在上一篇文章中,介紹了cpufreq的core層,core提供了cpufreq系統的初始化,公共資料結構的建立以及對cpufreq中其它子部件提供注冊功能,core的最核心功能是對policy的管理,一個policy通過cpufreq_policy結構中的governor欄位,和某個governor相關聯,本章的內容正是要對governor進行討論,
通過前面兩篇文章的介紹,我們知道,governor的作用是:檢測系統的負載狀況,然后根據當前的負載,選擇出某個可供使用的作業頻率,然后把該作業頻率傳遞給cpufreq_driver,完成頻率的動態調節,內核默認提供了5種governor供我們使用,在之前的內核版本中,每種governor幾乎是獨立的代碼,它們各自用自己的方式實作對系統的負載進行監測,很多時候,檢測的邏輯其實是很相似的,各個governor最大的不同之處其實是根據檢測的結果,選擇合適頻率的策略,所以,為了減少代碼的重復,在我現在分析的內核版本中(3.10.0),一些公共的邏輯代碼被單獨抽象出來,單獨用一個檔案來實作:/drivers/cpufreq/cpufreq_governor.c,而各個具體的governor則分別有自己的代碼檔案,如:cpufreq_ondemand.c,cpufreq_performance.c,下面我們先從公共部分討論,
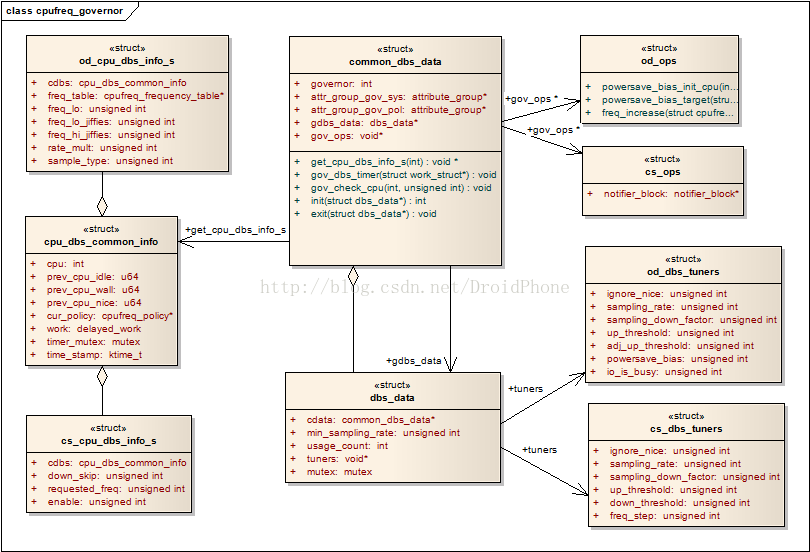
1. 資料結構
cpu_dbs_common_info 該結構把對計算cpu負載需要使用到的一些輔助變數整合在了一起,通常,每個cpu都需要一個cpu_dbs_common_info結構體,該結構體中的成員會在governor的生命周期期間進行傳遞,以用于統計當前cpu的負載,它的定義如下:
/* Per cpu structures */
struct cpu_dbs_common_info {
int cpu;
u64 prev_cpu_idle;
u64 prev_cpu_wall;
u64 prev_cpu_nice;
struct cpufreq_policy *cur_policy;
struct delayed_work work;
struct mutex timer_mutex;
ktime_t time_stamp;
};
- cpu 與該結構體相關聯的cpu編號,
- prev_cpu_idle 上一次統計時刻該cpu停留在idle狀態的總時間,
- prev_cpu_wall 上一次統計時刻對應的總作業時間,
- cur_policy 指向該cpu所使用的cpufreq_policy結構,
- work 作業佇列,該作業佇列會被定期地觸發,然后定期地進行負載的更新和統計作業,
dbs縮寫,實際是:demand based switching,通常,因為cpu_dbs_common_info只包含了經過抽象后的公共部分,所以,各個governor會自己定義的一個包含cpu_dbs_common_info的自定義結構,例如對于ondemand,他會定義:
struct od_cpu_dbs_info_s {
struct cpu_dbs_common_info cdbs;
struct cpufreq_frequency_table *freq_table;
unsigned int freq_lo;
unsigned int freq_lo_jiffies;
unsigned int freq_hi_jiffies;
unsigned int rate_mult;
unsigned int sample_type:1;
};
而對于Conservative,他的定義如下:
struct cs_cpu_dbs_info_s {
struct cpu_dbs_common_info cdbs;
unsigned int down_skip;
unsigned int requested_freq;
unsigned int enable:1;
};
把它理解為類似于C++語言的基類和子類的概念就是了,
common_dbs_data 各個獨立的governor,需要和governor的公共層互動,需要實作一套公共的介面,這個介面由common_dbs_data結構來提供:
struct common_dbs_data {
/* Common across governors */
#define GOV_ONDEMAND 0
#define GOV_CONSERVATIVE 1
int governor;
struct attribute_group *attr_group_gov_sys; /* one governor - system */
struct attribute_group *attr_group_gov_pol; /* one governor - policy */
