1. 前言
筆者在 《從 Linux 內核角度看 IO 模型的演變》一文中曾對 Socket 檔案在內核中的相關資料結構為大家做了詳盡的闡述,
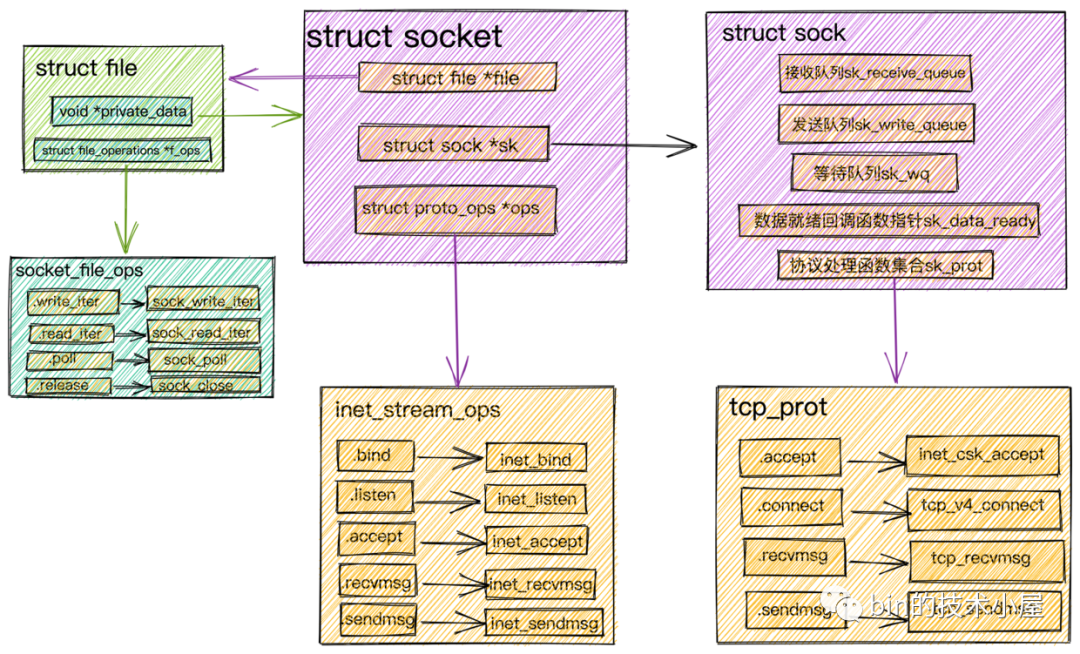
又在此基礎之上介紹了針對 socket 檔案的相關操作及其對應在內核中的處理流程:
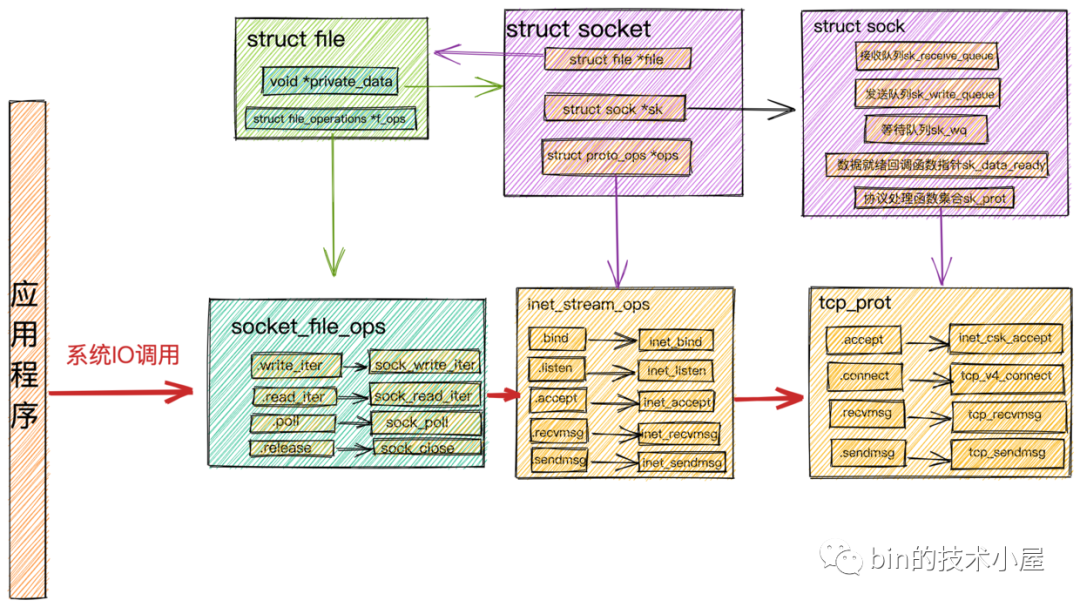
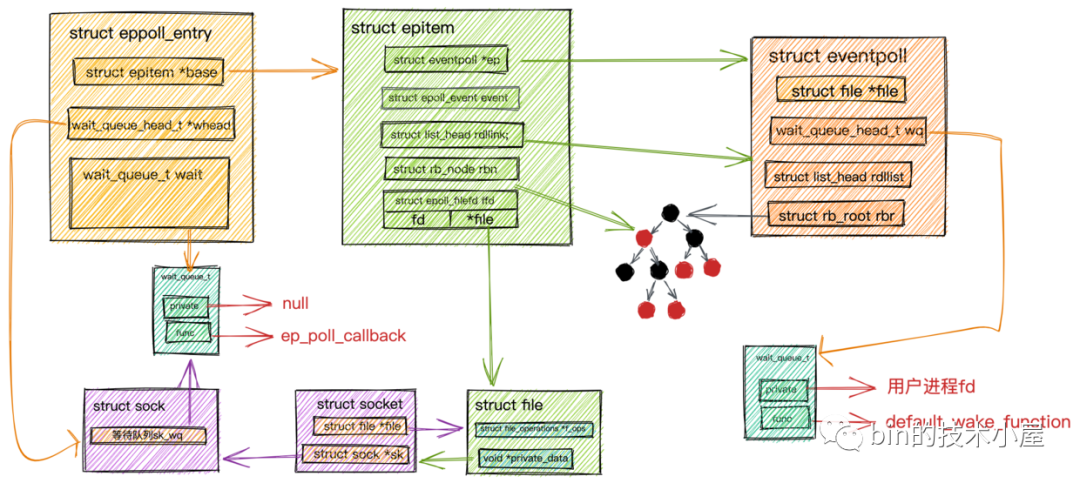
并與 epoll 的作業機制進行了串聯:
通過這些內容的串聯介紹,我想大家現在一定對 socket 檔案非常熟悉了,在我們利用 socket 檔案介面在與內核進行網路資料讀取,發送的相關互動的時候,不可避免的涉及到一個新的問題,就是我們如何在用戶空間設計一個位元組緩沖區來高效便捷的存盤管理這些需要和 socket 檔案進行互動的網路資料,
于是筆者又在 《一步一圖帶你深入剖析 JDK NIO ByteBuffer 在不同位元組序下的設計與實作》 一文中帶大家從 JDK NIO Buffer 的頂層設計開始,詳細介紹了 NIO Buffer 中的頂層抽象設計以及行為定義,隨后我們選取了在網路應用程式中比較常用的 ByteBuffer 來詳細介紹了這個Buffer具體型別的實作,并以 HeapByteBuffer 為例說明了JDK NIO 在不同位元組序下的 ByteBuffer 實作,
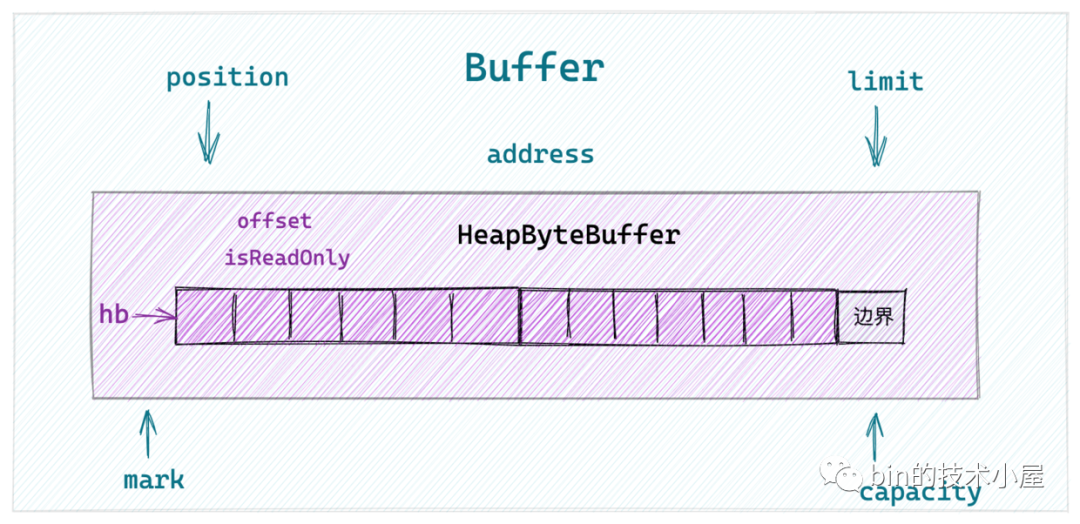
現在我們已經熟悉了 socket 檔案的相關操作及其在內核中的實作,但筆者覺得這還不夠,還是有必要在為大家介紹一下 JDK NIO 如何利用 ByteBuffer 對普通檔案進行讀寫的相關原理及其實作,為大家徹底打通 Linux 檔案操作相關知識的系統脈絡,于是就有了本文的內容,
下面就讓我們從一個普通的 IO 讀寫操作開始聊起吧~~~

2. JDK NIO 讀取普通檔案
我們先來看一個利用 NIO FileChannel 來讀寫普通檔案的例子,由這個簡單的例子開始,慢慢地來一步一步深入本質,
JDK NIO 中的 FileChannel 比較特殊,它只能是阻塞的,不能設定非阻塞模式,FileChannel的讀寫方法均是執行緒安全的,
注意:下面的例子并不是最佳實踐,之所以這里引入 HeapByteBuffer 是為了將上篇文章的內容和本文銜接起來,事實上,對于 IO 的操作一般都會選擇 DirectByteBuffer ,關于 DirectByteBuffer 的相關內容筆者會在后面的文章中詳細為大家介紹,
FileChannel fileChannel = new RandomAccessFile(new File("file-read-write.txt"), "rw").getChannel();
ByteBuffer heapByteBuffer = ByteBuffer.allocate(4096);
fileChannel.read(heapByteBuffer);
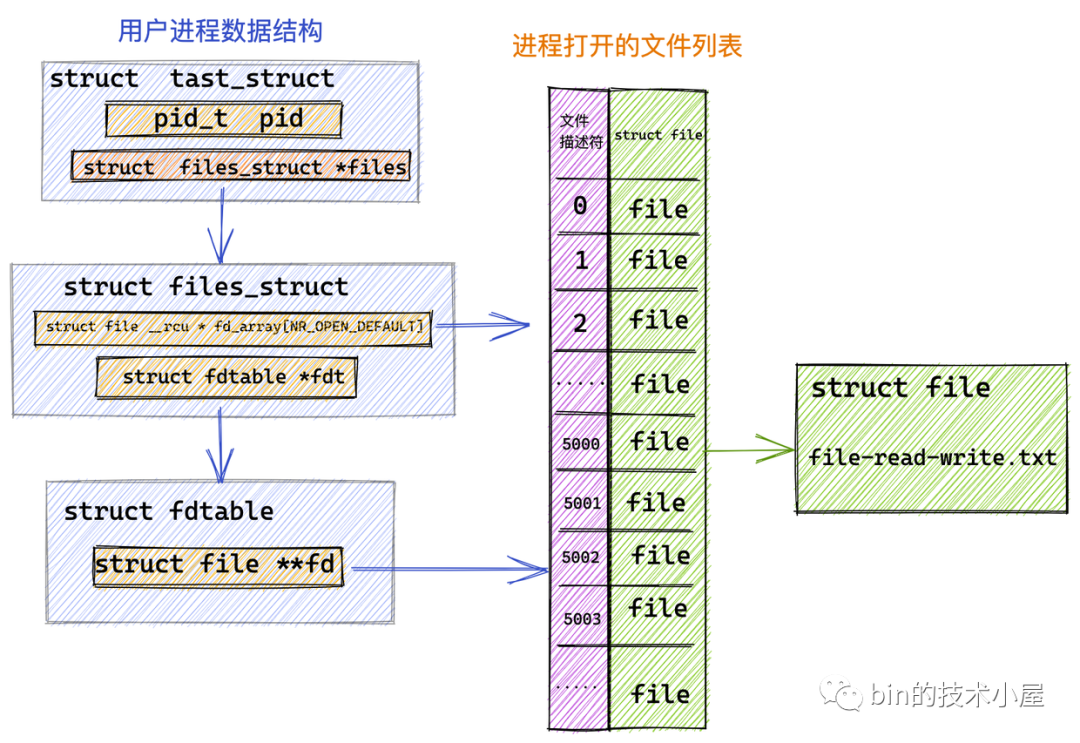
我們首先利用 RandomAccessFile 在內核中打開指定的檔案 file-read-write.txt 并獲取到它的檔案描述符 fd = 5000,
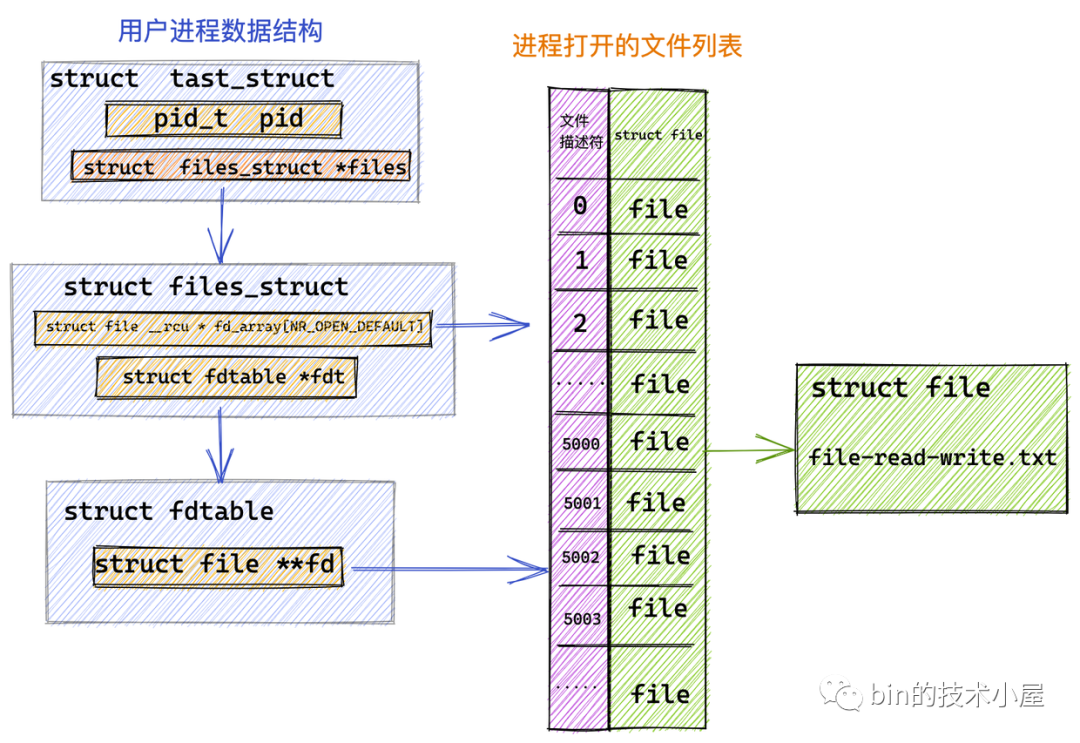
隨后我們在 JVM 堆中開辟一塊 4k 大小的虛擬記憶體 heapByteBuffer,用來讀取檔案中的資料,
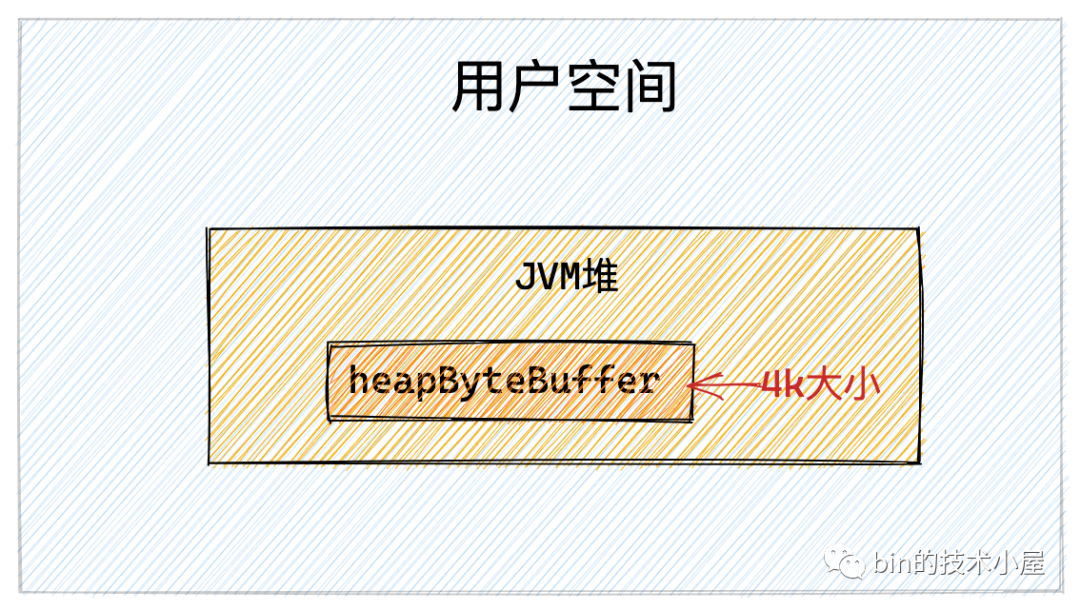
作業系統在管理記憶體的時候是將記憶體分為一頁一頁來管理的,每頁大小為 4k ,我們在操作記憶體的時候一定要記得進行頁對齊,也就是偏移位置以及讀取的記憶體大小需要按照 4k 進行對齊,具體為什么?文章后邊會從內核角度詳細為大家介紹,
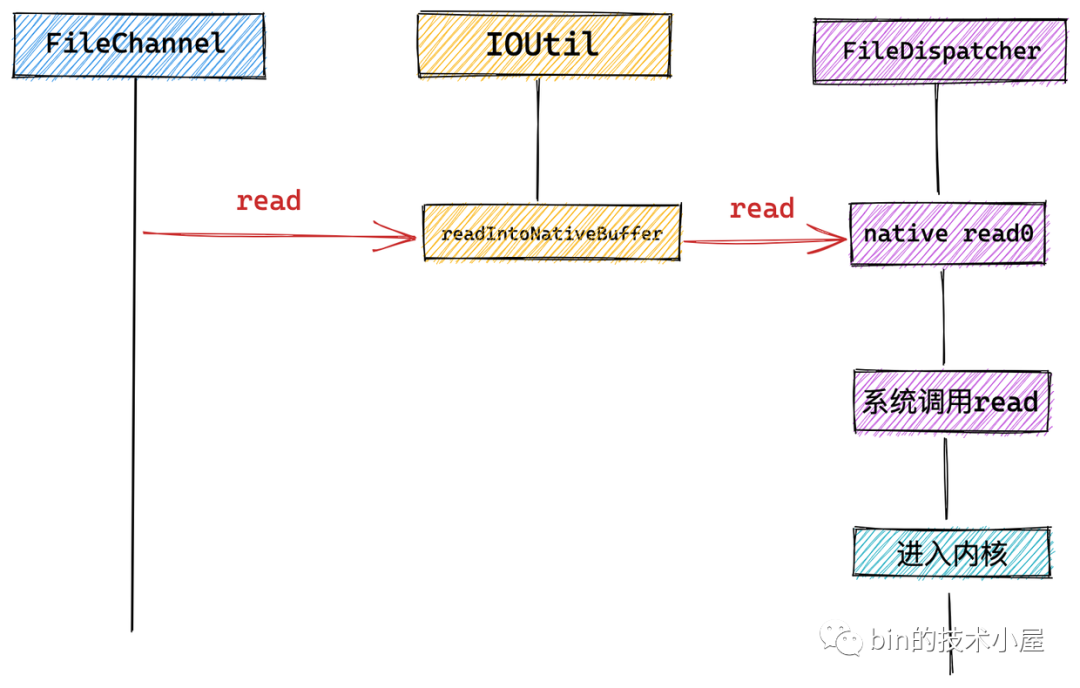
最后通過 FileChannel#read 方法觸發底層系統呼叫 read,進行檔案讀取,
public class FileChannelImpl extends FileChannel {
// 前邊介紹打開的檔案描述符 5000
private final FileDescriptor fd;
// NIO 中用它來觸發 native read 和 write 的系統呼叫
private final FileDispatcher nd;
// 讀寫檔案時加鎖,前邊介紹 FileChannel 的讀寫方法均是執行緒安全的
private final Object positionLock = new Object();
public int read(ByteBuffer dst) throws IOException {
synchronized (positionLock) {
.......... 省略 .......
try {
.......... 省略 .......
do {
n = IOUtil.read(fd, dst, -1, nd);
} while ((n == IOStatus.INTERRUPTED) && isOpen());
return IOStatus.normalize(n);
} finally {
.......... 省略 .......
}
}
}
}
我們看到在 FileChannel 中會呼叫 IOUtil 的 read 方法,NIO 中的所有 IO 操作全部封裝在 IOUtil 類中,
而 NIO 中的 SocketChannel 以及這里介紹的 FileChannel 底層依賴的系統呼叫可能不同,這里會通過 NativeDispatcher 對具體 Channel 操作實作分發,呼叫具體的系統呼叫,對于 FileChannel 來說 NativeDispatcher 的實作類為 FileDispatcher,對于 SocketChannel 來說 NativeDispatcher 的實作類為 SocketDispatcher,
下面我們進入 IOUtil 里面來一探究竟~~
public class IOUtil {
static int read(FileDescriptor fd, ByteBuffer dst, long position,
NativeDispatcher nd)
throws IOException
{
.......... 省略 .......
.... 創建一個臨時的directByteBuffer....
try {
int n = readIntoNativeBuffer(fd, directByteBuffer, position, nd);
.......... 省略 .......
.... 將directByteBuffer中讀取到的內容再次拷貝到heapByteBuffer中給用戶回傳....
return n;
} finally {
.......... 省略 .......
}
}
private static int readIntoNativeBuffer(FileDescriptor fd, ByteBuffer bb,
long position, NativeDispatcher nd)
throws IOException
{
int pos = bb.position();
int lim = bb.limit();
assert (pos <= lim);
int rem = (pos <= lim ? lim - pos : 0);
.......... 省略 .......
if (position != -1) {
.......... 省略 .......
} else {
n = nd.read(fd, ((DirectBuffer)bb).address() + pos, rem);
}
if (n > 0)
bb.position(pos + n);
return n;
}
}
我們看到 FileChannel 的 read 方法最侄訓呼叫到 NativeDispatcher 的 read 方法,前邊我們介紹了這里的 NativeDispatcher 就是 FileDispatcher 在 NIO 中的實作類為 FileDispatcherImpl,用來觸發 native 方法執行底層系統呼叫,
class FileDispatcherImpl extends FileDispatcher {
int read(FileDescriptor fd, long address, int len) throws IOException {
return read0(fd, address, len);
}
static native int read0(FileDescriptor fd, long address, int len)
throws IOException;
}
最終在 FileDispatcherImpl 類中觸發了 native 方法 read0 的呼叫,我們繼續到 FileDispatcherImpl.c 檔案中去查看 native 方法的實作,
// FileDispatcherImpl.c 檔案
JNIEXPORT jint JNICALL Java_sun_nio_ch_FileDispatcherImpl_read0(JNIEnv *env, jclass clazz,
jobject fdo, jlong address, jint len)
{
jint fd = fdval(env, fdo);
void *buf = (void *)jlong_to_ptr(address);
// 發起 read 系統呼叫進入內核
return convertReturnVal(env, read(fd, buf, len), JNI_TRUE);
}
系統呼叫 read(fd, buf, len) 最終是在 native 方法 read0 中被觸發的,下面是系統呼叫 read 在內核中的定義,
SYSCALL_DEFINE3(read, unsigned int, fd, char __user *, buf, size_t, count){
...... 省略 ......
}
這樣一來我們就從 JDK NIO 這一層逐步來到了用戶空間與內核空間的邊界處 --- OS 系統呼叫 read 這里,馬上就要進入內核了,
下面我們就來看一下當系統呼叫 read 發起之后,用戶行程在內核態具體做了哪些事情?
