寫在前面
本系列的文章是博主邊學邊記錄的,可能不是特別的正確,因為會加上博主自己的理解,僅供參考,
正文:
為了能夠將用戶程式裝入記憶體,必須為它分配一定大小的記憶體空間,常見的分配方式有:
1.連續分配
連續分配方式是最早出現的一種存盤器分配方式,該分配方式為一個用戶程式分配一個連續的記憶體空間,常見的連續分配方式有:
1.單一連續分配
單一連續分配適合早期的單道批作業系統,在用戶區中,僅裝入一道用戶程式,整個記憶體的用戶空間由該程式獨占,這樣的存盤器分配方式稱為單一連續分配,
2.固定磁區分配
在多道程式系統中,為了在記憶體中裝土多道程式,且這些程式之間又不會發生相互干擾,于是將整個用戶空間劃分成若干隔固定大小的區域,每個磁區中只裝入一道作業,這樣形成了最早、也是最簡單的一種可運行多道程式的磁區式存盤管理方式,
劃分磁區的方法:
1.將用戶空間劃分成若干個固定大小的磁區
這種分配方式缺乏靈活性,但是對于利用一臺計算機同時控制多個相同大小物件的場合,這種劃分方式比較方便和使用,
2.將用戶空間劃分成若干個大小不定的磁區
這種分配方式靈活性較高,通常式根據用戶的需求來進行劃分,為不同大小的行程分配不同的記憶體空間,
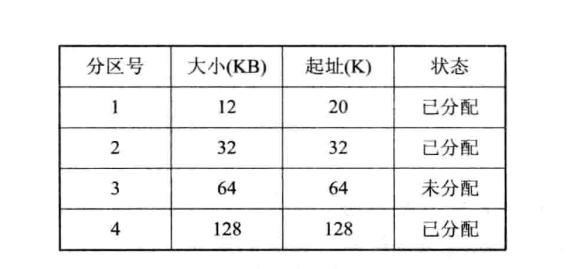
磁區表:
為了便于記憶體的管理,通常將記憶體按照其大小進行排隊,并為之建立一張磁區使用表,
磁區表包括每個磁區的起始地址,大小、狀態等,
3.動態磁區分配
為了實作動態磁區分配,系統配置了相應的一些資料機構,用以描述空閑磁區和已分配磁區的情況,常見的資料結構有:
1.空閑磁區表
在系統中設定一張空閑磁區表,用戶記錄每個空閑磁區的情況,包括磁區號、大小、起始地址等,
2.空閑磁區鏈
以鏈表形式組織空閑磁區,
3.動態磁區分配演算法
為了實作動態分配呢,通常將系統中的空閑磁區鏈接成一個鏈,下面介紹下基于順序搜索的動態磁區分配演算法:
所謂順序搜索,是指依次搜索空閑磁區鏈上的空閑磁區,去尋找一個其大小能夠滿足要求的磁區,常見的演算法有:
1.首次適應演算法 FF
特點:
空閑磁區鏈以地址遞增的次序鏈接,
流程:
每次都從鏈首開始順序查找,直至找到一個大小能滿足要求的空閑磁區為止,然后進行切割分配,
優點:
該演算法優先利用記憶體中低地址的部分的空閑磁區,從而保留了高地址部分的大空閑區,為大作業分分配大的記憶體空間創建了條件,
缺點:
1.每次查找都從頭部開始,會增加查找可用空閑磁區的開銷
2.低地址部分不斷被劃分,會留下很多難以利用的小空間,也就是外部碎片,浪費記憶體空間,
2.回圈首次適應演算法 NF
區別于首次適應演算法,NF不再是每次都從鏈首開始查找,而是從上次找到的空閑磁區的下一個空閑磁區開始查找,直至找到一個能滿足要求的空閑磁區,
3.最佳適應演算法 BF
最佳適應演算法,每次分配空間的時候,總是把能滿足要求、又是最小的空閑磁區分配給作業,避免"大材小用"
同樣也是從遞增的方式形成空閑鏈表,每次分配完記憶體后,要進行及時的調整,保證鏈表的遞增性,
該種分配方式,也同樣有可能造成碎片化,
4.最壞適應演算法 WF
以遞減的方式形成空閑鏈表,分配作業的時候,總是挑選一個最大的空閑磁區,從中分割一部分存盤空間給作業使用,
缺點:
導致存盤器中缺乏大的空閑磁區,所以稱為最壞適應演算法,
提一個問題,BF和WF真的就是最好或者最壞的嗎?
