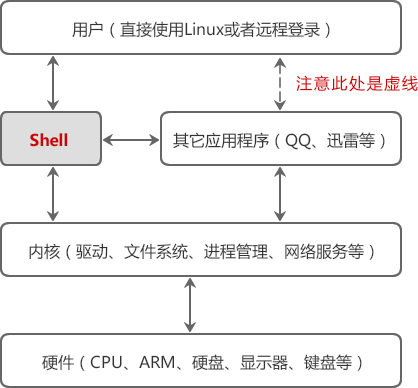
1、什么是shell和shell腳本
Shell 本身是一個用 C 語言撰寫的程式,是一個命令列解釋器,它的作用就是遵循一定的語法將輸入的命令加以解釋并傳給系統,它是用戶使用 Linux 的橋梁,是UNIX/Linux系統的用戶與作業系統之間的一種介面,
這個應用程式提供了一個界面,用戶通過這個界面訪問作業系統內核的服務,Shell是作業系統的介面,是用戶與作業系統互動的橋梁,
Shell既是一種命令語言,又是一種程式設計語言(shell腳本),它雖然不是 Linux系統內核的一部分,但它呼叫了系統內核的大部分功能來執行程式、創建檔案并以并行的方式協調各個程式的運行,
它既是終端上的用戶與UNIX/Linux作業系統互動的命令解釋程式(shell命令),又是一種高級的命令程式設計語言(shell腳本),
作為命令解釋程式,shell接收用戶輸入的命令語言,將命令翻譯成一個動作序列,然后呼叫系統程序執行這條命令,作為命令程式設計語言,shell具有一般高級語言的許多特征,如變數定義、賦值、條件和回圈陳述句等,用戶可以利用SHELL的這些功能將多條命令組織成一個命令程式,以完成某種特定的任務,這個命令程式稱為shell程式或shell程序,
參考:https://www.cnblogs.com/The-explosion/articles/12336061.html
2、關于shell的變數設定
1.變數與變數內容以一個等號“=”來鏈接,如下所示:
“myname=VBird”
2.等號兩邊不能直接接空白字符,如下所示為錯誤:
“myname = VBird”或“myname=VBird Tsai”
3.變數名稱只能是英文字母與數字,但是開頭字符不能是數字,如下為錯誤:
“2myname=VBird”
4.變數內容若有空白字符可使用雙引號“"”或單引號“'”將變數內容結合起來,但
#雙引號內的特殊字符如 $等,可以保有原本的特性,如下所示:
“var="lang is $LANG"”則“echo $var”可得“lang is zh_TW.UTF-8”
#單引號內的特殊字符則僅為一般字符(純文本),如下所示:
“var='lang is $LANG'”則“echo $var”可得“lang is $LANG”
5.可用轉義符“ \”將特殊符號(如 [Enter], $, \,空白字符, '等)變成一般字符,如:
“myname=VBird\ Tsai”
6.在一串指令的執行中,還需要借由其他額外的指令所提供的資訊時,可以使用反單
引號“`指令`”或“$(指令)”,特別注意,那個 `是鍵盤上方的數字鍵 1左邊那個按
鍵,而不是單引號!例如想要取得核心版本的設定:
“version=$(uname -r)”再“echo $version”可得“3.10.0-229.el7.x86_64”
注:在一串指令中,在` `之內的指令將會被先執行,而其執行出來的結果將做為外部的輸入資訊
7.若該變數為擴增變數內容時,則可用 "$變數名稱"或 ${變數}累加內容,如下所
示:
“PATH="$PATH":/home/bin”或“PATH=${PATH}:/home/bin”或 "PATH=$PATH:/home/bin”
8.若該變數需要在其他子程式執行,則需要以 export來使變數變成環境變數:
“export PATH”實作"分享自己的變數設定給后來呼叫的檔案或其他程式,"
9.通常大寫字符為系統默認變數,自行設定變數可以使用小寫字符,方便判斷(純
粹依照使用者興趣與嗜好);
10.取消變數的方法為使用 unset:“unset變數名稱”例如取消 myname的設定:
“unset myname”
代碼示例
范例一:設定一變數 name,且內容為 VBird
[dmtsai@study ~]$ 12name=VBird
bash: 12name=VBird: command not found... <==螢屏會顯示錯誤!因為不能以數字開頭!
[dmtsai@study ~]$ name = VBird <==還是錯誤!因為有空白!
[dmtsai@study ~]$ name=VBird <==OK的啦!