3. 從內核角度探秘檔案讀取本質
內核將檔案的 IO 操作根據是否使用記憶體(頁高速快取 page cache)做磁盤熱點資料的快取,將檔案 IO 分為:Buffered IO 和 Direct IO 兩種型別,
行程在通過系統呼叫 open() 打開檔案的時候,可以通過將引數 flags 賦值為 O_DIRECT 來指定檔案操作為 Direct IO,默認情況下為 Buffered IO,
int open(const char *pathname, int flags, mode_t mode);
而 Java 在 JDK 10 之前一直是不支持 Direct IO 的,到了 JDK 10 才開始支持 Direct IO,但是在 JDK 10 之前我們可以使用第三方的 Direct IO 框架 Jaydio 來通過 Direct IO 的方式對檔案進行讀寫操作,
Jaydio GitHub :https://github.com/smacke/jaydio
下面筆者就帶大家從內核角度深度剖析下這兩種 IO 型別各自的特點:
3.1 Buffered IO
大部分檔案系統默認的檔案 IO 型別為 Buffered IO,當行程進行檔案讀取時,內核會首先檢查檔案對應的頁高速快取 page cache 中是否已經快取了檔案資料,如果有則直接回傳,如果沒有才會去磁盤中去讀取檔案資料,而且還會根據非常精妙的預讀演算法來預先讀取后續若干檔案資料到 page cache 中,這樣等行程下一次順序讀取檔案時,想要的資料已經預讀進 page cache 中了,行程直接回傳,不用再到磁盤中去龜速讀取了,這樣一來就極大地提高了 IO 性能,
比如一些著名的訊息佇列中間件 Kafka , RocketMq 對訊息日志檔案進行順序讀取的時候,訪問速度接近于記憶體,這就是 Buffered IO 中頁高速快取 page cache 的功勞,在本文的后面,筆者會為大家詳細的介紹這一部分內容,
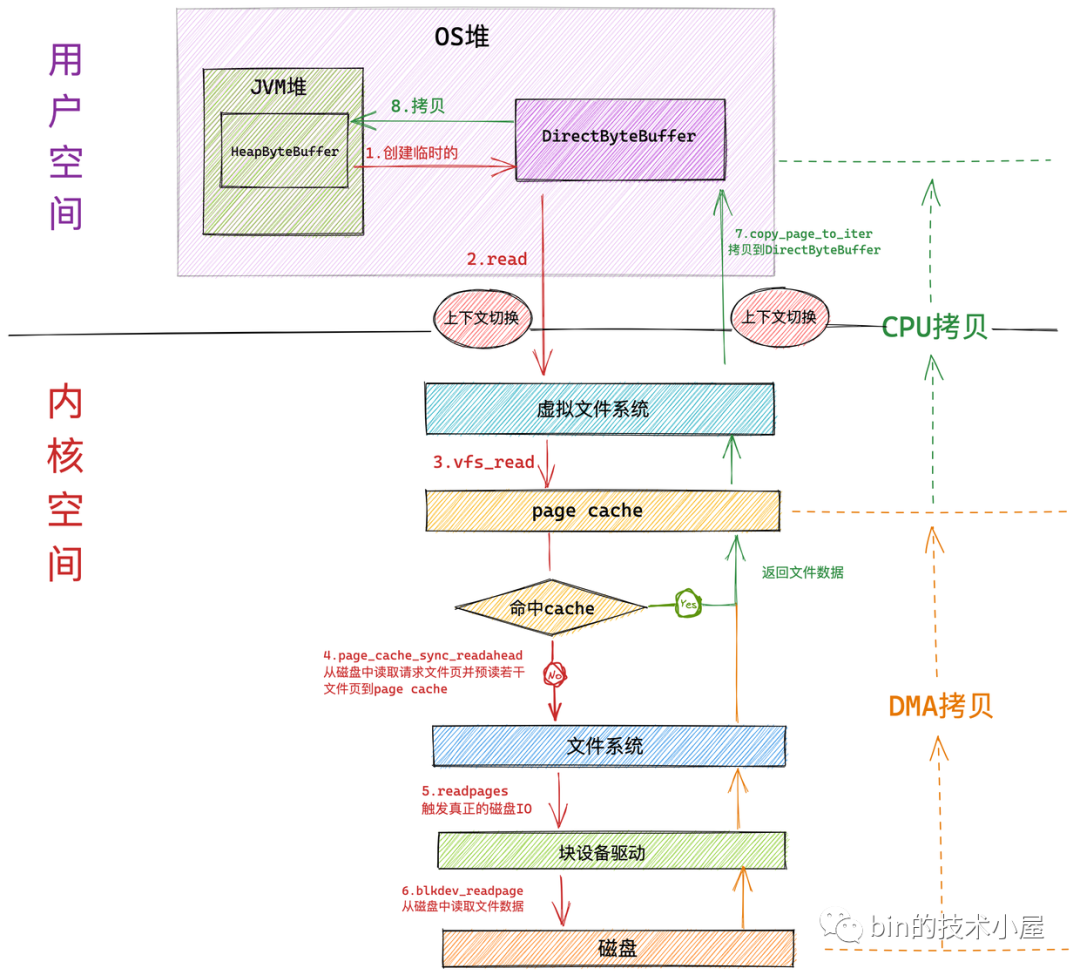
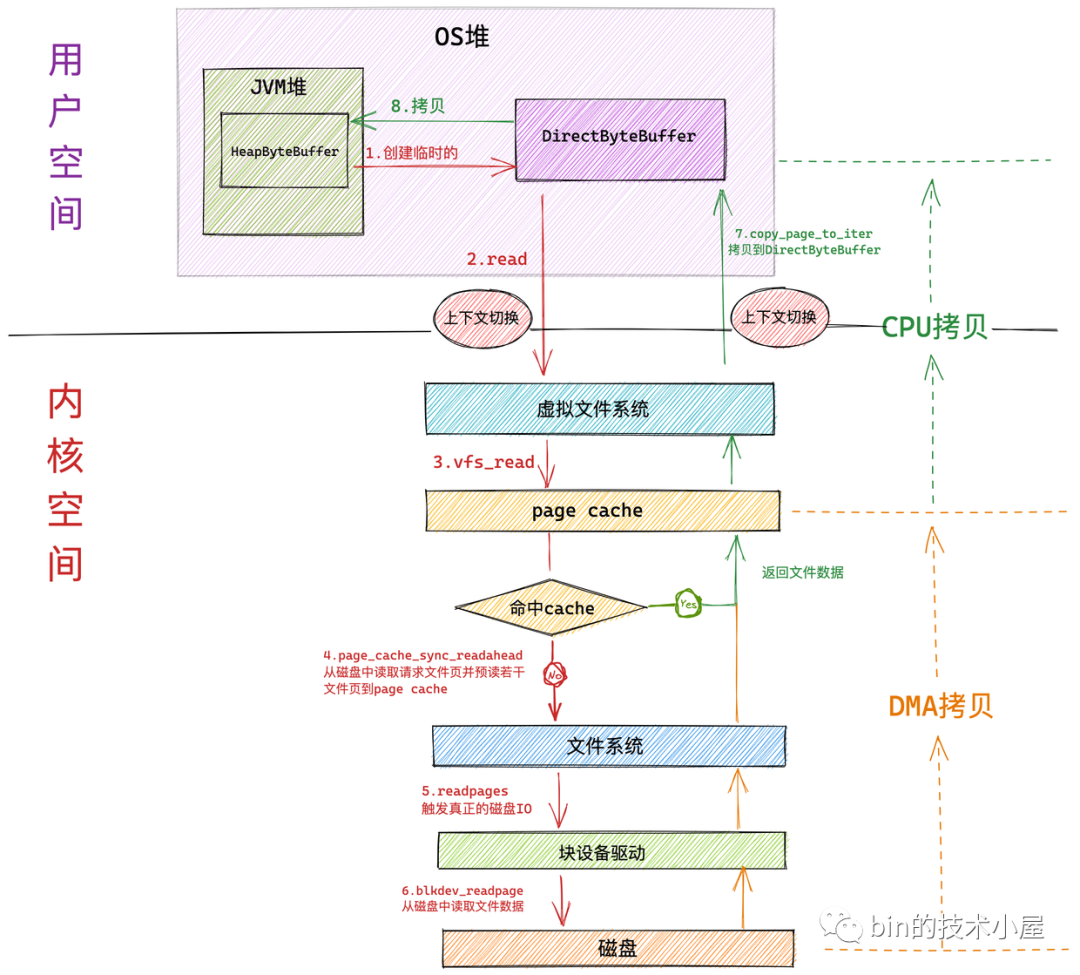
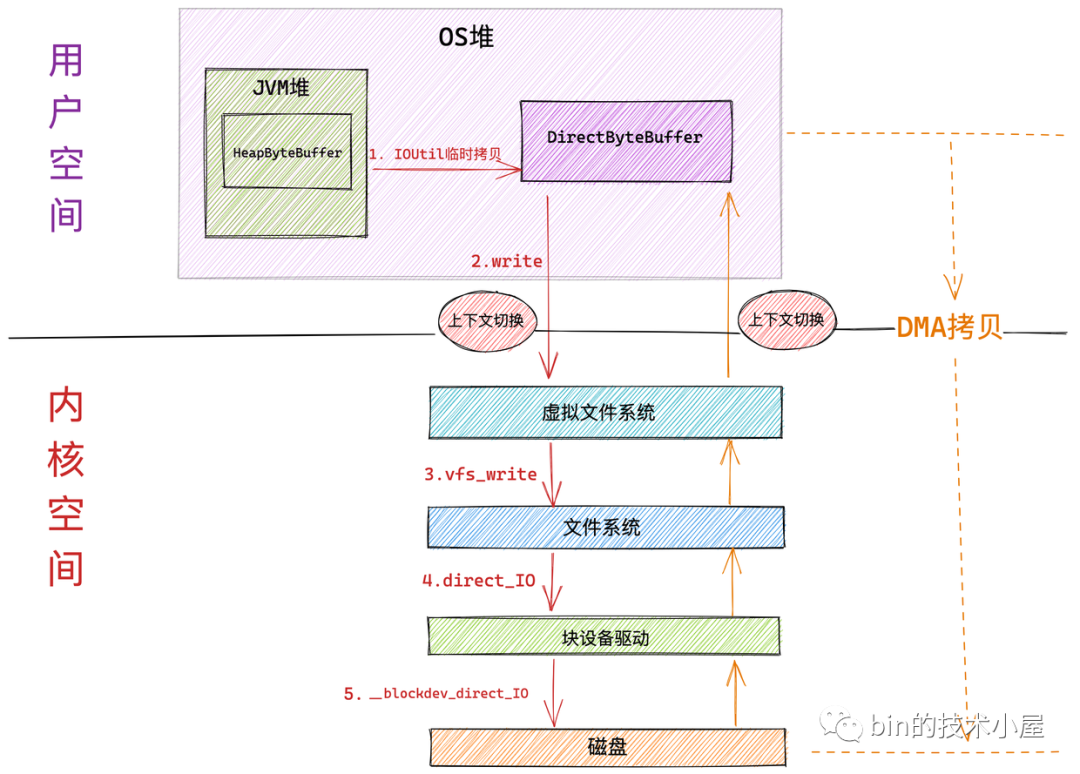
如果我們使用在上篇文章 《一步一圖帶你深入剖析 JDK NIO ByteBuffer 在不同位元組序下的設計與實作》 中介紹的 HeapByteBuffer 來接收 NIO 讀取檔案資料的時候,整個檔案讀取的程序分為如下幾個步驟:
- NIO 首先會將創建一個臨時的 DirectByteBuffer 用于臨時接收檔案資料,
具體為什么會創建一個臨時的 DirectByteBuffer 來接收資料以及關于 DirectByteBuffer 的原理筆者會在后面的文章中為大家詳細介紹,這里大家可以把它簡單看成在 OS 堆中的一塊虛擬記憶體地址,
-
隨后 NIO 會在用戶態呼叫系統呼叫 read 向內核發起檔案讀取的請求,此時發生第一次背景關系切換,
-
用戶行程隨即轉到內核態運行,進入虛擬檔案系統層,在這一層內核首先會查看讀取檔案對應的頁高速快取 page cache 中是否含有請求的檔案資料,如果有直接回傳,避免一次磁盤 IO,并根據內核預讀演算法從磁盤中異步預讀若干檔案資料到 page cache 中(檔案順序讀取高性能的關鍵所在),
在內核中,一個檔案對應一個 page cache 結構,注意:這個 page cache 在記憶體中只會有一份,
-
如果行程請求資料不在 page cache 中,則會進入檔案系統層,在這一層呼叫塊設備驅動程式觸發真正的磁盤 IO,并根據內核預讀演算法同步預讀若干檔案資料,請求的檔案資料和預讀的檔案資料將被一起填充到 page cache 中,
-
在塊設備驅動層完成真正的磁盤 IO,在這一層會從磁盤中讀取行程請求的檔案資料以及內核預讀的檔案資料,
-
磁盤控制器 DMA 將從磁盤中讀取的資料拷貝到頁高速快取 page cache 中,發生第一次資料拷貝,
-
隨后 CPU 將 page cache 中的資料拷貝到 NIO 在用戶空間臨時創建的緩沖區 DirectByteBuffer 中,發生第二次資料拷貝,
-
最后系統呼叫 read 回傳,行程從內核態切換回用戶態,發生第二次背景關系切換,
-
NIO 將 DirectByteBuffer 中臨時存放的檔案資料拷貝到 JVM 堆中的 HeapBytebuffer 中,發生第三次資料拷貝,
我們看到如果使用 HeapByteBuffer 進行 NIO 檔案讀取的整個程序中,一共發生了 兩次背景關系切換和三次資料拷貝,如果請求的資料命中 page cache 則發生兩次資料拷貝省去了一次磁盤的 DMA 拷貝,
3.2 Direct IO
在上一小節中,筆者介紹了 Buffered IO 的諸多好處,尤其是在行程對檔案進行順序讀取的時候,訪問性能接近于記憶體,
但是有些情況,我們并不需要 page cache,比如一些高性能的資料庫應用程式,它們在用戶空間自己實作了一套高效的高速快取機制,以充分挖掘對資料庫獨特的查詢訪問性能,所以這些資料庫應用程式并不希望內核中的 page cache起作用,否則內核會同時處理 page cache 以及預讀相關操作的指令,會使得性能降低,
另外還有一種情況是,當我們在隨機讀取檔案的時候,也不希望內核使用 page cache,因為這樣違反了程式區域性原理,當我們隨機讀取檔案的時候,內核預讀進 page cache 中的資料將很久不會再次得到訪問,白白浪費 page cache 空間不說,還額外增加了預讀的磁盤 IO,
基于以上兩點原因,我們很自然的希望內核能夠提供一種機制可以繞過 page cache 直接對磁盤進行讀寫操作,這種機制就是本小節要為大家介紹的 Direct IO,
下面是內核采用 Direct IO 讀取檔案的作業流程:
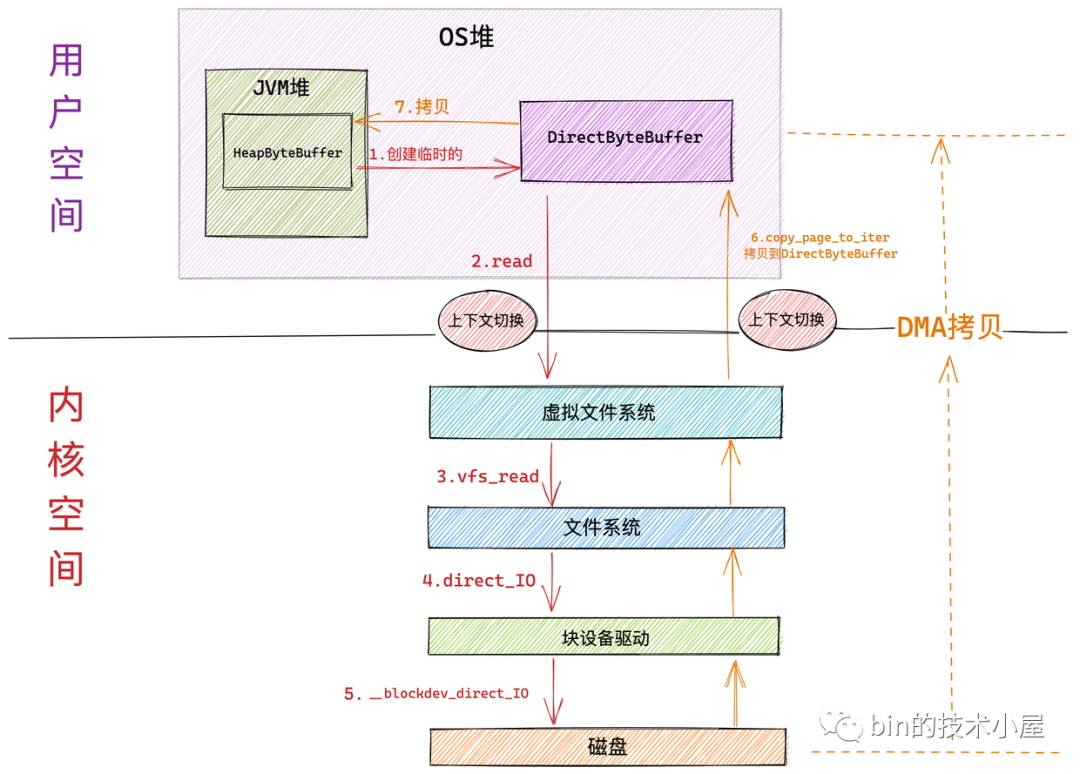
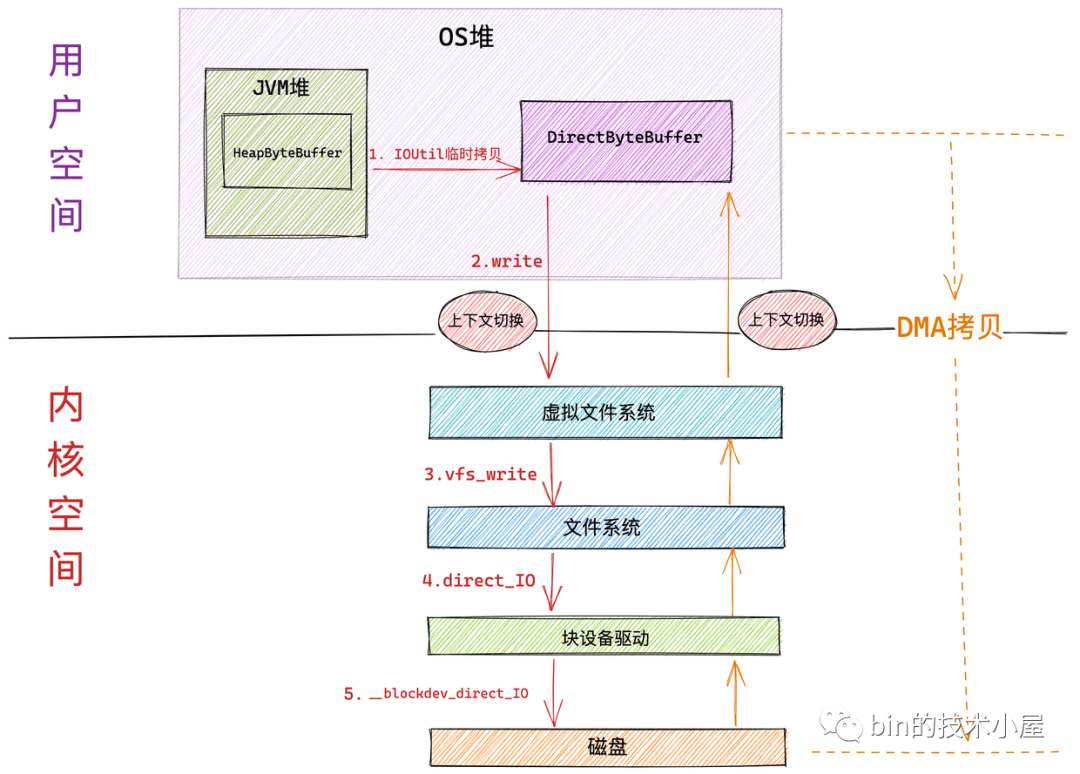
Direct IO 和 Buffered IO 在進入內核虛擬檔案系統層之前的流程全部都是一樣的,區別就是進入到虛擬檔案系統層之后,Direct IO 會繞過 page cache 直接來到檔案系統層通過 direct_io 呼叫來到塊驅動設備層,在塊設備驅動層呼叫 __blockdev_direct_IO 對磁盤內容直接進行讀寫,
-
和 Buffered IO 一樣,在系統呼叫 read 進入內核以及 Direct IO 完成從內核回傳的時候各自會發生一次上下文切換,共兩次背景關系切換
-
磁盤控制器 DMA 從磁盤中讀取資料后直接拷貝到用戶空間緩沖區 DirectByteBuffer 中,只發生一次 DMA 拷貝
-
隨后 NIO 將 DirectByteBuffer 中臨時存放的資料拷貝到 JVM 堆 HeapByteBuffer 中,發生第二次資料拷貝,
-
注意塊設備驅動層的 __blockdev_direct_IO 需要等到所有的 Direct IO 傳送資料完成之后才會回傳,這里的傳送指的是直接從磁盤拷貝到用戶空間緩沖區中,當 Direct IO 模式下的 read() 或者 write() 系統呼叫回傳之后,行程就可以安全放心地去讀取用戶緩沖區中的資料了,
從整個 Direct IO 的程序中我們看到,一共發生了兩次背景關系的切換,兩次的資料拷貝,
4. Talk is cheap ! show you the code
下面是系統呼叫 read 在內核中的完整定義:
SYSCALL_DEFINE3(read, unsigned int, fd, char __user *, buf, size_t, count) {
// 根據檔案描述符獲取檔案對應的 struct file結構
struct fd f = fdget_pos(fd);
.....
// 獲取當前檔案的讀取位置 offset
loff_t pos = file_pos_read(f.file);
// 進入虛擬檔案系統層,執行具體的檔案操作
ret = vfs_read(f.file, buf, count, &pos);
......
}
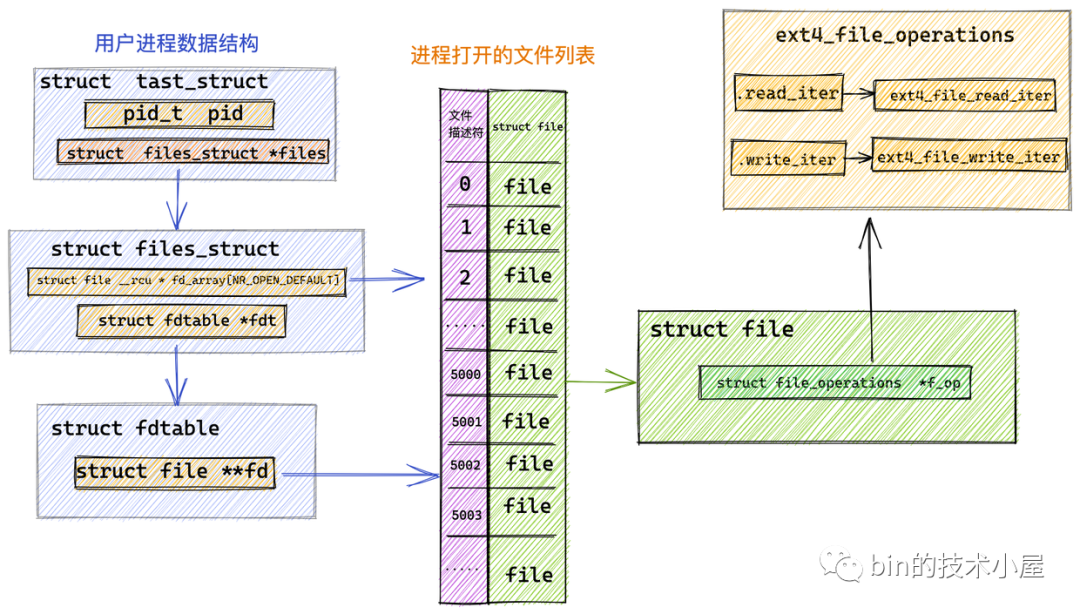
首先會根據檔案描述符 fd 通過 fdget_pos 方法獲取 struct fd 結構,進而可以獲取到檔案的 struct file 結構,
struct fd {
struct file *file;
int need_put;
};
file_pos_read 獲取當前檔案的讀取位置 offset,并通過 vfs_read 進入虛擬檔案系統層,
ssize_t __vfs_read (struct file *file, char __user *buf, size_t count, loff_t *pos) {
if (file->f_op->read)
return file->f_op->read(file, buf, count, pos);
else if (file->f_op->read_iter)
return new_sync_read(file, buf, count, pos);
else
return -EINVAL;
}
這里我們看到內核對檔案的操作全部定義在 struct file 結構中的 f_op 欄位中,
struct file {
const struct file_operations *f_op;
}
對于 Java 程式員來說,file_operations 大家可以把它當做內核針對檔案相關操作定義的一個公共介面(其實就是一個函式指標),它只是一個介面,具體的實作根據不同的檔案型別有所不同,
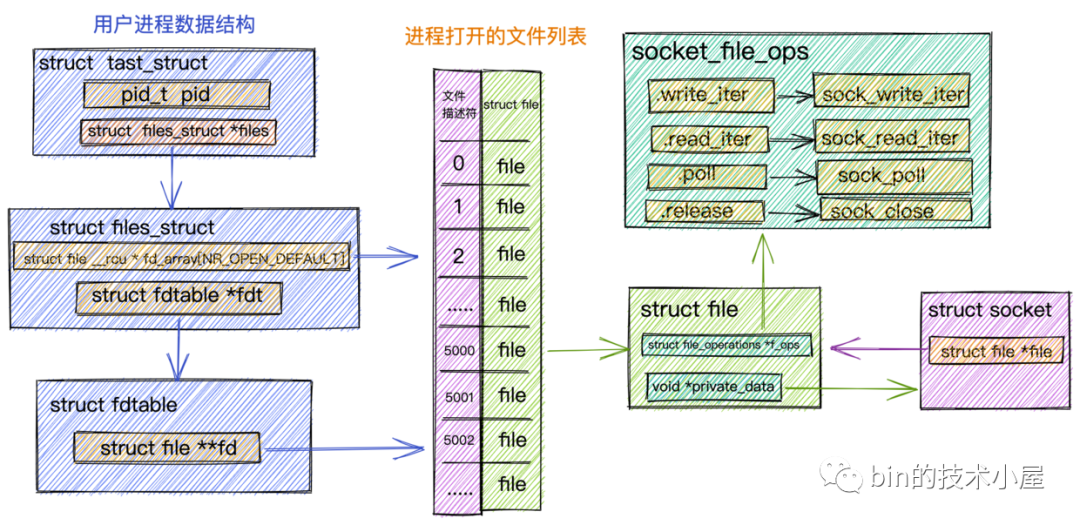
比如我們在《聊聊Netty那些事兒之從內核角度看IO模型》一文中詳細介紹過的 Socket 檔案,針對 Socket 檔案型別,這里的 file_operations 指向的是 socket_file_ops,
static const struct file_operations socket_file_ops = {
.owner = THIS_MODULE,
.llseek = no_llseek,
.read_iter = sock_read_iter,
.write_iter = sock_write_iter,
.poll = sock_poll,
.unlocked_ioctl = sock_ioctl,
.mmap = sock_mmap,
.release = sock_close,
.fasync = sock_fasync,
.sendpage = sock_sendpage,
.splice_write = generic_splice_sendpage,
.splice_read = sock_splice_read,
};
而本小節中我們討論的是對普通檔案的操作,針對普通檔案的操作定義在具體的檔案系統中,這里我們以 Linux 中最為常見的 ext4 檔案系統為例說明:
在 ext4 檔案系統中管理的檔案對應的 file_operations 指向 ext4_file_operations,專門用于操作 ext4 檔案系統中的檔案,
const struct file_operations ext4_file_operations = {
......省略........
