寫在本文開始之前....
從本文開始我們就正式開啟了 Linux 內核記憶體管理子系統原始碼決議系列,筆者還是會秉承之前系列文章的風格,采用一步一圖的方式先是詳細介紹相關原理,在保證大家清晰理解原理的基礎上,我們再來一步一步的決議相關內核原始碼的實作,有了原始碼的輔證,這樣大家看得也安心,理解起來也放心,最起碼可以證明筆者沒有胡編亂造騙大家,哈哈~~
記憶體管理子系統可謂是 Linux 內核眾多子系統中最為復雜最為龐大的一個,其中包含了眾多繁雜的概念和原理,通過記憶體管理這條主線我們把可以把作業系統的眾多核心系統給拎出來,比如:行程管理子系統,網路子系統,檔案子系統等,
由于記憶體管理子系統過于復雜龐大,其中涉及到的眾多繁雜的概念又是一環套一環,層層遞進,如何把這些繁雜的概念具有層次感地,并且清晰地,給大家梳理呈現出來真是一件比較有難度的事情,因此關于這個問題,筆者在動筆寫這個記憶體管理原始碼決議系列之前也是思考了很久,
萬事開頭難,那么到底什么內容適合作為這個系列的開篇呢 ?筆者還是覺得從大家日常開發作業中接觸最多最為熟悉的部分開始比較好,比如:在我們日常開發中創建的類,呼叫的函式,在函式中定義的區域變數以及 new 出來的資料容器(Map,List,Set .....等)都需要存盤在物理記憶體中的某個角落,
而我們在程式中撰寫業務邏輯代碼的時候,往往需要參考這些創建出來的資料結構,并通過這些參考對相關資料結構進行業務處理,
當程式運行起來之后就變成了行程,而這些業務資料結構的參考在行程的視角里全都都是虛擬記憶體地址,因為行程無論是在用戶態還是在內核態能夠看到的都是虛擬記憶體空間,物理記憶體空間被作業系統所屏蔽行程是看不到的,
行程通過虛擬記憶體地址訪問這些資料結構的時候,虛擬記憶體地址會在記憶體管理子系統中被轉換成物理記憶體地址,通過物理記憶體地址就可以訪問到真正存盤這些資料結構的物理記憶體了,隨后就可以對這塊物理記憶體進行各種業務操作,從而完成業務邏輯,
-
那么到底什么是虛擬記憶體地址 ?
-
Linux 內核為啥要引入虛擬記憶體而不直接使用物理記憶體 ?
-
虛擬記憶體空間到底長啥樣?
-
內核如何管理虛擬記憶體?
-
什么又是物理記憶體地址 ?如何訪問物理記憶體?
本文筆者就來為大家詳細一一解答上述幾個問題,讓我們馬上開始吧~~~~
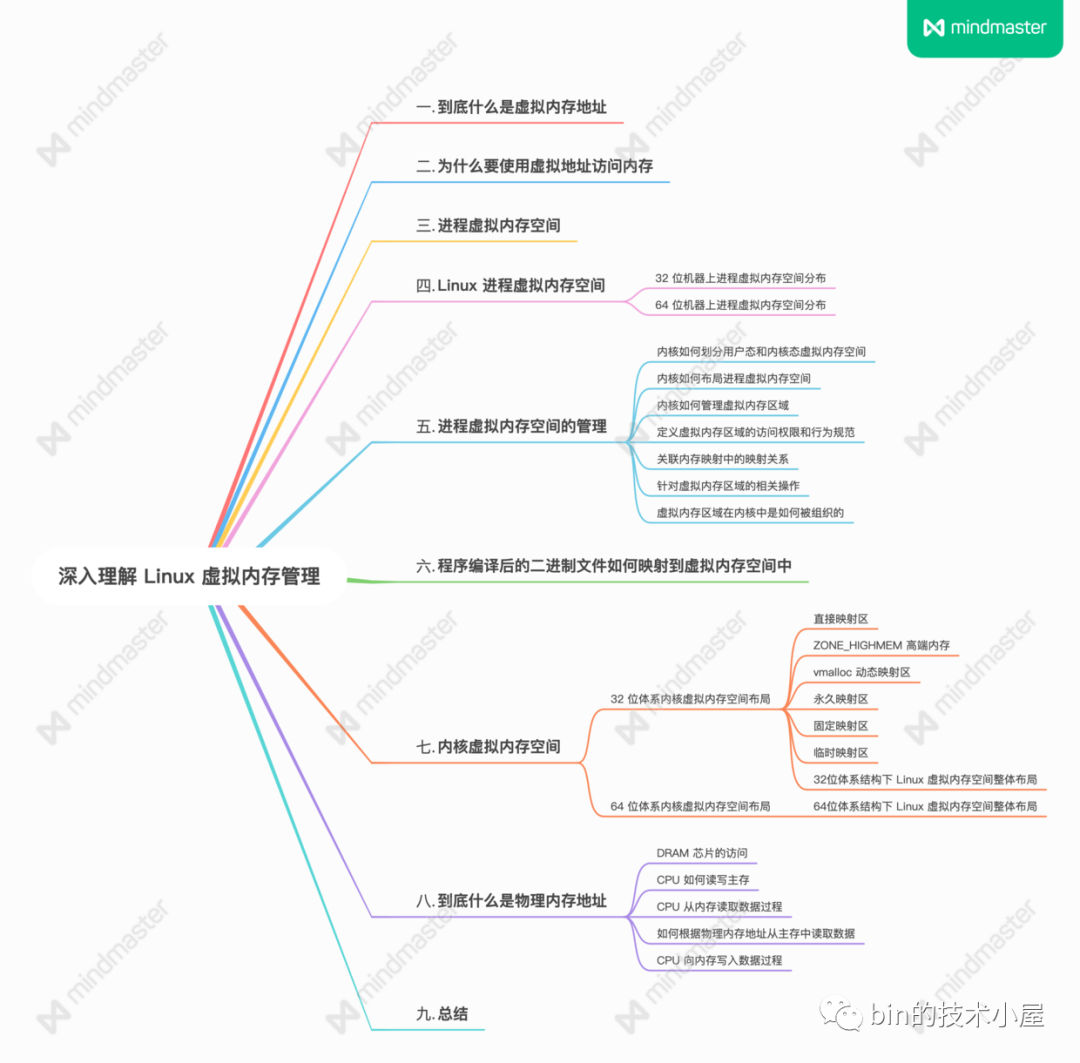
1. 到底什么是虛擬記憶體地址
首先人們提出地址這個概念的目的就是用來方便定位現實世界中某一個具體事物的真實地理位置,它是一種用于定位的概念模型,
舉一個生活中的例子,比如大家在日常生活中給親朋好友郵寄一些本地特產時,都會填寫收件人地址以及寄件人地址,以及在日常網上購物時,都會在相應電商 APP 中填寫自己的識訓地址,
隨后快遞小哥就會根據我們填寫的識訓地址找到我們的真實住所,將我們網購的商品送達到我們的手里,
識訓地址是用來定位我們在現實世界中真實住所地理位置的,而現實世界中我們所在的城市,街道,小區,房屋都是一磚一瓦,一草一木真實存在的,但識訓地址這個概念模型在現實世界中并不真實存在,它只是人們提出的一個虛擬概念,通過識訓地址這個虛擬概念將它和現實世界真實存在的城市,小區,街道的地理位置一一映射起來,這樣我們就可以通過這個虛擬概念來找到現實世界中的具體地理位置,
綜上所述,識訓地址是一個虛擬地址,它是人為定義的,而我們的城市,小區,街道是真實存在的,他們的地理位置就是物理地址,
比如現在的廣東省深圳市在過去叫寶安縣,河北省的石家莊過去叫常山,安徽省的合肥過去叫瀘州,不管是常山也好,石家莊也好,又或是合肥也好,瀘州也罷,這些都是人為定義的名字而已,但是地方還是那個地方,它所在的地理位置是不變的,也就說虛擬地址可以人為的變來變去,但是物理地址永遠是不變的,
現在讓我們把視角在切換到計算機的世界,在計算機的世界里記憶體地址用來定義資料在記憶體中的存盤位置的,記憶體地址也分為虛擬地址和物理地址,而虛擬地址也是人為設計的一個概念,類比我們現實世界中的識訓地址,而物理地址則是資料在物理記憶體中的真實存盤位置,類比現實世界中的城市,街道,小區的真實地理位置,
說了這么多,那么到底虛擬記憶體地址長什么樣子呢?
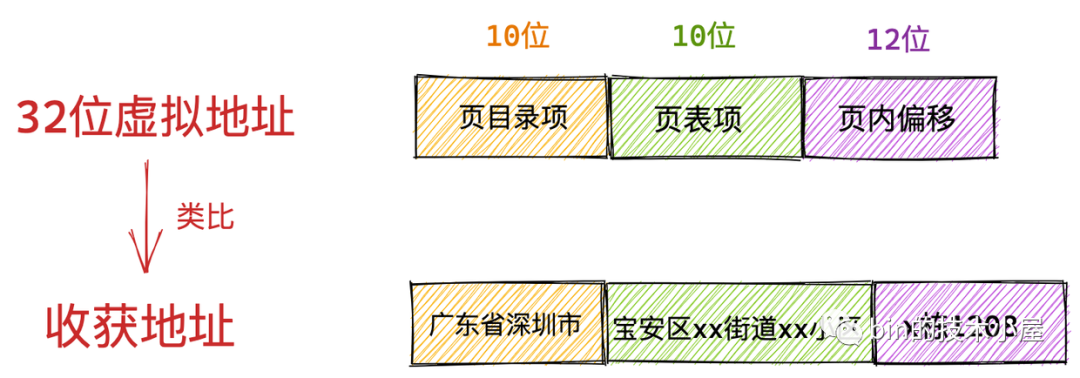
我們還是以日常生活中的識訓地址為例做出類比,我們都很熟悉識訓地址的格式:xx省xx市xx區xx街道xx小區xx室,它是按照地區層次遞進的,同樣,在計算機世界中的虛擬記憶體地址也有這樣的遞進關系,
這里我們以 Intel Core i7 處理器為例,64 位虛擬地址的格式為:全域頁目錄項(9位)+ 上層頁目錄項(9位)+ 中間頁目錄項(9位)+ 頁內偏移(12位),共 48 位組成的虛擬記憶體地址,
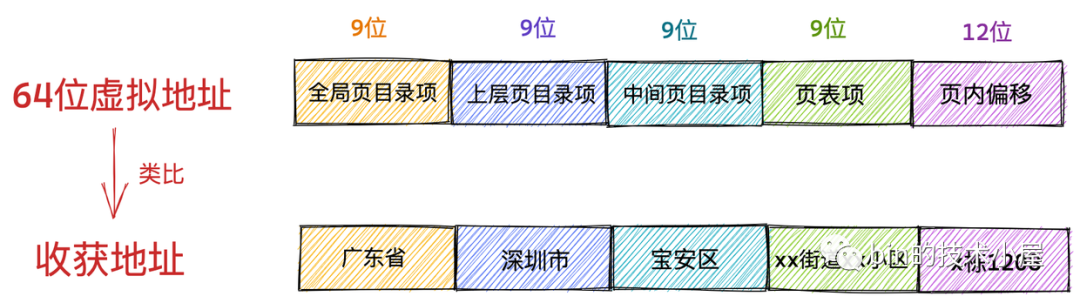
虛擬記憶體地址中的全域頁目錄項就類比我們日常生活中識訓地址里的省,上層頁目錄項就類比市,中間層頁目錄項類比區縣,頁表項類比街道小區,頁內偏移類比我們所在的樓棟和幾層幾號,
這里大家只需要大體明白虛擬記憶體地址到底長什么樣子,它的格式是什么,能夠和日常生活中的識訓地址對比理解起來就可以了,至于頁目錄項,頁表項以及頁內偏移這些計算機世界中的概念,大家暫時先不用管,后續文章中筆者會慢慢給大家解釋清楚,
32 位虛擬地址的格式為:頁目錄項(10位)+ 頁表項(10位) + 頁內偏移(12位),共 32 位組成的虛擬記憶體地址,
行程虛擬記憶體空間中的每一個位元組都有與其對應的虛擬記憶體地址,一個虛擬記憶體地址表示行程虛擬記憶體空間中的一個特定的位元組,
2. 為什么要使用虛擬地址訪問記憶體
經過第一小節的介紹,我們現在明白了計算機世界中的虛擬記憶體地址的含義及其展現形式,那么大家可能會問了,既然物理記憶體地址可以直接定位到資料在記憶體中的存盤位置,那為什么我們不直接使用物理記憶體地址去訪問記憶體而是選擇用虛擬記憶體地址去訪問記憶體呢?
在回答大家的這個疑問之前,讓我們先來看下,如果在程式中直接使用物理記憶體地址會發生什么情況?
假設現在沒有虛擬記憶體地址,我們在程式中對記憶體的操作全都都是使用物理記憶體地址,在這種情況下,程式員就需要精確的知道每一個變數在記憶體中的具體位置,我們需要手動對物理記憶體進行布局,明確哪些資料存盤在記憶體的哪些位置,除此之外我們還需要考慮為每個行程究竟要分配多少記憶體?記憶體緊張的時候該怎么辦?如何避免行程與行程之間的地址沖突?等等一系列復雜且瑣碎的細節,
如果我們在單行程系統中比如嵌入式設備上開發應用程式,系統中只有一個行程,這單個行程獨享所有的物理資源包括記憶體資源,在這種情況下,上述提到的這些直接使用物理記憶體的問題可能還好處理一些,但是仍然具有很高的開發門檻,
然而在現代作業系統中往往支持多個行程,需要處理多行程之間的協同問題,在多行程系統中直接使用物理記憶體地址操作記憶體所帶來的上述問題就變得非常復雜了,
這里筆者為大家舉一個簡單的例子來說明在多行程系統中直接使用物理記憶體地址的復雜性,
比如我們現在有這樣一個簡單的 Java 程式,
public static void main(String[] args) throws Exception {
string i = args[0];
..........