范例二:承上題,若變數內容為 VBird's name呢,就是變數內容含有特殊符號時:
[dmtsai@study ~]$ name=VBird's name
#單引號與雙引號必須要成對,在上面的設定中僅有一個單引號,因此當你按下 enter后,
#你還可以繼續輸入變數內容,這與我們所需要的功能不同,失敗啦!
#記得,失敗后要復原請按下 [ctrl]-c結束!
[dmtsai@study ~]$ name="VBird's name" <==OK的啦!
#指令是由左邊向右找→,先遇到的引號先有用,因此如上所示,單引號變成一般字符!
[dmtsai@study ~]$ name='VBird's name' <==失敗的啦!
#因為前兩個單引號已成對,后面就多了一個不成對的單引號了!因此也就失敗了!
[dmtsai@study ~]$ name=VBird\'s\ name <==OK的啦!
#利用反斜線(\)跳脫特殊字符,例如單引號與空白鍵,這也是 OK的啦!
范例三:我要在 PATH這個變數當中“累加”:/home/dmtsai/bin這個目錄
[dmtsai@study ~]$ PATH=$PATH:/home/dmtsai/bin
[dmtsai@study ~]$ PATH="$PATH":/home/dmtsai/bin
[dmtsai@study ~]$ PATH=${PATH}:/home/dmtsai/bin
#上面這三種格式在 PATH里頭的設定都是 OK的!但是下面的例子就不見得啰!
范例四:承范例三,我要將 name的內容多出 "yes"呢?
[dmtsai@study ~]$ name=$nameyes
#知道了吧?如果沒有雙引號,那么變數成了啥?name的內容是 $nameyes這個變數!
#呵呵!我們可沒有設定過 nameyes這個變數吶!所以,應該是下面這樣才對!
[dmtsai@study ~]$ name="$name"yes
[dmtsai@study ~]$ name=${name}yes <==以此例較佳!
范例五:如何讓我剛剛設定的 name=VBird可以用在下個 shell的程式?
[dmtsai@study ~]$ name=VBird
[dmtsai@study ~]$ bash <==進入到所謂的子程式
[dmtsai@study ~]$ echo $name <==子程式:再次的 echo一下;
<==嘿嘿!并沒有剛剛設定的內容喔!
[dmtsai@study ~]$ exit <==子程式:離開這個子程式
[dmtsai@study ~]$ export name
[dmtsai@study ~]$ bash <==進入到所謂的子程式
[dmtsai@study ~]$ echo $name <==子程式:在此執行!
VBird <==看吧!出現設定值了!
[dmtsai@study ~]$ unset name <==最后用unset命令取消變數值3、shell中常見環境變數
用 env 或 export 觀察環境變數與常見環境變數說明
范例一:列出目前的 shell環境下的所有環境變數與其內容,
[dmtsai@study ~]$ env
HOSTNAME=study.centos.vbird <==這部主機的主機名稱
TERM=xterm <==這個終端機使用的環境是什么型別
SHELL=/bin/bash <==目前這個環境下,使用的 Shell是哪一個程式?
HISTSIZE=1000 <==“記錄指令的筆數”在 CentOS默認可記錄 1000筆
OLDPWD=/home/dmtsai <==上一個作業目錄的所在
LC_ALL=en_US.utf8 <==由于語系的關系,鳥哥偷偷丟上來的一個設定
USER=dmtsai <==使用者的名稱啊!
LS_COLORS=rs=0:di=01;34:ln=01;36:mh=00:pi=40;33:so=01;35:do=01;35:bd=40;33;01:cd=40;33;01:
or=40;31;01:mi=01;05;37;41:su=37;41:sg=30;43:ca=30;41:tw=30;42:ow=34;42:st=37;44:ex=01;32:
*.tar=01... <==一些顏色顯示
MAIL=/var/spool/mail/dmtsai <==這個使用者所取用的 mailbox位置
PATH=/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/dmtsai/.local/bin:/home/dmtsai/bin
PWD=/home/dmtsai <==目前使用者所在的作業目錄(利用 pwd取出!)
LANG=zh_TW.UTF-8 <==這個與語系有關,下面會再介紹!
HOME=/home/dmtsai <==這個使用者的主檔案夾啊!
