_date(date_breaks = '1 month', date_labels = "%b-%y")
geom_area(alpha=0.6 , size=1, colour="black", position = position_fill())
theme(legend.position="bottom", legend.box = "horizontal")
guides(fill = guide_legend(nrow = 1))
scale_fill_discrete(limits = paste("Topic", LETTERS[c(1,7,9,2,5,8,3,4,6)], sep = "_"))
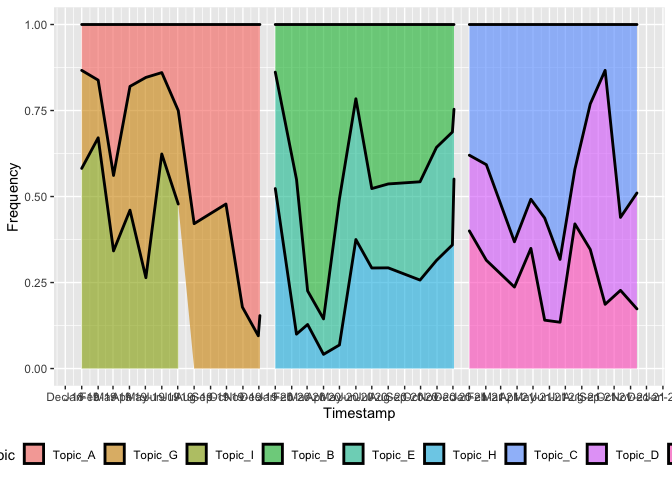
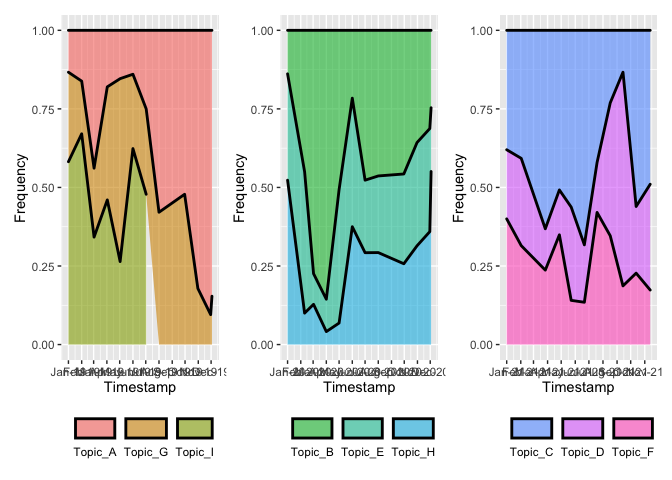
為了每年獲得一個單獨的圖例,您基本上需要使用各自的圖例創建單獨的圖。主要挑戰是分配正確的顏色值和指導限制。
library(tidyverse)
library(patchwork)
## first get the colors
my_cols <- scales::hue_pal()(9)
## assign them to the order you like
names(my_cols) = paste("Topic", LETTERS[c(1,7,9,2,5,8,3,4,6)], sep = "_")
p_list <-
df %>%
## create year variable by which you split into a list
mutate(year = lubridate::year(Timestamp)) %>%
split(.$year) %>%
## pass this list to a loop function to create three separate plots
map(~ggplot(data = .x, aes(x=Timestamp, y=Frequency, fill=Topic))
scale_x_date(date_breaks = '1 month', date_labels = "%b-%y")
geom_area(alpha=0.6 , size=1, colour="black", position = position_fill())
theme(legend.position="bottom", legend.box = "horizontal")
## changing label position because of crowding
guides(fill = guide_legend(nrow = 1, label.position = "bottom"))
## you will need to set the limits to the unique values in each plot
## I am also removing the guide title because of the visual crowding
scale_fill_manual(NULL, values = my_cols, limits = unique(.x$Topic))
)
## patchwork is great for such things
wrap_plots(p_list)
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/487997.html
上一篇:如何在Rggplot上錯開多個因素的線 Rsquared方程?
下一篇:在軸上設定時間限制會洗掉所有值