}
在程式代碼相同的情況下,我們用這份代碼同時啟動三個 JVM 行程,我們暫時將行程依次命名為 a , b , c ,
這三個行程用到的代碼是一樣的,都是我們提前寫好的,可以被多次運行,由于我們是直接操作物理記憶體地址,假設變數 i 保存在 0x354 這個物理地址上,這三個行程運行起來之后,同時操作這個 0x354 物理地址,這樣這個變數 i 的值不就混亂了嗎? 三個行程就會出現變數的地址沖突,
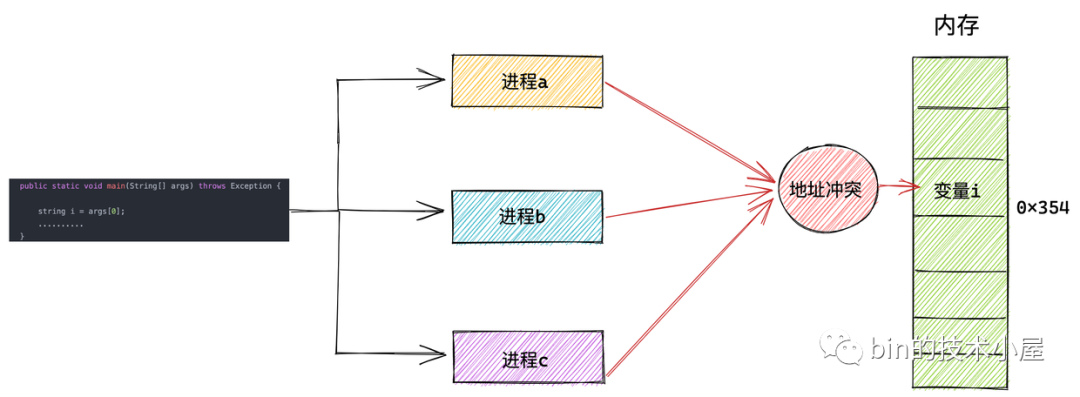
所以在直接操作物理記憶體的情況下,我們需要知道每一個變數的位置都被安排在了哪里,而且還要注意和多個行程同時運行的時候,不能共用同一個地址,否則就會造成地址沖突,
現實中一個程式會有很多的變數和函式,這樣一來我們給它們都需要計算一個合理的位置,還不能與其他行程沖突,這就很復雜了,
那么我們該如何解決這個問題呢?程式的區域性原理再一次救了我們~~
程式區域性原理表現為:時間區域性和空間區域性,時間區域性是指如果程式中的某條指令一旦執行,則不久之后該指令可能再次被執行;如果某塊資料被訪問,則不久之后該資料可能再次被訪問,空間區域性是指一旦程式訪問了某個存盤單元,則不久之后,其附近的存盤單元也將被訪問,
從程式區域性原理的描述中我們可以得出這樣一個結論:行程在運行之后,對于記憶體的訪問不會一下子就要訪問全部的記憶體,相反行程對于記憶體的訪問會表現出明顯的傾向性,更加傾向于訪問最近訪問過的資料以及熱點資料附近的資料,
根據這個結論我們就清楚了,無論一個行程實際可以占用的記憶體資源有多大,根據程式區域性原理,在某一段時間內,行程真正需要的物理記憶體其實是很少的一部分,我們只需要為每個行程分配很少的物理記憶體就可以保證行程的正常執行運轉,
而虛擬記憶體的引入正是要解決上述的問題,虛擬記憶體引入之后,行程的視角就會變得非常開闊,每個行程都擁有自己獨立的虛擬地址空間,行程與行程之間的虛擬記憶體地址空間是相互隔離,互不干擾的,每個行程都認為自己獨占所有記憶體空間,自己想干什么就干什么,

系統上還運行了哪些行程和我沒有任何關系,這樣一來我們就可以將多行程之間協同的相關復雜細節統統交給內核中的記憶體管理模塊來處理,極大地解放了程式員的心智負擔,這一切都是因為虛擬記憶體能夠提供記憶體地址空間的隔離,極大地擴展了可用空間,
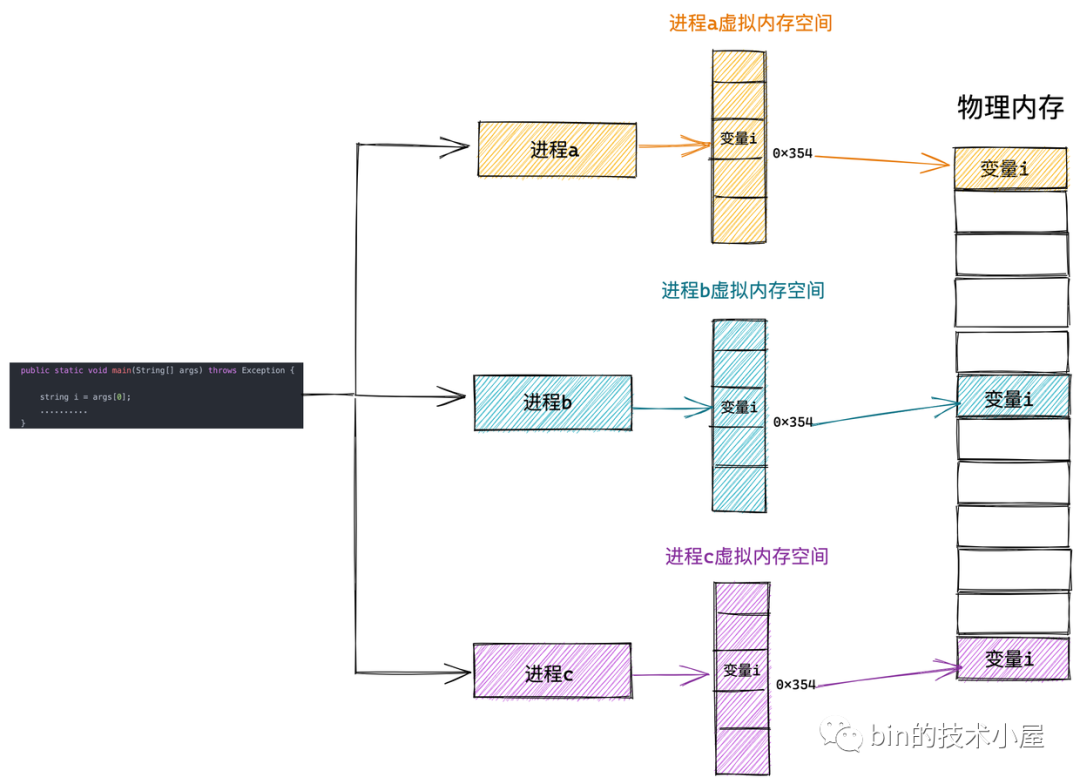
這樣行程就以為自己獨占了整個記憶體空間資源,給行程產生了所有記憶體資源都屬于它自己的幻覺,這其實是 CPU 和作業系統使用的一個障眼法罷了,任何一個虛擬記憶體里所存盤的資料,本質上還是保存在真實的物理記憶體里的,只不過內核幫我們做了虛擬記憶體到物理記憶體的這一層映射,將不同行程的虛擬地址和不同記憶體的物理地址映射起來,
當 CPU 訪問行程的虛擬地址時,經過地址翻譯硬體將虛擬地址轉換成不同的物理地址,這樣不同的行程運行的時候,雖然操作的是同一虛擬地址,但其實背后寫入的是不同的物理地址,這樣就不會沖突了,
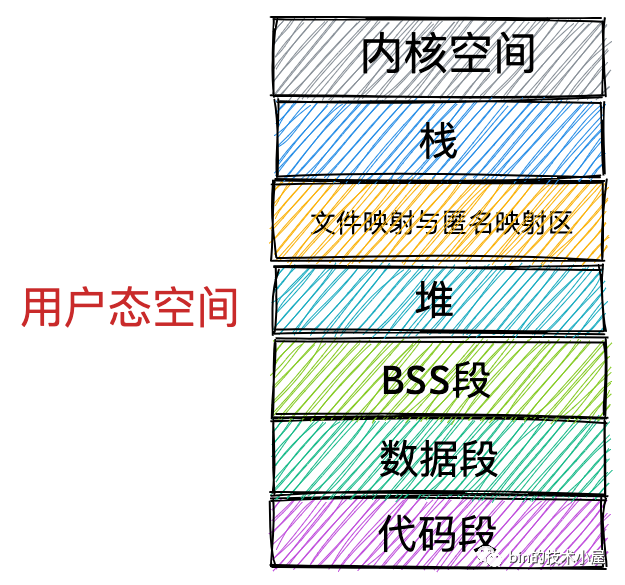
3. 行程虛擬記憶體空間
上小節中,我們介紹了為了防止多行程運行時造成的記憶體地址沖突,內核引入了虛擬記憶體地址,為每個行程提供了一個獨立的虛擬記憶體空間,使得行程以為自己獨占全部記憶體資源,
那么這個行程獨占的虛擬記憶體空間到底是什么樣子呢?在本小節中,筆者就為大家揭開這層神秘的面紗~~~
在本小節內容開始之前,我們先想象一下,如果我們是內核的設計人員,我們該從哪些方面來規劃行程的虛擬記憶體空間呢?
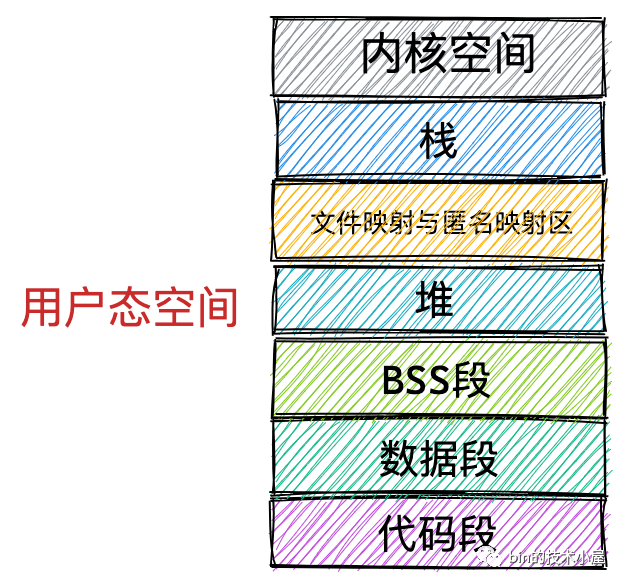
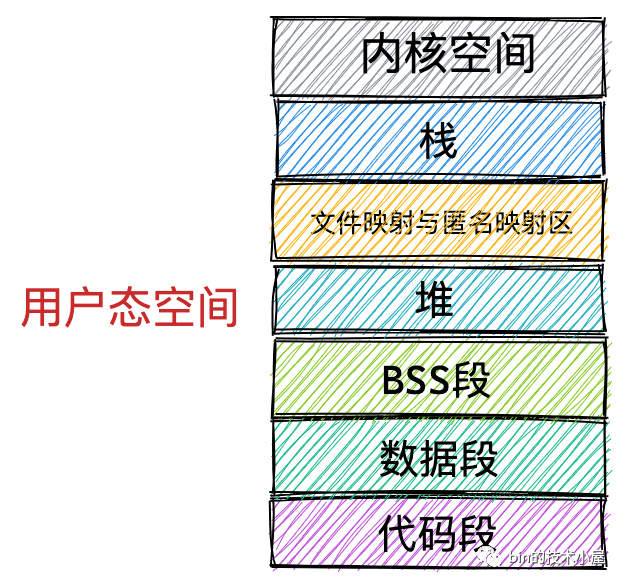
本小節我們只討論行程用戶態虛擬記憶體空間的布局,我們先把內核態的虛擬記憶體空間當做一個黑盒來看待,在后面的小節中筆者再來詳細介紹內核態相關內容,
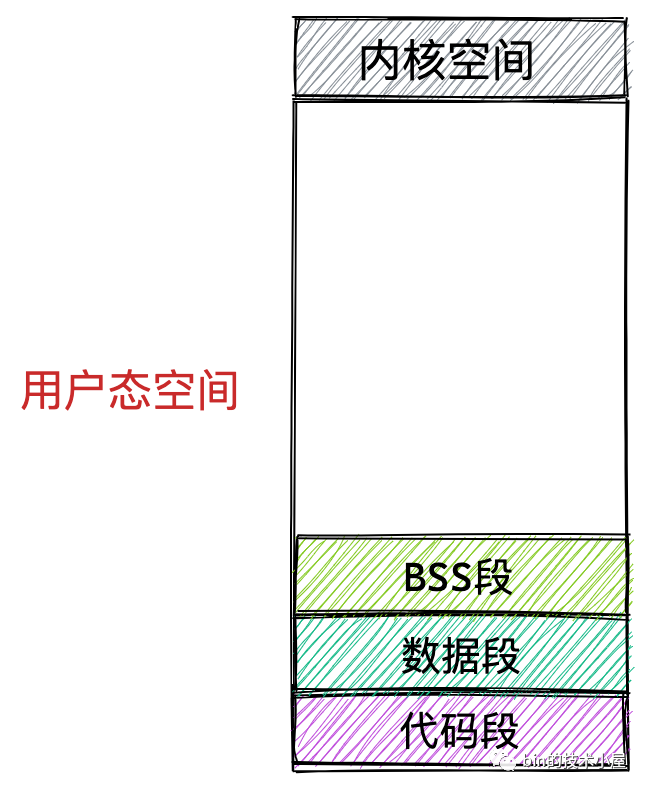
首先我們會想到的是一個行程運行起來是為了執行我們交代給行程的作業,執行這些作業的步驟我們通程序式代碼事先撰寫好,然后編譯成二進制檔案存放在磁盤中,CPU 會執行二進制檔案中的機器碼來驅動行程的運行,所以在行程運行之前,這些存放在二進制檔案中的機器碼需要被加載進記憶體中,而用于存放這些機器碼的虛擬記憶體空間叫做代碼段,