/* Common data for platforms that don't set have_governor_per_policy */
struct dbs_data *gdbs_data;
struct cpu_dbs_common_info *(*get_cpu_cdbs)(int cpu);
void *(*get_cpu_dbs_info_s)(int cpu);
void (*gov_dbs_timer)(struct work_struct *work);
void (*gov_check_cpu)(int cpu, unsigned int load);
int (*init)(struct dbs_data *dbs_data);
void (*exit)(struct dbs_data *dbs_data);
/* Governor specific ops, see below */
void *gov_ops;
};
主要的欄位意義如下:
- governor 因為ondemand和conservative的實作部分有很多相似的地方,用該欄位做一區分,可以設定為GOV_ONDEMAND或GOV_CONSERVATIVE的其中之一,
- attr_group_gov_sys 該公共的sysfs屬性組,
- attr_group_gov_pol 各policy使用的屬性組,有時候多個policy會使用同一個governor演算法,
- gdbs_data 通常,當沒有設定have_governor_per_policy時,表示所有的policy使用了同一種governor,該欄位指向該governor的dbs_data結構,
- get_cpu_cdbs 回呼函式,公共層用它取得對應cpu的cpu_dbs_common_info結構指標,
- get_cpu_dbs_info_s 回呼函式,公共層用它取得對應cpu的cpu_dbs_common_info_s的派生結構指標,例如:od_cpu_dbs_info_s,cs_cpu_dbs_info_s,
- gov_dbs_timer 前面說過,cpu_dbs_common_info_s結構中有一個作業佇列,該回呼通常用作作業佇列的作業函式,
- gov_check_cpu 計算cpu負載的回呼函式,通常會直接呼叫公共層提供的dbs_check_cpu函式完成實際的計算作業,
- init 初始化回呼,用于完成該governor的一些額外的初始化作業,
- exit 回呼函式,governor被移除時呼叫,
- gov_ops 各個governor可以用該指標定義各自特有的一些操作介面,
- dbs_data 該結構體通常由governor的公共層代碼在governor的初始化階段動態創建,該結構的一個最重要的欄位就是cdata:一個common_dbs_data結構指標,另外,該結構還包含一些定義governor作業方式的一些調節引數,該結構的詳細定義如下:
struct dbs_data {
struct common_dbs_data *cdata;
unsigned int min_sampling_rate;
int usage_count;
void *tuners;
/* dbs_mutex protects dbs_enable in governor start/stop */
struct mutex mutex;
};
幾個主要的欄位:
-
cdata 一個common_dbs_data結構指標,通常由具體governor的實作部分定義好,然后作為引數,通過公共層的API:cpufreq_governor_dbs,傳遞到公共層,cpufreq_governor_dbs函式在創建好dbs_data結構后,把該指標賦值給該欄位,
-
min_sampling_rate 用于記錄統計cpu負載的采樣周期,
-
usage_count 當沒有設定have_governor_per_policy時,意味著所有的policy采用同一個governor,該欄位就是用來統計目前該governor被多少個policy參考,
-
tuners 指向governor的調節引數結構,不同的governor可以定義自己的tuner結構,公共層代碼會在governor的初始化階段呼叫common_dbs_data結構的init回呼函式,governor的實作可以在init回呼中初始化tuners欄位,
如果設定了have_governor_per_policy,每個policy擁有各自獨立的governor,也就是說,擁有獨立的dbs_data結構,它會記錄在cpufreq_policy結構的governor_data欄位中,否則,如果沒有設定have_governor_per_policy,多個policy共享一個governor,和同一個dbs_data結構關聯,此時,dbs_data被賦值在common_dbs_data結構的gdbs_data欄位中,