.read_iter = ext4_file_read_iter,
.write_iter = ext4_file_write_iter,
......省略.........
}
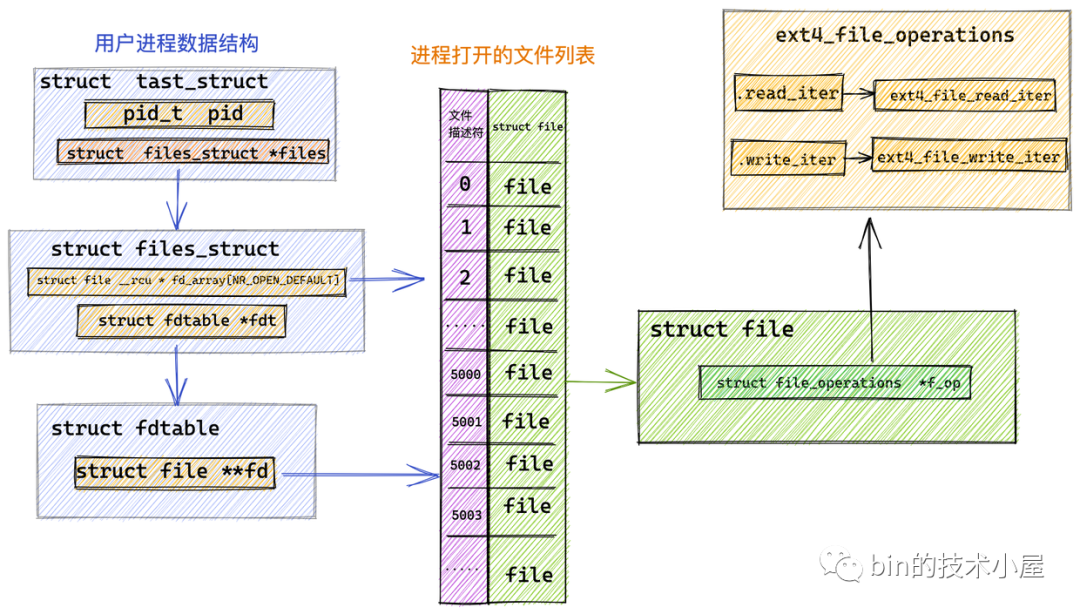
從圖中我們可以看到 ext4 檔案系統定義的相關檔案操作 ext4_file_operations 并未定義 .read 函式指標,而是定義了 .read_iter 函式指標,指向 ext4_file_read_iter 函式,
ssize_t __vfs_read (struct file *file, char __user *buf, size_t count, loff_t *pos) {
if (file->f_op->read)
return file->f_op->read(file, buf, count, pos);
else if (file->f_op->read_iter)
return new_sync_read(file, buf, count, pos);
else
return -EINVAL;
}
所以在虛擬檔案系統 VFS 中,__vfs_read 呼叫的是 new_sync_read 方法,在該方法中會對系統呼叫傳進來的引數進行重新封裝,比如:
-
struct file *filp : 要讀取檔案的 struct file 結構,
-
char __user *buf :用戶空間的 Buffer,這里指的我們例子中 NIO 創建的臨時 DirectByteBuffer,
-
size_t count :進行讀取的位元組數,也就是我們傳入的用戶態緩沖區 DirectByteBuffer 剩余可容納的容量大小,
-
loff_t *pos :檔案當前讀取位置偏移 offset,
將這些引數重新封裝到 struct iovec 和 struct kiocb 結構體中,
ssize_t new_sync_read(struct file *filp, char __user *buf, size_t len, loff_t *ppos)
{
// 將 DirectByteBuffer 以及要讀取的位元組數封裝進 iovec 結構體中
struct iovec iov = { .iov_base = buf, .iov_len = len };
struct kiocb kiocb;
struct iov_iter iter;
ssize_t ret;
// 利用檔案 struct file 初始化 kiocb 結構體
init_sync_kiocb(&kiocb, filp);
// 設定檔案讀取偏移
kiocb.ki_pos = *ppos;
// 讀取檔案位元組數
kiocb.ki_nbytes = len;
// 初始化 iov_iter 結構
iov_iter_init(&iter, READ, &iov, 1, len);
// 最終呼叫 ext4_file_read_iter
ret = filp->f_op->read_iter(&kiocb, &iter);
.......省略......
return ret;
}
struct iovec 結構體主要用來封裝用來接收檔案資料用的用戶快取區相關的資訊:
struct iovec
{
void __user *iov_base; // 用戶空間快取區地址 這里是 DirectByteBuffer 的地址
__kernel_size_t iov_len; // 緩沖區長度
}
但是內核中一般會使用 struct iov_iter 結構體對 struct iovec 進行包裝,iov_iter 中可以包含多個 iovec,這一點從 struct iov_iter 結構體的命名關鍵字 iter 上可以看得出來,
struct iov_iter {
......省略.....
const struct iovec *iov;
}
之所以使用 struct iov_iter 結構體來包裝 struct iovec 是為了兼容 readv() 系統呼叫,它允許用戶使用多個用戶快取區去讀取檔案中的資料,JDK NIO Channel 支持的 scatter 操作底層原理就是 readv 系統呼叫,
FileChannel fileChannel = new RandomAccessFile(new File("file-read-write.txt"), "rw").getChannel();
ByteBuffer heapByteBuffer1 = ByteBuffer.allocate(4096);
ByteBuffer heapByteBuffer2 = ByteBuffer.allocate(4096);
ByteBuffer[] scatter = { heapByteBuffer1, heapByteBuffer2 };
fileChannel.read(scatter);
struct kiocb 結構體則是用來封裝檔案 IO 相關操作的狀態和進度資訊:
struct kiocb {
struct file *ki_filp; // 要讀取的檔案 struct file 結構
loff_t ki_pos; // 檔案讀取位置偏移,表示檔案處理進度
void (*ki_complete)(struct kiocb *iocb, long ret); // IO完成回呼
int ki_flags; // IO型別,比如是 Direct IO 還是 Buffered IO
........省略.......
};
當 struct iovec 和 struct kiocb 在 new_sync_read 方法中被初始化好之后,最終通過 file_operations 中定義的函式指標 .read_iter 呼叫到 ext4_file_read_iter 方法中,從而進入 ext4 檔案系統執行具體的讀取操作,
static ssize_t ext4_file_read_iter(struct kiocb *iocb, struct iov_iter *to)
{
........省略........
return generic_file_read_iter(iocb, to);
}
ssize_t generic_file_read_iter(struct kiocb *iocb, struct iov_iter *iter)
{
........省略........
if (iocb->ki_flags & IOCB_DIRECT) {
........ Direct IO ........
// 獲取 page cache
struct address_space *mapping = file->f_mapping;
........省略........
// 繞過 page cache 直接從磁盤中讀取資料
retval = mapping->a_ops->direct_IO(iocb, iter);
}
........ Buffered IO ........
// 從 page cache 中讀取資料
retval = generic_file_buffered_read(iocb, iter, retval);
}
generic_file_read_iter 會根據 struct kiocb 中的 ki_flags 屬性判斷檔案 IO 操作是 Direct IO 還是 Buffered IO,
4.1 Direct IO
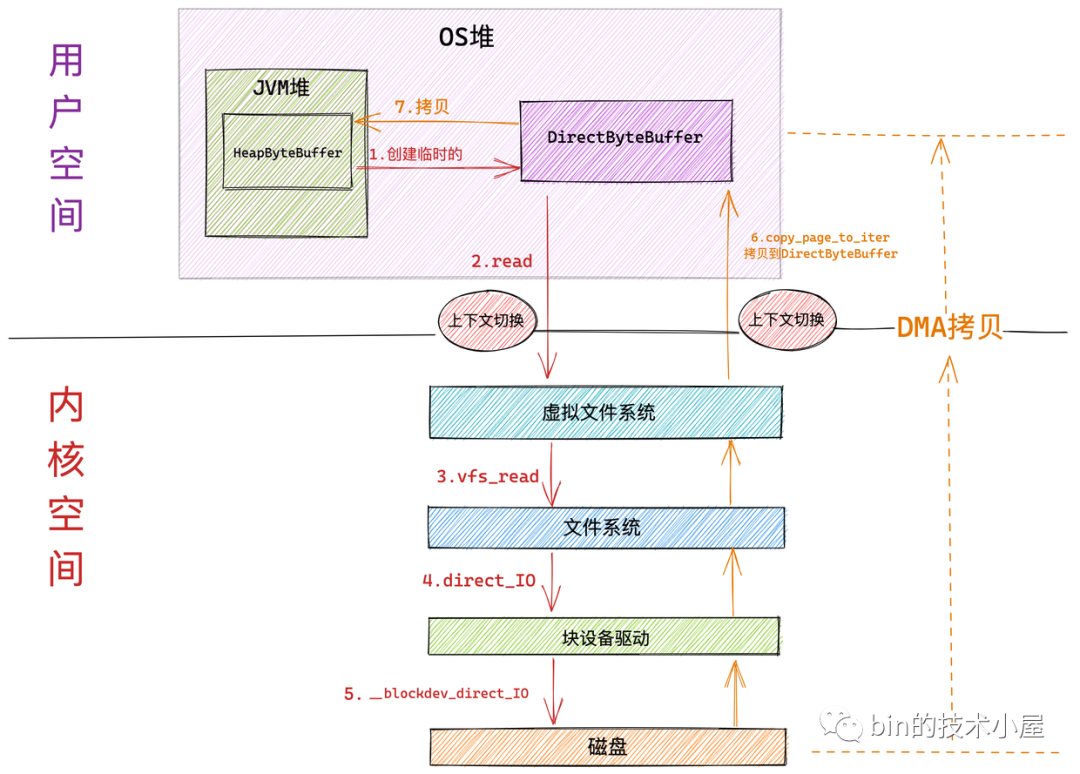
我們可以通過 open 系統呼叫在打開檔案的時候指定相關 IO 操作的模式是 Direct IO 還是 Buffered IO:
int open(const char *pathname, int flags, mode_t mode);
-
char *pathname : 指定要檔案的路徑,
-
int flags :指定檔案的訪問模式,比如:O_RDONLY(只讀),O_WRONLY,(只寫), O_RDWR(讀寫),O_DIRECT(Direct IO),默認為 Buffered IO,
-
mode_t mode :可選,指定打開檔案的權限
而 Java 在 JDK 10 之前一直是不支持 Direct IO,到了 JDK 10 才開始支持 Direct IO,
Path path = Paths.get("file-read-write.txt");
FileChannel fc = FileChannel.open(p, ExtendedOpenOption.DIRECT);
如果在檔案打開的時候,我們設定了 Direct IO 模式,那么以后在對檔案進行讀取的程序中,內核將會繞過 page cache,直接從磁盤中讀取資料到用戶空間緩沖區 DirectByteBuffer 中,這樣就可以避免一次資料從內核 page cache 到用戶空間緩沖區的拷貝,
當應用程式期望使用自定義的快取演算法從而可以在用戶空間實作更加高效更加可控的快取邏輯時(比如資料庫等應用程式),這時應該使用直接 Direct IO,在隨機讀取,隨機寫入的場景中也是比較適合用 Direct IO,
作業系統行程在接下來使用 read() 或者 write() 系統呼叫去讀寫檔案的時候使用的是 Direct IO 方式,所傳輸的資料均不經過檔案對應的高速快取 page cache (這里就是網上常說的內核緩沖區),
我們都知道作業系統是將記憶體分為一頁一頁的單位進行組織管理的,每頁大小 4K ,那么同樣檔案中的資料在磁盤中的組織形式也是按照一塊一塊的單位來組織管理的,每塊大小也是 4K ,所以我們在使用 Direct IO 讀寫資料時必須要按照檔案在磁盤中的組織單位進行磁盤塊大小對齊,緩沖區的大小也必須是磁盤塊大小的整數倍,具體表現在如下幾點:
-
檔案的讀寫位置偏移需要按照磁盤塊大小對齊,
-
用戶緩沖區 DirectByteBuffer 起始地址需要按照磁盤塊大小對齊,
-
使用 Direct IO 進行資料讀寫時,讀寫的資料大小需要按照磁盤塊大小進行對齊,這里指 DirectByteBuffer 中剩余資料的大小,
當我們采用 Direct IO 直接讀取磁盤中的檔案資料時,內核會從 struct file 結構中獲取到該檔案在記憶體中的 page cache,而我們多次提到的這個 page cache 在內核中的資料結構就是 struct address_space ,我們可以根據 file->f_mapping 獲取,
struct file {
// page cache
struct address_space *f_mapping;
}
和前面我們介紹的 struct file 結構中的 file_operations 一樣,內核中將 page cache 相關的操作全部定義在 struct address_space_operations 結構中,這里和前邊介紹的 file_operations 的作用是一樣的,只是內核針對 page cache 操作定義的一個公共介面,
struct address_space {
const struct address_space_operations *a_ops;
}
具體的實作會根據檔案系統的不同而不同,這里我們還是以 ext4 檔案系統為例:
static const struct address_space_operations ext4_aops = {
.direct_IO = ext4_direct_IO,
};
內核通過 struct address_space_operations 結構中定義的 .direct_IO 函式指標,具體函式為 ext4_direct_IO 來繞過 page cache 直接對磁盤進行讀寫,
采用 Direct IO 的方式對檔案的讀寫操作全部是在 ext4_direct_IO 這一個函式中完成的,
由于磁盤檔案中的資料是按照塊為單位來組織管理的,所以檔案系統其實就是一個塊設備,通過 ext4_direct_IO 繞過 page cache 直接來到了檔案系統的塊設備驅動層,最終在塊設備驅動層呼叫 __blockdev_direct_IO 來完成磁盤的讀寫操作,
注意:塊設備驅動層的 __blockdev_direct_IO 需要等到所有的 Direct IO 傳送資料完成之后才會回傳,這里的傳送指的是直接從磁盤拷貝到用戶空間緩沖區中,當 Direct IO 模式下的 read() 或者 write() 系統呼叫回傳之后,行程就可以安全放心地去讀取用戶緩沖區中的資料了,
4.2 Buffered IO
Buffered IO 相關的讀取操作封裝在 generic_file_buffered_read 函式中,其核心邏輯如下:
-
由于檔案在磁盤中是以塊為單位組織管理的,每塊大小為 4k,記憶體是按照頁為單位組織管理的,每頁大小也是 4k,檔案中的塊資料被快取在 page cache 中的快取頁中,所以首先通過 find_get_page 方法查找我們要讀取的檔案資料是否已經快取在了 page cache 中,
-
如果 page cache 中不存在檔案資料的快取頁,就需要通過 page_cache_sync_readahead 方法從磁盤中讀取資料并快取到 page cache 中,于此同時還需要同步預讀若干相鄰的資料塊到 page cache 中,這樣在下一次順序讀取的時候,直接就可以從 page cache 中讀取了,
-
如果此次讀取的檔案資料已經存在于 page cache 中了,就需要呼叫 PageReadahead 來判斷是否需要進一步預讀資料到快取頁中,如果是,則從磁盤中異步預讀若干頁到 page cache 中,具體預讀多少頁是根據內核相關預讀演算法來動態調整的,
-
經過上面幾個流程,此時檔案資料已經存在于 page cache 中的快取頁中了,最后內核呼叫 copy_page_to_iter 方法將 page cache 中的資料拷貝到用戶空間緩沖區 DirectByteBuffer 中,
static ssize_t generic_file_buffered_read(struct kiocb *iocb,
struct iov_iter *iter, ssize_t written)
{
// 獲取檔案在內核中對應的 struct file 結構
struct file *filp = iocb->ki_filp;
// 獲取檔案對應的 page cache
struct address_space *mapping = filp->f_mapping;
// 獲取檔案的 inode
struct inode *inode = mapping->host;
...........省略...........
// 開始 Buffered IO 讀取邏輯
for (;;) {
// 用于從 page cache 中獲取快取的檔案資料 page
struct page *page;
// 根據檔案讀取偏移計算出 第一個位元組所在物理頁的索引
pgoff_t index;
// 根據檔案讀取偏移計算出 第一個位元組所在物理頁中的頁內偏移
unsigned long offset;
// 在 page cache 中查找是否有讀取資料在記憶體中的快取頁
page = find_get_page(mapping, index);
if (!page) {
if (iocb->ki_flags & IOCB_NOWAIT) {
....... 如果設定的是異步IO,則直接回傳 -EAGAIN ......
}
// 要讀取的檔案資料在 page cache 中沒有對應的快取頁
// 則從磁盤中讀取檔案資料,并同步預讀若干相鄰的資料塊到 page cache中
page_cache_sync_readahead(mapping,
ra, filp,
index, last_index - index);
// 再一次觸發快取頁的查找,這一次就可以找到了
page = find_get_page(mapping, index);
if (unlikely(page == NULL))
goto no_cached_page;
}
//如果讀取的檔案資料已經在 page cache 中了,則判斷是否進行近一步的預讀操作
if (PageReadahead(page)) {
//異步預讀若干檔案資料塊到 page cache 中
page_cache_async_readahead(mapping,
ra, filp, page,
index, last_index - index);
}
..............省略..............
//將 page cache 中的資料拷貝到用戶空間緩沖區 DirectByteBuffer 中
ret = copy_page_to_iter(page, offset, nr, iter);
}
}

到這里關于檔案讀取的兩種模式 Buffered IO 和 Direct IO 在內核中的主干邏輯流程筆者就為大家介紹完了,
但是大家可能會對 Buffered IO 中的兩個細節比較感興趣:
-
如何在 page cache 中查找我們要讀取的檔案資料 ?也就是說上面提到的 find_get_page 函式是如何實作的?
-
檔案預讀的程序是怎么樣的?內核中的預讀演算法又是什么樣的呢?
在為大家解答這兩個疑問之前,筆者先為大家介紹一下內核中的頁高速快取 page cache,
5. 頁高速快取 page cache
筆者在《一文聊透物件在 JVM 中的記憶體布局,以及記憶體對齊和壓縮指標的原理及應用》 文章中為大家介紹 CPU 的高速快取時曾提到過,根據摩爾定律:芯片中的晶體管數量每隔 18 個月就會翻一番,導致 CPU 的性能和處理速度變得越來越快,而提升 CPU 的運行速度比提升記憶體的運行速度要容易和便宜的多,所以就導致了 CPU 與記憶體之間的速度差距越來越大,
CPU 與記憶體之間的速度差異到底有多大呢? 我們知道暫存器是離 CPU 最近的,CPU 在訪問暫存器的時候速度近乎于 0 個時鐘周期,訪問速度最快,基本沒有時延,而訪問記憶體則需要 50 - 200 個時鐘周期,
所以為了彌補 CPU 與記憶體之間巨大的速度差異,提高 CPU 的處理效率和吞吐,于是我們引入了 L1 , L2 , L3 高速快取集成到 CPU 中,CPU 訪問高速快取僅需要用到 1 - 30 個時鐘周期,CPU 中的高速快取是對記憶體熱點資料的一個快取,
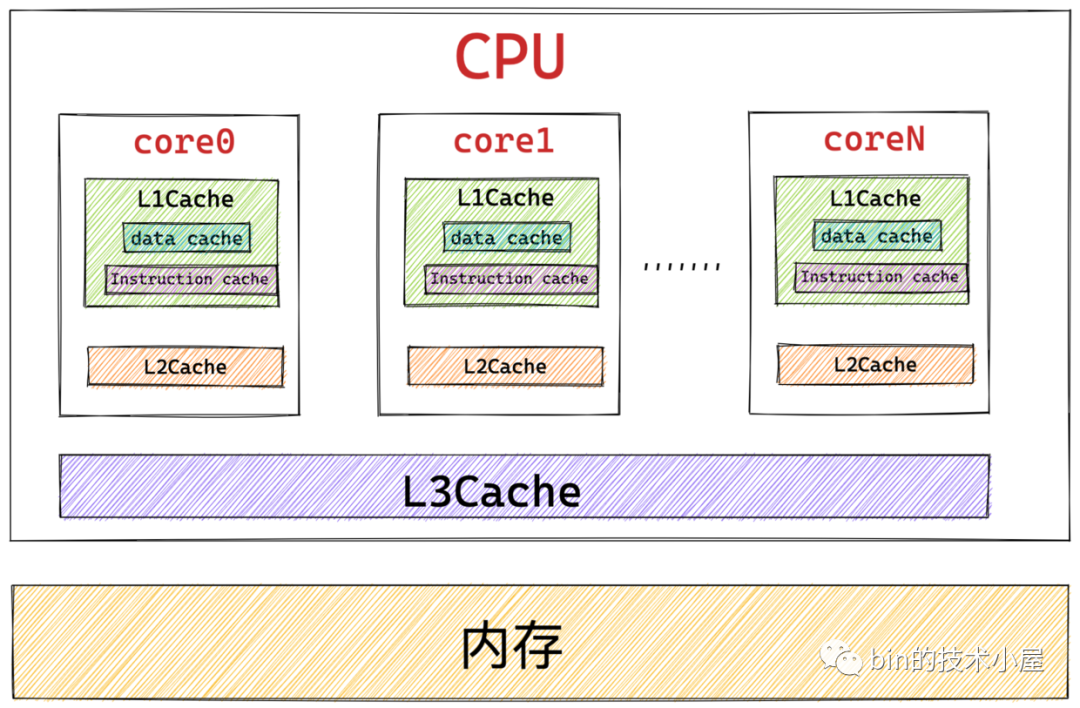
而本文我們討論的主題是記憶體與磁盤之間的關系,CPU 訪問磁盤的速度就更慢了,需要用到大概約幾千萬個時鐘周期.