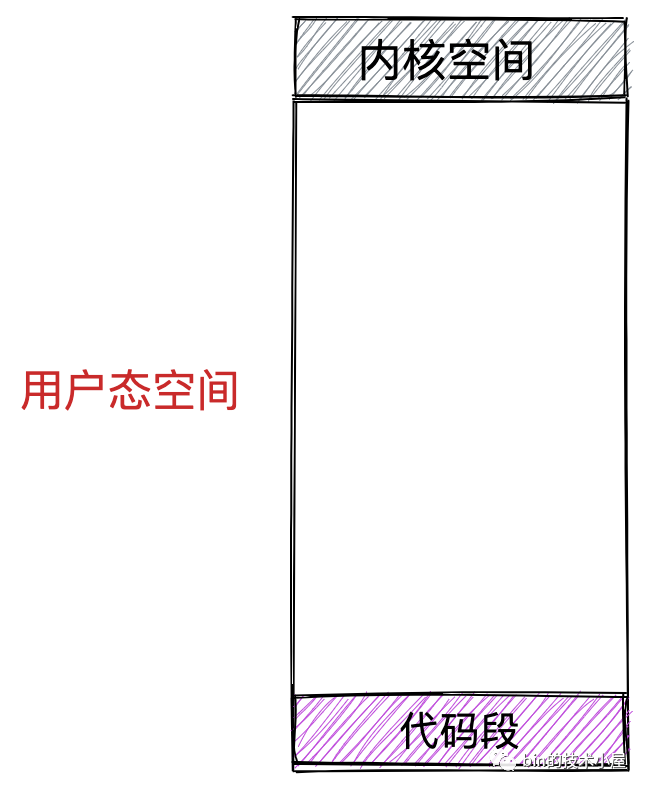
在程式運行起來之后,總要操作變數吧,在程式代碼中我們通常會定義大量的全域變數和靜態變數,這些全域變數在程式編譯之后也會存盤在二進制檔案中,在程式運行之前,這些全域變數也需要被加載進記憶體中供程式訪問,所以在虛擬記憶體空間中也需要一段區域來存盤這些全域變數,
-
那些在代碼中被我們指定了初始值的全域變數和靜態變數在虛擬記憶體空間中的存盤區域我們叫做資料段,
-
那些沒有指定初始值的全域變數和靜態變數在虛擬記憶體空間中的存盤區域我們叫做 BSS 段,這些未初始化的全域變數被加載進記憶體之后會被初始化為 0 值,
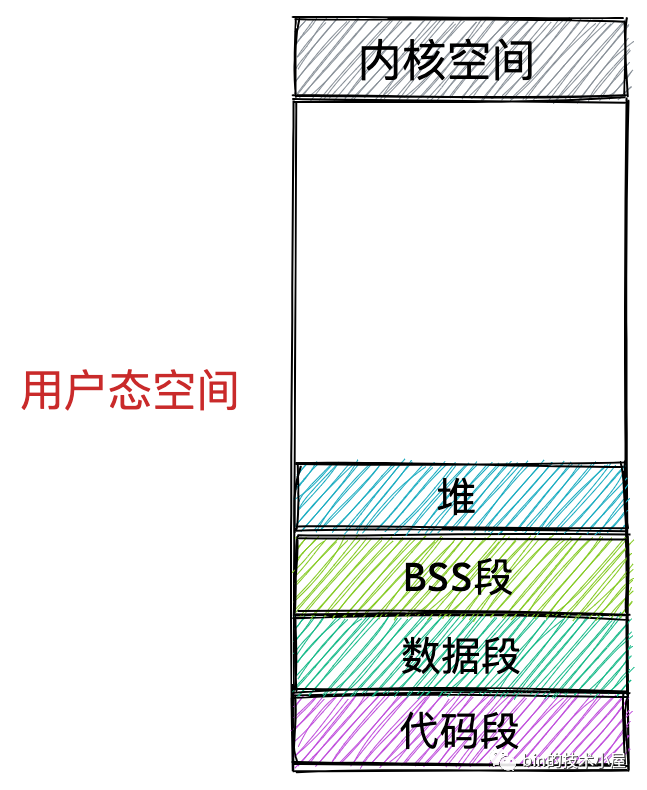
上面介紹的這些全域變數和靜態變數都是在編譯期間就確定的,但是我們程式在運行期間往往需要動態的申請記憶體,所以在虛擬記憶體空間中也需要一塊區域來存放這些動態申請的記憶體,這塊區域就叫做堆,注意這里的堆指的是 OS 堆并不是 JVM 中的堆,
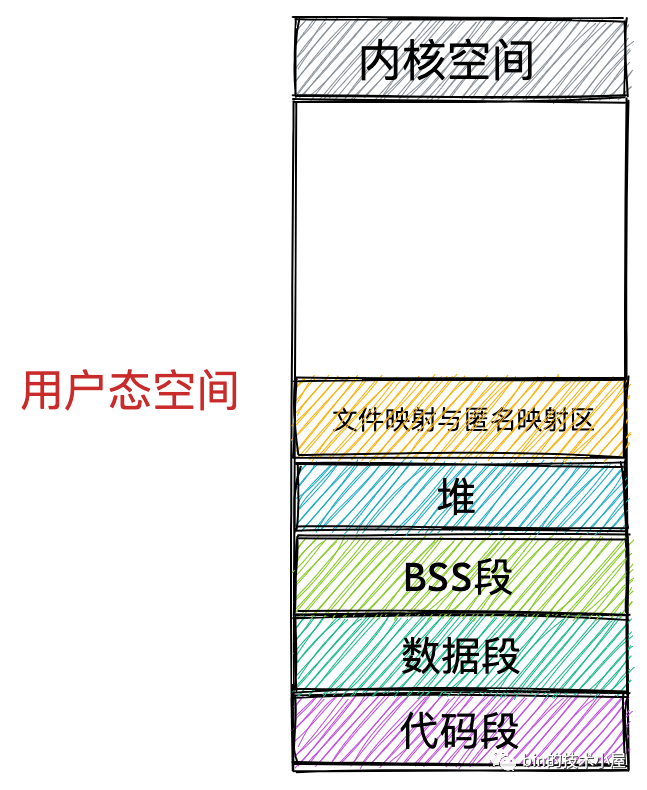
除此之外,我們的程式在運行程序中還需要依賴元件,這些元件以 .so 檔案的形式存放在磁盤中,比如 C 程式中的 glibc,里邊對系統呼叫進行了封裝,glibc 庫里提供的用于動態申請堆記憶體的 malloc 函式就是對系統呼叫 sbrk 和 mmap 的封裝,這些元件也有自己的對應的代碼段,資料段,BSS 段,也需要一起被加載進記憶體中,
還有用于記憶體檔案映射的系統呼叫 mmap,會將檔案與記憶體進行映射,那么映射的這塊記憶體(虛擬記憶體)也需要在虛擬地址空間中有一塊區域存盤,
這些元件中的代碼段,資料段,BSS 段,以及通過 mmap 系統呼叫映射的共享記憶體區,在虛擬記憶體空間的存盤區域叫做檔案映射與匿名映射區,
最后我們在程式運行的時候總該要呼叫各種函式吧,那么呼叫函式程序中使用到的區域變數和函式引數也需要一塊記憶體區域來保存,這一塊區域在虛擬記憶體空間中叫做堆疊,
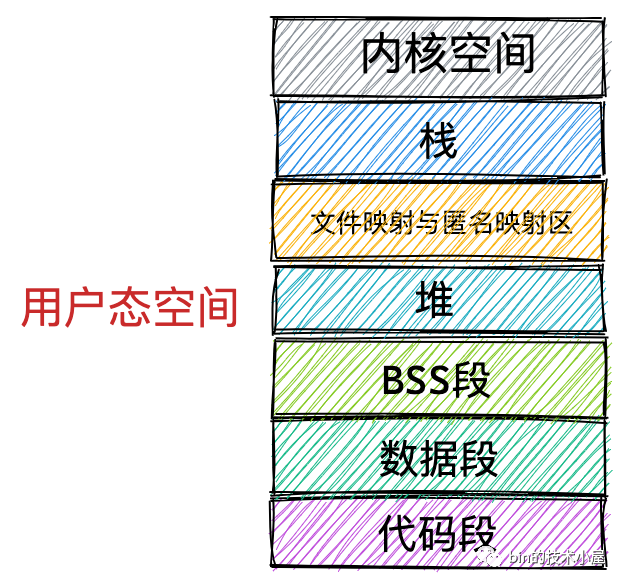
現在行程的虛擬記憶體空間所包含的主要區域,筆者就為大家介紹完了,我們看到內核根據行程運行的程序中所需要不同種類的資料而為其開辟了對應的地址空間,分別為:
-
用于存放行程程式二進制檔案中的機器指令的代碼段
-
用于存放程式二進制檔案中定義的全域變數和靜態變數的資料段和 BSS 段,
-
用于在程式運行程序中動態申請記憶體的堆,
-
用于存放元件以及記憶體映射區域的檔案映射與匿名映射區,
-
用于存放函式呼叫程序中的區域變數和函式引數的堆疊,
以上就是我們通過一個程式在運行程序中所需要的資料所規劃出的虛擬記憶體空間的分布,這些只是一個大概的規劃,那么在真實的 Linux 系統中,行程的虛擬記憶體空間的具體規劃又是如何的呢?我們接著往下看~~
4. Linux 行程虛擬記憶體空間
在上小節中我們介紹了行程虛擬記憶體空間中各個記憶體區域的一個大概分布,在此基礎之上,本小節筆者就帶大家分別從 32 位 和 64 位機器上看下在 Linux 系統中行程虛擬記憶體空間的真實分布情況,
4.1 32 位機器上行程虛擬記憶體空間分布
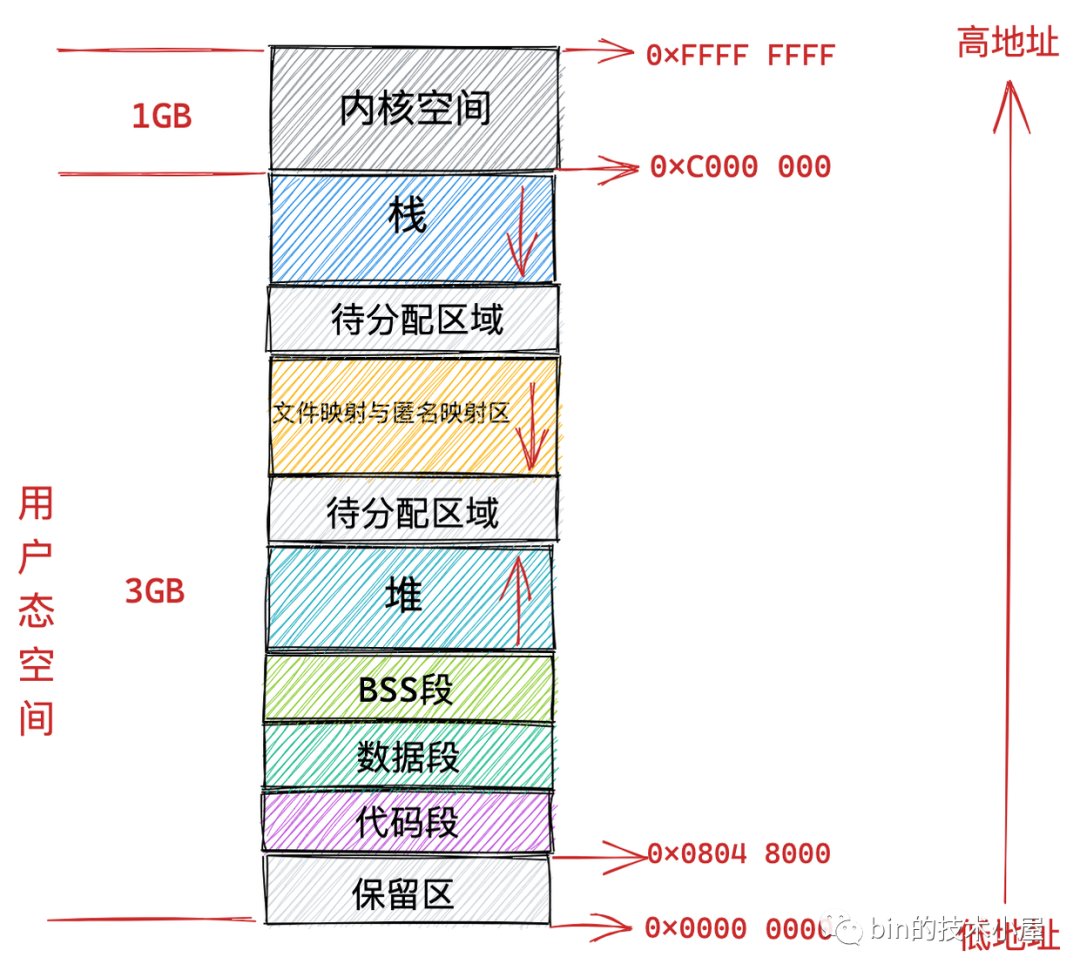
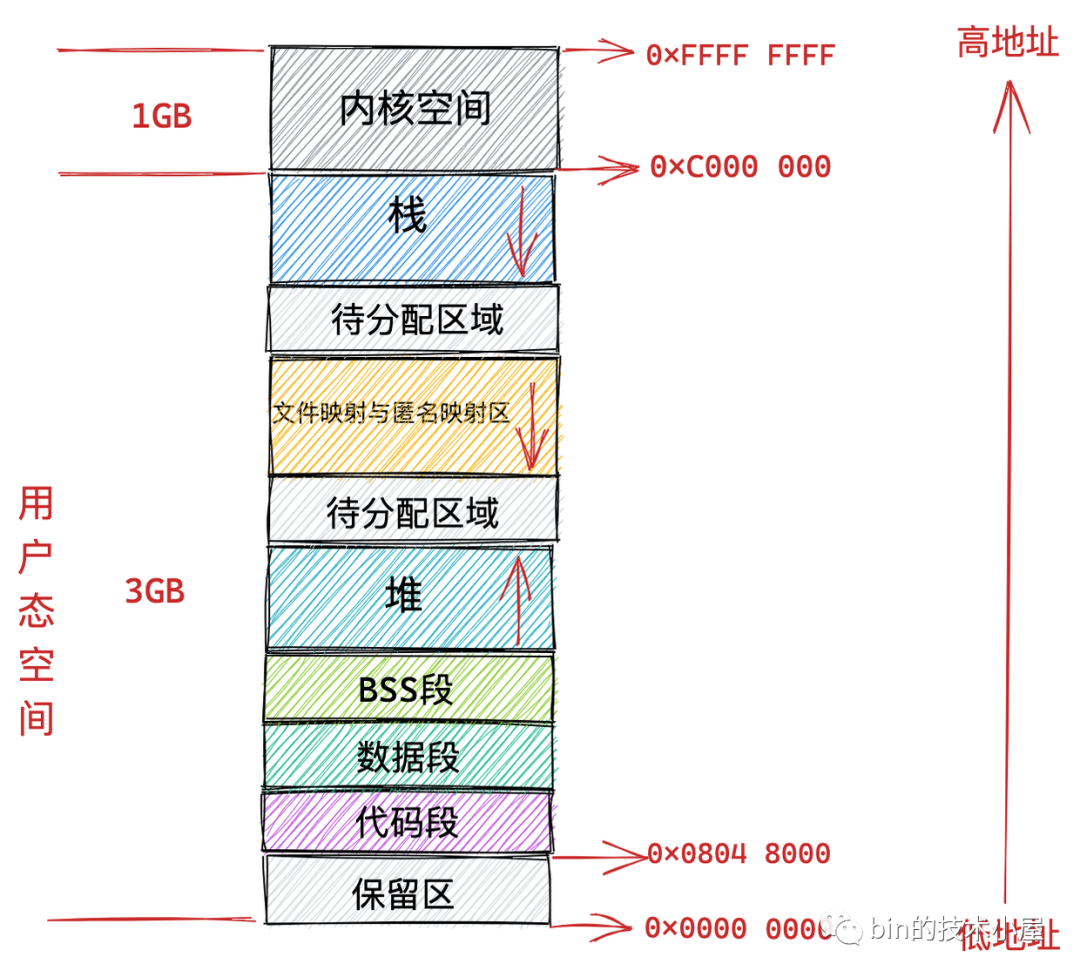
在 32 位機器上,指標的尋址范圍為 2^32,所能表達的虛擬記憶體空間為 4 GB,所以在 32 位機器上行程的虛擬記憶體地址范圍為:0x0000 0000 - 0xFFFF FFFF,
其中用戶態虛擬記憶體空間為 3 GB,虛擬記憶體地址范圍為:0x0000 0000 - 0xC000 000 ,
內核態虛擬記憶體空間為 1 GB,虛擬記憶體地址范圍為:0xC000 000 - 0xFFFF FFFF,
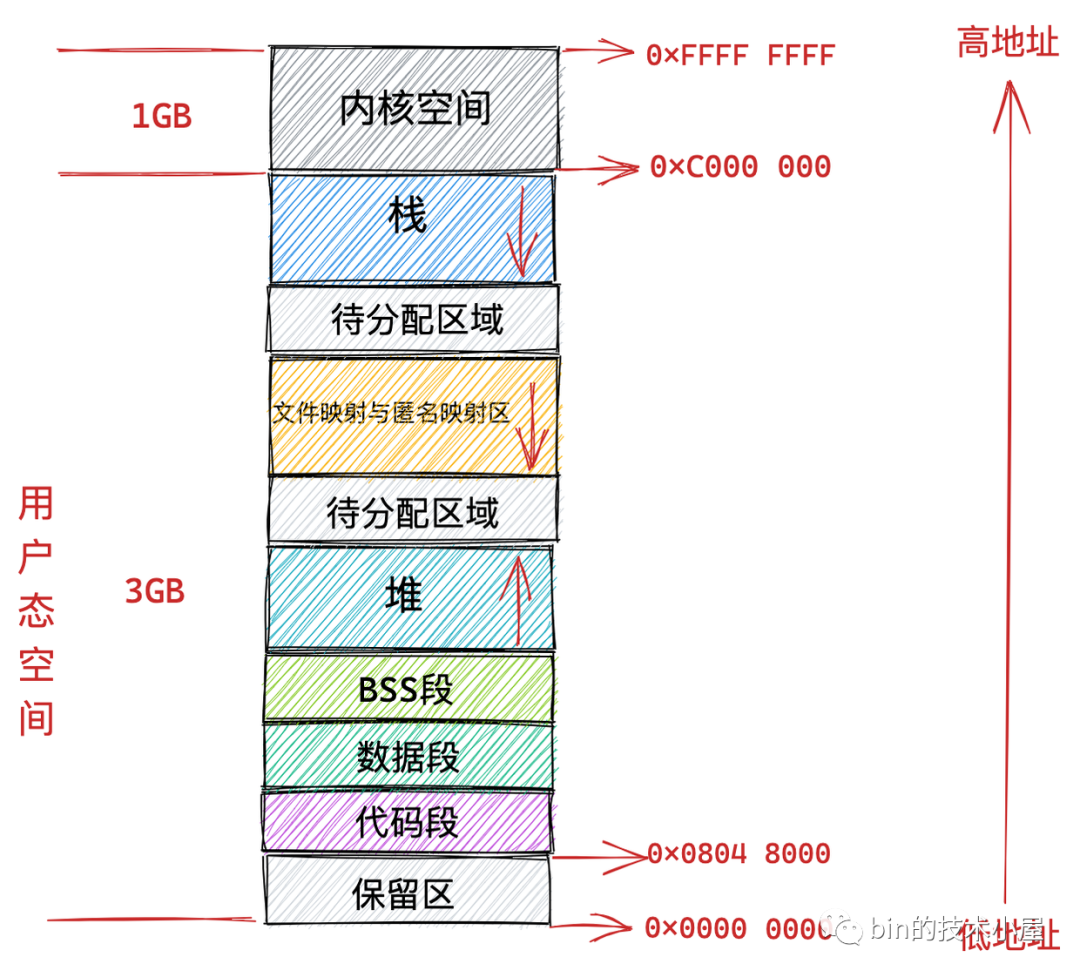