cpufreq_governor 這個結構在本系列文章的第一篇已經介紹過了,請參看Linux動態頻率調節系統CPUFreq之一:概述,幾個資料結構的關系如下圖所示:
下面我們以ondemand這個系統已經實作的governor為例,說明一下如何實作一個governor,具體的代碼請參看:/drivers/cpufreq/cpufreq_ondemand.c,
2. 定義一個governor
要實作一個governor,首先要定義一個cpufreq_governor結構,對于ondeman來說,它的定義如下:
struct cpufreq_governor cpufreq_gov_ondemand = {
.name = "ondemand",
.governor = od_cpufreq_governor_dbs,
.max_transition_latency = TRANSITION_LATENCY_LIMIT,
.owner = THIS_MODULE,
};
其中,governor是這個結構的核心欄位,cpufreq_governor注冊后,cpufreq的核心層通過該欄位操縱這個governor的行為,包括:初始化、啟動、退出等作業,現在,該欄位被設定為od_cpufreq_governor_dbs,我們看看它的實作:
static int od_cpufreq_governor_dbs(struct cpufreq_policy *policy,
unsigned int event)
{
return cpufreq_governor_dbs(policy, &od_dbs_cdata, event);
}
只是簡單地呼叫了governor的公共層提供的API:cpufreq_governor_dbs,關于這個API,我們在后面會逐一進行展開,這里我們注意到引數:&od_dbs_cdata,正是我們前面討論過得common_dbs_data結構,作為和governor公共層的介面,在這里它的定義如下:
static struct common_dbs_data od_dbs_cdata = https://www.cnblogs.com/linhaostudy/p/{
.governor = GOV_ONDEMAND,
.attr_group_gov_sys = &od_attr_group_gov_sys,
.attr_group_gov_pol = &od_attr_group_gov_pol,
.get_cpu_cdbs = get_cpu_cdbs,
.get_cpu_dbs_info_s = get_cpu_dbs_info_s,
.gov_dbs_timer = od_dbs_timer,
.gov_check_cpu = od_check_cpu,
.gov_ops = &od_ops,
.init = od_init,
.exit = od_exit,
};
這里先介紹一下get_cpu_cdbs和get_cpu_dbs_info_s這兩個回呼,前面介紹cpu_dbs_common_info_s結構的時候已經說過,各個governor需要定義一個cpu_dbs_common_info_s結構的派生結構,對于ondemand來說,這個派生結構是:od_cpu_dbs_info_s,兩個回呼函式分別用來獲得基類和派生類這兩個結構的指標,我們先看看od_cpu_dbs_info_s是如何定義的:
static DEFINE_PER_CPU(struct od_cpu_dbs_info_s, od_cpu_dbs_info);
沒錯,它被定義為了一個per_cpu變數,也就是說,每個cpu擁有各自獨立的od_cpu_dbs_info_s,這很正常,因為每個cpu需要的實時負載是不一樣的,需要獨立的背景關系變數來進行負載的統計,前面也已經列出了od_cpu_dbs_info_s的宣告,他的第一個欄位cdbs就是一個cpu_dbs_common_info_s結構,內核為我們提供了一個輔助宏來幫助我們定義get_cpu_cdbs和get_cpu_dbs_info_s這兩個回呼函式:
#define define_get_cpu_dbs_routines(_dbs_info) \
static struct cpu_dbs_common_info *get_cpu_cdbs(int cpu) \
{ \
return &per_cpu(_dbs_info, cpu).cdbs; \
} \
\
static void *get_cpu_dbs_info_s(int cpu) \
{ \
return &per_cpu(_dbs_info, cpu); \
}