我們可以看到 CPU 訪問高速快取的速度比訪問記憶體的速度快大約10倍,而訪問記憶體的速度要比訪問磁盤的速度快大約 100000 倍,
引入 CPU 高速快取的目的在于消除 CPU 與記憶體之間的速度差距,CPU 用高速快取來存放記憶體中的熱點資料,那么同樣的道理,本小節中我們引入的頁高速快取 page cache 的目的是為了消除記憶體與磁盤之間的巨大速度差距,page cache 中快取的是磁盤檔案的熱點資料,
另外我們根據程式的時間區域性原理可以知道,磁盤檔案中的資料一旦被訪問,那么它很有可能在短期被再次訪問,如果我們訪問的磁盤檔案資料快取在 page cache 中,那么當行程再次訪問的時候資料就會在 page cache 中命中,這樣我們就可以把對磁盤的訪問變為對物理記憶體的訪問,極大提升了對磁盤的訪問性能,
程式區域性原理表現為:時間區域性和空間區域性,時間區域性是指如果程式中的某條指令一旦執行,則不久之后該指令可能再次被執行;如果某塊資料被訪問,則不久之后該資料可能再次被訪問,空間區域性是指一旦程式訪問了某個存盤單元,則不久之后,其附近的存盤單元也將被訪問,
在前邊的內容中我們多次提到作業系統是將物理記憶體分為一個一個的頁面來組織管理的,每頁大小為 4k ,而磁盤中的檔案資料在磁盤中是分為一個一個的塊來組織管理的,每塊大小也為 4k,
page cache 中快取的就是這些記憶體頁面,頁面中的資料對應于磁盤上物理塊中的資料,page cache 中快取的大小是可以動態調整的,它可以通過占用空閑記憶體來擴大快取頁面的容量,當記憶體不足時也可以通過回收頁面來緩解記憶體使用的壓力,
正如我們上小節介紹的 read 系統呼叫在內核中的實作邏輯那樣,當用戶行程發起 read 系統呼叫之后,內核首先會在 page cache 中檢查請求資料所在頁面是否已經快取在 page cache 中,
-
如果快取命中,內核直接會把 page cache 中快取的磁盤檔案資料拷貝到用戶空間緩沖區 DirectByteBuffer 中,從而避免了龜速的磁盤 IO,
-
如果快取沒有命中,內核會分配一個物理頁面,將這個新分配的頁面插入 page cache 中,然后調度磁盤塊 IO 驅動從磁盤中讀取資料,最后用從磁盤中讀取的資料填充這個物里頁面,
根據前面介紹的程式時間區域性原理,當行程在不久之后再來讀取資料的時候,請求的資料已經在 page cache 中了,極大地提升了檔案 IO 的性能,
page cache 中快取的不僅有基于檔案的快取頁,還會快取記憶體映射檔案,以及磁盤塊設備檔案,這里大家只需要有這個概念就行,本文我們主要聚焦于基于檔案的快取頁,在筆者后面的文章中,我們還會再次介紹到這些剩余型別的快取頁,
在我們了解了 page cache 引入的目的以及 page cache 在磁盤 IO 中所發揮的作用之后,大家一定會很好奇這個 page cache 在內核中到底是怎么實作的呢?
讓我們先從 page cache 在內核中的資料結構開始聊起~~~~
6. page cache 在內核中的資料結構
page cache 在內核中的資料結構是一個叫做 address_space 的結構體:struct address_space,
這個名字起的真是有點詞不達意,從命名上根本無法看出它是表示 page cache 的,所以大家在日常開發中一定要注意命名的精準規范,
每個檔案都會有自己的 page cache,struct address_space 結構在記憶體中只會保留一份,
什么意思呢?比如我們可以通過多個不同的行程打開一個相同的檔案,行程每打開一個檔案,內核就會為它創建 struct file 結構,這樣在內核中就會有多個 struct file 結構來表示同一個檔案,但是同一個檔案的 page cache 也就是 struct address_space 在內核中只會有一個,
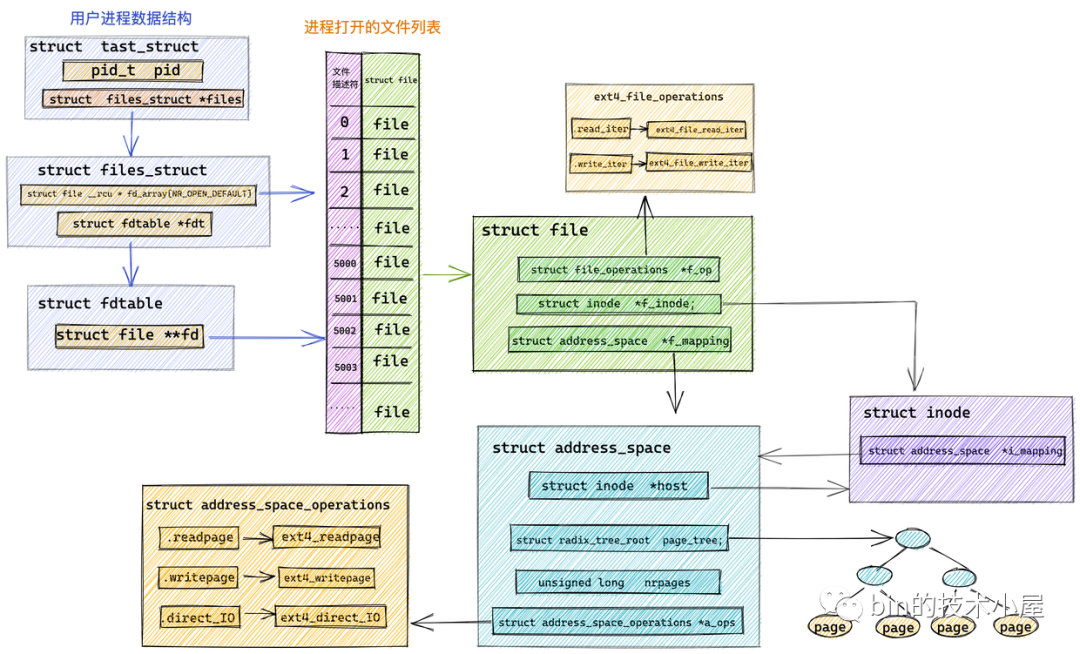
struct address_space {
struct inode *host; // 關聯 page cache 對應檔案的 inode
struct radix_tree_root page_tree; // 這里就是 page cache,里邊快取了檔案的所有快取頁面
spinlock_t tree_lock; // 訪問 page_tree 時用到的自旋鎖
unsigned long nrpages; // page cache 中快取的頁面總數
..........省略..........
const struct address_space_operations *a_ops; // 定義對 page cache 中快取頁的各種操作方法
..........省略..........
}
struct inode *host:一個檔案對應一個 page cache 結構 struct address_space ,檔案的 inode 描述了一個檔案的所有元資訊,在 struct address_space 中通過 host 指標與檔案的 inode 關聯,而在 inode 結構體 struct inode 中又通過 i_mapping 指標與檔案的 page cache 進行關聯,
struct inode {
struct address_space *i_mapping; // 關聯檔案的 page cache
}
-
struct radix_tree_root page_tree: page cache 中快取的所有檔案頁全部存盤在 radix_tree 這樣一個高效搜索樹結構當中,在檔案 IO 相關的操作中,內核需要頻繁大量地在 page cache 中搜索請求頁是否已經快取在頁高速快取中,所以針對 page cache 的搜索操作必須是高效的,否則引入 page cache 所帶來的性能提升將會被低效的搜索開銷所抵消掉, -
unsigned long nrpages:記錄了當前檔案對應的 page cache 快取頁面的總數, -
const struct address_space_operations *a_ops:a_ops 定義了 page cache 中所有針對快取頁的 IO 操作,提供了管理 page cache 的各種行為,比如:常用的頁面讀取操作 readPage() 以及頁面寫入操作 writePage() 等,保證了所有針對快取頁的 IO 操作必須是通過 page cache 進行的,
struct address_space_operations {
// 寫入更新頁面快取
int (*writepage)(struct page *page, struct writeback_control *wbc);
// 讀取頁面快取
int (*readpage)(struct file *, struct page *);
// 設定快取頁為臟頁,等待后續內核回寫磁盤
int (*set_page_dirty)(struct page *page);
// Direct IO 繞過 page cache 直接操作磁盤
ssize_t (*direct_IO)(struct kiocb *, struct iov_iter *iter);
........省略..........
}
前邊我們提到 page cache 中快取的不僅僅是基于檔案的頁,它還會快取記憶體映射頁,以及磁盤塊設備檔案,況且基于檔案的記憶體頁背后也有不同的檔案系統,所以內核只是通過 a_ops 定義了操作 page cache 快取頁 IO 的通用行為定義,而具體的實作需要各個具體的檔案系統通過自己定義的 address_space_operations 來描述自己如何與 page cache 進行互動,比如前邊我們介紹的 ext4 檔案系統就有自己的 address_space_operations 定義,
static const struct address_space_operations ext4_aops = {
.readpage = ext4_readpage,
.writepage = ext4_writepage,
.direct_IO = ext4_direct_IO,
........省略.....
};
在我們從整體上了解了 page cache 在內核中的資料結構 struct address_space 之后,我們接下來看一下 radix_tree 這個資料結構是如何支持內核來高效搜索檔案頁的,以及 page cache 中這些被快取的檔案頁是如何組織管理的,
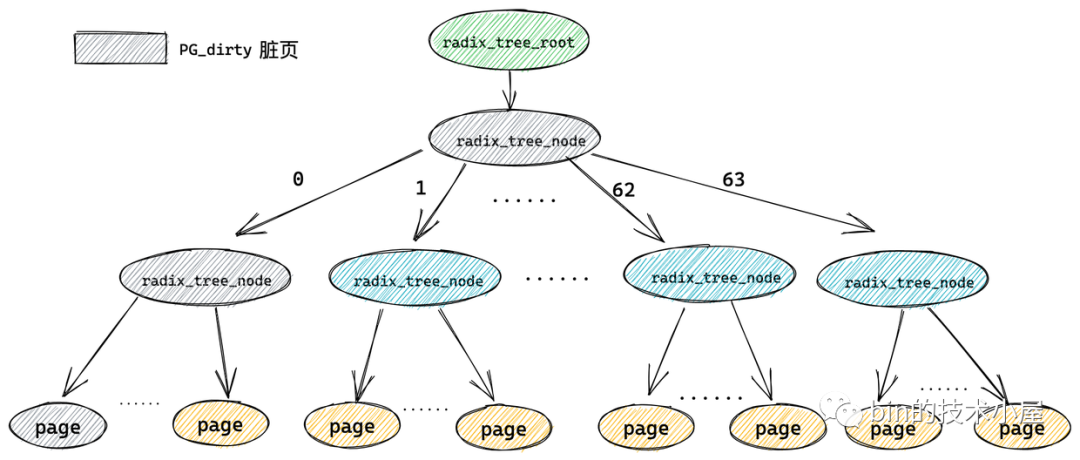
7. 基樹 radix_tree
正如前邊我們提到的,在檔案 IO 相關的操作中,內核會頻繁大量地在 page cache 中查找請求頁是否在頁高速快取中,還有就是當我們訪問大檔案時(linux 能支持大到幾個 TB 的檔案),page cache 中將會充斥著大量的檔案頁,
基于上面提到的兩個原因:一個是內核對 page cache 的頻繁搜索操作,另一個是 page cache 中會快取大量的檔案頁,所以內核需要采用一個高效的搜索資料結構來組織管理 page cache 中的快取頁,
本小節我們就來介紹下,page cache 中用來存盤快取頁的資料結構 radix_tree,
在 linux 內核 5.0 版本中 radix_tree 已被替換成 xarray 結構,感興趣的同學可以自行了解下,
在 page cache 結構 struct address_space 中有一個型別為 struct radix_tree_root 的欄位 page_tree,它表示的是 radix_tree 的根節點,
struct address_space {
struct radix_tree_root page_tree; // 這里就是 page cache,里邊快取了檔案的所有快取頁面
..........省略..........
}
struct radix_tree_root {
gfp_t gfp_mask;
struct radix_tree_node __rcu *rnode; // radix_tree 根節點
};
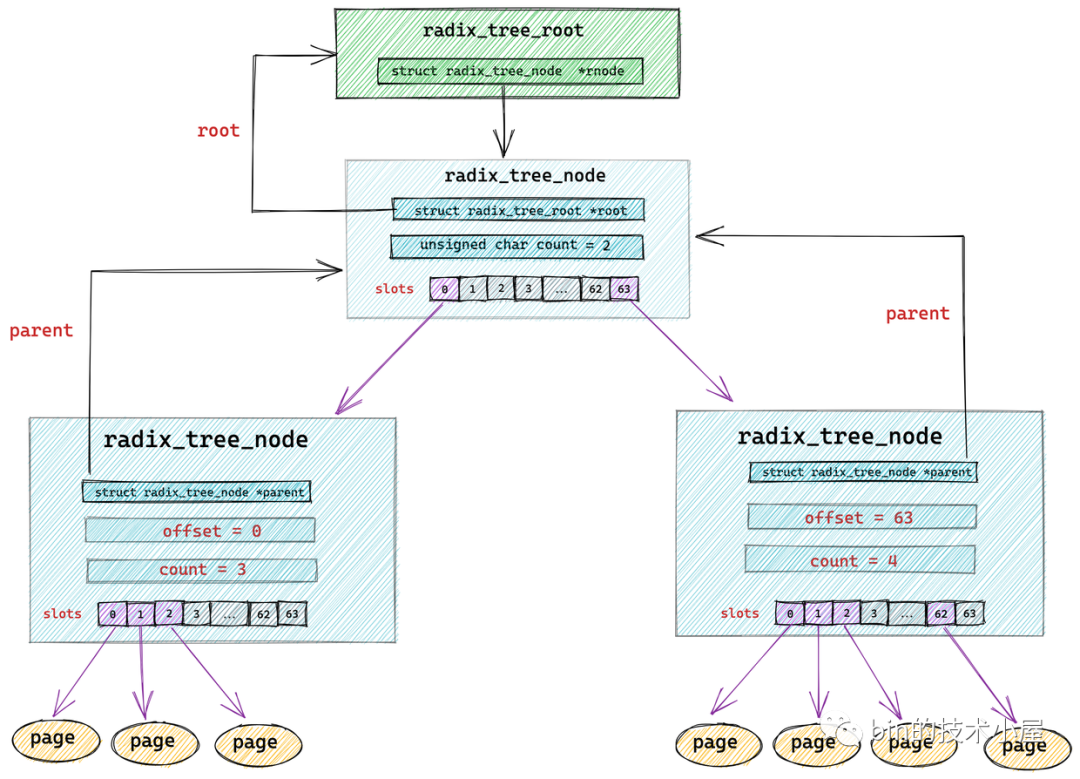
radix_tree 中的節點型別為 struct radix_tree_node,
struct radix_tree_node {
void __rcu *slots[RADIX_TREE_MAP_SIZE]; //包含 64 個指標的陣列,用于指向下一層節點或者快取頁
unsigned char offset; //父節點中指向該節點的指標在父節點 slots 陣列中的偏移
unsigned char count;//記錄當前節點的 slots 陣列指向了多少個節點
struct radix_tree_node *parent; // 父節點指標
struct radix_tree_root *root; // 根節點
..........省略.........
unsigned long tags[RADIX_TREE_MAX_TAGS][RADIX_TREE_TAG_LONGS]; // radix_tree 中的二維標記陣列,用于標記子節點的狀態,
};
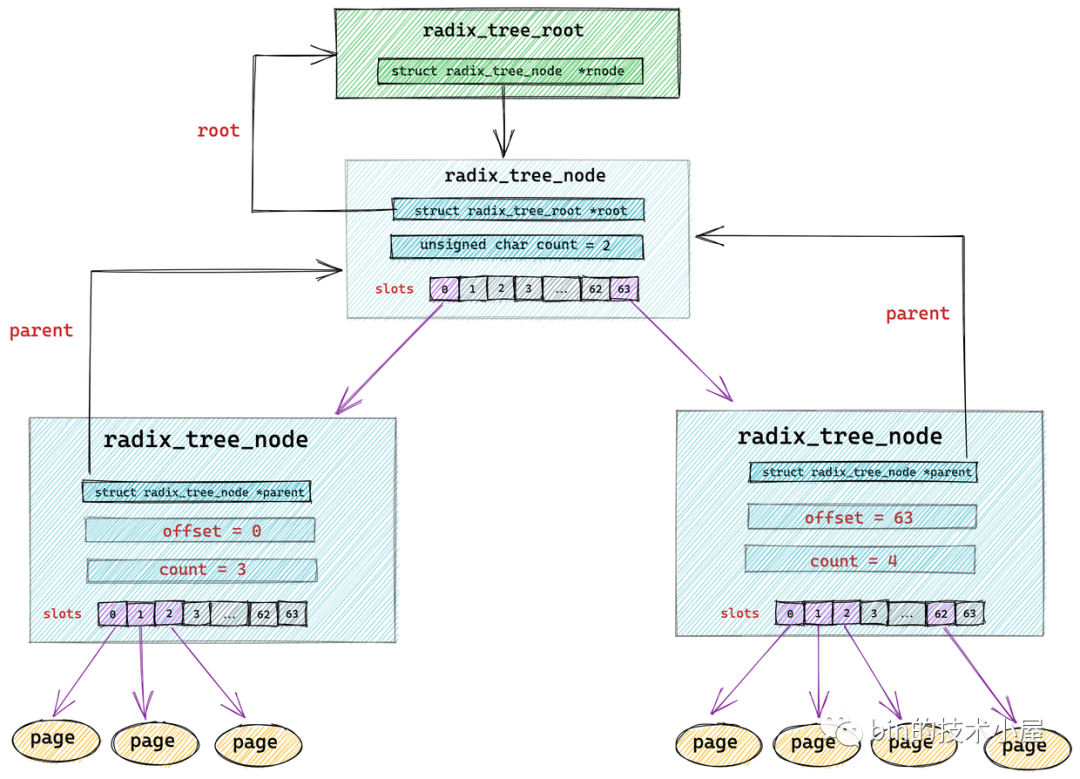
void __rcu *slots[RADIX_TREE_MAP_SIZE] :radix_tree 樹中的每個節點中包含一個 slots ,它是一個包含 64 個指標的陣列,每個指標指向它的下一層節點或者快取頁描述符 struct page,
radix_tree 將快取頁全部存放在它的葉子結點中,所以它的葉子結點型別為 struct page,其余的節點型別為 radix_tree_node,最底層的 radix_tree_node 節點中的 slots 指向快取頁描述符 struct page,
unsigned char offset 用于表示父節點的 slots 陣列中指向當前節點的指標,在父節點的slots陣列中的索引,
unsigned char count 用于記錄當前 radix_tree_node 的 slots 陣列中指向的節點個數,因為 slots 陣列中的指標有可能指向 null ,
這里大家可能已經注意到了在 struct radix_tree_node 結構中還有一個 long 型的 tags 二維陣列 tags[RADIX_TREE_MAX_TAGS][RADIX_TREE_TAG_LONGS],那么這個二維陣列到底是用來干嘛的呢?我們接著往下看~~
7.1 radix_tree 的標記
經過前面的介紹我們知道,頁高速快取 page cache 的引入是為了在記憶體中快取磁盤的熱點資料盡可能避免龜速的磁盤 IO,
而在進行檔案 IO 的時候,內核會頻繁大量的在 page cache 中搜索請求資料是否已經快取在 page cache 中,如果是,內核就直接將 page cache 中的資料拷貝到用戶緩沖區中,從而避免了一次磁盤 IO,
這就要求內核需要采用一種支持高效搜索的資料結構來組織管理這些快取頁,所以引入了基樹 radix_tree,
到目前為止,我們還沒有涉及到快取頁的狀態,不過在文章的后面我們很快就會涉及到,這里提前給大家引出來,讓大家腦海里先有個概念,
那么什么是快取頁的狀態呢?
我們知道在 Buffered IO 模式下,對于檔案 IO 的操作都是需要經過 page cache 的,后面我們即將要介紹的 write 系統呼叫就會將資料直接寫到 page cache 中,并將該快取頁標記為臟頁(PG_dirty)直接回傳,隨后內核會根據一定的規則來將這些臟頁回寫到磁盤中,在會寫的程序中這些臟頁又會被標記為 PG_writeback,表示該頁正在被回寫到磁盤,
PG_dirty 和 PG_writeback 就是快取頁的狀態,而內核不僅僅是需要在 page cache 中高效搜索請求資料所在的快取頁,還需要高效搜索給定狀態的快取頁,
比如:快速查找 page cache 中的所有臟頁,但是如果此時 page cache 中的大部分快取頁都不是臟頁,那么順序遍歷 radix_tree 的方式就實在是太慢了,所以為了快速搜索到臟頁,就需要在 radix_tree 中的每個節點 radix_tree_node
中加入一個針對其所有子節點的臟頁標記,如果其中一個子節點被標記被臟時,那么這個子節點對應的父節點 radix_tree_node 結構中的對應臟頁標記位就會被置 1 ,
而用來存盤臟頁標記的正是上小節中提到的 tags 二維陣列,其中第一維 tags[] 用來表示標記型別,有多少標記型別,陣列大小就為多少,比如 tags[0] 表示 PG_dirty 標記陣列,tags[1] 表示 PG_writeback 標記陣列,
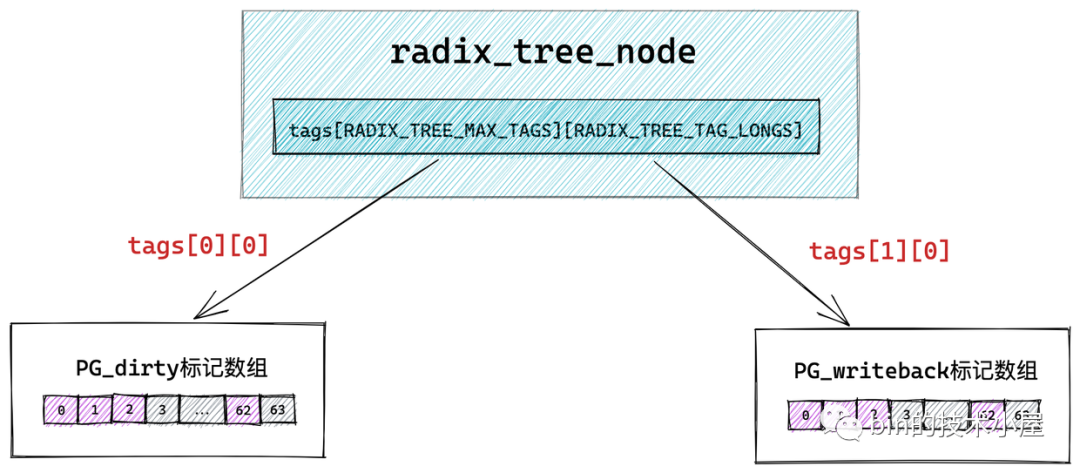
第二維 tags[][] 陣列則表示對應標記型別針對每一個子節點的標記位,因為一個 radix_tree_node 節點中包含 64 個指標指向對應的子節點,所以二維 tags[][] 陣列的大小也為 64 ,陣列中的每一位表示對應子節點的標記,tags[0][0] 指向 PG_dirty 標記陣列,tags[1][0] 指向PG_writeback 標記陣列,
而快取頁( radix_tree 中的葉子結點)這些標記是存放在其對應的頁描述符 struct page 里的 flag 中,
struct page {
unsigned long flags;
}
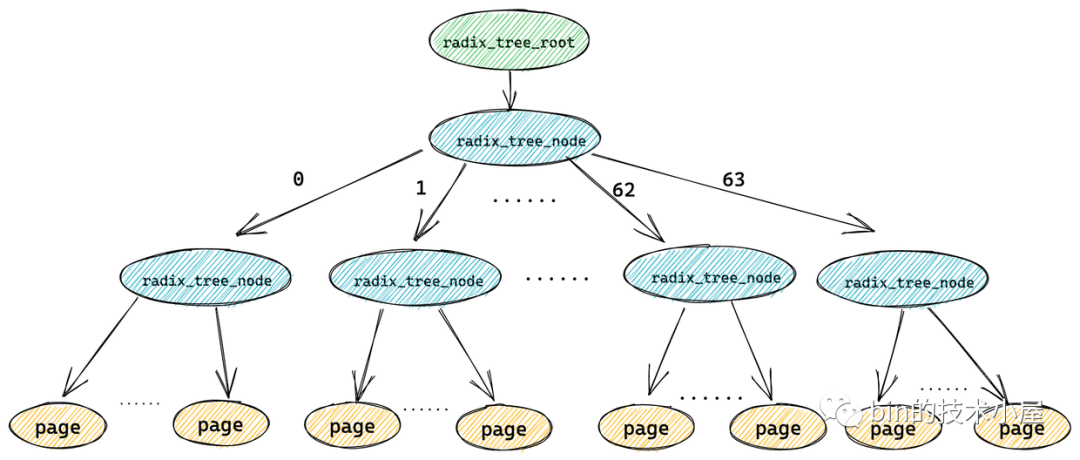
只要一個快取頁(葉子結點)被標記,那么從這個葉子結點一直到 radix_tree 根節點的路徑將會全部被標記,這就好比你在一盆清水中滴入一滴墨水,不久之后整盆水就會變為黑色,
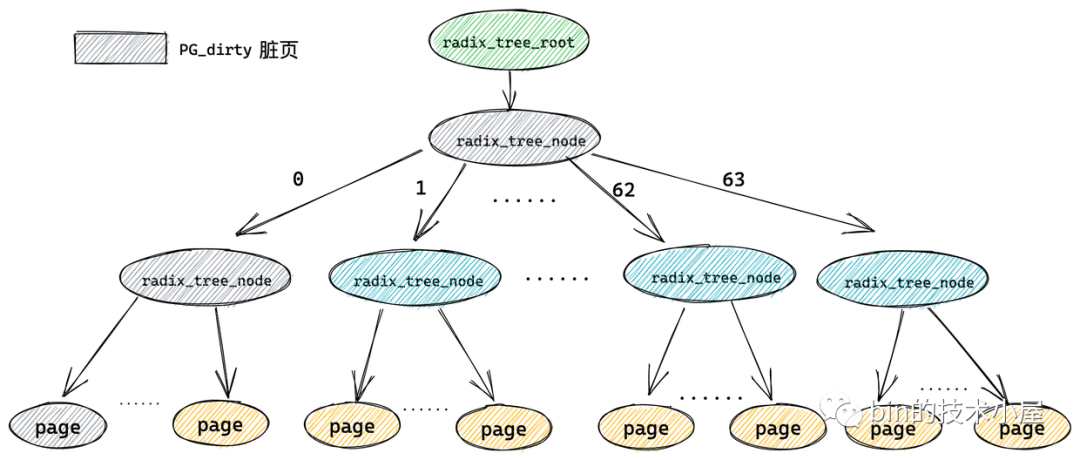
這樣內核在 radix_tree 中搜索被標記的臟頁(PG_dirty)或者正在回寫的頁(PG_writeback)時,就可以迅速跳過哪些標記為 0 的中間節點的所有子樹,中間節點對應的標記為 0 說明其所有的子樹中包含的快取頁(葉子結點)都是干凈的(未標記),從而達到在 radix_tree 中迅速搜索指定狀態的快取頁的目的,
8. page cache 中查找快取頁
在我們明白了 radix_tree 這個資料結構之后,接下來我們來看一下在《4.2 Buffered IO》小節中遺留的問題:內核如何通過 find_get_page 在 page cache 中高效查找快取頁?