其實不然,BF看似每次分配的都是最佳的方式,但是每次分配后所切割下來的剩余部分總是最小的,這樣會形成大量的碎片,
而WF,由于每次都是從大空間中切分出去要分配的空閑,可使剩下的空閑磁區不至于太小,產生碎片的可能性小,對中、小型作業有利,WF查找效率也很高,查找的時候只需要看第一個磁區能否滿足作業要求即可,
可見,沒有最好和最壞一說,各有所長,也各有所短,
4.動態可重定位磁區分配
首先在這里面涉及一個"緊湊"的概念,就是將記憶體中不相鄰的作業移動,使得之間間距的空間碎片聚集到一起,形成一個空用的空間,看下圖應該就懂了.......
可以看到后,緊湊后,空間得以重新利用,但是程式的地址也發生了改變,所以在每次緊湊后,都必須對移動的程式和資料進行重定位,但是這樣做,很是麻煩,于是引入了動態重定位:
為了使得地址的轉換為不會影響到指令的執行速度,必須有硬體地址變換機構的支持,于是引入一個重定位暫存器,用它來存放程式在記憶體中起始地址,
2.離散分配
上面我們了解了連續分配會形成許多碎片,雖然可以通過緊湊方法將許多碎片拼接成可用的大塊空間,但是必須付出很大的開銷,如果允許將一個行程直接分散的裝入去多不相鄰接的磁區中,便可以充分的利用記憶體空間,而無須再進行緊湊,
基于這一思想,產生了離散分配方式,根據離散分配時所分配地址空間的基本單位的不同,又可以將離散分配分為以下三種:
1.分頁存盤管理方式
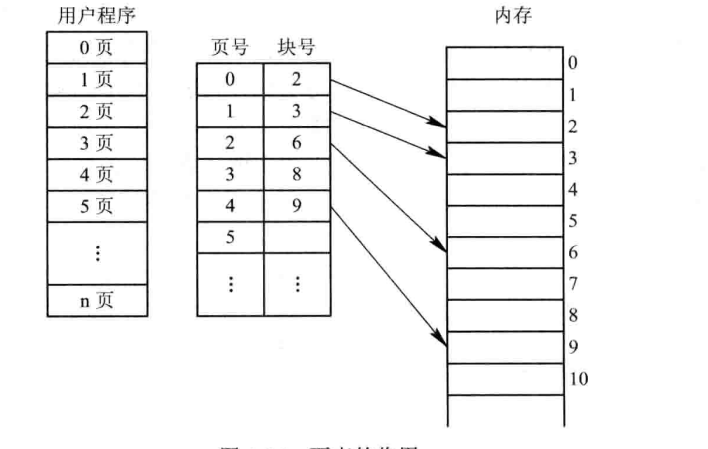
分頁存盤管理方式,個人理解的是將用戶程式的離散的存入到不同的物理塊中,但是為了找到這些程式的地址,需要用一個資料結構來記錄,這個資料結構就是頁,當然一般情況下將頁組織起來,形成該程式的頁表,從而讓系統得知該程式分配在記憶體中的哪些物理塊中,
補充一下分頁涉及的概念:
1.頁面,分頁存盤管理將行程的邏輯地址空間分成若干個頁,并為各頁加以編號,同時也將記憶體的物理地址空間分成若干個塊,
一頁對應一個塊,在進行分配記憶體的時候,以塊為單位,將行程中的若干頁分別裝入到多個可以不相鄰的物理塊中,
2.頁面大小:顧名思義,但是頁面大小要適中選擇,不能過大也不能過小,
3.地址結構
分頁地址中的地址結構:

4.頁表
為了保證行程能夠在記憶體中找到每個頁面所對應的物理塊,系統為每個行程建立了一張頁面映像表,簡稱為頁表,
TLB(Translation Look aside Buffer) /快表:
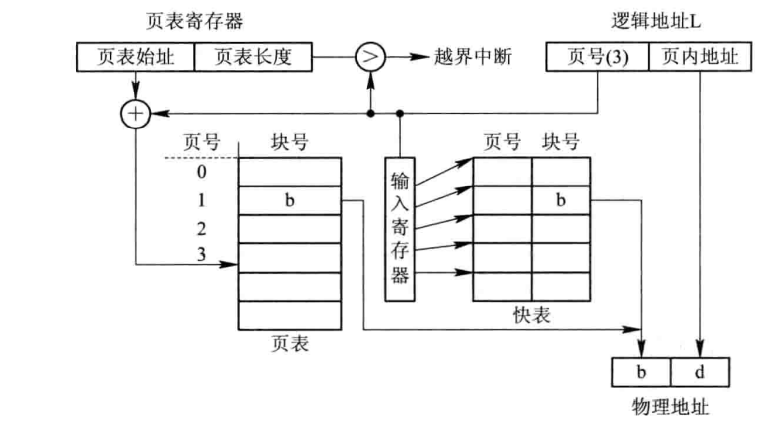
頁表是存放在記憶體中的,cpu每次存取一個資料的時候,都要訪問兩次記憶體,第一是訪問頁表,從中找到指定頁的物理塊號,形成物理地址,第二次是訪問該物理地址,并寫入或者取出資料,可見效率是比較低的,
為了提高地址的變換速度,可以設定一個緩沖暫存器,也就是TLB,用來存放之前訪問的那些頁表項,再進行查找的時候,可以先查找TLB,如果命中,可直接讀出改頁對應的物理塊號,并寫入物理地址暫存器中,
沒有命中的化,還是需要再次訪問頁表,后期把本次頁表項存入快表中,從而提高訪問的速度,
2.分段存盤管理方式
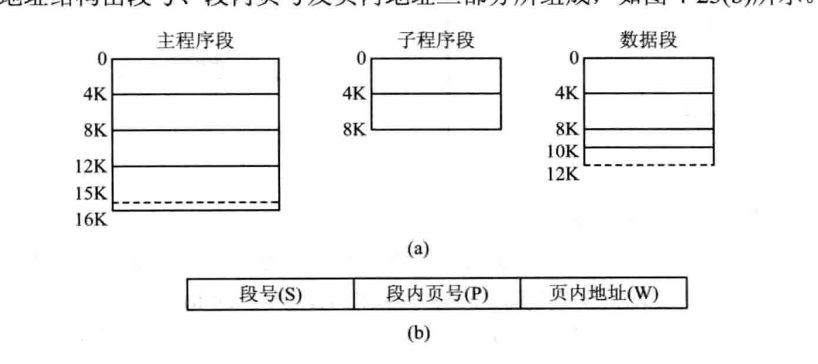
分段存盤管理方式主要是為了滿足用戶在編程和使用上多方面的要求,像主程式段、子程式段、資料段、堆疊段等等,因此分段存盤大小并不固定,因為每個段的大小并不是固定的,
分段地址的結構:

段表:和頁表的作用是一樣的,方便程式尋址,看一下段表的組成:
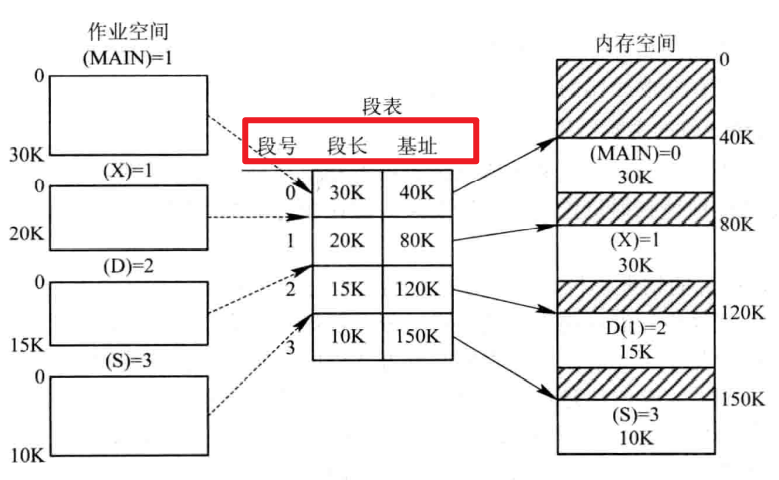
當采用分段的方式分配空間的時候,需要先比較磁區的大小也就是段長是否合適,否則是不能夠分配的,
3.段頁式存盤管理方式
分頁系統以頁面作為記憶體分配的基本單位,能夠有效的提高記憶體利用率,分段系統以段作為記憶體分配的基本單位,能夠更好地滿足用戶多方面地需求,所以,我們可以對這兩種存盤管理方式各取所長,則可形成一種新的存盤管理方式,也就是段頁式存盤管理方式,
分段和分頁是有很大區別的,下面具體來看下它們的區別吧!!
總結下分段和分頁的區別
1.分頁是系統管理上的需要,完全是系統來進行管理的,對于用戶是不可見的,分段目的主要是更好地滿足用戶地需求,是資訊邏輯上地單位,
2.頁得大小固定且有系統進行決定,這里指的是物理塊或者說頁面大小是固定的,但是分段則不是,每段的長度取決于用戶所撰寫的程式,
3.分頁的用戶程式地址空間是一維的,分段是二維的,因為程式員在編程的時候需要給出段名和段內地址,
以上就是本文的所有內容了,我們下篇再見
不驕不躁,保持學習
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/500564.html
標籤:其他
上一篇:Linux 文本編輯工具vim