LOGNAME=dmtsai <==登陸者用來登陸的帳號名稱
_=/usr/bin/env <==上一次使用的指令的最后一個引數(或指令本身)3.1 用set查看全部變數
[dmtsai@study ~]$ set #查看所有變數(含環境變數和自訂變數)
BASH=/bin/bash <== bash的主程式放置路徑
BASH_VERSINFO=([0]="4" [1]="2" [2]="46" [3]="1" [4]="release" [5]="x86_64-redhat-linux-gnu")
BASH_VERSION='4.2.46(1)-release' <==這兩行是 bash的版本
COLUMNS=90 <==在目前的終端機環境下,使用的欄位有幾個字符長度
HISTFILE=/home/dmtsai/.bash_history <==歷史命令記錄的放置檔案,隱藏檔案
HISTFILESIZE=1000 <==存起來(與上個變數有關)的檔案之指令的最大紀錄筆數,
HISTSIZE=1000 <==目前環境下,記憶體中記錄的歷史命令最大筆數,
IFS=$' \t\n' <==默認的分隔符號
LINES=20 <==目前的終端機下的最大行數
MACHTYPE=x86_64-redhat-linux-gnu <==安裝的機器型別
OSTYPE=linux-gnu <==作業系統的型別!
PS1='[\u@\h \W]\$ ' <== PS1是命令提示字符,也就是我們常見的[root@www ~]
#或 [dmtsai ~]$的設定值啦!可以更動的!
PS2='> ' <==如果你使用轉義符號(\)第二行以后的提示字符也
$ <==目前這個 shell所使用的 PID
? <==剛剛執行完指令的回傳值,3.2 PSI值
\d: #可顯示出“星期月日”的日期格式,如:"Mon Feb 2"
\H: #完整的主機名稱,舉例來說,鳥哥的練習機為“study.centos.vbird”
\h: #僅取主機名稱在第一個小數點之前的名字,如鳥哥主機則為“study”后面省略
\t: #顯示時間,為 24小時格式的“HH:MM:SS”
\T: #顯示時間,為 12小時格式的“HH:MM:SS”
\A: #顯示時間,為 24小時格式的“HH:MM”
\@: #顯示時間,為 12小時格式的“am/pm”樣式
\u: #目前使用者的帳號名稱,如“dmtsai”;
\v: #BASH的版本資訊,如鳥哥的測驗主機版本為 4.2.46(1)-release,僅取“4.2”顯示
\w: #完整的作業目錄名稱,由根目錄寫起的目錄名稱,但主檔案夾會以 ~取代;
\W: #利用 basename函式取得作業目錄名稱,所以僅會列出最后一個目錄名,
\#: #下達的第幾個指令,
\$: #提示字符,如果是 root時,提示字符為 #,否則就是 $啰~
CentOS默認的 PS1內容:"[\u@\h \W]\$ "當然也可任意設定,如:
[zengcj@localhost ~]$ PS1='[\u@\h \w \A #\#]\$ '
[zengcj@localhost ~ 14:58 #48]$ ls
Docker Exercise genomic GWAS miniconda3 n.sh SMR software 下載 公共 圖片 檔案 桌面 模板 視頻 音樂
[zengcj@localhost ~ 14:59 #49]$ PS1='[\u@\h \w \A ]\$ '
[zengcj@localhost ~ ]$ PS1='[xiangsui@\h \w ]\$ '
[xiangsui@localhost ~ ]$ PS1='[xiangsui@\h \w ]\$'
[xiangsui@localhost ~ ]$PS1='[xiangsui@^_^ \w ]\$' #一般最后引號前需多一個空格
[xiangsui@^_^ ~ ]$PS1='[xiangsui@^_^ \w ]\$ '
[xiangsui@^_^ ~ ]$ PS1="[xiangsui@^_^ \w ]\$ "3.3 其他
$:(關于本 shell的 PID)
$字號本身也是個變數,代表的是“目前這個 Shell的執行緒代號”,亦即是所謂的 PID(Process ID),更多的程式觀念,我們會在第四篇的時候提及,想要知道我們的 shell的 PID,就可以用:“ echo $$”即可!出現的數字就是你的 PID號碼,
?:(關于上個執行指令的回傳值)
在 bash里面這個變數可重要的很!這個變數是:“上一個執行的指令所回傳的值”,上面這句話的重點是“上一個指令”與“回傳值”兩個地方,當我們執行某些指令時,這些指令都會回傳一個執行后的代碼,一般來說,如果成功的執行該指令,則會回傳一個 0值,如果執行程序發生錯誤,就會回傳“錯誤代碼”,可以根據回傳錯誤代碼的不同,判斷發生的錯誤型別,
用以下程式判斷錯誤代碼含義
#include <stdio.h>
#include <stdlib.h>
#include <errno.h>
#include <string.h>
int main()
{
int i=0;
for(i=0;i<43;i++) //43及以后就木有了
printf("errno:%d:\t%s\n",i,strerror(i));
return 0;
}參考:https://www.cnblogs.com/castor-xu/p/12026515.html
3.4 關于Linux支持的語系
-- 可以用locale -a查詢,語系檔案一般放在 /usr/lib/locale/ 目錄,系統默認語系定義為/etc/locale.conf
[xiangsui@^_^ ~]$ locale <==后面不加任何選項與引數即可!