在介紹 find_get_page 之前,筆者先來帶大家看看 radix_tree 具體是如何組織和管理其中的快取頁 page 的,
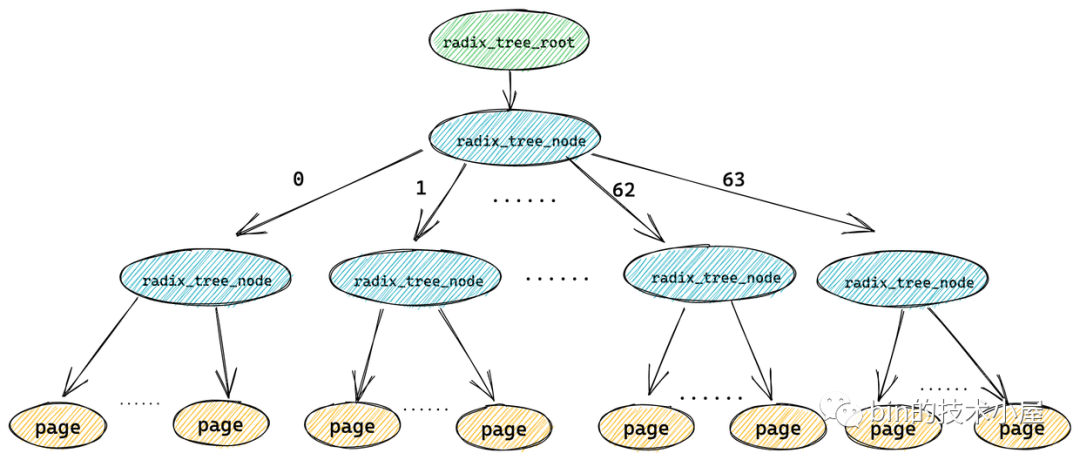
經過上小節相關內容的介紹,我們了解到在 radix_tree 中每個節點 radix_tree_node 包含一個大小為 64 的指標陣列 slots 用于指向它的子節點或者快取頁描述符(葉子節點),
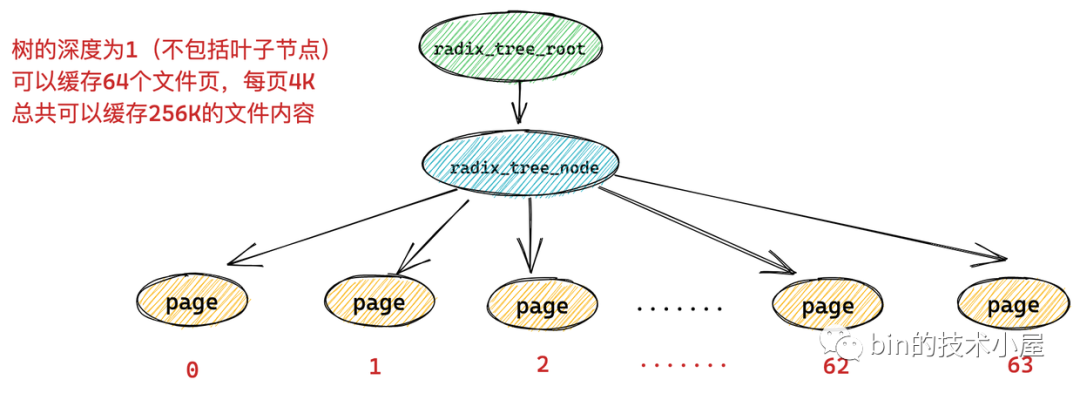
一個 radix_tree_node 節點下邊最多可容納 64 個子節點,如果 radix_tree 的深度為 1 (不包括葉子節點),那么這顆 radix_tree 就可以快取 64 個檔案頁,而每頁大小為 4k,所以一顆深度為 1 的 radix_tree 可以快取 256k 的檔案內容,
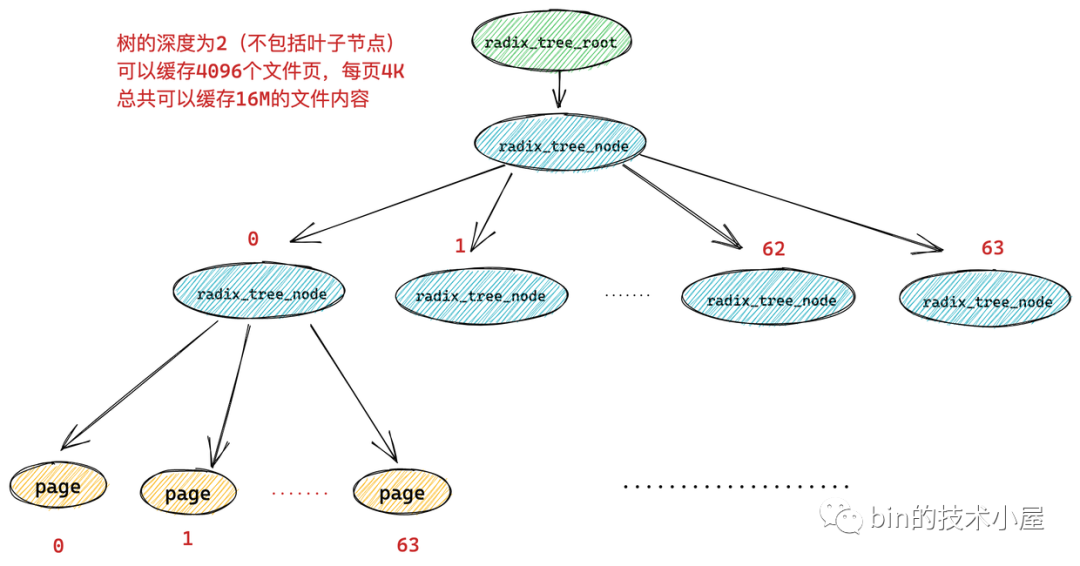
而如果一顆 radix_tree 的深度為 2,那么它就可以快取 64 * 64 = 4096 個檔案頁,總共可以快取 16M 的檔案內容,
依次類推我們可以得到不同的 radix_tree 深度可以快取多大的檔案內容:
| radix_tree 深度 | page 最大索引值 | 快取檔案大小 |
|---|---|---|
| 1 | 2^6 - 1 = 63 | 256K |
| 2 | 2^12 - 1 = 4095 | 16M |
| 3 | 2^18 - 1 = 262143 | 1G |
| 4 | 2^24 -1 =16777215 | 64G |
| 5 | 2^30 - 1 | 4T |
| 6 | 2^36 - 1 | 64T |
通過以上內容的介紹,我們看到在 radix_tree 是根據快取頁的 index (索引)來組織管理快取頁的,內核會根據這個 index 迅速找到對應的快取頁,在快取頁描述符 struct page 結構中保存了其在 page cache 中的索引 index,
struct page {
unsigned long flags; //快取頁標記
struct address_space *mapping; // 快取頁所在的 page cache
unsigned long index; // 頁索引
...
}
事實上 find_get_page 函式也是根據快取頁描述符中的這個 index 來在 page cache 中高效查找對應的快取頁,
static inline struct page *find_get_page(struct address_space *mapping,
pgoff_t offset)
{
return pagecache_get_page(mapping, offset, 0, 0);
}
-
struct address_space *mapping: 為讀取檔案對應的 page cache 頁高速快取, -
pgoff_t offset: 為所請求的快取頁在 page cache 中的索引 index,型別為 long 型,
那么在內核是如何利用這個 long 型的 offset 在 page cache 中高效搜索指定的快取頁呢?
經過前邊我們對 radix_tree 結構的介紹,我們已經知道 radix_tree 中每個節點 radix_tree_node 包含一個大小為 64 的指標陣列 slots 用于指向它的子節點或者快取頁描述符,
一個 radix_tree_node 節點下邊最多可容納 64 個子節點,如果 radix_tree 的深度為 1 (不包括葉子節點),那么這顆 radix_tree 就可以快取 64 個檔案頁,只能表示 0 - 63 的索引范圍,所以 long 型的快取頁 offset 的低 6 位可以表示這個范圍,對應于第一層 radix_tree_node 節點的 slots 陣列下標,
如果一顆 radix_tree 的深度為 2(不包括葉子節點),那么它就可以快取 64 * 64 = 4096 個檔案頁,表示的索引范圍為 0 - 4095,在這種情況下,快取頁索引 offset 的低 12 位可以分成 兩個 6 位的欄位,高位的欄位用來表示第一層節點的 slots 陣列的下標,低位欄位用于表示第二層節點的 slots 陣列下標,
依次類推,如果 radix_tree 的深度為 6 那么它可以快取 64T 的檔案頁,表示的索引范圍為:0 到 2^36 - 1, 快取頁索引 offset 的低 36 位可以分成 六 個 6 位的欄位,快取頁索引的最高位欄位來表示 radix_tree 中的第一層節點中的 slots 陣列下標,接下來的 6 位欄位表示第二層節點中的 slots 陣列下標,這樣一直到最低的 6 位欄位表示第 6 層節點中的 slots 陣列下標,
通過以上根據快取頁索引 offset 的查找程序,我們看出內核在 page cache 查找快取頁的時間復雜度和 radix_tree 的深度有關,
在我們理解了內核在 radix_tree 中的查找快取頁邏輯之后,再來看 find_get_page 的代碼實作就變得很簡單了~~
struct page *pagecache_get_page(struct address_space *mapping, pgoff_t offset,
int fgp_flags, gfp_t gfp_mask)
{
struct page *page;
repeat:
// 在 radix_tree 中根據 快取頁 offset 查找快取頁
page = find_get_entry(mapping, offset);
// 快取頁不存在的話,跳轉到 no_page 處理邏輯
if (!page)
goto no_page;
.......省略.......
no_page:
if (!page && (fgp_flags & FGP_CREAT)) {
// 分配新頁
page = __page_cache_alloc(gfp_mask);
if (!page)
return NULL;
if (fgp_flags & FGP_ACCESSED)
//增加頁的參考計數
__SetPageReferenced(page);
// 將新分配的記憶體頁加入到頁高速快取 page cache 中
err = add_to_page_cache_lru(page, mapping, offset, gfp_mask);
.......省略.......
}
return page;
}
-
內核首先呼叫 find_get_entry 方法根據快取頁的 offset 到 page cache 中去查找看請求的檔案頁是否已經在頁高速快取中,如果存在直接回傳,
-
如果請求的檔案頁不在 page cache 中,內核則會首先會在物理記憶體中分配一個記憶體頁,然后將新分配的記憶體頁加入到 page cache 中,并增加頁參考計數,
-
隨后會通過 address_space_operations 重定義的 readpage 激活塊設備驅動從磁盤中讀取請求資料,然后用讀取到的資料填充新分配的記憶體頁,
static const struct address_space_operations ext4_aops = {
.readpage = ext4_readpage,
.writepage = ext4_writepage,
.direct_IO = ext4_direct_IO,
........省略.....
};
9. 檔案頁的預讀
之前我們在引入 page cache 的時候提到過,根據程式時間區域性原理:如果行程在訪問某一塊資料,那么在訪問的不久之后,行程還會再次訪問這塊資料,所以內核引入了 page cache 在記憶體中快取磁盤中的熱點資料,從而減少對磁盤的 IO 訪問,提升系統性能,
而本小節我們要介紹的檔案頁預讀特性是根據程式空間區域性原理:當行程訪問一段資料之后,那么在不就的將來和其臨近的一段資料也會被訪問到,所以當行程在訪問檔案中的某頁資料的時候,內核會將它和臨近的幾個頁一起預讀到 page cache 中,這樣當行程再次訪問檔案的時候,就不需要進行龜速的磁盤 IO 了,因為它所請求的資料已經預讀進 page cache 中了,
我們常提到的當你順序讀取檔案的時候,性能會非常的高,因為相當于是在讀記憶體,這就是檔案預讀的功勞,
但是在我們隨機訪問檔案的時候,檔案預讀不僅不會提高性能,回傳會降低檔案讀取的性能,因為隨機讀取檔案并不符合程式空間區域性原理,因此預讀進 page cache 中的檔案頁通常是無效的,下一次根本不會再去讀取,這無疑是白白浪費了 page cache 的空間,還額外增加了不必要的預讀磁盤 IO,
事實上,在我們對檔案進行隨機讀取的場景下,更適合用 Direct IO 的方式繞過 page cache 直接從磁盤中讀取檔案,還能減少一次從 page cache 到用戶緩沖區的拷貝,
所以內核需要一套非常精密的預讀演算法來根據行程是順序讀檔案還是隨機讀檔案來精確地調控預讀的檔案頁數,或者直接關閉預讀,
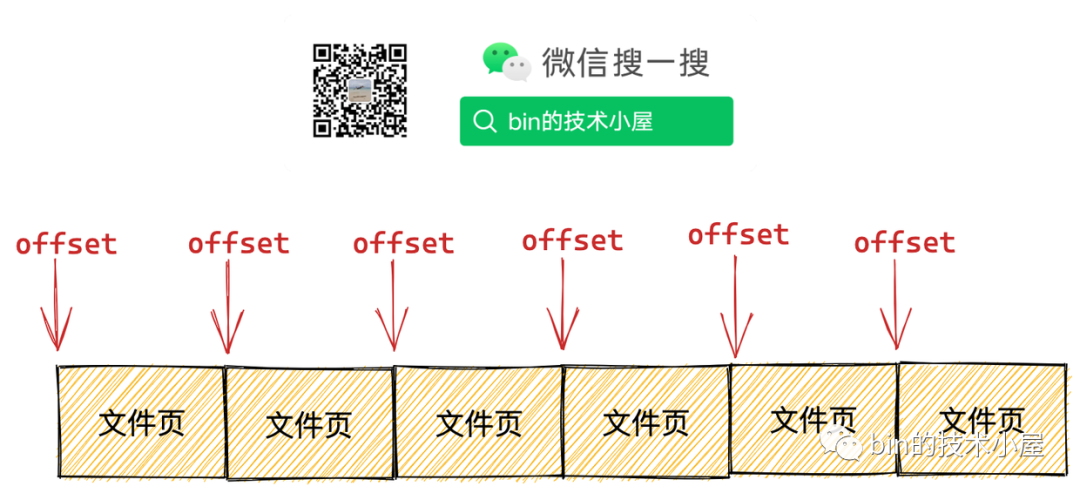
- 行程在讀取檔案資料的時候都是逐頁進行讀取的,因此在預讀檔案頁的時候內核并不會考慮頁內偏移,而是根據請求資料在檔案內部的頁偏移進行讀取,
-
如果行程持續的順序訪問一個檔案,那么預讀頁數也會隨著逐步增加,
-
當發現行程開始隨機訪問檔案了(當前訪問的檔案頁和最后一次訪問的檔案頁 offset 不是連續的),內核就會逐步減少預讀頁數或者徹底禁止預讀,
-
當內核發現行程再重復的訪問同一檔案頁時或者檔案中的檔案頁已經幾乎全部快取在 page cache 中了,內核此時就會禁止預讀,
以上幾點就是內核的預讀演算法的核心邏輯,從這個預讀邏輯中我們可以看出,行程在進行檔案讀取的時候涉及到兩種不同型別的頁面集合,一個是行程可以請求的檔案頁(已經快取在 page cache 中的檔案頁),另一個是內核預讀的檔案頁,
而內核也確實按照這兩種頁面集合分為兩個視窗:
-
當前視窗(current window): 表示行程本次檔案請求可以直接讀取的頁面集合,這個集合中的頁面全部已經快取在 page cache 中,行程可以直接讀取回傳,當前視窗中包含行程本次請求的檔案頁以及上次內核預讀的檔案頁集合,表示行程本次可以從 page cache 直接獲取的頁面范圍,
-
預讀視窗(ahead window):預讀視窗的頁面都是內核正在預讀的檔案頁,它們此時并不在 page cache 中,這些頁面并不是行程請求的檔案頁,但是內核根據空間區域性原理假定它們遲早會被行程請求,預讀視窗內的頁面緊跟著當前視窗后面,并且內核會動態調整預讀視窗的大小(有點類似于 TCP 中的滑動視窗),
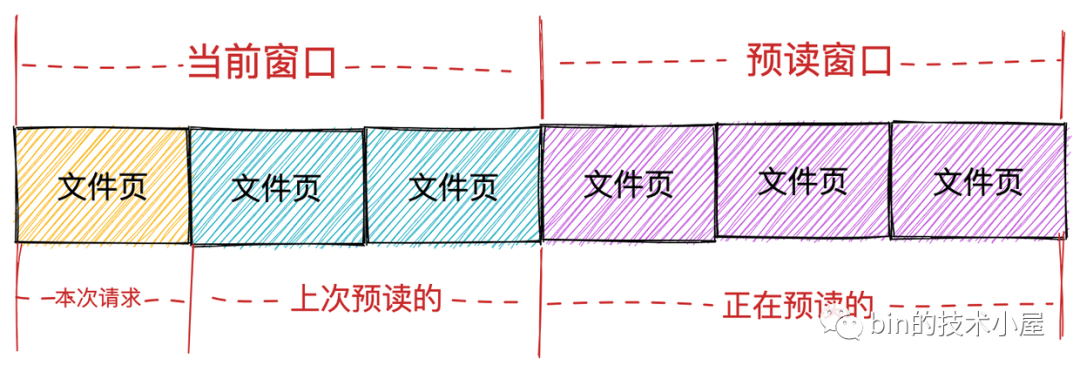
如果行程本次檔案請求的第一頁的 offset,緊跟著上一次檔案請求的最后一頁的 offset,內核就認為是順序讀取,在順序讀取檔案的場景下,如果請求的第一頁在當前視窗內,內核隨后就會檢查是否建立了預讀視窗,如果沒有就會創建預讀視窗并觸發相應頁的讀取操作,
在理想情況下,行程會繼續在當前視窗內請求頁,于此同時,預讀視窗內的預讀頁同時異步傳送著,這樣行程在順序讀取檔案的時候就相當于直接讀取記憶體,極大地提高了檔案 IO 的性能,
以上包含的這些檔案預讀資訊,比如:如何判斷行程是順序讀取還是隨機讀取,當前視窗資訊,預讀視窗資訊,全部保存在 struct file 結構中的 f_ra 欄位中,
struct file {
struct file_ra_state f_ra;
}
用于描述檔案預讀資訊的結構體在內核中用 struct file_ra_state 結構體來表示:
struct file_ra_state {
pgoff_t start; // 當前視窗第一頁的索引
unsigned int size; // 當前視窗的頁數,-1表示臨時禁止預讀
unsigned int async_size; // 異步預讀頁面的頁數
unsigned int ra_pages; // 檔案允許的最大預讀頁數
loff_t prev_pos; // 行程最后一次請求頁的索引
};
內核可以根據 start 和 prev_pos 這兩個欄位來判斷行程是否在順序訪問檔案,
ra_pages 表示當前檔案允許預讀的最大頁數,行程可以通過系統呼叫 posix_fadvise() 來改變已打開檔案的 ra_page 值來調優預讀演算法,
int posix_fadvise(int fd, off_t offset, off_t len, int advice);
該系統呼叫用來通知內核,我們將來打算以特定的模式 advice 訪問檔案資料,從而允許內核執行適當的優化,
advice 引數主要有下面幾種數值:
-
POSIX_FADV_NORMAL : 設定檔案最大預讀頁數 ra_pages 為默認值 32 頁,
-
POSIX_FADV_SEQUENTIAL : 行程期望順序訪問指定的檔案資料,ra_pages 值為默認值的兩倍,
-
POSIX_FADV_RANDOM :行程期望以隨機順序訪問指定的檔案資料,ra_pages 設定為 0,表示禁止預讀,
后來人們發現當禁止預讀后,這樣一頁一頁的讀取性能非常的低下,于是 linux 3.19.8 之后 POSIX_FADV_RANDOM 的語意被改變了,它會在 file->f_flags 中設定 FMODE_RANDOM 屬性(后面我們分析內核預讀相關原始碼的時候還會提到),當遇到 FMODE_RANDOM 的時候內核就會走強制預讀的邏輯,按最大 2MB 單元大小的 chunk 進行預讀,
This fixes inefficient page-by-page reads on POSIX_FADV_RANDOM.
POSIX_FADV_RANDOM used to set ra_pages=0, which leads to poor
performance: a 16K read will be carried out in 4 _sync_ 1-page reads.
- POSIX_FADV_WILLNEED :通知內核,行程指定這段檔案資料將在不久之后被訪問,
而觸發內核進行檔案預讀的場景,分為以下幾種:
-
當行程采用 Buffered IO 模式通過系統呼叫 read 進行檔案讀取時,內核會觸發預讀,
-
通過 POSIX_FADV_WILLNEED 引數執行系統呼叫 posix_fadvise,會通知內核這個指定范圍的檔案頁不就將會被訪問,觸發預讀,
-
當行程顯示執行 readahead() 系統呼叫時,會顯示觸發內核的預讀動作,
-
當內核為記憶體檔案映射區域分配一個物理頁面時,會觸發預讀,關于記憶體映射的相關內容,筆者會在后面的文章為大家詳細介紹,
-
和 posix_fadvise 一樣的道理,系統呼叫 madvise 主要用來指定記憶體檔案映射區域的訪問模式,可通過 advice = MADV_WILLNEED 通知內核,某個檔案記憶體映射區域中的指定范圍的檔案頁在不久將會被訪問,觸發預讀,
int madvise(caddr_t addr, size_t len, int advice);
從觸發內核預讀的這幾種場景中我們可以看出,預讀分為主動觸發和被動觸發,在《4.2 Buffered IO》小節中遺留的 page_cache_sync_readahead 函式為被動觸發,接下來我們來看下它在內核中的實作邏輯,
9.1 page_cache_sync_readahead
void page_cache_sync_readahead(struct address_space *mapping,
struct file_ra_state *ra, struct file *filp,
pgoff_t offset, unsigned long req_size)
{
// 禁止預讀,直接回傳
if (!ra->ra_pages)
return;
if (blk_cgroup_congested())
return;
// 通過 posix_fadvise 設定了 POSIX_FADV_RANDOM,內核走強制預讀邏輯
if (filp && (filp->f_mode & FMODE_RANDOM)) {
// 按最大2MB單元大小的chunk進行預讀
force_page_cache_readahead(mapping, filp, offset, req_size);
return;
}
// 執行預讀邏輯
ondemand_readahead(mapping, ra, filp, false, offset, req_size);
}
!ra->ra_pages 表示 ra_pages 設定為 0 ,預讀被禁止,直接回傳,
如果行程通過前邊介紹的 posix_fadvise 系統呼叫并且 advice 引數設定為 POSIX_FADV_RANDOM,在 linux 3.19.8 之后檔案的 file->f_flags 屬性會被設定為 FMODE_RANDOM,這樣內核會走強制預讀邏輯,按最大 2MB 單元大小的 chunk 進行預讀,
int posix_fadvise(int fd, off_t offset, off_t len, int advice);
// mm/fadvise.c
switch (advice) {
.........省略........
case POSIX_FADV_RANDOM:
.........省略........
file->f_flags |= FMODE_RANDOM;
.........省略........
break;
.........省略........
}
而真正的預讀邏輯封裝在 ondemand_readahead 函式中,
9.2 ondemand_readahead
該方法中封裝了前邊介紹的預讀演算法邏輯,動態的調整當前視窗以及預讀視窗的大小,
/*
* A minimal readahead algorithm for trivial sequential/random reads.
*/
static unsigned long
ondemand_readahead(struct address_space *mapping,
struct file_ra_state *ra, struct file *filp,
bool hit_readahead_marker, pgoff_t offset,
unsigned long req_size)
{
struct backing_dev_info *bdi = inode_to_bdi(mapping->host);
unsigned long max_pages = ra->ra_pages; // 默認32頁
unsigned long add_pages;
pgoff_t prev_offset;
........預讀演算法邏輯,動態調整當前視窗和預讀視窗.........