但是用戶態虛擬記憶體空間中的代碼段并不是從 0x0000 0000 地址開始的,而是從 0x0804 8000 地址開始,
0x0000 0000 到 0x0804 8000 這段虛擬記憶體地址是一段不可訪問的保留區,因為在大多數作業系統中,數值比較小的地址通常被認為不是一個合法的地址,這塊小地址是不允許訪問的,比如在 C 語言中我們通常會將一些無效的指標設定為 NULL,指向這塊不允許訪問的地址,
保留區的上邊就是代碼段和資料段,它們是從程式的二進制檔案中直接加載進記憶體中的,BSS 段中的資料也存在于二進制檔案中,因為內核知道這些資料是沒有初值的,所以在二進制檔案中只會記錄 BSS 段的大小,在加載進記憶體時會生成一段 0 填充的記憶體空間,
緊挨著 BSS 段的上邊就是我們經常使用到的堆空間,從圖中的紅色箭頭我們可以知道在堆空間中地址的增長方向是從低地址到高地址增長,
內核中使用 start_brk 標識堆的起始位置,brk 標識堆當前的結束位置,當堆申請新的記憶體空間時,只需要將 brk 指標增加對應的大小,回收地址時減少對應的大小即可,比如當我們通過 malloc 向內核申請很小的一塊記憶體時(128K 之內),就是通過改變 brk 位置實作的,
堆空間的上邊是一段待分配區域,用于擴展堆空間的使用,接下來就來到了檔案映射與匿名映射區域,行程運行時所依賴的元件中的代碼段,資料段,BSS 段就加載在這里,還有我們呼叫 mmap 映射出來的一段虛擬記憶體空間也保存在這個區域,注意:在檔案映射與匿名映射區的地址增長方向是從高地址向低地址增長,
接下來用戶態虛擬記憶體空間的最后一塊區域就是堆疊空間了,在這里會保存函式運行程序所需要的區域變數以及函式引數等函式呼叫資訊,堆疊空間中的地址增長方向是從高地址向低地址增長,每次行程申請新的堆疊地址時,其地址值是在減少的,
在內核中使用 start_stack 標識堆疊的起始位置,RSP 暫存器中保存堆疊頂指標 stack pointer,RBP 暫存器中保存的是堆疊基地址,
在堆疊空間的下邊也有一段待分配區域用于擴展堆疊空間,在堆疊空間的上邊就是內核空間了,行程雖然可以看到這段內核空間地址,但是就是不能訪問,這就好比我們在飯店里雖然可以看到廚房在哪里,但是廚房門上寫著 “廚房重地,閑人免進” ,我們就是進不去,

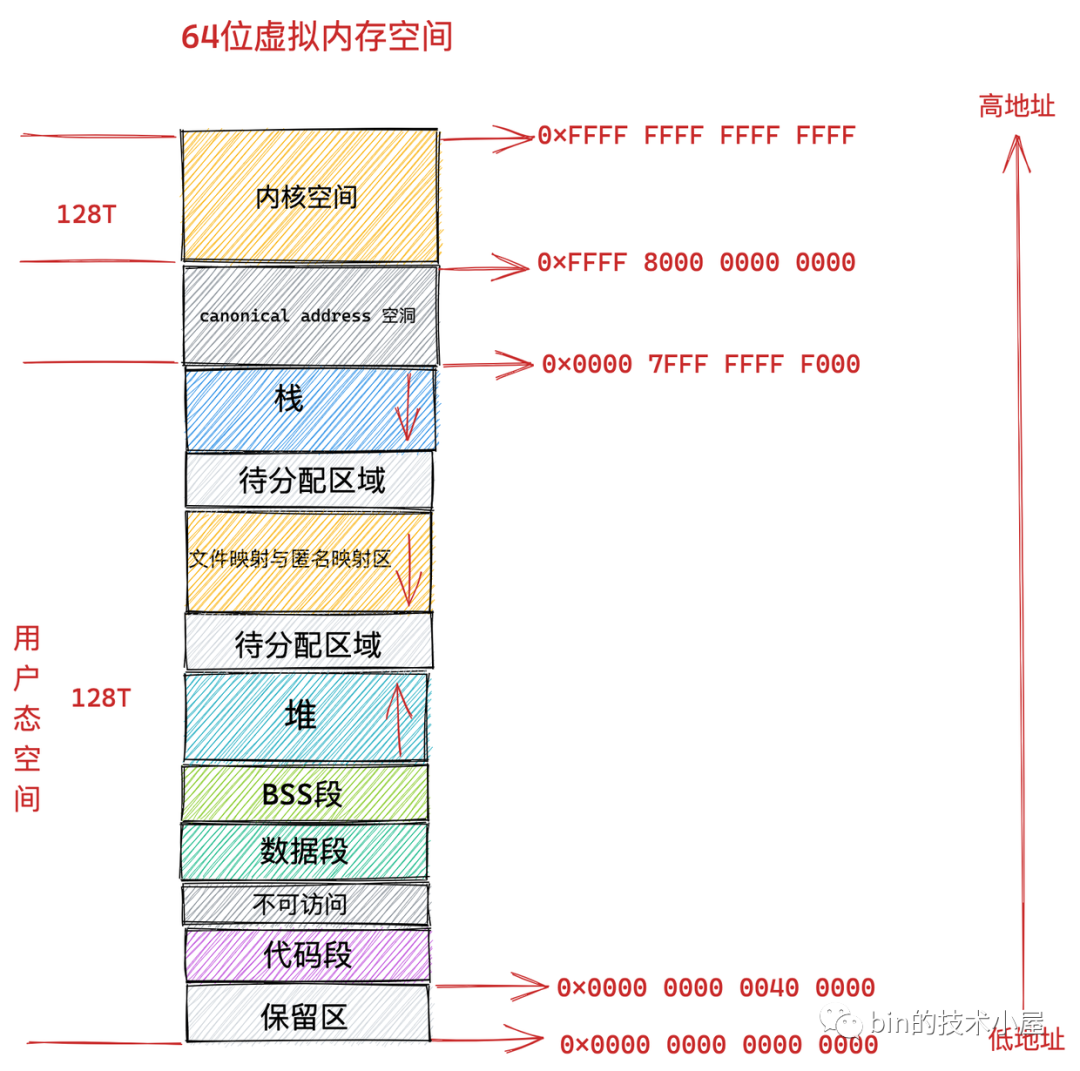
4.2 64 位機器上行程虛擬記憶體空間分布
上小節中介紹的 32 位虛擬記憶體空間布局和本小節即將要介紹的 64 位虛擬記憶體空間布局都可以通過 cat /proc/pid/maps 或者 pmap pid 來查看某個行程的實際虛擬記憶體布局,
我們知道在 32 位機器上,指標的尋址范圍為 2^32,所能表達的虛擬記憶體空間為 4 GB,
那么我們理所應當的會認為在 64 位機器上,指標的尋址范圍為 2^64,所能表達的虛擬記憶體空間為 16 EB ,虛擬記憶體地址范圍為:0x0000 0000 0000 0000 0000 - 0xFFFF FFFF FFFF FFFF ,
好家伙 !!! 16 EB 的記憶體空間,筆者都沒見過這么大的磁盤,在現實情況中根本不會用到這么大范圍的記憶體空間,
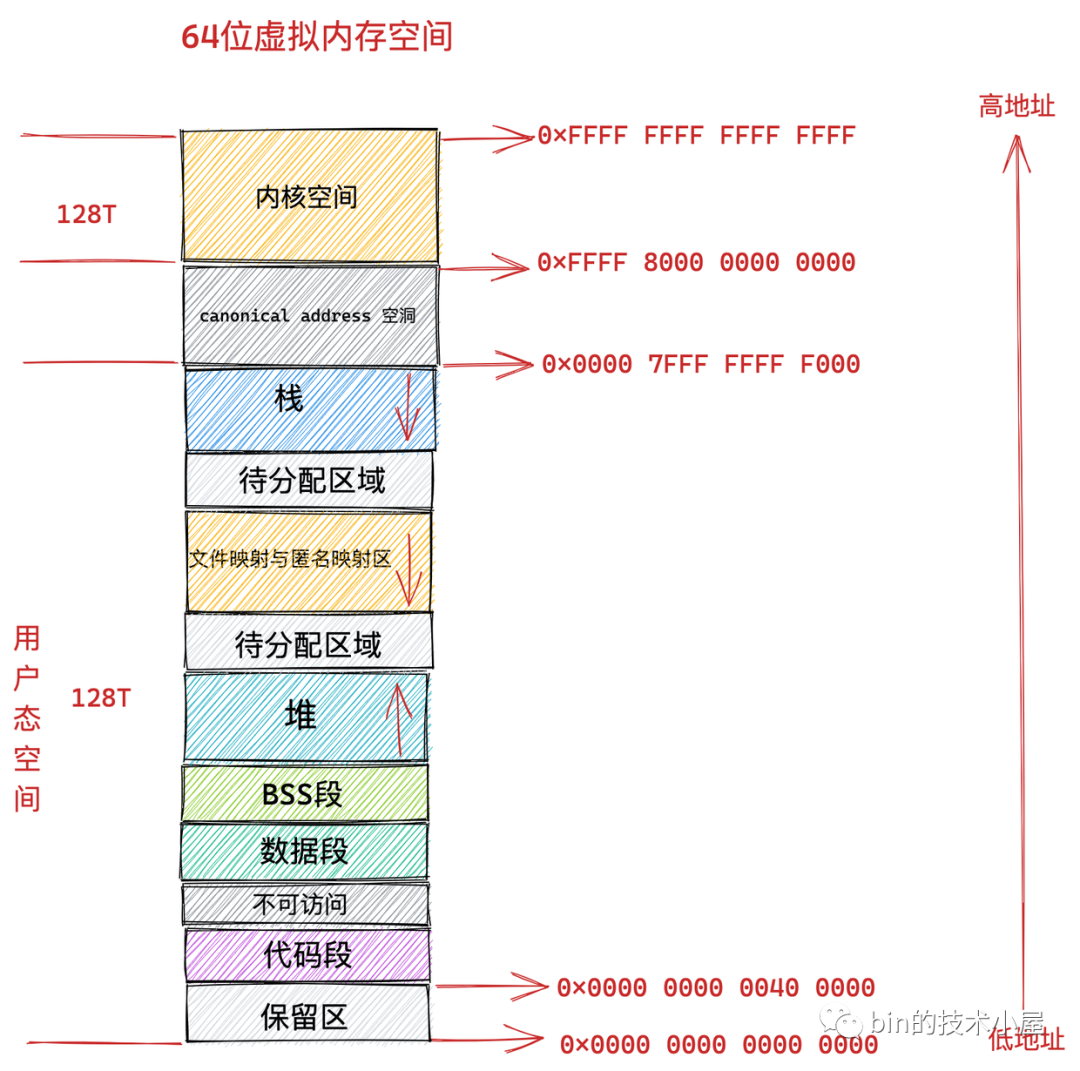
事實上在目前的 64 位系統下只使用了 48 位來描述虛擬記憶體空間,尋址范圍為 2^48 ,所能表達的虛擬記憶體空間為 256TB,
其中低 128 T 表示用戶態虛擬記憶體空間,虛擬記憶體地址范圍為:0x0000 0000 0000 0000 - 0x0000 7FFF FFFF F000 ,
高 128 T 表示內核態虛擬記憶體空間,虛擬記憶體地址范圍為:0xFFFF 8000 0000 0000 - 0xFFFF FFFF FFFF FFFF ,
這樣一來就在用戶態虛擬記憶體空間與內核態虛擬記憶體空間之間形成了一段 0x0000 7FFF FFFF F000 - 0xFFFF 8000 0000 0000 的地址空洞,我們把這個空洞叫做 canonical address 空洞,
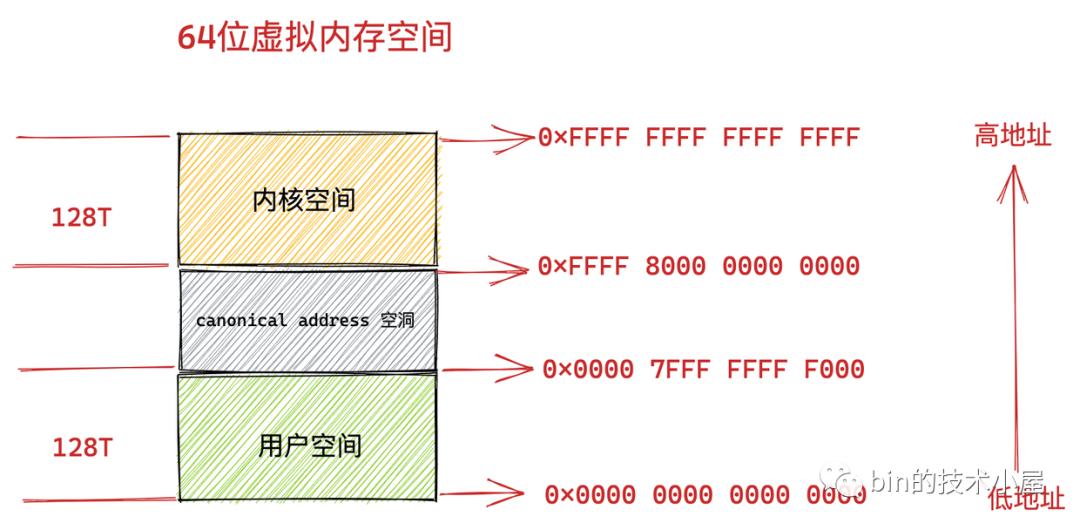
那么這個 canonical address 空洞是如何形成的呢?