所以,在cpufreq_ondemand.c中,我們只要簡單地使用上述的宏即可定義這兩個回呼:
define_get_cpu_dbs_routines(od_cpu_dbs_info);
經過上述這一系列的定義以后,governor的公共層即可通過這兩個回呼獲取各個cpu所對應的cpu_dbs_common_info_s和od_cpu_dbs_info_s的結構指標,用來記錄本次統計周期的一些背景關系引數(idle時間和運行時間等等),
3. 初始化一個governor
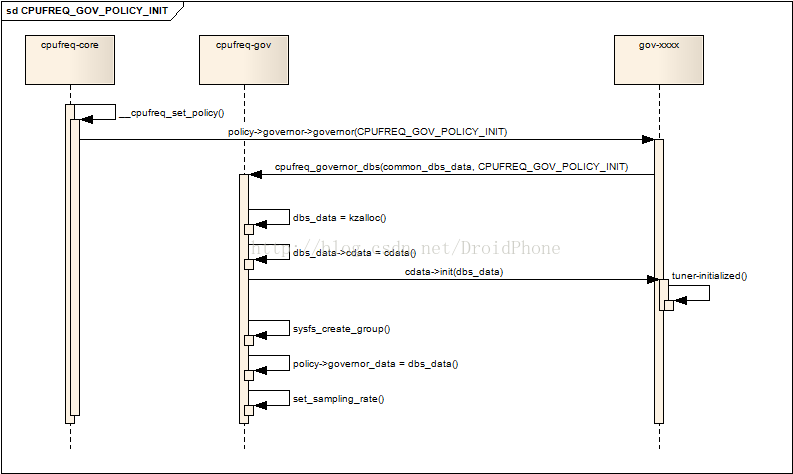
當一個governor被policy選定后,核心層會通過__cpufreq_set_policy函式對該cpu的policy進行設定,參看 Linux動態頻率調節系統CPUFreq之二:核心(core)架構與API中的第4節和圖4.1,如果policy認為這是一個新的governor(和原來使用的舊的governor不相同),policy會通過__cpufreq_governor函式,并傳遞CPUFREQ_GOV_POLICY_INIT引數,而__cpufreq_governor函式實際上是呼叫cpufreq_governor結構中的governor回呼函式,在第2節中我們已經知道,這個回呼最后會進入governor公共API:cpufreq_governor_dbs,下面是它收到CPUFREQ_GOV_POLICY_INIT引數時,經過簡化后的代碼片段:
case CPUFREQ_GOV_POLICY_INIT:
......
dbs_data = https://www.cnblogs.com/linhaostudy/p/kzalloc(sizeof(*dbs_data), GFP_KERNEL);
......
dbs_data->cdata = cdata;
dbs_data->usage_count = 1;
rc = cdata->init(dbs_data);
......
rc = sysfs_create_group(get_governor_parent_kobj(policy),
get_sysfs_attr(dbs_data));
......
policy->governor_data = dbs_data;
......
/* Bring kernel and HW constraints together */
dbs_data->min_sampling_rate = max(dbs_data->min_sampling_rate,
MIN_LATENCY_MULTIPLIER * latency);
set_sampling_rate(dbs_data, max(dbs_data->min_sampling_rate,
latency * LATENCY_MULTIPLIER));
if ((cdata->governor == GOV_CONSERVATIVE) &&
(!policy->governor->initialized)) {
struct cs_ops *cs_ops = dbs_data->cdata->gov_ops;
cpufreq_register_notifier(cs_ops->notifier_block,
CPUFREQ_TRANSITION_NOTIFIER);
}
if (!have_governor_per_policy())
cdata->gdbs_data = dbs_data;
return 0;
首先,它會給這個policy分配一個dbs_data實體,然后把通過引數cdata傳入的common_dbs_data指標,賦值給它的cdata欄位,這樣,policy就可以通過該欄位獲得governor的操作介面(通過cdata的一系列回呼函式),然后,呼叫cdata的init回呼函式,對這個governor做進一步的初始化作業,對于ondemand來說,init回呼的實際執行函式是:od_init,主要是完成和governor相關的一些調節引數的初始化,然后把初始化好的od_dbs_tuners結構指標賦值到dbs_data的tuners欄位中,它的詳細代碼這里就不貼出了,接著,通過sysfs_create_group函式,建立該governor在sysfs中的節點,以后我們就可以通過這些節點對該governor的演算法邏輯進行微調,ondemand在我的電腦中,建立了以下這些節點(sys/devices/system/cpu/cpufreq/ondemand):
sampling_rate;
io_is_busy;
up_threshold;
sampling_down_factor;
ignore_nice;
powersave_bias;
sampling_rate_min;