//根據條件,計算本次預讀最大預讀取多少個頁,一般情況下是max_pages=32個頁
if (req_size > max_pages && bdi->io_pages > max_pages)
max_pages = min(req_size, bdi->io_pages);
//offset即page index,如果page index=0,表示這是檔案第一個頁,
//內核認為是順序讀,跳轉到initial_readahead進行處理
if (!offset)
goto initial_readahead;
initial_readahead:
// 當前視窗第一頁的索引
ra->start = offset;
// get_init_ra_size初始化第一次預讀的頁的個數,一般情況下第一次預讀是4個頁
ra->size = get_init_ra_size(req_size, max_pages);
// 異步預讀頁面個數也就是預讀視窗大小
ra->async_size = ra->size > req_size ? ra->size - req_size : ra->size;
// 默認情況下是 ra->start=0, ra->size=0, ra->async_size=0 ra->prev_pos=0
// 但是經過第一次預讀后,上面三個值會出現變化
if ((offset == (ra->start + ra->size - ra->async_size) ||
offset == (ra->start + ra->size))) {
ra->start += ra->size;
ra->size = get_next_ra_size(ra, max_pages);
ra->async_size = ra->size;
goto readit;
}
//異步預讀的時候會進入這個判斷,更新ra的值,然后預讀特定的范圍的頁
//異步預讀的呼叫表示Readahead出來的頁連續命中
if (hit_readahead_marker) {
pgoff_t start;
rcu_read_lock();
// 這個函式用于找到offset + 1開始到offset + 1 + max_pages這個范圍內,第一個不在page cache的頁的index
start = page_cache_next_miss(mapping, offset + 1, max_pages);
rcu_read_unlock();
if (!start || start - offset > max_pages)
return 0;
ra->start = start;
ra->size = start - offset; /* old async_size */
ra->size += req_size;
// 由于連續命中,get_next_ra_size會加倍上次的預讀頁數
// 第一次預讀了4個頁
// 第二次命中以后,預讀8個頁
// 第三次命中以后,預讀16個頁
// 第四次命中以后,預讀32個頁,達到默認情況下最大的讀取頁數
// 第五次、第六次、第N次命中都是預讀32個頁
ra->size = get_next_ra_size(ra, max_pages);
ra->async_size = ra->size;
goto readit;
........ 省略.........
return __do_page_cache_readahead(mapping, filp, offset, req_size, 0);
}
-
struct address_space *mapping: 讀取檔案對應的 page cache 結構, -
struct file_ra_state *ra: 檔案對應的預讀狀態資訊,封裝在 file->f_ra 中, -
struct file *filp: 讀取檔案對應的 struct file 結構, -
pgoff_t offset: 本次請求檔案頁在 page cache 中的索引,(檔案頁偏移) -
long req_size: 要完成當前讀操作還需要讀取的頁數,
在預讀演算法邏輯中,內核通過 struct file_ra_state 結構中封裝的檔案預讀資訊來判斷檔案的讀取是否為順序讀,比如:
-
通過檢查 ra->prev_pos 和 offset 是否相同,來判斷當前請求頁是否和最近一次請求的頁相同,如果重復訪問同一頁,預讀就會停止,
-
通過檢查 ra->prev_pos 和 offset 是否相鄰,來判斷行程是否順序讀取檔案,如果是順序訪問檔案,預讀就會增加,
-
當行程第一次訪問檔案時,并且請求的第一個檔案頁在檔案中的偏移量為 0 時表示行程從頭開始讀取檔案,那么內核就會認為行程想要順序的訪問檔案,隨后內核就會從檔案的第一頁開始創建一個新的當前視窗,初始的當前視窗總是 2 的次冪,視窗具體大小與行程的讀操作所請求的頁數有一定的關系,請求頁數越大,當前視窗就越大,直到最大值 ra->ra_pages ,
static unsigned long get_init_ra_size(unsigned long size, unsigned long max)
{
unsigned long newsize = roundup_pow_of_two(size);
if (newsize <= max / 32)
newsize = newsize * 4;
else if (newsize <= max / 4)
newsize = newsize * 2;
else
newsize = max;
return newsize;
}
-
相反,當行程第一次訪問檔案,但是請求頁在檔案中的偏移量不為 0 時,內核就會假定行程不準備順序讀取檔案,函式就會暫時禁止預讀,
-
一旦內核發現行程在當前視窗內執行了順序讀取,那么預讀視窗就會被建立,預讀視窗總是緊挨著當前視窗的最后一頁,
-
預讀視窗的大小和當前視窗有關,如果已經被預讀的頁不在 page cache 中(可能記憶體緊張,預讀頁被回收),那么預讀視窗就會是
當前視窗大小 - 2,最小值為 4,否則預讀視窗就會是當前視窗的4倍或者2倍, -
當行程繼續順序訪問檔案時,最終預讀視窗就會變為當前視窗,隨后新的預讀視窗就會被建立,隨著行程順序地讀取檔案,預讀會越來越大,但是內核一旦發現對于檔案的訪問 offset 相對于上一次的請求頁 ra->prev_pos 不是順序的時候,當前視窗和預讀視窗就會被清空,預讀被暫時禁止,
當內核通過以上介紹的預讀演算法確定了預讀視窗的大小之后,就開始呼叫 __do_page_cache_readahead 從磁盤去預讀指定的頁數到 page cache 中,
9.3 __do_page_cache_readahead
unsigned int __do_page_cache_readahead(struct address_space *mapping,
struct file *filp, pgoff_t offset, unsigned long nr_to_read,
unsigned long lookahead_size)
{
struct inode *inode = mapping->host;
struct page *page;
unsigned long end_index; /* The last page we want to read */
int page_idx;
unsigned int nr_pages = 0;
loff_t isize = i_size_read(inode);
end_index = ((isize - 1) >> PAGE_SHIFT);
/*
* 盡可能的一次性分配全部需要預讀的頁 nr_to_read
* 注意這里是盡可能的分配,意思就是能分配多少就分配多少,并不一定要全部分配
*/
for (page_idx = 0; page_idx < nr_to_read; page_idx++) {
pgoff_t page_offset = offset + page_idx;
if (page_offset > end_index)
break;
.......省略.....
// 首先在記憶體中為預讀資料分配物理頁面
page = __page_cache_alloc(gfp_mask);
if (!page)
break;
// 設定新分配的物理頁在 page cache 中的索引
page->index = page_offset;
// 將新分配的物理頁面加入到 page cache 中
list_add(&page->lru, &page_pool);
if (page_idx == nr_to_read - lookahead_size)
// 設定頁面屬性為 PG_readahead 后續會開啟異步預讀
SetPageReadahead(page);
nr_pages++;
}
/*
* 當需要預讀的頁面分配完畢之后,開始真正的 IO 動作,從磁盤中讀取
* 資料填充 page cache 中的快取頁,
*/
if (nr_pages)
read_pages(mapping, filp, &page_pool, nr_pages, gfp_mask);
BUG_ON(!list_empty(&page_pool));
out:
return nr_pages;
}
內核呼叫 read_pages 方法激活磁盤塊設備驅動程式從磁盤中讀取檔案資料之前,需要為本次行程讀取請求所需要的所有頁面盡可能地一次性全部分配,如果不能一次性分配全部頁面,預讀操作就只在分配好的快取頁面上進行,也就是說只從磁盤中讀取資料填充已經分配好的頁面,
10. JDK NIO 對普通檔案的寫入
注意:下面的例子并不是最佳實踐,之所以這里引入 HeapByteBuffer 是為了將上篇文章的內容和本文銜接起來,事實上,對于 IO 的操作一般都會選擇 DirectByteBuffer ,關于 DirectByteBuffer 的相關內容筆者會在后面的文章中詳細為大家介紹,
FileChannel fileChannel = new RandomAccessFile(new File("file-read-write.txt"), "rw").getChannel();
ByteBuffer heapByteBuffer = ByteBuffer.allocate(4096);
fileChannel.write(heapByteBuffer);
在對檔案進行讀寫之前,我們需要首先利用 RandomAccessFile 在內核中打開指定的檔案 file-read-write.txt ,并獲取到它的檔案描述符 fd = 5000,
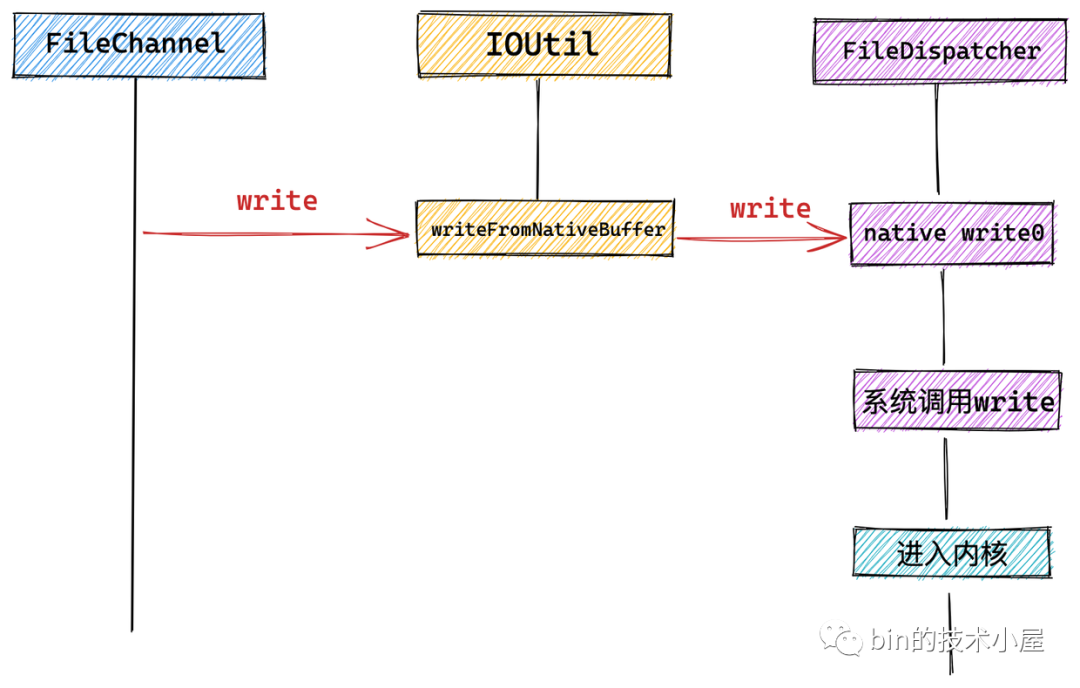
本例 heapByteBuffer 中存放著需要寫入檔案的內容,隨后來到 FileChannelImpl 實作類呼叫 IOUtil 觸發底層系統呼叫 write 來寫入檔案,
public class FileChannelImpl extends FileChannel {
// 前邊介紹打開的檔案描述符 5000
private final FileDescriptor fd;
// NIO中用它來觸發 native read 和 write 的系統呼叫
private final FileDispatcher nd;
// 讀寫檔案時加鎖,前邊介紹 FileChannel 的讀寫方法均是執行緒安全的
private final Object positionLock = new Object();
public int write(ByteBuffer src) throws IOException {
ensureOpen();
if (!writable)
throw new NonWritableChannelException();
synchronized (positionLock) {
//寫入的位元組數
int n = 0;
try {
......省略......
if (!isOpen())
return 0;
do {
n = IOUtil.write(fd, src, -1, nd);
} while ((n == IOStatus.INTERRUPTED) && isOpen());
// 回傳寫入的位元組數
return IOStatus.normalize(n);
} finally {
......省略......
}
}
}
}
NIO 中的所有 IO 操作全部封裝在 IOUtil 類中,而 NIO 中的 SocketChannel 以及這里介紹的 FileChannel 底層依賴的系統呼叫可能不同,這里會通過 NativeDispatcher 對具體 Channel 操作實作分發,呼叫具體的系統呼叫,對于 FileChannel 來說 NativeDispatcher 的實作類為 FileDispatcher,對于 SocketChannel 來說 NativeDispatcher 的實作類為 SocketDispatcher,
public class IOUtil {
static int write(FileDescriptor fd, ByteBuffer src, long position,
NativeDispatcher nd)
throws IOException
{
// 標記傳遞進來的 heapByteBuffer 的 position 位置用于后續恢復
int pos = src.position();
// 獲取 heapByteBuffer 的 limit 用于計算 寫入位元組數
int lim = src.limit();
assert (pos <= lim);
// 寫入的位元組數
int rem = (pos <= lim ? lim - pos : 0);
// 創建臨時的 DirectByteBuffer,用于通過系統呼叫 write 寫入資料到內核
ByteBuffer bb = Util.getTemporaryDirectBuffer(rem);
try {
// 將 heapByteBuffer 中的內容拷貝到臨時 DirectByteBuffer 中
bb.put(src);
// DirectByteBuffer 切換為讀模式,用于后續發送資料
bb.flip();
// 恢復 heapByteBuffer 中的 position
src.position(pos);
int n = writeFromNativeBuffer(fd, bb, position, nd);
if (n > 0) {
// 此時 heapByteBuffer 中的內容已經發送完畢,更新它的 postion + n
// 這里表達的語意是從 heapByteBuffer 中讀取了 n 個位元組并發送成功
src.position(pos + n);
}
// 回傳發送成功的位元組數
return n;
} finally {
// 釋放臨時創建的 DirectByteBuffer
Util.offerFirstTemporaryDirectBuffer(bb);
}
}
private static int writeFromNativeBuffer(FileDescriptor fd, ByteBuffer bb,
long position, NativeDispatcher nd)
throws IOException
{
int pos = bb.position();
int lim = bb.limit();
assert (pos <= lim);
// 要發送的位元組數
int rem = (pos <= lim ? lim - pos : 0);
int written = 0;
if (rem == 0)
return 0;
if (position != -1) {
........省略.......
} else {
written = nd.write(fd, ((DirectBuffer)bb).address() + pos, rem);
}
if (written > 0)
// 發送完畢之后更新 DirectByteBuffer 的position
bb.position(pos + written);
// 回傳寫入的位元組數
return written;
}
}
在 IOUtil 中首先創建一個臨時的 DirectByteBuffer,然后將本例中 HeapByteBuffer 中的資料全部拷貝到這個臨時的 DirectByteBuffer 中,這個 DirectByteBuffer 就是我們在 IO 系統呼叫中經常提到的用戶空間緩沖區,
隨后在 writeFromNativeBuffer 方法中通過 FileDispatcher 觸發 JNI 層的
native 方法執行底層系統呼叫 write ,
class FileDispatcherImpl extends FileDispatcher {
int write(FileDescriptor fd, long address, int len) throws IOException {
return write0(fd, address, len);
}
static native int write0(FileDescriptor fd, long address, int len)
throws IOException;
}
NIO 中關于檔案 IO 相關的系統呼叫全部封裝在 JNI 層中的 FileDispatcherImpl.c 檔案中,里邊定義了各種 IO 相關的系統呼叫的 native 方法,
// FileDispatcherImpl.c 檔案
JNIEXPORT jint JNICALL
Java_sun_nio_ch_FileDispatcherImpl_write0(JNIEnv *env, jclass clazz,
jobject fdo, jlong address, jint len)
{
jint fd = fdval(env, fdo);
void *buf = (void *)jlong_to_ptr(address);
// 發起 write 系統呼叫進入內核
return convertReturnVal(env, write(fd, buf, len), JNI_FALSE);
}
系統呼叫 write 在內核中的定義如下所示:
SYSCALL_DEFINE3(write, unsigned int, fd, const char __user *, buf,
size_t, count)
{
struct fd f = fdget_pos(fd);
......
loff_t pos = file_pos_read(f.file);
ret = vfs_write(f.file, buf, count, &pos);
......
}
現在我們就從用戶空間的 JDK NIO 這一層逐步來到了內核空間的邊界處 --- OS 系統呼叫 write 這里,馬上就要進入內核了,
這一次我們來看一下當系統呼叫 write 發起之后,用戶行程在內核態具體做了哪些事情?
11. 從內核角度探秘檔案寫入本質
現在讓我們再次進入內核,來看一下內核中具體是如何處理檔案寫入操作的,這個程序會比檔案讀取要復雜很多,大家需要有點耐心~~
再次強調一下,本文所舉示例中用到的 HeapByteBuffer 只是為了與上篇文章 《一步一圖帶你深入剖析 JDK NIO ByteBuffer 在不同位元組序下的設計與實作》介紹的內容做出呼應,并不是最佳實踐,筆者會在后續的文章中一步一步為大家展開這塊內容的最佳實踐,
11.1 Buffered IO
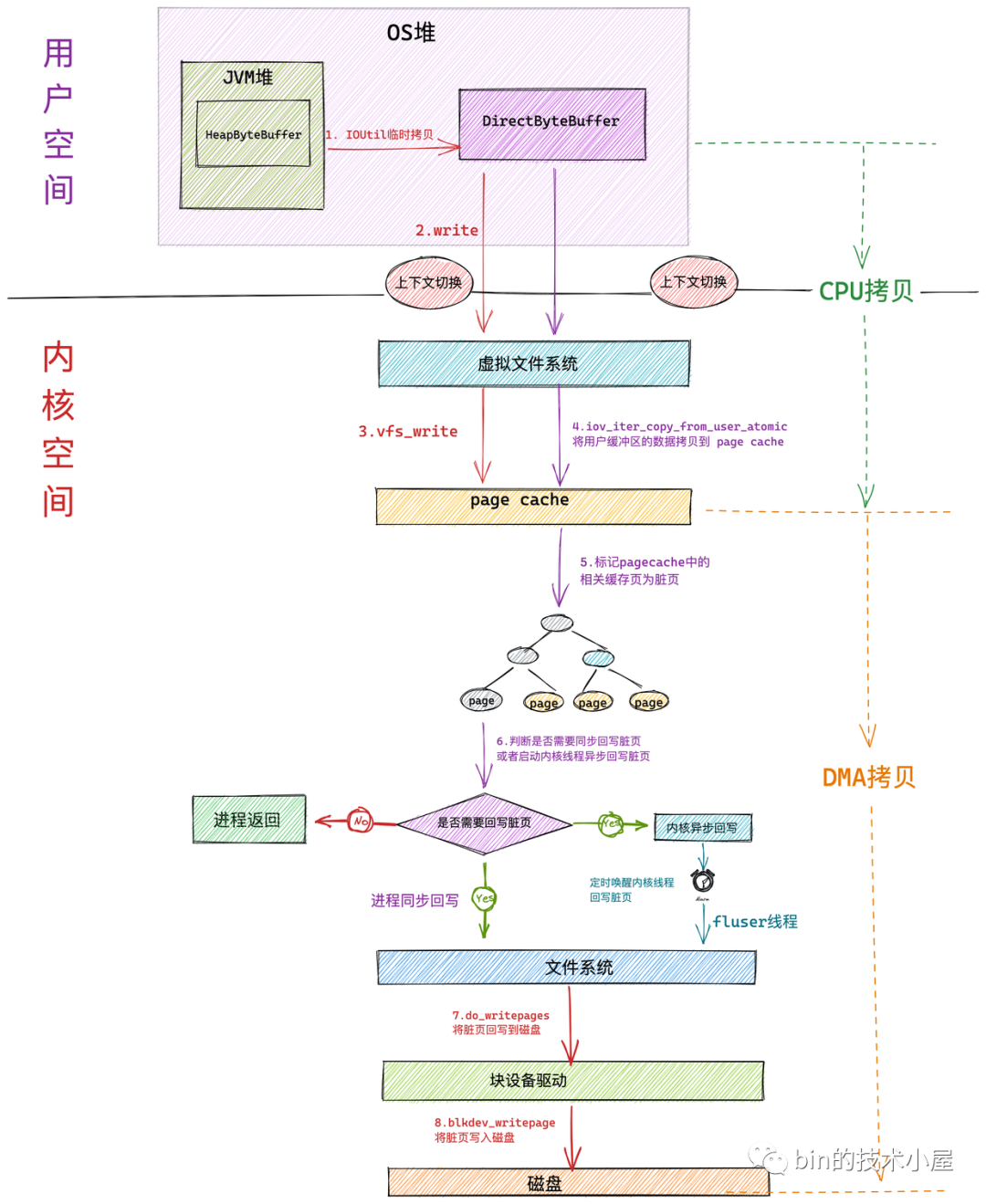
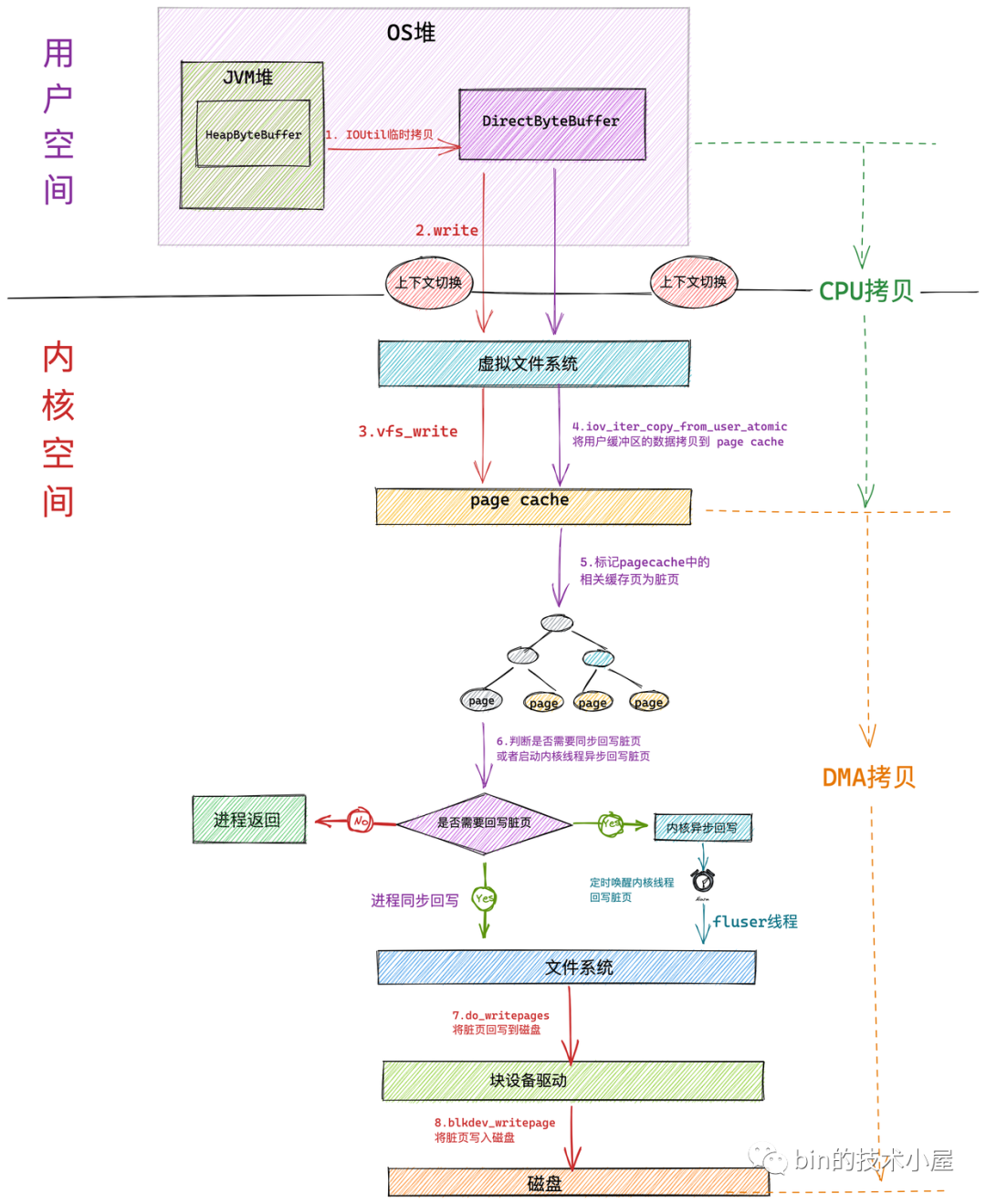
使用 JDK NIO 中的 HeapByteBuffer 在對檔案進行寫入的程序,主要分為如下幾個核心步驟:
-
首先會在用戶空間的 JDK 層將位于 JVM 堆中的 HeapByteBuffer 中的待寫入資料拷貝到位于 OS 堆中的 DirectByteBuffer 中,這里發生第一次拷貝
-
隨后 NIO 會在用戶態通過系統呼叫 write 發起檔案寫入的請求,此時發生第一次背景關系切換,
-
隨后用戶行程進入內核態,在虛擬檔案系統層呼叫 vfs_write 觸發對 page cache 寫入的操作,相關操作封裝在 generic_perform_write 函式中,這個后面筆者會細講,這里我們只關注核心總體流程,
-
內核呼叫 iov_iter_copy_from_user_atomic 函式將用戶空間緩沖區 DirectByteBuffer 中的待寫入資料拷貝到 page cache 中,發生第二次拷貝動作,這里的操作就是我們常說的 CPU 拷貝,
-
當待寫入資料拷貝到 page cache 中時,內核會將對應的檔案頁標記為臟頁,
臟頁表示記憶體中的資料要比磁盤中對應檔案資料要新,
- 此時內核會根據一定的閾值判斷是否要對 page cache 中的臟頁進行回寫,如果不需要同步回寫,行程直接回傳,檔案寫入操作完成,這里發生第二次背景關系切換
從這里我們看到在對檔案進行寫入時,內核只會將資料寫入到 page cache 中,整個寫入程序就完成了,并不會寫到磁盤中,
- 臟頁回寫又會根據臟頁數量在記憶體中的占比分為:行程同步回寫和內核異步回寫,當臟頁太多了,行程自己都看不下去的時候,會同步回寫記憶體中的臟頁,直到回寫完畢才會回傳,在回寫的程序中會發生第三次拷貝,通過DMA 將 page cache 中的臟頁寫入到磁盤中,
所謂內核異步回寫就是內核會定時喚醒一個 flusher 執行緒,定時將記憶體中的臟頁回寫到磁盤中,這部分的內容筆者會在后續的章節中詳細講解,
在 NIO 使用 HeapByteBuffer 在對檔案進行寫入的程序中,一般只會發生兩次拷貝動作和兩次背景關系切換,因為內核將資料拷貝到 page cache 中后,檔案寫入程序就結束了,如果臟頁在記憶體中的占比太高了,達到了行程同步回寫的閾值,那么就會發生第三次 DMA 拷貝,將臟頁資料回寫到磁盤檔案中,
如果行程需要同步回寫臟頁資料時,在本例中是要發生三次拷貝動作,但一般情況下,在本例中只會發生兩次,沒有第三次的 DMA 拷貝,
11.2 Direct IO
在 JDK 10 中我們可以通過如下的方式采用 Direct IO 模式打開檔案:
FileChannel fc = FileChannel.open(p, StandardOpenOption.WRITE,
ExtendedOpenOption.DIRECT)
在 Direct IO 模式下的檔案寫入操作最明顯的特點就是繞過 page cache 直接通過 DMA 拷貝將用戶空間緩沖區 DirectByteBuffer 中的待寫入資料寫入到磁盤中,
-
同樣發生兩次背景關系切換、
-
在本例中只會發生兩次資料拷貝,第一次是將 JVM 堆中的 HeapByteBuffer 中的待寫入資料拷貝到位于 OS 堆中的 DirectByteBuffer 中,第二次則是 DMA 拷貝,將用戶空間緩沖區 DirectByteBuffer 中的待寫入資料寫入到磁盤中,
12. Talk is cheap ! show you the code
下面是系統呼叫 write 在內核中的完整定義:
SYSCALL_DEFINE3(write, unsigned int, fd, const char __user *, buf,
size_t, count)
{
// 根據檔案描述符獲取檔案對應的 struct file 結構
struct fd f = fdget_pos(fd);
......