我們都知道在 64 位機器上的指標尋址范圍為 2^64,但是在實際使用中我們只使用了其中的低 48 位來表示虛擬記憶體地址,那么這多出的高 16 位就形成了這個地址空洞,
大家注意到在低 128T 的用戶態地址空間:0x0000 0000 0000 0000 - 0x0000 7FFF FFFF F000 范圍中,所以虛擬記憶體地址的高 16 位全部為 0 ,
如果一個虛擬記憶體地址的高 16 位全部為 0 ,那么我們就可以直接判斷出這是一個用戶空間的虛擬記憶體地址,
同樣的道理,在高 128T 的內核態虛擬記憶體空間:0xFFFF 8000 0000 0000 - 0xFFFF FFFF FFFF FFFF 范圍中,所以虛擬記憶體地址的高 16 位全部為 1 ,
也就是說內核態的虛擬記憶體地址的高 16 位全部為 1 ,如果一個試圖訪問內核的虛擬地址的高 16 位不全為 1 ,則可以快速判斷這個訪問是非法的,
這個高 16 位的空閑地址被稱為 canonical ,如果虛擬記憶體地址中的高 16 位全部為 0 (表示用戶空間虛擬記憶體地址)或者全部為 1 (表示內核空間虛擬記憶體地址),這種地址的形式我們叫做 canonical form,對應的地址我們稱作 canonical address ,
那么處于 canonical address 空洞 :0x0000 7FFF FFFF F000 - 0xFFFF 8000 0000 0000 范圍內的地址的高 16 位 不全為 0 也不全為 1 ,如果某個虛擬地址落在這段 canonical address 空洞區域中,那就是既不在用戶空間,也不在內核空間,肯定是非法訪問了,
未來我們也可以利用這塊 canonical address 空洞,來擴展虛擬記憶體地址的范圍,比如擴展到 56 位,
在我們理解了 canonical address 這個概念之后,我們再來看下 64 位 Linux 系統下的真實虛擬記憶體空間布局情況:
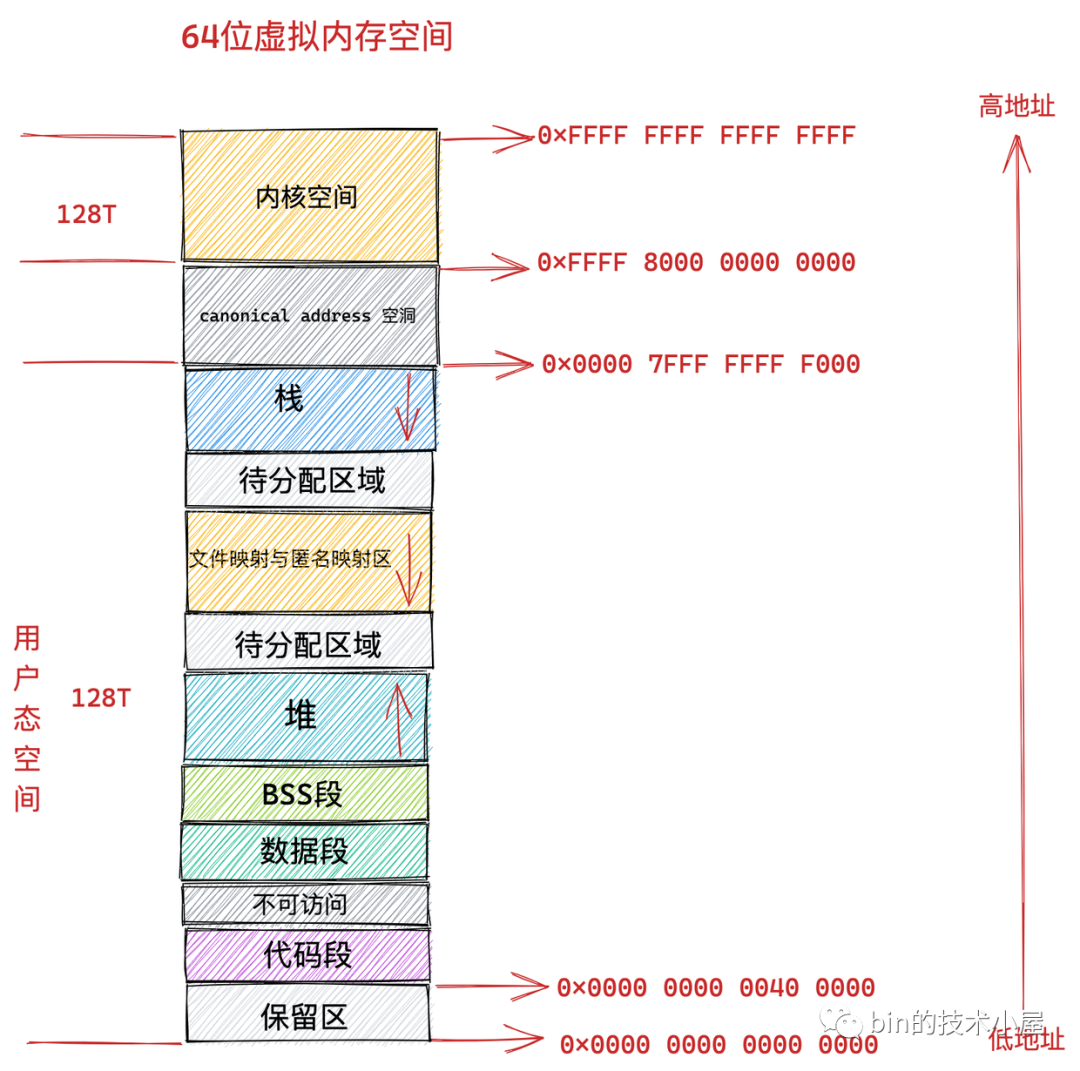
從上圖中我們可以看出 64 位系統中的虛擬記憶體布局和 32 位系統中的虛擬記憶體布局大體上是差不多的,主要不同的地方有三點:
-
就是前邊提到的由高 16 位空閑地址造成的 canonical address 空洞,在這段范圍內的虛擬記憶體地址是不合法的,因為它的高 16 位既不全為 0 也不全為 1,不是一個 canonical address,所以稱之為 canonical address 空洞,
-
在代碼段跟資料段的中間還有一段不可以讀寫的保護段,它的作用是防止程式在讀寫資料段的時候越界訪問到代碼段,這個保護段可以讓越界訪問行為直接崩潰,防止它繼續往下運行,
-
用戶態虛擬記憶體空間與內核態虛擬記憶體空間分別占用 128T,其中低128T 分配給用戶態虛擬記憶體空間,高 128T 分配給內核態虛擬記憶體空間,
5. 行程虛擬記憶體空間的管理
在上一小節中,筆者為大家介紹了 Linux 作業系統在 32 位機器上和 64 位機器上行程虛擬記憶體空間的布局分布,我們發現無論是在 32 位機器上還是在 64 位機器上,行程虛擬記憶體空間的核心區域分布的相對位置是不變的,它們都包含下圖所示的這幾個核心記憶體區域,
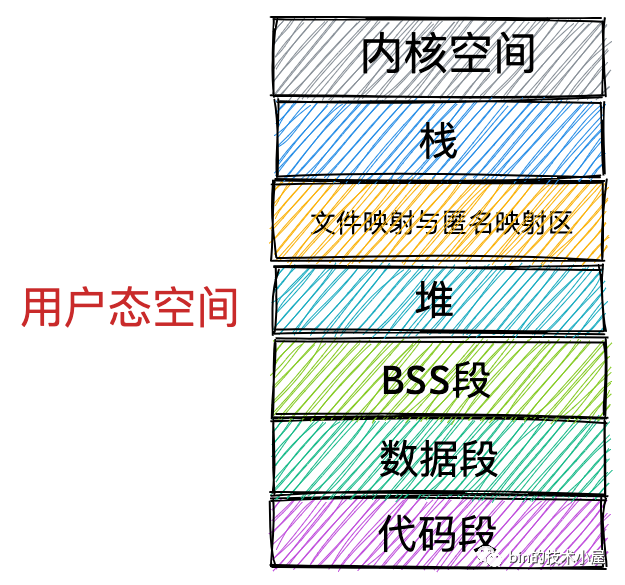
唯一不同的是這些核心記憶體區域在 32 位機器和 64 位機器上的絕對位置分布會有所不同,
那么在此基礎之上,內核如何為行程管理這些虛擬記憶體區域呢?這將是本小節重點為大家介紹的內容~~
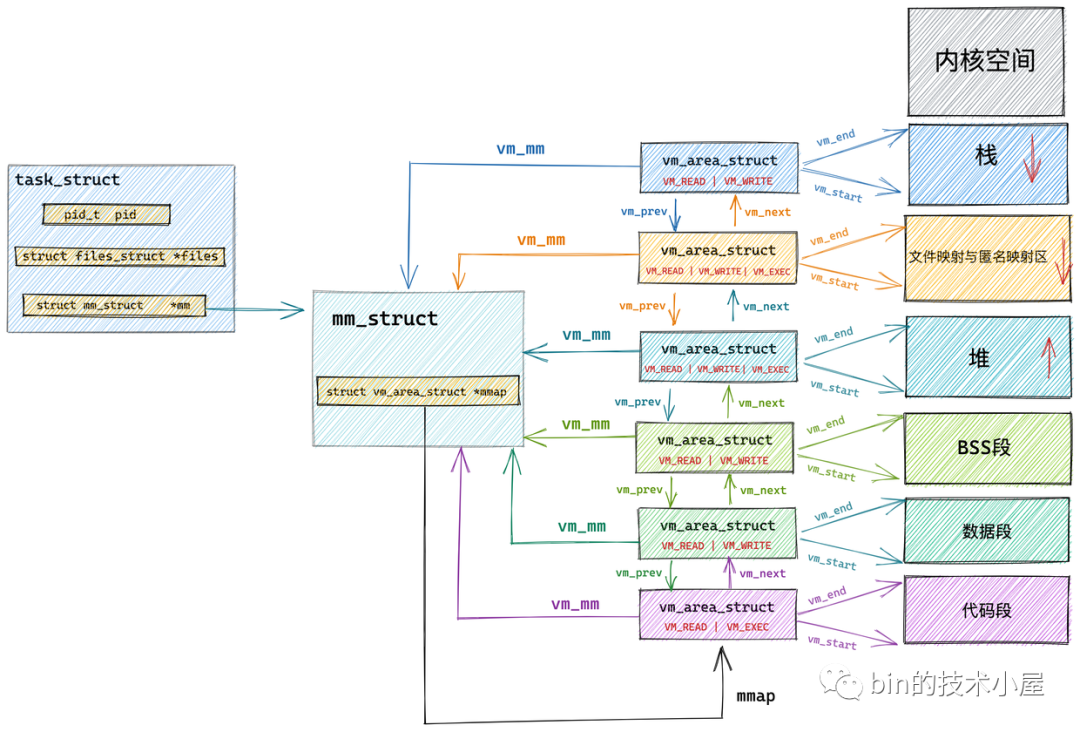
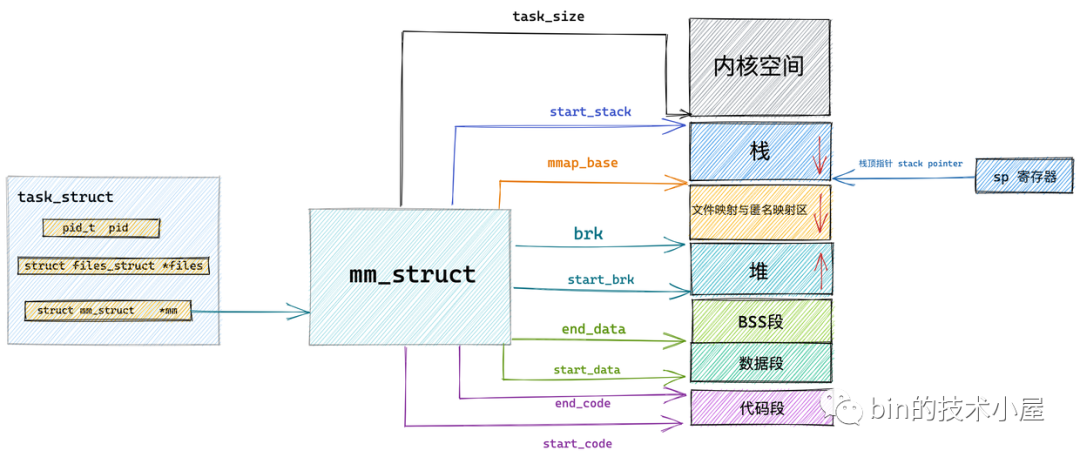
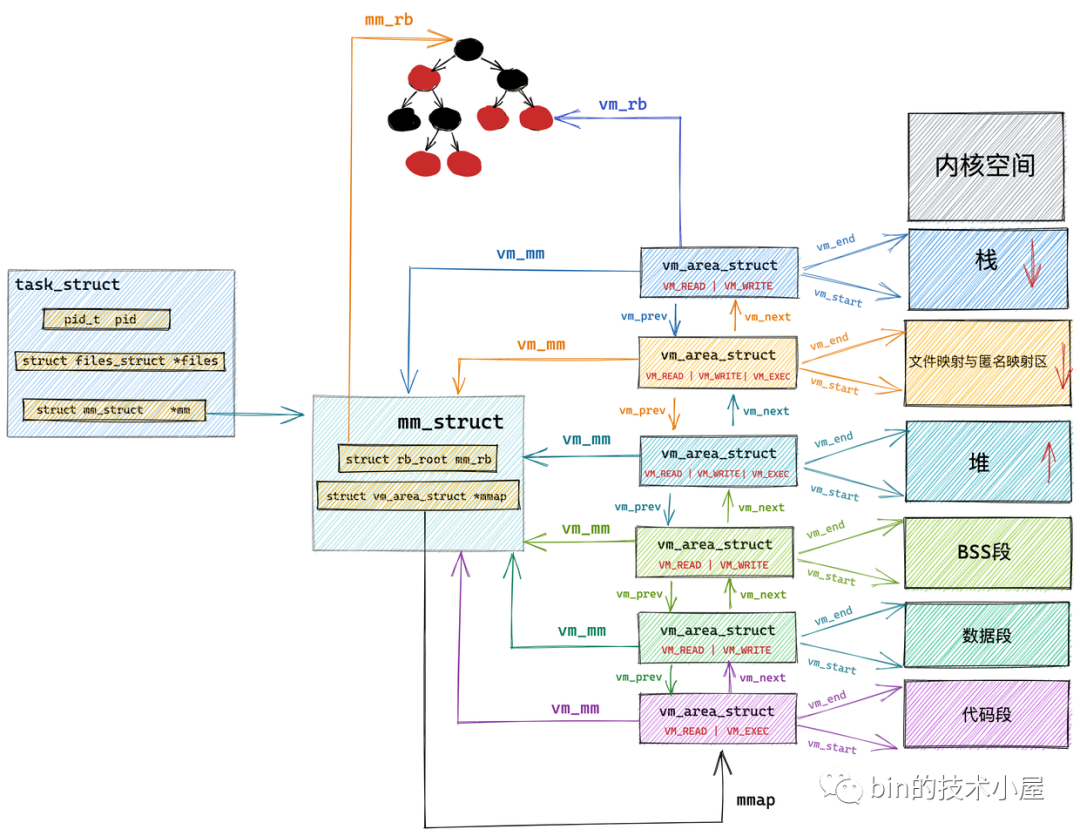
既然我們要介紹行程的虛擬記憶體空間管理,那就離不開行程在內核中的描述符 task_struct 結構,
struct task_struct {
// 行程id
pid_t pid;
// 用于標識執行緒所屬的行程 pid
pid_t tgid;
// 行程打開的檔案資訊
struct files_struct *files;
// 記憶體描述符表示行程虛擬地址空間
struct mm_struct *mm;
.......... 省略 .......