繼續,把初始化好的dbs_data結構賦值給policy的governor_data欄位,以方便以后的訪問,最后是通過set_sampling_rate設定governor的采樣周期,如果還有設定have_governor_per_policy,把dbs_data結構指標賦值給cdata結構的gdbs_data欄位,至此,governor的初始化作業完成,下面是整個程序的序列圖:
4. 啟動一個governor
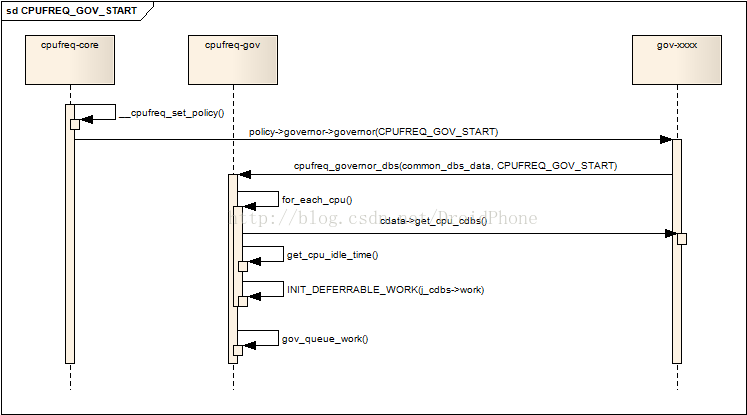
核心層會通過__cpufreq_set_policy函式,通過CPUFREQ_GOV_POLICY_INIT引數,在公共層的API:cpufreq_governor_dbs中,完成了對governor的初始化作業,緊接著,__cpufreq_set_policy會通過CPUFREQ_GOV_START引數,和初始化governor的流程一樣,最侄訓到達cpufreq_governor_dbs函式中,我們看看它是如何啟動一個governor的:
case CPUFREQ_GOV_START:
if (!policy->cur)
return -EINVAL;
mutex_lock(&dbs_data->mutex);
for_each_cpu(j, policy->cpus) {
struct cpu_dbs_common_info *j_cdbs =
dbs_data->cdata->get_cpu_cdbs(j);
j_cdbs->cpu = j;
j_cdbs->cur_policy = policy;
j_cdbs->prev_cpu_idle = get_cpu_idle_time(j,
&j_cdbs->prev_cpu_wall, io_busy);
if (ignore_nice)
j_cdbs->prev_cpu_nice =
kcpustat_cpu(j).cpustat[CPUTIME_NICE];
mutex_init(&j_cdbs->timer_mutex);
INIT_DEFERRABLE_WORK(&j_cdbs->work,
dbs_data->cdata->gov_dbs_timer);
}
首先,遍歷使用該policy的所有的處于online狀態的cpu,針對每一個cpu,做以下動作:
- 取出該cpu相關聯的cpu_dbs_common_info結構指標,之前已經討論過,governor定義了一個per_cpu變數來定義各個cpu所對應的cpu_dbs_common_info結構,通過common_dbs_data結構的回呼函式可以獲取該結構的指標,
- 初始化cpu_dbs_common_info結構的cpu,cur_policy,prev_cpu_idle,prev_cpu_wall,prev_cpu_nice欄位,其中,prev_cpu_idle,prev_cpu_wall這兩個欄位會被以后的負載計算所使用,
- 為每個cpu初始化一個作業佇列,作業佇列的執行函式是common_dbs_data結構中的gov_dbs_timer欄位所指向的回呼函式,對于ondemand來說,該函式是:od_dbs_timer,這個作業佇列會被按照設定好的采樣率定期地被喚醒,進行cpu負載的統計作業,
然后,記錄目前的時間戳,調度初始化好的作業佇列在稍后某個時間點運行:
/* Initiate timer time stamp */
cpu_cdbs->time_stamp = ktime_get();
gov_queue_work(dbs_data, policy,
delay_for_sampling_rate(sampling_rate), true);
下圖表達了啟動一個governor的程序:
作業佇列被調度執行后,會在作業佇列的執行函式中進行cpu負載的統計作業,這個我們在下一節中討論,
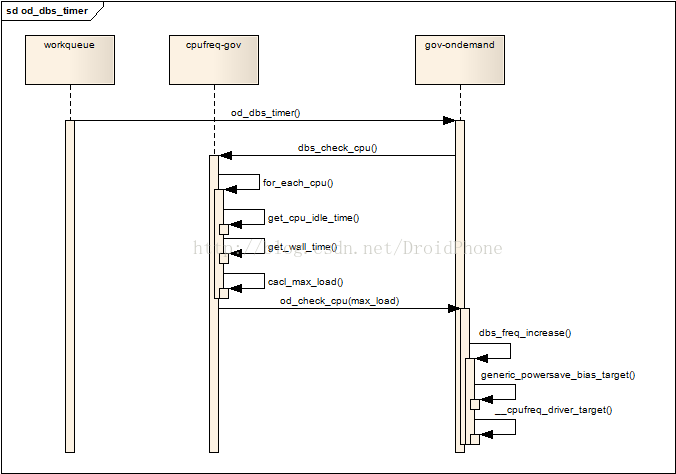
5. 系統負載的檢測
上一節我們提到,核心層啟動一個governor后,會在每個使用該governor的cpu上建立一個作業佇列,作業佇列的執行函式是在common_dbs_data中gov_dbs_timer欄位所指向的函式,理所當然,該函式由各個governor的具體代碼來實作,對于ondemand governor,它的實作函式是od_dbs_timer,governor的公共層代碼為我們提供了一個API:dbs_check_cpu,該API用來計算兩個統計周期期間某個cpu的負載情況,我們先分析一下dbs_check_cpu:
void dbs_check_cpu(struct dbs_data *dbs_data, int cpu)
{
struct cpu_dbs_common_info *cdbs = dbs_data->cdata->get_cpu_cdbs(cpu);
......