LANG=en_US <==主語言的環境
LC_CTYPE="en_US" <==字符(文字)辨識的編碼
LC_NUMERIC="en_US" <==數字系統的顯示訊息
LC_TIME="en_US" <==時間系統的顯示資料
LC_COLLATE="en_US" <==字串的比較與排序等
LC_MONETARY="en_US" <==幣值格式的顯示等
LC_MESSAGES="en_US" <==訊息顯示的內容,如功能表、錯誤訊息等
LC_ALL= <==整體語系的環境基本上,你可以逐一設定每個與語系有關的變數資料,但事實上,如果其他的語系變數都未設定,且你有設定 LANG或者是 LC_ALL時,則其他的語系變數就會被這兩個變數所取代!這也是為什么我們在 Linux當中,通常說明僅設定 LANG或 LC_ALL這兩個變數而已,因為他是最主要的設定變數!你是在 MS Windows主機以遠端連線服務器的軟體連線到主機的話,其實命令列確實是可以看到中文的,此時反而你得要在 LC_ALL設定中文編碼!
4、變數鍵盤讀取、陣列與宣告: read, array, declare
-- read
[dmtsai@study ~]$ read [-pt] variable
選項與引數:
-p :后面可以接提示字符!
-t :后面可以接等待的“秒數!”這個比較有趣~不會一直等待使用者啦!
范例一:讓使用者由鍵盤輸入一內容,將該內容變成名為 atest的變數
[dmtsai@study ~]$ read atest
This is a test <==此時游標會等待你輸入!請輸入左側文字看看
[dmtsai@study ~]$ echo ${atest}
This is a test <==你剛剛輸入的資料已經變成一個變數內容!
范例二:提示使用者 30秒內輸入自己的大名,將該輸入字串作為名為 named的變數內容
[dmtsai@study ~]$ read -p "Please keyin your name: " -t 30 named
Please keyin your name: VBird Tsai <==注意看,會有提示字符喔!
[dmtsai@study ~]$ echo ${named}
VBird Tsai <==輸入的資料又變成一個變數的內容了!read之后不加任何引數,直接加上變數名稱,那么下面就會主動出現一個空白行等待你的輸入(如范例一),如果加上 -t后面接秒數,例如上面的范例二,那么 30秒之內沒有任何動作時,該指令就會自動略過了~如果是加上 -p,嘿嘿!在輸入的游標前就會有比較多可以用的提示字符給我們參考!在指令的下達里面,比較美觀啦! ^_^
-- declare / typeset
declare或 typeset是一樣的功能,就是在“宣告變數的型別”,如果使用 declare后面并沒有接任何引數,那么 bash就會主動的將所有的變數名稱與內容通通列出來,就好像使用 set一樣,
[dmtsai@study ~]$ declare [-aixr] variable
選項與引數:
-a :將后面名為 variable的變數定義成為陣列(array)型別
-i :將后面名為 variable的變數定義成為整數數字(integer)型別
-x :用法與 export一樣,就是將后面的 variable變成環境變數;
-r :將變數設定成為 readonly型別,該變數不可被更改內容,也不能 unset
范例一:讓變數 sum進行 100+300+50的加總結果
[dmtsai@study ~]$ sum=100+300+50
[dmtsai@study ~]$ echo ${sum}
100+300+50 <==咦!怎么沒有幫我計算加總?因為這是文字體態的變數屬性啊!
[dmtsai@study ~]$ declare -i sum=100+300+50
[dmtsai@study ~]$ echo ${sum}
450 <==瞭乎??由于在默認的情況下面, bash對于變數有幾個基本的定義:
- 變數型別默認為“字串”,所以若不指定變數型別,則 1+2為一個“字串”而不是“計算式”,所以上述第一個執行的結果才會出現那個情況的;
- bash環境中的數值運算,默認最多僅能到達整數形態,所以 1/3結果是 0;
- 如果需要非字串型別的變數,那就得要進行變數的宣告才行!