// 獲取當前檔案的寫入位置 offset
loff_t pos = file_pos_read(f.file);
// 進入虛擬檔案系統層,執行具體的檔案寫入操作
ret = vfs_write(f.file, buf, count, &pos);
......
}
這里和檔案讀取的流程基本一樣,也是通過 vfs_write 進入虛擬檔案系統層,
ssize_t __vfs_write(struct file *file, const char __user *p, size_t count,
loff_t *pos)
{
if (file->f_op->write)
return file->f_op->write(file, p, count, pos);
else if (file->f_op->write_iter)
return new_sync_write(file, p, count, pos);
else
return -EINVAL;
}
在虛擬檔案系統層,通過 struct file 中定義的函式指標 file_operations 在具體的檔案系統中執行相應的檔案 IO 操作,我們還是以 ext4 檔案系統為例,
struct file {
const struct file_operations *f_op;
}
在 ext4 檔案系統中 .write_iter 函式指標指向的是 ext4_file_write_iter 函式執行具體的檔案寫入操作,
const struct file_operations ext4_file_operations = {
......省略........
.read_iter = ext4_file_read_iter,
.write_iter = ext4_file_write_iter,
......省略.........
}
由于 ext4_file_operations 中只定義了 .write_iter 函式指標,所以在 __vfs_write 函式中流程進入 else if {......} 分支來到 new_sync_write 函式中:
static ssize_t new_sync_write(struct file *filp, const char __user *buf, size_t len, loff_t *ppos)
{
// 將 DirectByteBuffer 以及要寫入的位元組數封裝進 iovec 結構體中
struct iovec iov = { .iov_base = (void __user *)buf, .iov_len = len };
// 用來封裝檔案 IO 相關操作的狀態和進度資訊:
struct kiocb kiocb;
// 用來封裝用用戶快取區 DirectByteBuffer 的相關的資訊
struct iov_iter iter;
ssize_t ret;
// 利用檔案 struct file 初始化 kiocb 結構體
init_sync_kiocb(&kiocb, filp);
// 設定檔案寫入偏移位置
kiocb.ki_pos = (ppos ? *ppos : 0);
iov_iter_init(&iter, WRITE, &iov, 1, len);
// 呼叫 ext4_file_write_iter
ret = call_write_iter(filp, &kiocb, &iter);
BUG_ON(ret == -EIOCBQUEUED);
if (ret > 0 && ppos)
*ppos = kiocb.ki_pos;
return ret;
}
在檔案讀取的相關章節中,我們介紹了用于封裝傳遞進來的用戶空間緩沖區 DirectByteBuffer 相關資訊的 struct iovec 結構體,也介紹了用于封裝檔案 IO 相關操作的狀態和進度資訊的 struct kiocb 結構體,這里筆者不在贅述,
不過在這里筆者還是想強調的一下,內核中一般會使用 struct iov_iter 結構體對 struct iovec 進行包裝,iov_iter 中包含多個 iovec,
struct iov_iter {
......省略.....
const struct iovec *iov;
}
這是為了兼容 readv() ,writev() 等系統呼叫,它允許用戶使用多個快取區去讀取檔案中的資料或者從多個緩沖區中寫入資料到檔案中,
-
JDK NIO Channel 支持的 Scatter 操作底層原理就是 readv 系統呼叫,
-
JDK NIO Channel 支持的 Gather 操作底層原理就是 writev 系統呼叫,
FileChannel fileChannel = new RandomAccessFile(new File("file-read-write.txt"), "rw").getChannel();
ByteBuffer heapByteBuffer1 = ByteBuffer.allocate(4096);
ByteBuffer heapByteBuffer2 = ByteBuffer.allocate(4096);
ByteBuffer[] gather = { heapByteBuffer1, heapByteBuffer2 };
fileChannel.write(gather);
最終在 call_write_iter 中觸發 ext4_file_write_iter 的呼叫,從虛擬檔案系統層進入到具體檔案系統 ext4 中,
static inline ssize_t call_write_iter(struct file *file, struct kiocb *kio,
struct iov_iter *iter)
{
return file->f_op->write_iter(kio, iter);
}
static ssize_t
ext4_file_write_iter(struct kiocb *iocb, struct iov_iter *from)
{
..........省略..........
ret = __generic_file_write_iter(iocb, from);
return ret;
}
我們看到在檔案系統 ext4 中呼叫的是 __generic_file_write_iter 方法,內核針對檔案寫入的所有邏輯都封裝在這里,
ssize_t __generic_file_write_iter(struct kiocb *iocb, struct iov_iter *from)
{
struct file *file = iocb->ki_filp;
struct address_space * mapping = file->f_mapping;
struct inode *inode = mapping->host;
ssize_t written = 0;
ssize_t err;
ssize_t status;
........省略基本校驗邏輯和更新檔案原資料邏輯........
if (iocb->ki_flags & IOCB_DIRECT) {
loff_t pos, endbyte;
// Direct IO
written = generic_file_direct_write(iocb, from);
.......省略......
} else {
// Buffered IO
written = generic_perform_write(file, from, iocb->ki_pos);
if (likely(written > 0))
iocb->ki_pos += written;
}
.......省略......
// 回傳寫入檔案的位元組數 或者 錯誤
return written ? written : err;
}
這里和我們在介紹檔案讀取時候提到的 generic_file_read_iter 函式中的邏輯是一樣的,都會處理 Direct IO 和 Buffered IO 的場景,
這里對于 Direct IO 的處理都是一樣的,在 generic_file_direct_write 中也是會呼叫 address_space 中的 address_space_operations 定義的 .direct_IO 函式指標來繞過 page cache 直接寫入磁盤,
struct address_space {
const struct address_space_operations *a_ops;
}
written = mapping->a_ops->direct_IO(iocb, from);
在 ext4 檔案系統中實作 Direct IO 的函式是 ext4_direct_IO,這里直接會呼叫到塊設備驅動層,通過 do_blockdev_direct_IO 直接將用戶空間緩沖區 DirectByteBuffer 中的內容寫入磁盤中,do_blockdev_direct_IO 函式會等到所有的 Direct IO 寫入到磁盤之后才會回傳,
static const struct address_space_operations ext4_aops = {
.direct_IO = ext4_direct_IO,
};
Direct IO 是由 DMA 直接從用戶空間緩沖區 DirectByteBuffer 中拷貝到磁盤中,
下面我們主要介紹下 Buffered IO 的寫入邏輯 generic_perform_write 方法,
12.1 Buffered IO
ssize_t generic_perform_write(struct file *file,
struct iov_iter *i, loff_t pos)
{
// 獲取 page cache,資料將會被寫入到這里
struct address_space *mapping = file->f_mapping;
// 獲取 page cache 相關的操作函式
const struct address_space_operations *a_ops = mapping->a_ops;
long status = 0;
ssize_t written = 0;
unsigned int flags = 0;
do {
// 用于參考要寫入的檔案頁
struct page *page;
// 要寫入的檔案頁在 page cache 中的 index
unsigned long offset; /* Offset into pagecache page */
unsigned long bytes; /* Bytes to write to page */
size_t copied; /* Bytes copied from user */
offset = (pos & (PAGE_SIZE - 1));
bytes = min_t(unsigned long, PAGE_SIZE - offset,
iov_iter_count(i));
again:
// 檢查用戶空間緩沖區 DirectByteBuffer 地址是否有效
if (unlikely(iov_iter_fault_in_readable(i, bytes))) {
status = -EFAULT;
break;
}
// 從 page cache 中獲取要寫入的檔案頁并準備記錄檔案元資料日志作業
status = a_ops->write_begin(file, mapping, pos, bytes, flags,
&page, &fsdata);
// 將用戶空間緩沖區 DirectByteBuffer 中的資料拷貝到 page cache 中的檔案頁中
copied = iov_iter_copy_from_user_atomic(page, i, offset, bytes);
flush_dcache_page(page);
// 將寫入的檔案頁標記為臟頁并完成檔案元資料日志的寫入
status = a_ops->write_end(file, mapping, pos, bytes, copied,
page, fsdata);
// 更新檔案 ppos
pos += copied;
written += copied;
// 判斷是否需要回寫臟頁
balance_dirty_pages_ratelimited(mapping);
} while (iov_iter_count(i));
// 回傳寫入位元組數
return written ? written : status;
}
由于本文中筆者是以 ext4 檔案系統為例來介紹檔案的讀寫流程,本小節中介紹的檔案寫入流程涉及到與檔案系統相關的兩個操作:write_begin,write_end,這兩個函式在不同的檔案系統中都有不同的實作,在不同的檔案系統中,寫入每一個檔案頁都需要呼叫一次 write_begin,write_end 這兩個方法,
static const struct address_space_operations ext4_aops = {
......省略.......
.write_begin = ext4_write_begin,
.write_end = ext4_write_end,
......省略.......
}
下圖為本文中涉及檔案讀寫的所有內核資料結構圖:
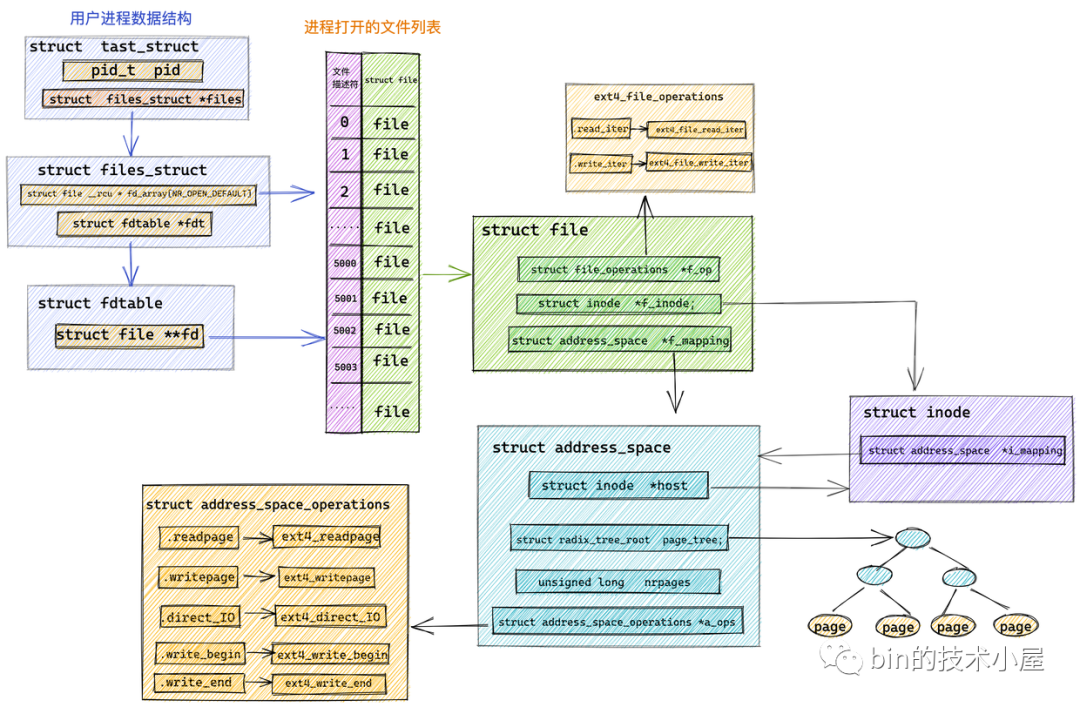
經過前邊介紹檔案讀取的章節我們知道在讀取檔案的時候都是先從 page cache 中讀取,如果 page cache 正好快取了檔案頁就直接回傳,如果沒有在進行磁盤 IO,
檔案的寫入程序也是一樣,內核會將用戶緩沖區 DirectByteBuffer 中的待寫資料先拷貝到 page cache 中,寫完就直接回傳,后續內核會根據一定的規則把這些檔案頁回寫到磁盤中,
從這個程序我們可以看出,內核將資料先是寫入 page cache 中但是不會立刻寫入磁盤中,如果突然斷電或者系統崩潰就可能導致檔案系統處于不一致的狀態,
為了解決這種場景,于是 linux 內核引入了 ext3 , ext4 等日志檔案系統,而日志檔案系統比非日志檔案系統在磁盤中多了一塊 Journal 區域,Journal 區域就是存放管理檔案元資料和檔案資料操作日志的磁盤區域,
-
檔案元資料的日志用于恢復檔案系統的一致性,
-
檔案資料的日志用于防止系統故障造成的檔案內容損壞,
ext3 , ext4 等日志檔案系統分為三種模式,我們可以在掛載的時候選擇不同的模式,
-
日志模式(Journal 模式):這種模式在將資料寫入檔案系統前,必須等待元資料和資料的日志已經落盤才能發揮作用,這樣性能比較差,但是最安全,
-
順序模式(Order 模式): 在 Order 模式不會記錄資料的日志,只會記錄元資料的日志,但是在寫元資料的日志前,必須先確保資料已經落盤,這樣可以減少檔案內容損壞的機會,這種模式是對性能的一種折中,是默認模式,
-
回寫模式(WriteBack 模式):WriteBack 模式 和 Order 模式一樣它們都不會記錄資料的日志,只會記錄元資料的日志,不同的是在 WriteBack 模式下不會保證資料比元資料先落盤,這個性能最好,但是最不安全,
而 write_begin,write_end 正是對檔案系統中相關日志的操作,在 ext4 檔案系統中對應的是 ext4_write_begin,ext4_write_end,下面我們就來看一下在 Buffered IO 模式下對于 ext4 檔案系統中的檔案寫入的核心步驟,
12.2 ext4_write_begin
static int ext4_write_begin(struct file *file, struct address_space *mapping,
loff_t pos, unsigned len, unsigned flags,
struct page **pagep, void **fsdata)
{
struct inode *inode = mapping->host;
struct page *page;
pgoff_t index;
...........省略.......
retry_grab:
// 從 page cache 中查找要寫入檔案頁
page = grab_cache_page_write_begin(mapping, index, flags);
if (!page)
return -ENOMEM;
unlock_page(page);
retry_journal:
// 相關日志的準備作業
handle = ext4_journal_start(inode, EXT4_HT_WRITE_PAGE, needed_blocks);
...........省略.......
在寫入檔案資料之前,內核在 ext4_write_begin 方法中呼叫 ext4_journal_start 方法做一些相關日志的準備作業,
還有一個重要的事情是在 grab_cache_page_write_begin 方法中從 page cache 中根據 index 查找要寫入資料的檔案快取頁,
struct page *grab_cache_page_write_begin(struct address_space *mapping,
pgoff_t index, unsigned flags)
{
struct page *page;
int fgp_flags = FGP_LOCK|FGP_WRITE|FGP_CREAT;
// 在 page cache 中查找寫入資料的快取頁
page = pagecache_get_page(mapping, index, fgp_flags,
mapping_gfp_mask(mapping));
if (page)
wait_for_stable_page(page);
return page;
}
通過 pagecache_get_page 在 page cache 中查找要寫入資料的快取頁,如果快取頁不在 page cache 中,內核則會首先會在物理記憶體中分配一個記憶體頁,然后將新分配的記憶體頁加入到 page cache 中,
相關的查找程序筆者已經在 《8. page cache 中查找快取頁》小節中詳細介紹過了,這里不在贅述,
12.3 iov_iter_copy_from_user_atomic
這里就是寫入程序的關鍵所在,圖中描述的 CPU 拷貝是將用戶空間快取區 DirectByteBuffer 中的待寫入資料拷貝到內核里的 page cache 中,這個程序就發生在這里,
size_t iov_iter_copy_from_user_atomic(struct page *page,
struct iov_iter *i, unsigned long offset, size_t bytes)
{
// 將快取頁臨時映射到內核虛擬地址空間的高端地址上
char *kaddr = kmap_atomic(page),
*p = kaddr + offset;
// 將用戶快取區 DirectByteBuffer 中的待寫入資料拷貝到檔案快取頁中
iterate_all_kinds(i, bytes, v,
copyin((p += v.iov_len) - v.iov_len, v.iov_base, v.iov_len),
memcpy_from_page((p += v.bv_len) - v.bv_len, v.bv_page,
v.bv_offset, v.bv_len),
memcpy((p += v.iov_len) - v.iov_len, v.iov_base, v.iov_len)
)
// 解除內核虛擬地址空間與快取頁之間的臨時映射,這里映射只是為了拷貝資料用
kunmap_atomic(kaddr);
return bytes;
}
但是這里不能直接進行拷貝,因為此時從 page cache 中取出的快取頁 page 是物理地址,而在內核中是不能夠直接操作物理地址的,只能操作虛擬地址,
那怎么辦呢?所以就需要呼叫 kmap_atomic 將快取頁臨時映射到內核空間的一段虛擬地址上,然后將用戶空間快取區 DirectByteBuffer 中的待寫入資料通過這段映射的虛擬地址拷貝到 page cache 中的相應快取頁中,這時檔案的寫入操作就已經完成了,
從這里我們看出,內核對于檔案的寫入只是將資料寫入到 page cache 中就完事了并沒有真正地寫入磁盤,
由于是臨時映射,所以在拷貝完成之后,呼叫 kunmap_atomic 將這段映射再解除掉,
12.4 ext4_write_end
static int ext4_write_end(struct file *file,
struct address_space *mapping,
loff_t pos, unsigned len, unsigned copied,
struct page *page, void *fsdata)
{
handle_t *handle = ext4_journal_current_handle();
struct inode *inode = mapping->host;
......省略.......
// 將寫入的快取頁在 page cache 中標記為臟頁
copied = block_write_end(file, mapping, pos, len, copied, page, fsdata);
......省略.......
// 完成相關日志的寫入
ret2 = ext4_journal_stop(handle);
......省略.......
}
在這里會對檔案的寫入流程做一些收尾的作業,比如在 block_write_end 方法中會呼叫 mark_buffer_dirty 將寫入的快取頁在 page cache 中標記為臟頁,后續內核會根據一定的規則將 page cache 中的這些臟頁回寫進磁盤中,
具體的標記程序筆者已經在《7.1 radix_tree 的標記》小節中詳細介紹過了,這里不在贅述,
另一個核心的步驟就是呼叫 ext4_journal_stop 完成相關日志的寫入,這里日志也只是會先寫到快取里,不會直接落盤,
12.5 balance_dirty_pages_ratelimited
當行程將待寫資料寫入 page cache 中之后,相應的快取頁就變為了臟頁,我們需要找一個時機將這些臟頁回寫到磁盤中,防止斷電導致資料丟失,
本小節我們主要聚焦于臟頁回寫的主體流程,相應細節部分以及內核對臟頁的回寫時機我們放在下一小節中在詳細為大家介紹,
void balance_dirty_pages_ratelimited(struct address_space *mapping)
{
struct inode *inode = mapping->host;
struct backing_dev_info *bdi = inode_to_bdi(inode);
struct bdi_writeback *wb = NULL;
int ratelimit;
......省略......
if (unlikely(current->nr_dirtied >= ratelimit))
balance_dirty_pages(mapping, wb, current->nr_dirtied);
......省略......
}
在 balance_dirty_pages_ratelimited 會判斷如果臟頁數量在記憶體中達到了一定的規模 ratelimit 就會觸發 balance_dirty_pages 回寫臟頁邏輯,
static void balance_dirty_pages(struct address_space *mapping,
struct bdi_writeback *wb,
unsigned long pages_dirtied)
{
.......根據內核異步回寫閾值判斷是否需要喚醒 flusher 執行緒異步回寫臟頁...
if (nr_reclaimable > gdtc->bg_thresh)
wb_start_background_writeback(wb);
}
如果達到了臟頁回寫的條件,那么內核就會喚醒 flusher 執行緒去將這些臟頁異步回寫到磁盤中,
void wb_start_background_writeback(struct bdi_writeback *wb)
{
/*
* We just wake up the flusher thread. It will perform background
* writeback as soon as there is no other work to do.
*/
wb_wakeup(wb);
}
13. 內核回寫臟頁的觸發時機
經過前邊對檔案寫入程序的介紹我們看到,用戶行程在對檔案進行寫操作的時候只是將待寫入資料從用戶空間的緩沖區 DirectByteBuffer 寫入到內核中的 page cache 中就結束了,后面內核會對臟頁進行延時寫入到磁盤中,
當 page cache 中的快取頁比磁盤中對應的檔案頁的資料要新時,就稱這些快取頁為臟頁,
延時寫入的好處就是行程可以多次頻繁的對檔案進行寫入但都是寫入到 page cache 中不會有任何磁盤 IO 發生,隨后內核可以將行程的這些多次寫入操作轉換為一次磁盤 IO ,將這些寫入的臟頁一次性重繪回磁盤中,這樣就把多次磁盤 IO 轉換為一次磁盤 IO 極大地提升檔案 IO 的性能,
那么內核在什么情況下才會去觸發 page cache 中的臟頁回寫呢?
-
內核在初始化的時候,會創建一個 timer 定時器去定時喚醒內核 flusher 執行緒回寫臟頁,
-
當記憶體中臟頁的數量太多了達到了一定的比例,就會主動喚醒內核中的 flusher 執行緒去回寫臟頁,
-
臟頁在記憶體中停留的時間太久了,等到 flusher 執行緒下一次被喚醒的時候就會回寫這些駐留太久的臟頁,
-
用戶行程可以通過 sync() 回寫記憶體中的所有臟頁和 fsync() 回寫指定檔案的所有臟頁,這些是行程主動發起臟頁回寫請求,
-
在記憶體比較緊張的情況下,需要回收物理頁或者將物理頁中的內容 swap 到磁盤上時,如果發現通過頁面置換演算法置換出來的頁是臟頁,那么就會觸發回寫,
現在我們了解了內核回寫臟頁的一個大概時機,這里大家可能會問了:
-
內核通過 timer 定時喚醒 flush 執行緒回寫臟頁,那么到底間隔多久喚醒呢?
-
記憶體中的臟頁數量太多會觸發回寫,那么這里的太多指的具體是多少呢?
-
臟頁在記憶體中駐留太久也會觸發回寫,那么這里的太久指的到底是多久呢?