}
在行程描述符 task_struct 結構中,有一個專門描述行程虛擬地址空間的記憶體描述符 mm_struct 結構,這個結構體中包含了前邊幾個小節中介紹的行程虛擬記憶體空間的全部資訊,
每個行程都有唯一的 mm_struct 結構體,也就是前邊提到的每個行程的虛擬地址空間都是獨立,互不干擾的,
當我們呼叫 fork() 函式創建行程的時候,表示行程地址空間的 mm_struct 結構會隨著行程描述符 task_struct 的創建而創建,
long _do_fork(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr,
unsigned long tls)
{
......... 省略 ..........
struct pid *pid;
struct task_struct *p;
......... 省略 ..........
// 為行程創建 task_struct 結構,用父行程的資源填充 task_struct 資訊
p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace, tls, NUMA_NO_NODE);
......... 省略 ..........
}
隨后會在 copy_process 函式中創建 task_struct 結構,并拷貝父行程的相關資源到新行程的 task_struct 結構里,其中就包括拷貝父行程的虛擬記憶體空間 mm_struct 結構,這里可以看出子行程在新創建出來之后它的虛擬記憶體空間是和父行程的虛擬記憶體空間一模一樣的,直接拷貝過來,
static __latent_entropy struct task_struct *copy_process(
unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *child_tidptr,
struct pid *pid,
int trace,
unsigned long tls,
int node)
{
struct task_struct *p;
// 創建 task_struct 結構
p = dup_task_struct(current, node);
....... 初始化子行程 ...........
....... 開始繼承拷貝父行程資源 .......
// 繼承父行程打開的檔案描述符
retval = copy_files(clone_flags, p);
// 繼承父行程所屬的檔案系統
retval = copy_fs(clone_flags, p);
// 繼承父行程注冊的信號以及信號處理函式
retval = copy_sighand(clone_flags, p);
retval = copy_signal(clone_flags, p);
// 繼承父行程的虛擬記憶體空間
retval = copy_mm(clone_flags, p);
// 繼承父行程的 namespaces
retval = copy_namespaces(clone_flags, p);
// 繼承父行程的 IO 資訊
retval = copy_io(clone_flags, p);
...........省略.........
// 分配 CPU
retval = sched_fork(clone_flags, p);
// 分配 pid
pid = alloc_pid(p->nsproxy->pid_ns_for_children);
. ..........省略.........
}
這里我們重點關注 copy_mm 函式,正是在這里完成了子行程虛擬記憶體空間 mm_struct 結構的的創建以及初始化,
static int copy_mm(unsigned long clone_flags, struct task_struct *tsk)
{
// 子行程虛擬記憶體空間,父行程虛擬記憶體空間
struct mm_struct *mm, *oldmm;
int retval;
...... 省略 ......
tsk->mm = NULL;
tsk->active_mm = NULL;
// 獲取父行程虛擬記憶體空間
oldmm = current->mm;
if (!oldmm)
return 0;
...... 省略 ......
// 通過 vfork 或者 clone 系統呼叫創建出的子行程(執行緒)和父行程共享虛擬記憶體空間
if (clone_flags & CLONE_VM) {
// 增加父行程虛擬地址空間的參考計數
mmget(oldmm);
// 直接將父行程的虛擬記憶體空間賦值給子行程(執行緒)
// 執行緒共享其所屬行程的虛擬記憶體空間
mm = oldmm;
goto good_mm;
}
retval = -ENOMEM;
// 如果是 fork 系統呼叫創建出的子行程,則將父行程的虛擬記憶體空間以及相關頁表拷貝到子行程中的 mm_struct 結構中,
mm = dup_mm(tsk);
if (!mm)
goto fail_nomem;
good_mm:
// 將拷貝出來的父行程虛擬記憶體空間 mm_struct 賦值給子行程
tsk->mm = mm;
tsk->active_mm = mm;
return 0;
...... 省略 ......
由于本小節中我們舉的示例是通過 fork() 函式創建子行程的情形,所以這里大家先占時忽略 if (clone_flags & CLONE_VM) 這個條件判斷邏輯,我們先跳過往后看~~
copy_mm 函式首先會將父行程的虛擬記憶體空間 current->mm 賦值給指標 oldmm,然后通過 dup_mm 函式將父行程的虛擬記憶體空間以及相關頁表拷貝到子行程的 mm_struct 結構中,最后將拷貝出來的 mm_struct 賦值給子行程的 task_struct 結構,
通過 fork() 函式創建出的子行程,它的虛擬記憶體空間以及相關頁表相當于父行程虛擬記憶體空間的一份拷貝,直接從父行程中拷貝到子行程中,
而當我們通過 vfork 或者 clone 系統呼叫創建出的子行程,首先會設定 CLONE_VM 標識,這樣來到 copy_mm 函式中就會進入 if (clone_flags & CLONE_VM) 條件中,在這個分支中會將父行程的虛擬記憶體空間以及相關頁表直接賦值給子行程,這樣一來父行程和子行程的虛擬記憶體空間就變成共享的了,也就是說父子行程之間使用的虛擬記憶體空間是一樣的,并不是一份拷貝,
子行程共享了父行程的虛擬記憶體空間,這樣子行程就變成了我們熟悉的執行緒,是否共享地址空間幾乎是行程和執行緒之間的本質區別,Linux 內核并不區別對待它們,執行緒對于內核來說僅僅是一個共享特定資源的行程而已,
內核執行緒和用戶態執行緒的區別就是內核執行緒沒有相關的記憶體描述符 mm_struct ,內核執行緒對應的 task_struct 結構中的 mm 域指向 Null,所以內核執行緒之間調度是不涉及地址空間切換的,
當一個內核執行緒被調度時,它會發現自己的虛擬地址空間為 Null,雖然它不會訪問用戶態的記憶體,但是它會訪問內核記憶體,聰明的內核會將調度之前的上一個用戶態行程的虛擬記憶體空間 mm_struct 直接賦值給內核執行緒,因為內核執行緒不會訪問用戶空間的記憶體,它僅僅只會訪問內核空間的記憶體,所以直接復用上一個用戶態行程的虛擬地址空間就可以避免為內核執行緒分配 mm_struct 和相關頁表的開銷,以及避免內核執行緒之間調度時地址空間的切換開銷,
父行程與子行程的區別,行程與執行緒的區別,以及內核執行緒與用戶態執行緒的區別其實都是圍繞著這個 mm_struct 展開的,
現在我們知道了表示行程虛擬記憶體空間的 mm_struct 結構是如何被創建出來的相關背景,那么接下來筆者就帶大家深入 mm_struct 結構內部,來看一下內核如何通過這么一個 mm_struct 結構體來管理行程的虛擬記憶體空間的,
5.1 內核如何劃分用戶態和內核態虛擬記憶體空間
通過 《3. 行程虛擬記憶體空間》小節的介紹我們知道,行程的虛擬記憶體空間分為兩個部分:一部分是用戶態虛擬記憶體空間,另一部分是內核態虛擬記憶體空間,
那么用戶態的地址空間和內核態的地址空間在內核中是如何被劃分的呢?
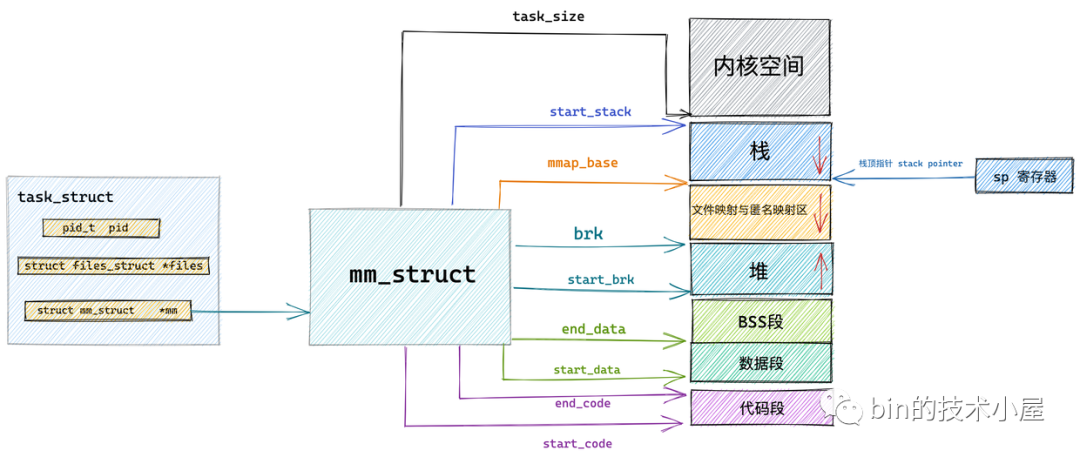
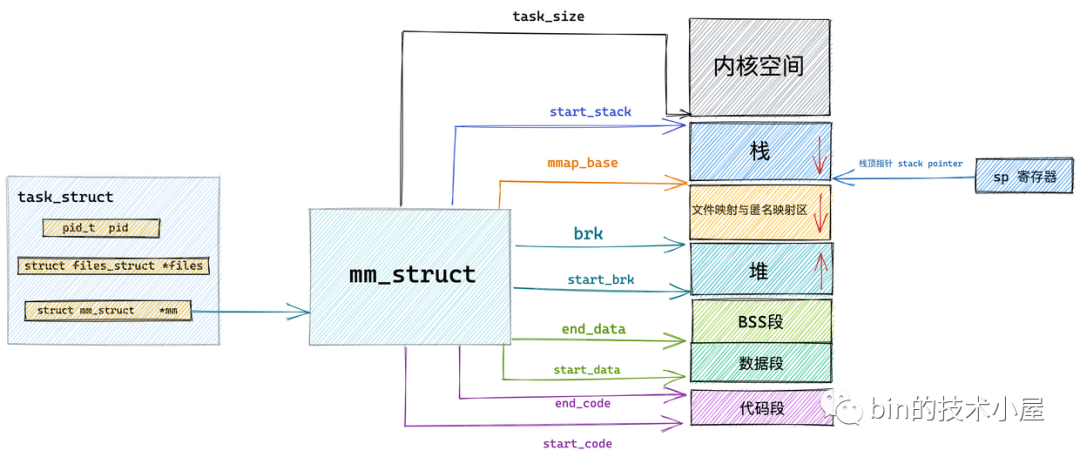
這就用到了行程的記憶體描述符 mm_struct 結構體中的 task_size 變數,task_size 定義了用戶態地址空間與內核態地址空間之間的分界線,
struct mm_struct {
unsigned long task_size; /* size of task vm space */
}
通過前邊小節的內容介紹,我們知道在 32 位系統中用戶態虛擬記憶體空間為 3 GB,虛擬記憶體地址范圍為:0x0000 0000 - 0xC000 000 ,
內核態虛擬記憶體空間為 1 GB,虛擬記憶體地址范圍為:0xC000 000 - 0xFFFF FFFF,
32 位系統中用戶地址空間和內核地址空間的分界線在 0xC000 000 地址處,那么自然行程的 mm_struct 結構中的 task_size 為 0xC000 000,
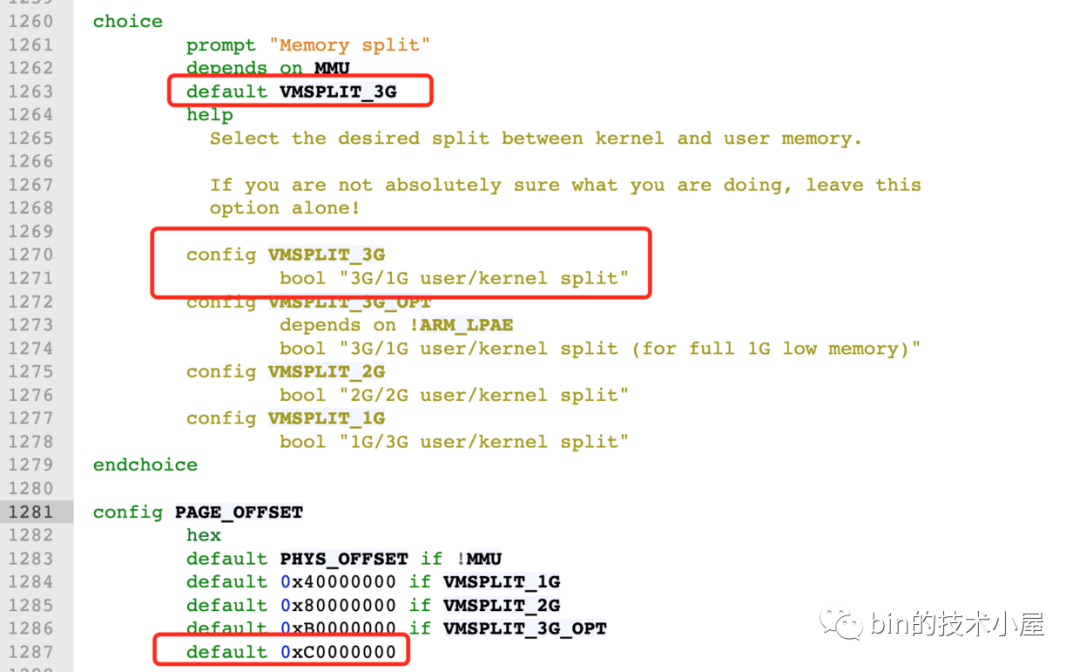
我們來看下內核在 /arch/x86/include/asm/page_32_types.h 檔案中關于 TASK_SIZE 的定義,
/*
* User space process size: 3GB (default).