范例二:將 sum變成環境變數
[dmtsai@study ~]$ declare -x sum
[dmtsai@study ~]$ export | grep sum
declare -ix sum="450" <==果然出現了!包括有 i與 x的宣告!
范例三:讓 sum變成只讀屬性,不可更動!
[dmtsai@study ~]$ declare -r sum
[dmtsai@study ~]$ sum=tesgting
-bash: sum: readonly variable <==老天爺~不能改這個變數了!
范例四:讓 sum變成非環境變數的自訂變數吧!
[dmtsai@study ~]$ declare +x sum <==將 -變成 +可以進行“取消”動作
[dmtsai@study ~]$ declare -p sum <== -p可以單獨列出變數的型別
declare -ir sum="450" <==看吧!只剩下 i, r的型別,不具有 x啰!-- 陣列(array)變數型別
在 bash中,陣列的設定方式是:var[index]=content
范例:設定var[1]~ var[3]的變數,
[dmtsai@study ~]$ var[1]="small min"
[dmtsai@study ~]$ var[2]="big min"
[dmtsai@study ~]$ var[3]="nice min"
[dmtsai@study ~]$ echo "${var[1]}, ${var[2]}, ${var[3]}"
small min, big min, nice min5、與檔案系統及程式的限制關系: ulimit
bash是可以“限制使用者的某些系統資源”的,包括可以打開的檔案數量,可以使用的 CPU時間,可以使用的記憶體總量等等,主要依靠ulimit命令實作,
[dmtsai@study ~]$ ulimit [-SHacdfltu] [配額]
選項與引數:
-H :hard limit,嚴格的設定,必定不能超過這個設定的數值;
-S :soft limit,警告的設定,可以超過這個設定值,但是若超過則有警告訊息,
在設定上,通常 soft會比 hard小,舉例來說,soft可設定為 80而 hard
設定為 100,那么你可以使用到 90(因為沒有超過 100),但介于 80~100之間時,
系統會有警告訊息通知你!
-a :后面不接任何選項與引數,可列出所有的限制額度;
-c :當某些程式發生錯誤時,系統可能會將該程式在記憶體中的資訊寫成檔案(除錯用),
這種檔案就被稱為核心檔案(core file),此為限制每個核心檔案的最大容量,
-f :此 shell可以創建的最大檔案大小(一般可能設定為 2GB)單位為 KBytes
-d :程式可使用的最大斷裂記憶體(segment)容量;
-l :可用于鎖定(lock)的記憶體量
-t :可使用的最大 CPU時間(單位為秒)
-u :單一使用者可以使用的最大程式(process)數量,
范例一:列出你目前身份(假設為一般帳號)的所有限制資料數值
[dmtsai@study ~]$ ulimit -a
core file size (blocks, -c) 0 <==只要是 0就代表沒限制
data seg size (kBytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited < ==可創建的單一檔案的大小
pending signals (-i) 4903
max locked memory (kBytes, -l) 64
max memory size (kBytes, -m) unlimited
open files (-n) 1024 < ==同時可打開的檔案數量
pipe size (512 Bytes, -p) 8
POSIX message queues (Bytes, -q) 819200
real-time priority (-r) 0
stack size (kBytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 4096
virtual memory (kBytes, -v) unlimited
file locks (-x) unlimited
范例二:限制使用者僅能創建 10MBytes以下的容量的檔案
[dmtsai@study ~]$ ulimit -f 10240
[dmtsai@study ~]$ ulimit -a | grep 'file size'
core file size (blocks, -c) 0
file size (blocks, -f) 10240 <==最大量為10240Kbyes,相當10MBytes
[dmtsai@study ~]$ dd if=/dev/zero of=123 bs=1M count=20
File size limit exceeded(core dumped) <==嘗試創建 20MB的檔案,結果失敗了!
[dmtsai@study ~]$ rm 123 <==趕快將這個檔案洗掉啰!同時你得要登出再次的登陸才能解開 10M的限制注:想要復原 ulimit的設定最簡單的方法就是登出再登陸,否則就是得要重新以ulimit設定才行!不過,要注意的是,一般身份使用者如果以 ulimit -f設定了的檔案大小,那么他“只能繼續減小檔案大小,不能增加檔案大小!”
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/494061.html
標籤:其他
下一篇:你如何修復npmWARNconfigglobal`--global`,`--local`已棄用。改用`--location=global`