我有一個串列串列,串列的每個子串列都包含用于從資料框中過濾文本的關鍵字。
keywords = [[('tarifa',), ('mantenimiento',), ('mensual',)],
[('tasa',), ('anual',)],
[('seguro',), ('bancaria',)],
[('seguro',), ('generales',)],
[('mi salud',), ('unific',)]]
我曾經通過手動輸入關鍵字來過濾,如下所示:
#for sublist 1:
kw_s = kw_df[kw_df['transaction_description'].str.contains('tarifa') & kw_df['transaction_description'].str.contains('mantenimiento') & kw_df['transaction_description'].str.contains('mensual')]
#for sublist 2:
kw_s = kw_df[kw_df['transaction_description'].str.contains('seguro') & kw_df['transaction_description'].str.contains('generales')]
現在我必須根據mysql表中配置的關鍵字進行過濾。因此,我將關鍵字保存在串列串列中,但我不知道如何通過子串列提取關鍵字以過濾資料框。
知道我該怎么做嗎?
這是資料框的示例
user_id reg_id date transaction_description value
kw_df = [[5, 56, Timestamp('2022-01-29 00:00:00'), 'pac c.misalud conv. unificado', 12320.0],
[5, 57, Timestamp('2021-12-19 00:00:00'), 'cargo seguro proteccion bancaria', 31222.0],
[5, 60, Timestamp('2021-04-06 00:00:00'), 'pac sura cia seguros generales', 8657.0],
[5, 178, Timestamp('2022-03-21 00:00:00'), 'cargo seguro proteccion bancaria', 31222.0],
[5, 179, Timestamp('2022-03-01 00:00:00'), 'pac c.misalud conv. unificado', 12320.0],
[5, 182, Timestamp('2022-03-15 00:00:00'), 'pac sura cia seguros generales', 8657.0],
[5, 189, Timestamp('2022-04-21 00:00:00'), 'cargo seguro proteccion bancaria', 31222.0],
[5, 190, Timestamp('2022-04-01 00:00:00'), 'pac c.misalud conv. unificado', 12320.0],
[5, 193, Timestamp('2022-04-15 00:00:00'), 'pac sura cia seguros generales', 8657.0],
[5, 206, Timestamp('2022-05-21 00:00:00'), 'cargo seguro proteccion bancaria', 31222.0],
[5, 256, Timestamp('2022-06-17 00:00:00'), 'cargo seguro proteccion bancaria', 40222.0]]
uj5u.com熱心網友回復:
如何通過可變的單詞子集過濾 DataFrame?
虛擬資料
import numpy as np
import pandas as pd
columns = ['transaction_description', 'value']
data = [
['pac c.misalud conv. unificado', 12320.0],
['cargo seguro proteccion bancaria', 31222.0],
['pac sura cia seguros generales', 8657.0],
['cargo seguro proteccion bancaria', 31222.0],
['pac c.misalud conv. unificado', 12320.0],
['pac sura cia seguros generales', 8657.0],
['cargo seguro proteccion bancaria', 31222.0],
['pac c.misalud conv. unificado', 12320.0],
['pac sura cia seguros generales', 8657.0],
['cargo seguro proteccion bancaria', 31222.0],
['cargo seguro proteccion bancaria', 40222.0]]
df=pd.DataFrame(data, columns=columns)
keywords = [
[('tarifa',), ('mantenimiento',), ('mensual',)],
[('tasa',), ('anual',)],
[('seguro',), ('bancaria',)],
[('seguro',), ('generales',)],
[('mi salud',), ('unific',)]]
求解
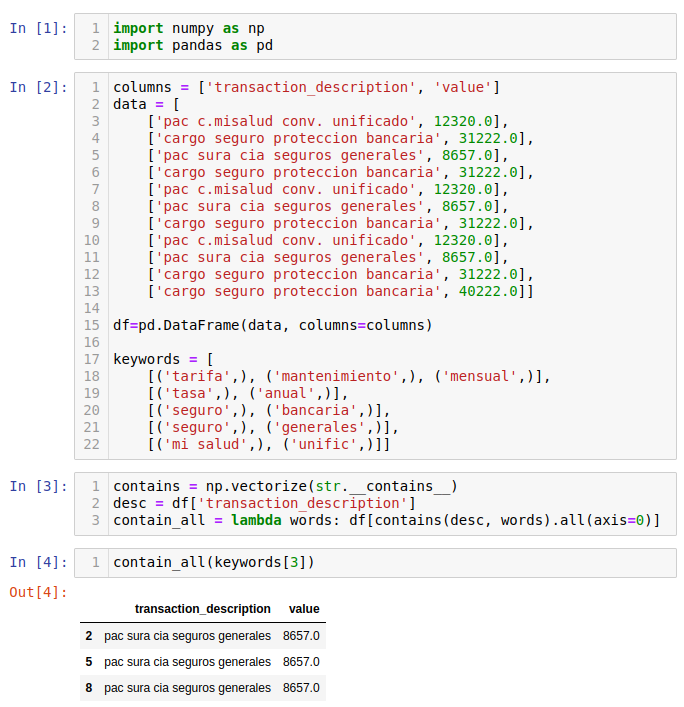
我將使用一種結構,其中子串列的單詞按列排列,或者更準確地說,每個單詞作為元組的唯一元素放置在串列中。
讓我們矢量化str.__contains__以使str1 in str2代碼適用于陣列:
contains = np.vectorize(str.__contains__)
現在,我將df["transaction_description"]在第四組關鍵字上測驗此功能[('seguro',), ('generales',)],例如:
desc = df['transaction_description']
contains(desc, keywords[3])
在這種情況下,我們得到以下結果:
array([[False, True, True, True, False, True, True, False, True, True, True],
[False, False, True, False, False, True, False, False, True, False, False]])
現在,要查看是否可以在描述中找到該子集的所有單詞,我們all沿前一個矩陣的第一個索引應用該方法:
df[contains(desc, keywords[3]).all(axis=0)]
我們得到這些過濾后的資料:
transaction_description value
2 pac sura cia seguros generales 8657.0
5 pac sura cia seguros generales 8657.0
8 pac sura cia seguros generales 8657.0
長話短說
contains = np.vectorize(str.__contains__)
desc = df['transaction_description']
contain_all = lambda words: df[contains(desc, words).all(axis=0)]
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/494936.html