*/
#define TASK_SIZE __PAGE_OFFSET
如下圖所示:__PAGE_OFFSET 的值在 32 位系統下為 0xC000 000,
而在 64 位系統中,只使用了其中的低 48 位來表示虛擬記憶體地址,其中用戶態虛擬記憶體空間為低 128 T,虛擬記憶體地址范圍為:0x0000 0000 0000 0000 - 0x0000 7FFF FFFF F000 ,
內核態虛擬記憶體空間為高 128 T,虛擬記憶體地址范圍為:0xFFFF 8000 0000 0000 - 0xFFFF FFFF FFFF FFFF ,
64 位系統中用戶地址空間和內核地址空間的分界線在 0x0000 7FFF FFFF F000 地址處,那么自然行程的 mm_struct 結構中的 task_size 為 0x0000 7FFF FFFF F000 ,
我們來看下內核在 /arch/x86/include/asm/page_64_types.h 檔案中關于 TASK_SIZE 的定義,
#define TASK_SIZE (test_thread_flag(TIF_ADDR32) ? \
IA32_PAGE_OFFSET : TASK_SIZE_MAX)
#define TASK_SIZE_MAX task_size_max()
#define task_size_max() ((_AC(1,UL) << __VIRTUAL_MASK_SHIFT) - PAGE_SIZE)
#define __VIRTUAL_MASK_SHIFT 47
我們來看下在 64 位系統中內核如何來計算 TASK_SIZE,在 task_size_max() 的計算邏輯中 1 左移 47 位得到的地址是 0x0000800000000000,然后減去一個 PAGE_SIZE (默認為 4K),就是 0x00007FFFFFFFF000,共 128T,所以在 64 位系統中的 TASK_SIZE 為 0x00007FFFFFFFF000 ,
這里我們可以看出,64 位虛擬記憶體空間的布局是和物理記憶體頁 page 的大小有關的,物理記憶體頁 page 默認大小 PAGE_SIZE 為 4K,
PAGE_SIZE 定義在 /arch/x86/include/asm/page_types.h檔案中:
/* PAGE_SHIFT determines the page size */
#define PAGE_SHIFT 12
#define PAGE_SIZE (_AC(1,UL) << PAGE_SHIFT)
而內核空間的起始地址是 0xFFFF 8000 0000 0000 ,在 0x00007FFFFFFFF000 - 0xFFFF 8000 0000 0000 之間的記憶體區域就是我們在 《4.2 64 位機器上行程虛擬記憶體空間分布》小節中介紹的 canonical address 空洞,
5.2 內核如何布局行程虛擬記憶體空間
在我們理解了內核是如何劃分行程虛擬記憶體空間和內核虛擬記憶體空間之后,那么在 《3. 行程虛擬記憶體空間》小節中介紹的那些虛擬記憶體區域在內核中又是如何劃分的呢?
接下來筆者就為大家介紹下內核是如何劃分行程虛擬記憶體空間中的這些記憶體區域的,本小節的示例圖中,筆者只保留了行程虛擬記憶體空間中的核心區域,方便大家理解,
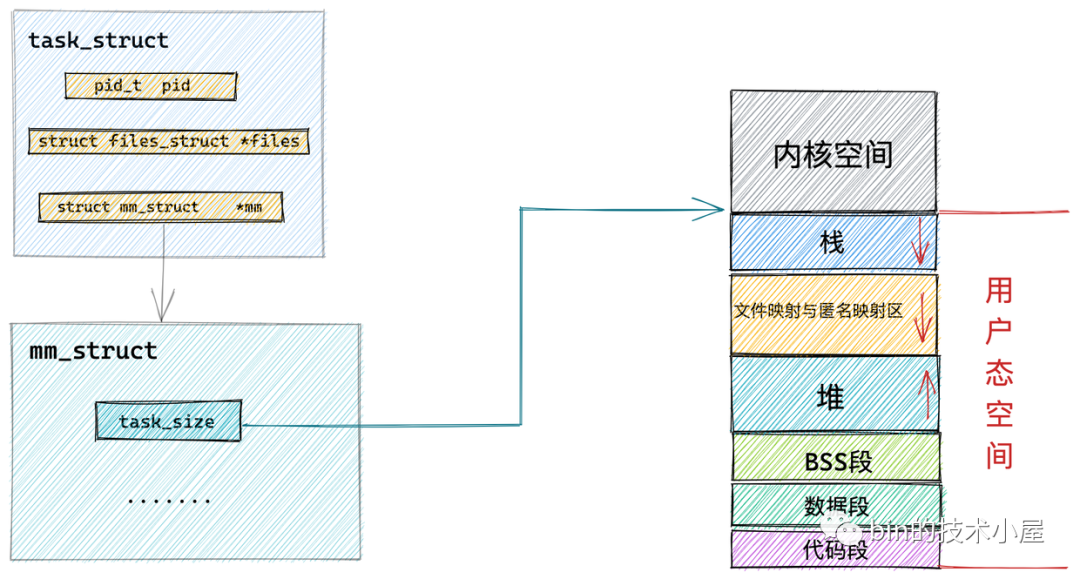
前邊我們提到,內核中采用了一個叫做記憶體描述符的 mm_struct 結構體來表示行程虛擬記憶體空間的全部資訊,在本小節中筆者就帶大家到 mm_struct 結構體內部去尋找下相關的線索,
struct mm_struct {
unsigned long task_size; /* size of task vm space */
unsigned long start_code, end_code, start_data, end_data;
unsigned long start_brk, brk, start_stack;
unsigned long arg_start, arg_end, env_start, env_end;
unsigned long mmap_base; /* base of mmap area */
unsigned long total_vm; /* Total pages mapped */
unsigned long locked_vm; /* Pages that have PG_mlocked set */
unsigned long pinned_vm; /* Refcount permanently increased */
unsigned long data_vm; /* VM_WRITE & ~VM_SHARED & ~VM_STACK */
unsigned long exec_vm; /* VM_EXEC & ~VM_WRITE & ~VM_STACK */
unsigned long stack_vm; /* VM_STACK */
...... 省略 ........
}
內核中用 mm_struct 結構體中的上述屬性來定義上圖中虛擬記憶體空間里的不同記憶體區域,
start_code 和 end_code 定義代碼段的起始和結束位置,程式編譯后的二進制檔案中的機器碼被加載進記憶體之后就存放在這里,
start_data 和 end_data 定義資料段的起始和結束位置,二進制檔案中存放的全域變數和靜態變數被加載進記憶體中就存放在這里,
后面緊挨著的是 BSS 段,用于存放未被初始化的全域變數和靜態變數,這些變數在加載進記憶體時會生成一段 0 填充的記憶體區域 (BSS 段), BSS 段的大小是固定的,
下面就是 OS 堆了,在堆中記憶體地址的增長方向是由低地址向高地址增長, start_brk 定義堆的起始位置,brk 定義堆當前的結束位置,
我們使用 malloc 申請小塊記憶體時(低于 128K),就是通過改變 brk 位置調整堆大小實作的,
接下來就是記憶體映射區,在記憶體映射區記憶體地址的增長方向是由高地址向低地址增長,mmap_base 定義記憶體映射區的起始地址,行程運行時所依賴的元件中的代碼段,資料段,BSS 段以及我們呼叫 mmap 映射出來的一段虛擬記憶體空間就保存在這個區域,
start_stack 是堆疊的起始位置在 RBP 暫存器中存盤,堆疊的結束位置也就是堆疊頂指標 stack pointer 在 RSP 暫存器中存盤,在堆疊中記憶體地址的增長方向也是由高地址向低地址增長,
arg_start 和 arg_end 是引數串列的位置, env_start 和 env_end 是環境變數的位置,它們都位于堆疊中的最高地址處,
在 mm_struct 結構體中除了上述用于劃分虛擬記憶體區域的變數之外,還定義了一些虛擬記憶體與物理記憶體映射內容相關的統計變數,作業系統會把物理記憶體劃分成一頁一頁的區域來進行管理,所以物理記憶體到虛擬記憶體之間的映射也是按照頁為單位進行的,這部分內容筆者會在后續的文章中詳細介紹,大家這里只需要有個概念就行,
mm_struct 結構體中的 total_vm 表示在行程虛擬記憶體空間中總共與物理記憶體映射的頁的總數,
注意映射這個概念,它表示只是將虛擬記憶體與物理記憶體建立關聯關系,并不代表真正的分配物理記憶體,
當記憶體吃緊的時候,有些頁可以換出到硬碟上,而有些頁因為比較重要,不能換出,locked_vm 就是被鎖定不能換出的記憶體頁總數,pinned_vm 表示既不能換出,也不能移動的記憶體頁總數,
data_vm 表示資料段中映射的記憶體頁數目,exec_vm 是代碼段中存放可執行檔案的記憶體頁數目,stack_vm 是堆疊中所映射的記憶體頁數目,這些變數均是表示行程虛擬記憶體空間中的虛擬記憶體使用情況,
現在關于內核如何對行程虛擬記憶體空間進行布局的內容我們已經清楚了,那么布局之后劃分出的這些虛擬記憶體區域在內核中又是如何被管理的呢?我們接著往下看~~~
5.3 內核如何管理虛擬記憶體區域
在上小節的介紹中,我們知道內核是通過一個 mm_struct 結構的記憶體描述符來表示行程的虛擬記憶體空間的,并通過 task_size 域來劃分用戶態虛擬記憶體空間和內核態虛擬記憶體空間,
而在劃分出的這些虛擬記憶體空間中如上圖所示,里邊又包含了許多特定的虛擬記憶體區域,比如:代碼段,資料段,堆,記憶體映射區,堆疊,那么這些虛擬記憶體區域在內核中又是如何表示的呢?