policy = cdbs->cur_policy;
/* Get Absolute Load (in terms of freq for ondemand gov) */
for_each_cpu(j, policy->cpus) {
struct cpu_dbs_common_info *j_cdbs;
......
j_cdbs = dbs_data->cdata->get_cpu_cdbs(j);
......
cur_idle_time = get_cpu_idle_time(j, &cur_wall_time, io_busy);
wall_time = (unsigned int)
(cur_wall_time - j_cdbs->prev_cpu_wall);
j_cdbs->prev_cpu_wall = cur_wall_time;
idle_time = (unsigned int)
(cur_idle_time - j_cdbs->prev_cpu_idle);
j_cdbs->prev_cpu_idle = cur_idle_time;
......
load = 100 * (wall_time - idle_time) / wall_time;
......
load *= cur_freq; /* 實際的代碼不是這樣,為了簡化討論,精簡為實際的計算邏輯*/
if (load > max_load)
max_load = load;
}
dbs_data->cdata->gov_check_cpu(cpu, max_load);
}
由代碼可以看出,遍歷該policy下每個online的cpu,取出該cpu對應的cpu_dbs_common_info結構,該結構中的prev_cpu_idle和prev_cpu_wall保存有上一次采樣周期時記錄的idle時間和運行時間,負載的計算其實很簡單:
- idle_time = 本次idle時間 - 上次idle時間;
- wall_time = 本次總運行時間 - 上次總運行時間;
- 負載load = 100 * (wall_time - idle_time)/ wall_time;
- 把所有cpu中,負載最大值記入max_load中,作為選擇頻率的依據;
計算出最大負載max_load后,呼叫具體governor實作的gov_check_cpu回呼函式,對于ondemand來說,該回呼函式是:od_check_cpu,我們跟進去看看:
static void od_check_cpu(int cpu, unsigned int load_freq)
{
struct od_cpu_dbs_info_s *dbs_info = &per_cpu(od_cpu_dbs_info, cpu);
struct cpufreq_policy *policy = dbs_info->cdbs.cur_policy;
struct dbs_data *dbs_data = https://www.cnblogs.com/linhaostudy/p/policy->governor_data;
struct od_dbs_tuners *od_tuners = dbs_data->tuners;
dbs_info->freq_lo = 0;
/* Check for frequency increase */
if (load_freq > od_tuners->up_threshold * policy->cur) {
/* If switching to max speed, apply sampling_down_factor */
if (policy->cur < policy->max)
dbs_info->rate_mult =
od_tuners->sampling_down_factor;
dbs_freq_increase(policy, policy->max);
return;
}
當負載比預設的閥值高時(od_tuners->up_threshold,默認值是95%),立刻選擇該policy最大的作業頻率作為接下來的作業頻率,如果負載沒有達到預設的閥值,但是當前頻率已經是最低頻率了,則什么都不做,直接回傳:
if (policy->cur == policy->min)
return;
運行到這里,cpu的頻率可能已經在上面的程序中被設定為最大頻率,實際上我們可能并不需要這么高的頻率,所以接著判斷,當負載低于另一個預設值時,這時需要計算一個合適于該負載的新頻率:
if (load_freq < od_tuners->adj_up_threshold
* policy->cur) {
unsigned int freq_next;
freq_next = load_freq / od_tuners->adj_up_threshold;
/* No longer fully busy, reset rate_mult */
dbs_info->rate_mult = 1;
if (freq_next < policy->min)
freq_next = policy->min;
if (!od_tuners->powersave_bias) {