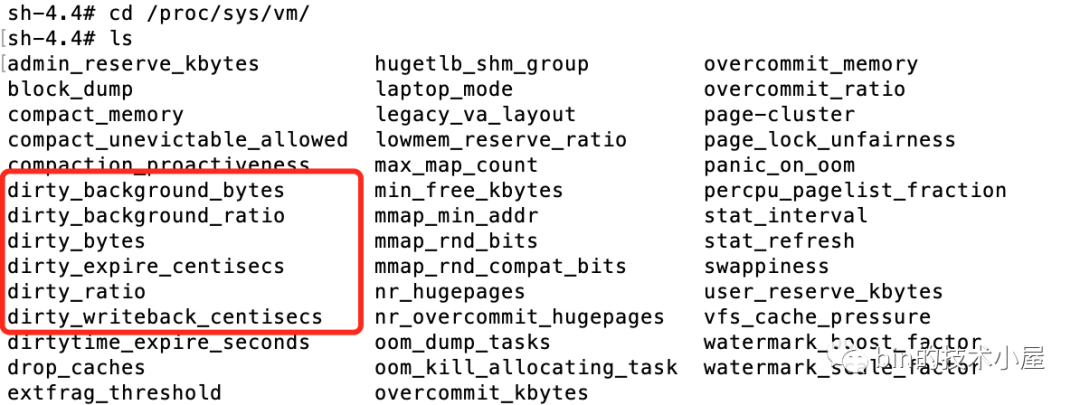
其實這三個問題中涉及到的具體數值,內核都提供了引數供我們來配置,這些引數的組態檔存在于 proc/sys/vm 目錄下:
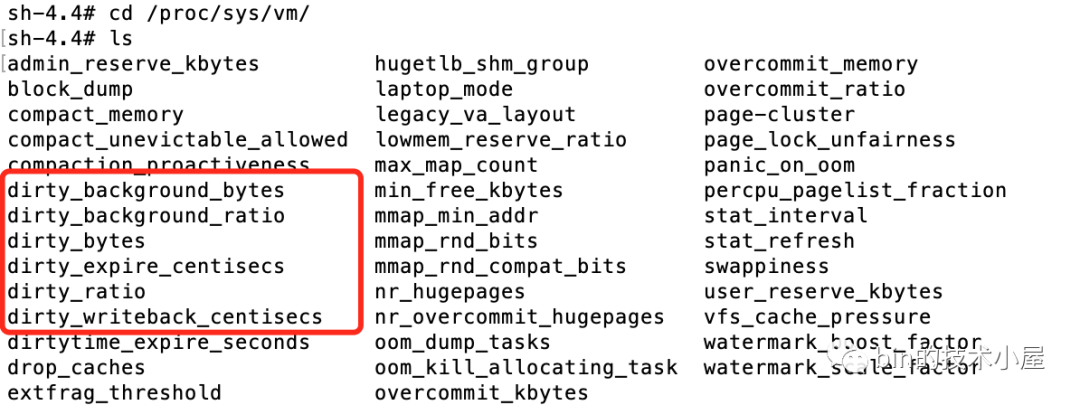
下面筆者就為大家介紹下內核回寫臟頁涉及到的這 6 個引數,并解答上面我們提出的這三個問題,
13.1 內核中的定時器間隔多久喚醒 flusher 執行緒
內核中通過 dirty_writeback_centisecs 引數來配置喚醒 flusher 執行緒的間隔時間,

該引數可以通過修改 /proc/sys/vm/dirty_writeback_centisecs 檔案來配置引數,我們也可以通過 sysctl 命令或者通過修改 /etc/sysctl.conf 組態檔來對這些引數進行修改,
這里我們先主要關注這些內核引數的含義以及原始碼實作,文章后面筆者有一個專門的章節來介紹這些內核引數各種不同的配置方式,
dirty_writeback_centisecs 內核引數的默認值為 500,單位為 0.01 s,也就是說內核會每隔 5s 喚醒一次 flusher 執行緒來執行相關臟頁的回寫,該引數在內核原始碼中對應的變數名為 dirty_writeback_interval,
筆者這里在列舉一個生活中的例子來解釋下這個 dirty_writeback_interval 的作用,
假設大家的作業都非常繁忙,于是大家就到家政公司請了專門的保潔阿姨(內核 flusher 回寫執行緒)來幫助我們打掃房間衛生(回寫臟頁),你和保潔阿姨約定每周(dirty_writeback_interval)來你房間(記憶體)打掃一次衛生(回寫臟頁),保潔阿姨會固定每周日按時來到你房間打掃,記住這個例子,我們后面還會用到~~~
13.2 內核中如何使用 dirty_writeback_interval 來控制 flusher 喚醒頻率
在磁盤中資料是以塊的形式存盤于扇區中的,前邊在介紹檔案讀寫的章節中,讀寫流程的最后都會從檔案系統層到塊設備驅動層,由塊設備驅動程式將資料寫入對應的磁盤塊中存盤,
記憶體中的檔案頁對應于磁盤中的一個資料塊,而這塊磁盤就是我們常說的塊設備,而每個塊設備在內核中對應一個 backing_dev_info 結構用于存盤相關資訊,其中最重要的資訊是 workqueue_struct *bdi_wq 用于快取塊設備上所有的回寫臟頁異步任務的佇列,
/* bdi_wq serves all asynchronous writeback tasks */
struct workqueue_struct *bdi_wq;
static int __init default_bdi_init(void)
{
int err;
// 創建 bdi_wq 佇列
bdi_wq = alloc_workqueue("writeback", WQ_MEM_RECLAIM | WQ_FREEZABLE |
WQ_UNBOUND | WQ_SYSFS, 0);
if (!bdi_wq)
return -ENOMEM;
// 初始化 backing_dev_info
err = bdi_init(&noop_backing_dev_info);
return err;
}
在系統啟動的時候,內核會呼叫 default_bdi_init 來創建 bdi_wq 佇列和初始化 backing_dev_info,
static int bdi_init(struct backing_dev_info *bdi)
{
int ret;
bdi->dev = NULL;
// 初始化 backing_dev_info 相關資訊
kref_init(&bdi->refcnt);
bdi->min_ratio = 0;
bdi->max_ratio = 100;
bdi->max_prop_frac = FPROP_FRAC_BASE;
INIT_LIST_HEAD(&bdi->bdi_list);
INIT_LIST_HEAD(&bdi->wb_list);
init_waitqueue_head(&bdi->wb_waitq);
// 這里會設定 flusher 執行緒的定時器 timer
ret = cgwb_bdi_init(bdi);
return ret;
}
在 bdi_init 中初始化 backing_dev_info 結構的相關資訊,并在 cgwb_bdi_init 中呼叫 wb_init 初始化回寫臟頁任務 bdi_writeback *wb,并創建一個 timer 用于定時啟動 flusher 執行緒,
static int wb_init(struct bdi_writeback *wb, struct backing_dev_info *bdi,
int blkcg_id, gfp_t gfp)
{
......... 初始化 bdi_writeback 結構該結構表示回寫臟頁任務相關資訊.....
// 創建 timer 定時執行 flusher 執行緒
INIT_DELAYED_WORK(&wb->dwork, wb_workfn);
......
}
#define __INIT_DELAYED_WORK(_work, _func, _tflags) \
do { \
INIT_WORK(&(_work)->work, (_func)); \
__setup_timer(&(_work)->timer, delayed_work_timer_fn, \
(unsigned long)(_work), \
bdi_writeback 有個成員變數 struct delayed_work dwork,bdi_writeback 就是把 delayed_work 結構掛到 bdi_wq 佇列上的,
而 wb_workfn 函式則是 flusher 執行緒要執行的回寫核心邏輯,全部封裝在 wb_workfn 函式中,
/*
* Handle writeback of dirty data for the device backed by this bdi. Also
* reschedules periodically and does kupdated style flushing.
*/
void wb_workfn(struct work_struct *work)
{
struct bdi_writeback *wb = container_of(to_delayed_work(work),
struct bdi_writeback, dwork);
long pages_written;
set_worker_desc("flush-%s", bdi_dev_name(wb->bdi));
current->flags |= PF_SWAPWRITE;
.......在回圈中不斷的回寫臟頁..........
// 如果 work-list 中還有回寫臟頁的任務,則立即喚醒flush執行緒
if (!list_empty(&wb->work_list))
wb_wakeup(wb);
// 如果回寫任務已經被全部執行完畢,但是記憶體中還有臟頁,則延時喚醒
else if (wb_has_dirty_io(wb) && dirty_writeback_interval)
wb_wakeup_delayed(wb);
current->flags &= ~PF_SWAPWRITE;
}
在 wb_workfn 中會不斷的回圈執行 work_list 中的臟頁回寫任務,當這些回寫任務執行完畢之后呼叫 wb_wakeup_delayed 延時喚醒 flusher執行緒,大家注意到這里的 dirty_writeback_interval 配置項終于出現了,后續會根據 dirty_writeback_interval 計算下次喚醒 flusher 執行緒的時機,
void wb_wakeup_delayed(struct bdi_writeback *wb)
{
unsigned long timeout;
// 使用 dirty_writeback_interval 配置設定下次喚醒時間
timeout = msecs_to_jiffies(dirty_writeback_interval * 10);
spin_lock_bh(&wb->work_lock);
if (test_bit(WB_registered, &wb->state))
queue_delayed_work(bdi_wq, &wb->dwork, timeout);
spin_unlock_bh(&wb->work_lock);
}
13.3 臟頁數量多到什么程度會主動喚醒 flusher 執行緒
這一節的內容中涉及到四個內核引數分別是:
drity_background_ratio :當臟頁數量在系統的可用記憶體 available 中占用的比例達到 drity_background_ratio 的配置值時,內核就會呼叫 wakeup_flusher_threads 來喚醒 flusher 執行緒異步回寫臟頁,默認值為:10,表示如果 page cache 中的臟頁數量達到系統可用記憶體的 10% 的話,就主動喚醒 flusher 執行緒去回寫臟頁到磁盤,
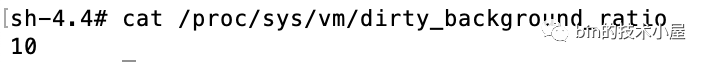
系統的可用記憶體 = 空閑記憶體 + 可回收記憶體,可以通過 free 命令的 available 項查看,

dirty_background_bytes :如果 page cache 中臟頁占用的記憶體用量絕對值達到指定的 dirty_background_bytes,內核就會呼叫 wakeup_flusher_threads 來喚醒 flusher 執行緒異步回寫臟頁,默認為:0,

dirty_background_bytes 的優先級大于 drity_background_ratio 的優先級,
dirty_ratio : dirty_background_* 相關的內核配置引數均是內核通過喚醒 flusher 執行緒來異步回寫臟頁,下面要介紹的 dirty_* 配置引數,均是由用戶行程同步回寫臟頁,表示記憶體中的臟頁太多了,用戶行程自己都看不下去了,不用等內核 flusher 執行緒喚醒,用戶行程自己主動去回寫臟頁到磁盤中,當臟頁占用系統可用記憶體的比例達到 dirty_ratio 配置的值時,用戶行程同步回寫臟頁,默認值為:20 ,
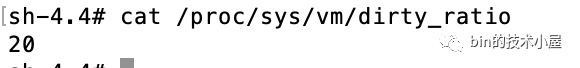
dirty_bytes :如果 page cache 中臟頁占用的記憶體用量絕對值達到指定的 dirty_bytes,用戶行程同步回寫臟頁,默認值為:0,
*_bytes 相關配置引數的優先級要大于 *_ratio 相關配置引數,
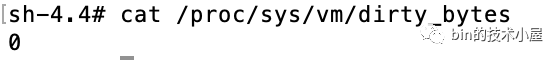
我們繼續使用上小節中保潔阿姨的例子說明:
之前你們已經約定好了,保潔阿姨會每周日固定(dirty_writeback_centisecs)來到你的房間打掃衛生(臟頁),但是你周三回家的時候,發現屋子里太臟了,是在是臟到一定程度了(drity_background_ratio ,dirty_background_bytes),你實在是看不去了,這時你就不會等這周日(dirty_writeback_centisecs)保潔阿姨過來才打掃,你會直接給阿姨打電話讓阿姨周三就來打掃一下(內核主動喚醒 flusher 執行緒異步回寫臟頁),
還有一種更極端的情況就是,你的房間已經臟到很夸張的程度了(dirty_ratio ,dirty_byte)連你自己都忍不了了,于是你都不用等保潔阿姨了(內核 flusher 回寫執行緒),你自己就乖乖的開始打掃房間衛生了,這就是用戶行程同步回寫臟頁,
13.4 內核如何主動喚醒 flusher 執行緒
通過 《12.5 balance_dirty_pages_ratelimited》小節的介紹,我們知道在 generic_perform_write 函式的最后一步會呼叫 balance_dirty_pages_ratelimited 來判斷是否要觸發臟頁回寫,
void balance_dirty_pages_ratelimited(struct address_space *mapping)
{
................省略............
if (unlikely(current->nr_dirtied >= ratelimit))
balance_dirty_pages(mapping, wb, current->nr_dirtied);
wb_put(wb);
}
這里會觸發 balance_dirty_pages 函式進行臟頁回寫,
static void balance_dirty_pages(struct address_space *mapping,
struct bdi_writeback *wb,
unsigned long pages_dirtied)
{
..................省略.............
for (;;) {
// 獲取系統可用記憶體
gdtc->avail = global_dirtyable_memory();
// 根據 *_ratio 或者 *_bytes 相關內核配置計算臟頁回寫觸發的閾值
domain_dirty_limits(gdtc);
.............省略..........
}
.............省略..........
在 balance_dirty_pages 中首先通過 global_dirtyable_memory() 獲取系統當前可用記憶體,在 domain_dirty_limits 函式中根據前邊我們介紹的 *_ratio 或者 *_bytes 相關內核配置計算臟頁回寫觸發的閾值,
static void domain_dirty_limits(struct dirty_throttle_control *dtc)
{
// 獲取可用記憶體
const unsigned long available_memory = dtc->avail;
// 封裝觸發臟頁回寫相關閾值資訊
struct dirty_throttle_control *gdtc = mdtc_gdtc(dtc);
// 這里就是內核引數 dirty_bytes 指定的值
unsigned long bytes = vm_dirty_bytes;
// 內核引數 dirty_background_bytes 指定的值
unsigned long bg_bytes = dirty_background_bytes;
// 將內核引數 dirty_ratio 指定的值轉換為以 頁 為單位
unsigned long ratio = (vm_dirty_ratio * PAGE_SIZE) / 100;
// 將內核引數 dirty_background_ratio 指定的值轉換為以 頁 為單位
unsigned long bg_ratio = (dirty_background_ratio * PAGE_SIZE) / 100;
// 行程同步回寫 dirty_* 相關閾值
unsigned long thresh;
// 內核異步回寫 direty_background_* 相關閾值
unsigned long bg_thresh;
struct task_struct *tsk;
if (gdtc) {
// 系統可用記憶體
unsigned long global_avail = gdtc->avail;
// 這里可以看出 bytes 相關配置的優先級大于 ratio 相關配置的優先級
if (bytes)
// 將 bytes 相關的配置轉換為以頁為單位的記憶體占用比例ratio
ratio = min(DIV_ROUND_UP(bytes, global_avail),
PAGE_SIZE);
// 設定 dirty_backgound_* 相關閾值
if (bg_bytes)
bg_ratio = min(DIV_ROUND_UP(bg_bytes, global_avail),
PAGE_SIZE);
bytes = bg_bytes = 0;
}
// 這里可以看出 bytes 相關配置的優先級大于 ratio 相關配置的優先級
if (bytes)
// 將 bytes 相關的配置轉換為以頁為單位的記憶體占用比例ratio
thresh = DIV_ROUND_UP(bytes, PAGE_SIZE);
else
thresh = (ratio * available_memory) / PAGE_SIZE;
// 設定 dirty_background_* 相關閾值
if (bg_bytes)
// 將 dirty_background_bytes 相關的配置轉換為以頁為單位的記憶體占用比例ratio
bg_thresh = DIV_ROUND_UP(bg_bytes, PAGE_SIZE);
else
bg_thresh = (bg_ratio * available_memory) / PAGE_SIZE;
// 保證異步回寫 backgound 的相關閾值要比同步回寫的閾值要低
if (bg_thresh >= thresh)
bg_thresh = thresh / 2;
dtc->thresh = thresh;
dtc->bg_thresh = bg_thresh;
..........省略..........
}
domain_dirty_limits 函式會分別計算用戶行程同步回寫臟頁的相關閾值 thresh 以及內核異步回寫臟頁的相關閾值 bg_thresh,邏輯比較好懂,筆者將每一步的注釋已經為大家標注出來了,這里只列出幾個關鍵核心點:
-
從原始碼中的 if (bytes) {....} else {.....} 分支以及 if (bg_bytes) {....} else {.....} 我們可以看出內核配置 *_bytes 相關的優先級會高于 *_ratio 相關配置的優先級,
-
*_bytes 相關配置我們只會指定臟頁占用記憶體的 bytes 閾值,但在內核實作中會將其轉換為 頁 為單位,(每頁 4K 大小),
-
內核中對于臟頁回寫閾值的判斷是通過 ratio 比例來進行判斷的,
-
內核異步回寫的閾值要小于行程同步回寫的閾值,如果超過,那么內核異步回寫的閾值將會被設定為行程通過回寫的一半,
static void balance_dirty_pages(struct address_space *mapping,
struct bdi_writeback *wb,
unsigned long pages_dirtied)
{
..................省略.............
for (;;) {
// 獲取系統可用記憶體
gdtc->avail = global_dirtyable_memory();
// 根據 *_ratio 或者 *_bytes 相關內核配置計算 臟頁回寫觸發的閾值
domain_dirty_limits(gdtc);
.............省略..........
}
// 根據行程同步回寫閾值判斷是否需要行程直接同步回寫臟頁
if (writeback_in_progress(wb))
return
// 根據內核異步回寫閾值判斷是否需要喚醒flusher異步回寫臟頁
if (nr_reclaimable > gdtc->bg_thresh)
wb_start_background_writeback(wb);
如果是異步回寫,內核則喚醒 flusher 執行緒開始異步回寫臟頁,直到臟頁數量低于閾值或者全部回寫到磁盤,
void wb_start_background_writeback(struct bdi_writeback *wb)
{
/*
* We just wake up the flusher thread. It will perform background
* writeback as soon as there is no other work to do.
*/
trace_writeback_wake_background(wb);
wb_wakeup(wb);
}
13.5 臟頁到底在記憶體中能駐留多久
內核為了避免 page cache 中的臟頁在記憶體中長久的停留,所以會給臟頁在記憶體中的駐留時間設定一定的期限,這個期限可由前邊提到的 dirty_expire_centisecs 內核引數配置,默認為:3000,單位為:0.01 s,

也就是說在默認配置下,臟頁在記憶體中的駐留時間為 30 s,超過 30 s 之后,flusher 執行緒將會在下次被喚醒的時候將這些臟頁回寫到磁盤中,
這些過期的臟頁最侄訓在 flusher 執行緒下一次被喚醒時候被 flusher 執行緒回寫到磁盤中,而前邊我們也多次提到過 flusher 執行緒執行邏輯全部封裝在 wb_workfn 函式中,接下來的呼叫鏈為 wb_workfn->wb_do_writeback->wb_writeback,在 wb_writeback 中會判斷根據 dirty_expire_interval 判斷哪些是過期的臟頁,
/*
* Explicit flushing or periodic writeback of "old" data.
*
* Define "old": the first time one of an inode's pages is dirtied, we mark the
* dirtying-time in the inode's address_space. So this periodic writeback code
* just walks the superblock inode list, writing back any inodes which are
* older than a specific point in time.
*
* Try to run once per dirty_writeback_interval. But if a writeback event
* takes longer than a dirty_writeback_interval interval, then leave a
* one-second gap.
*
* older_than_this takes precedence over nr_to_write. So we'll only write back
* all dirty pages if they are all attached to "old" mappings.
*/
static long wb_writeback(struct bdi_writeback *wb,
struct wb_writeback_work *work)
{
........省略.......
work->older_than_this = &oldest_jif;
for (;;) {
........省略.......
if (work->for_kupdate) {
oldest_jif = jiffies -
msecs_to_jiffies(dirty_expire_interval * 10);
} else if (work->for_background)
oldest_jif = jiffies;
}
........省略.......
}
13.6 臟頁回寫引數的相關配置方式
前面的幾個小節筆者結合內核原始碼實作為大家介紹了影響內核回寫臟頁時機的六個引數,
內核越頻繁的觸發臟頁回寫,資料的安全性就越高,但是同時系統性能會消耗很大,所以我們在日常作業中需要結合資料的安全性和 IO 性能綜合考慮這六個內核引數的配置,
本小節筆者就為大家介紹一下配置這些內核引數的方式,前面的小節中也提到過,內核提供的這些引數存在于 proc/sys/vm 目錄下,
比如我們直接將要配置的具體數值寫入對應的組態檔中:
echo "value" > /proc/sys/vm/dirty_background_ratio
我們還可以使用 sysctl 來對這些內核引數進行配置:
sysctl -w variable=value
sysctl 命令中定義的這些變數 variable 全部定義在內核 kernel/sysctl.c 源檔案中,
-
其中 .procname 定義的就是 sysctl 命令中指定的配置變數名字,
-
.data 定義的是內核原始碼中參考的變數名字,這在前邊我們介紹內核代碼的時候介紹過了,比如配置引數 dirty_writeback_centisecs 在內核原始碼中的變數名為 dirty_writeback_interval , dirty_ratio 在內核中的變數名為 vm_dirty_ratio,
static struct ctl_table vm_table[] = {
........省略........
{
.procname = "dirty_background_ratio",
.data = https://www.cnblogs.com/binlovetech/archive/2022/09/06/&dirty_background_ratio,
.maxlen = sizeof(dirty_background_ratio),
.mode = 0644,
.proc_handler = dirty_background_ratio_handler,
.extra1 = SYSCTL_ZERO,
.extra2 = SYSCTL_ONE_HUNDRED,
},
{
.procname ="dirty_background_bytes",
.data = https://www.cnblogs.com/binlovetech/archive/2022/09/06/&dirty_background_bytes,
.maxlen = sizeof(dirty_background_bytes),
.mode = 0644,
.proc_handler = dirty_background_bytes_handler,
.extra1 = SYSCTL_LONG_ONE,
},
{
.procname ="dirty_ratio",
.data = https://www.cnblogs.com/binlovetech/archive/2022/09/06/&vm_dirty_ratio,
.maxlen = sizeof(vm_dirty_ratio),
.mode = 0644,
.proc_handler = dirty_ratio_handler,
.extra1 = SYSCTL_ZERO,
.extra2 = SYSCTL_ONE_HUNDRED,
},
{
.procname ="dirty_bytes",
.data = https://www.cnblogs.com/binlovetech/archive/2022/09/06/&vm_dirty_bytes,
.maxlen = sizeof(vm_dirty_bytes),
.mode = 0644,
.proc_handler = dirty_bytes_handler,
.extra1 = (void *)&dirty_bytes_min,
},
{
.procname ="dirty_writeback_centisecs",
.data = https://www.cnblogs.com/binlovetech/archive/2022/09/06/&dirty_writeback_interval,
.maxlen = sizeof(dirty_writeback_interval),
.mode = 0644,
.proc_handler = dirty_writeback_centisecs_handler,
},
{
.procname ="dirty_expire_centisecs",
.data = https://www.cnblogs.com/binlovetech/archive/2022/09/06/&dirty_expire_interval,
.maxlen = sizeof(dirty_expire_interval),
.mode = 0644,
.proc_handler = proc_dointvec_minmax,
.extra1 = SYSCTL_ZERO,
}
........省略........
}
而前邊介紹的這兩種配置方式全部是臨時的,我們可以通過編輯 /etc/sysctl.conf 檔案來永久的修改內核相關的配置,
我們也可以在目錄
/etc/sysctl.d/下創建自定義的組態檔,
vi /etc/sysctl.conf
在 /etc/sysctl.conf 檔案中直接以 variable = value 的形式添加到檔案的末尾,
最后呼叫 sysctl -p /etc/sysctl.conf 使 /etc/sysctl.conf 組態檔中新添加的那些配置生效,
總結

本文筆者帶大家從 Linux 內核的角度詳細決議了 JDK NIO 檔案讀寫在 Buffered IO 以及 Direct IO 這兩種模式下的內核原始碼實作,探秘了檔案讀寫的本質,并對比了 Buffered IO 和 Direct IO 的不同之處以及各自的適用場景,
在這個程序中又詳細地介紹了與 Buffered IO 密切相關的檔案頁高速快取 page cache 在內核中的實作以及相關操作,
最后我們詳細介紹了影響檔案 IO 的兩個關鍵步驟:檔案預讀和臟頁回寫的詳細內核原始碼實作,以及內核中影響臟頁回寫時機的 6 個關鍵內核配置引數相關的實作及應用,
-
dirty_background_bytes
-
dirty_background_ratio
-
dirty_bytes
-
dirty_ratio
-
dirty_expire_centisecs
-
dirty_writeback_centisecs
以及關于內核引數的三種配置方式:
-
通過直接修改
proc/sys/vm目錄下的相關引陣列態檔, -
使用 sysctl 命令來對相關引數進行修改,
-
通過編輯
/etc/sysctl.conf檔案來永久的修改內核相關配置,
好了,本文的內容到這里就結束了,能夠看到這里的大家一定是個狠人兒,但是辛苦的付出總會有所識訓,恭喜大家現在已經徹底打通了 Linux 檔案操作相關知識的系統脈絡,感謝大家的耐心觀看,我們下篇文章見~~~
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/504603.html
標籤:其他