__cpufreq_driver_target(policy, freq_next,
CPUFREQ_RELATION_L);
return;
}
freq_next = od_ops.powersave_bias_target(policy, freq_next,
CPUFREQ_RELATION_L);
__cpufreq_driver_target(policy, freq_next, CPUFREQ_RELATION_L);
}
}
對于ondemand來說,因為傳入的負載是乘上了當前頻率后的歸一化值,所以計算新頻率時,直接用load_freq除以想要的負載即可,本來計算出來的頻率直接通過__cpufreq_driver_target函式,交給cpufreq_driver調節頻率即可,但是這里的處理考慮了powersave_bias的設定情況,當設定了powersave_bias時,表明我們為了進一步節省電力,我們希望在計算出來的新頻率的基礎上,再乘以一個powersave_bias設定的百分比,作為真正的運行頻率,powersave_bias的值從0-1000,每一步代表0.1%,實際的情況比想象中稍微復雜一點,考慮到乘以一個powersave_bias后的新頻率可能不在cpu所支持的頻率表中,ondemand演算法會在頻率表中查找,分別找出最接近新頻率的一個區間,由高低兩個頻率組成,低的頻率記入od_cpu_dbs_info_s結構的freq_lo欄位中,高的頻率通過od_ops.powersave_bias_target回呼回傳,同時,od_ops.powersave_bias_target回呼函式還計算出高低兩個頻率應該運行的時間,分別記入od_cpu_dbs_info_s結構的freq_hi_jiffies和freq_low_jiffies欄位中,原則是,通過兩個不同頻率的運行時間的組合,使得綜合結果接近我們想要的目標頻率,詳細的計算邏輯請參考函式:generic_powersave_bias_target,
討論完上面兩個函式,讓我們回到本節的開頭,負載的計算作業是在一個作業佇列中發起的,前面說過,ondemand對應的作業佇列的作業函式是od_dbs_timer,我們看看他的實作代碼:
static void od_dbs_timer(struct work_struct *work)
{
......
/* Common NORMAL_SAMPLE setup */
core_dbs_info->sample_type = OD_NORMAL_SAMPLE;
if (sample_type == OD_SUB_SAMPLE) {
delay = core_dbs_info->freq_lo_jiffies;
__cpufreq_driver_target(core_dbs_info->cdbs.cur_policy,
core_dbs_info->freq_lo, CPUFREQ_RELATION_H);
} else {
dbs_check_cpu(dbs_data, cpu);
if (core_dbs_info->freq_lo) {
/* Setup timer for SUB_SAMPLE */
core_dbs_info->sample_type = OD_SUB_SAMPLE;
delay = core_dbs_info->freq_hi_jiffies;
}
}
max_delay:
if (!delay)
delay = delay_for_sampling_rate(od_tuners->sampling_rate
* core_dbs_info->rate_mult);
gov_queue_work(dbs_data, dbs_info->cdbs.cur_policy, delay, modify_all);
mutex_unlock(&core_dbs_info->cdbs.timer_mutex);
}
如果sample_type是OD_SUB_SAMPLE時,表明上一次采樣時,需要用高低兩個頻率來模擬實際的目標頻率中的第二步:需要運行freq_lo,并且持續時間為freq_lo_jiffies,否則,呼叫公共層計算負載的API:dbs_check_cpu,開始一次新的采樣,當powersave_bias沒有設定時,該函式回傳前,所需要的新的目標頻率會被設定,考慮到powersave_bias的設定情況,判斷一下如果freq_lo被設定,說明需要用高低兩個頻率來模擬實際的目標頻率,高頻率已經在dbs_check_cpu回傳前被設置(實際的設定作業是在od_check_cpu中),所以把sample_type設定為OD_SUB_SAMPLE,以便下一次運行作業函式進行采樣時可以設定低頻率運行,最后,調度作業佇列在下一個采樣時刻再次運行,這樣,cpu的作業頻率實作了在每個采樣周期,根據實際的負載情況,動態地設定合適的作業頻率進行運行,既滿足了性能的需求,也降低了系統的功耗,達到了cpufreq系統的最終目的,整個流程可以參考下圖:
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/4945.html
標籤:嵌入式