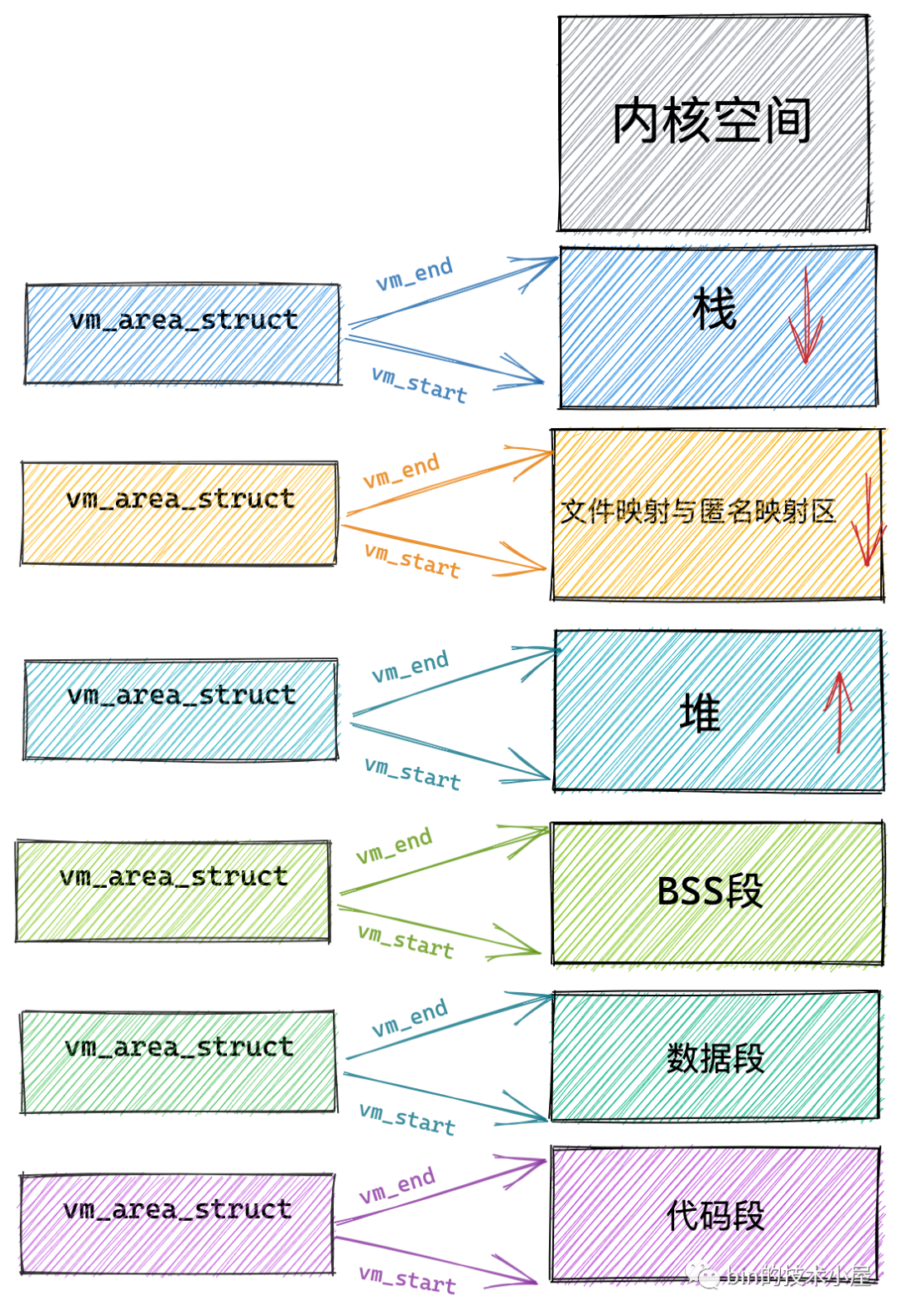
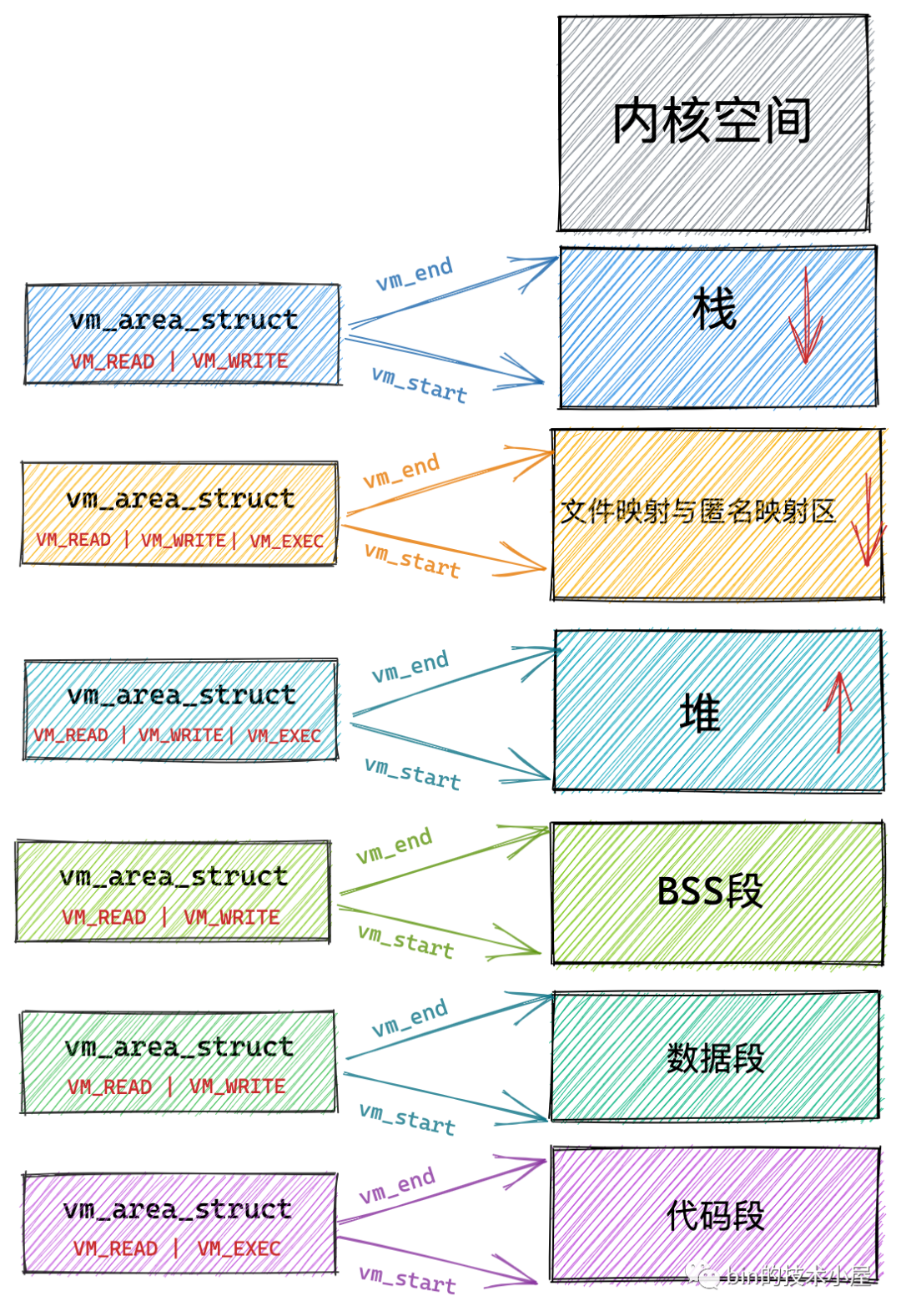
本小節中,筆者將為大家介紹一個新的結構體 vm_area_struct,正是這個結構體描述了這些虛擬記憶體區域 VMA(virtual memory area),
struct vm_area_struct {
unsigned long vm_start; /* Our start address within vm_mm. */
unsigned long vm_end; /* The first byte after our end address
within vm_mm. */
/*
* Access permissions of this VMA.
*/
pgprot_t vm_page_prot;
unsigned long vm_flags;
struct anon_vma *anon_vma; /* Serialized by page_table_lock */
struct file * vm_file; /* File we map to (can be NULL). */
unsigned long vm_pgoff; /* Offset (within vm_file) in PAGE_SIZE
units */
void * vm_private_data; /* was vm_pte (shared mem) */
/* Function pointers to deal with this struct. */
const struct vm_operations_struct *vm_ops;
}
每個 vm_area_struct 結構對應于虛擬記憶體空間中的唯一虛擬記憶體區域 VMA,vm_start 指向了這塊虛擬記憶體區域的起始地址(最低地址),vm_start 本身包含在這塊虛擬記憶體區域內,vm_end 指向了這塊虛擬記憶體區域的結束地址(最高地址),而 vm_end 本身包含在這塊虛擬記憶體區域之外,所以 vm_area_struct 結構描述的是 [vm_start,vm_end) 這樣一段左閉右開的虛擬記憶體區域,
5.4 定義虛擬記憶體區域的訪問權限和行為規范
vm_page_prot 和 vm_flags 都是用來標記 vm_area_struct 結構表示的這塊虛擬記憶體區域的訪問權限和行為規范,
上邊小節中我們也提到,內核會將整塊物理記憶體劃分為一頁一頁大小的區域,以頁為單位來管理這些物理記憶體,每頁大小默認 4K ,而虛擬記憶體最終也是要和物理記憶體一一映射起來的,所以在虛擬記憶體空間中也有虛擬頁的概念與之對應,虛擬記憶體中的虛擬頁映射到物理記憶體中的物理頁,無論是在虛擬記憶體空間中還是在物理記憶體中,內核管理記憶體的最小單位都是頁,
vm_page_prot 偏向于定義底層記憶體管理架構中頁這一級別的訪問控制權限,它可以直接應用在底層頁表中,它是一個具體的概念,
頁表用于管理虛擬記憶體到物理記憶體之間的映射關系,這部分內容筆者后續會詳細講解,這里大家有個初步的概念就行,
虛擬記憶體區域 VMA 由許多的虛擬頁 (page) 組成,每個虛擬頁需要經過頁表的轉換才能找到對應的物理頁面,頁表中關于記憶體頁的訪問權限就是由 vm_page_prot 決定的,
vm_flags 則偏向于定于整個虛擬記憶體區域的訪問權限以及行為規范,描述的是虛擬記憶體區域中的整體資訊,而不是虛擬記憶體區域中具體的某個獨立頁面,它是一個抽象的概念,可以通過 vma->vm_page_prot = vm_get_page_prot(vma->vm_flags) 實作到具體頁面訪問權限 vm_page_prot 的轉換,
下面筆者列舉一些常用到的 vm_flags 方便大家有一個直觀的感受:
| vm_flags | 訪問權限 |
|---|---|
| VM_READ | 可讀 |
| VM_WRITE | 可寫 |
| VM_EXEC | 可執行 |
| VM_SHARD | 可多行程之間共享 |
| VM_IO | 可映射至設備 IO 空間 |
| VM_RESERVED | 記憶體區域不可被換出 |
| VM_SEQ_READ | 記憶體區域可能被順序訪問 |
| VM_RAND_READ | 記憶體區域可能被隨機訪問 |
VM_READ,VM_WRITE,VM_EXEC 定義了虛擬記憶體區域是否可以被讀取,寫入,執行等權限,
比如代碼段這塊記憶體區域的權限是可讀,可執行,但是不可寫,資料段具有可讀可寫的權限但是不可執行,堆則具有可讀可寫,可執行的權限(Java 中的位元組碼存盤在堆中,所以需要可執行權限),堆疊一般是可讀可寫的權限,一般很少有可執行權限,而檔案映射與匿名映射區存放了共享鏈接庫,所以也需要可執行的權限,
VM_SHARD 用于指定這塊虛擬記憶體區域映射的物理記憶體是否可以在多行程之間共享,以便完成行程間通訊,
設定這個值即為 mmap 的共享映射,不設定的話則為私有映射,這個等后面我們講到 mmap 的相關實作時還會再次提起,
VM_IO 的設定表示這塊虛擬記憶體區域可以映射至設備 IO 空間中,通常在設備驅動程式執行 mmap 進行 IO 空間映射時才會被設定,
VM_RESERVED 的設定表示在記憶體緊張的時候,這塊虛擬記憶體區域非常重要,不能被換出到磁盤中,
VM_SEQ_READ 的設定用來暗示內核,應用程式對這塊虛擬記憶體區域的讀取是會采用順序讀的方式進行,內核會根據實際情況決定預讀后續的記憶體頁數,以便加快下次順序訪問速度,
VM_RAND_READ 的設定會暗示內核,應用程式會對這塊虛擬記憶體區域進行隨機讀取,內核則會根據實際情況減少預讀的記憶體頁數甚至停止預讀,
我們可以通過 posix_fadvise,madvise 系統呼叫來暗示內核是否對相關記憶體區域進行順序讀取或者隨機讀取,相關的詳細內容,大家可以看下筆者上篇文章 《從 Linux 內核角度探秘 JDK NIO 檔案讀寫本質》中的第 9 小節檔案頁預讀部分,
通過這一系列的介紹,我們可以看到 vm_flags 就是定義整個虛擬記憶體區域的訪問權限以及行為規范,而記憶體區域中記憶體的最小單位為頁(4K),虛擬記憶體區域中包含了很多這樣的虛擬頁,對于虛擬記憶體區域 VMA 設定的訪問權限也會全部復制到區域中包含的記憶體頁中,
5.5 關聯記憶體映射中的映射關系
接下來的三個屬性 anon_vma,vm_file,vm_pgoff 分別和虛擬記憶體映射相關,虛擬記憶體區域可以映射到物理記憶體上,也可以映射到檔案中,映射到物理記憶體上我們稱之為匿名映射,映射到檔案中我們稱之為檔案映射,
那么這個映射關系在內核中該如何表示呢?這就用到了 vm_area_struct 結構體中的上述三個屬性,
當我們呼叫 malloc 申請記憶體時,如果申請的是小塊記憶體(低于 128K)則會使用 do_brk() 系統呼叫通過調整堆中的 brk 指標大小來增加或者回收堆記憶體,
如果申請的是比較大塊的記憶體(超過 128K)時,則會呼叫 mmap 在上圖虛擬記憶體空間中的檔案映射與匿名映射區創建出一塊 VMA 記憶體區域(這里是匿名映射),這塊匿名映射區域就用 struct anon_vma 結構表示,
當呼叫 mmap 進行檔案映射時,vm_file 屬性就用來關聯被映射的檔案,這樣一來虛擬記憶體區域就與映射檔案關聯了起來,vm_pgoff 則表示映射進虛擬記憶體中的檔案內容,在檔案中的偏移,
當然在匿名映射中,vm_area_struct 結構中的 vm_file 就為 null,vm_pgoff 也就沒有了意義,
vm_private_data 則用于存盤 VMA 中的私有資料,具體的存盤內容和記憶體映射的型別有關,我們暫不展開論述,
5.6 針對虛擬記憶體區域的相關操作
struct vm_area_struct 結構中還有一個 vm_ops 用來指向針對虛擬記憶體區域 VMA 的相關操作的函式指標,
struct vm_operations_struct {
void (*open)(struct vm_area_struct * area);
void (*close)(struct vm_area_struct * area);
vm_fault_t (*fault)(struct vm_fault *vmf);
vm_fault_t (*page_mkwrite)(struct vm_fault *vmf);
..... 省略 .......
}
-
當指定的虛擬記憶體區域被加入到行程虛擬記憶體空間中時,open 函式會被呼叫
-
當虛擬記憶體區域 VMA 從行程虛擬記憶體空間中被洗掉時,close 函式會被呼叫
-
當行程訪問虛擬記憶體時,訪問的頁面不在物理記憶體中,可能是未分配物理記憶體也可能是被置換到磁盤中,這時就會產生缺頁例外,fault 函式就會被呼叫,
-
當一個只讀的頁面將要變為可寫時,page_mkwrite 函式會被呼叫,
struct vm_operations_struct 結構中定義的都是對虛擬記憶體區域 VMA 的相關操作函式指標,
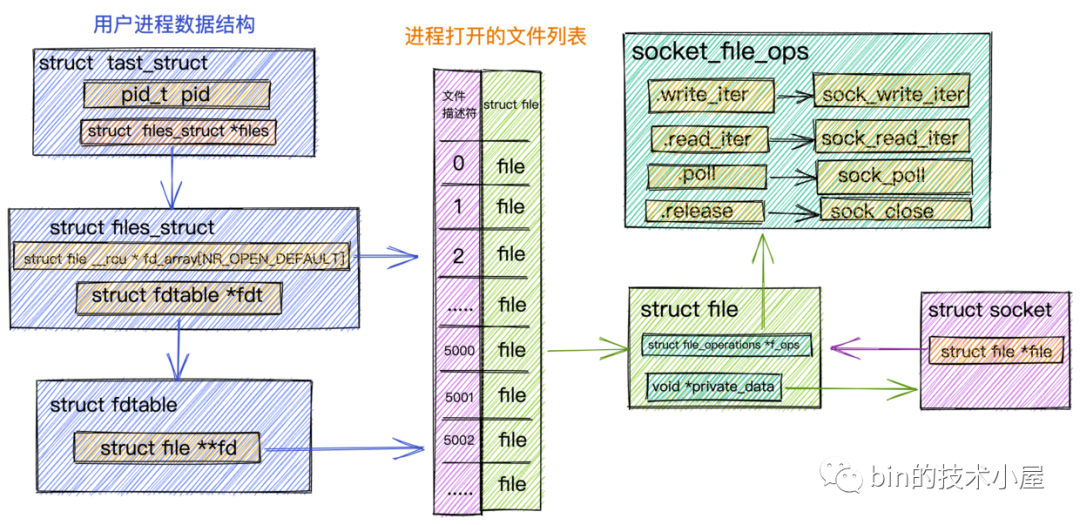
內核中這種類似的用法其實有很多,在內核中每個特定領域的描述符都會定義相關的操作,比如在前邊的文章 《從 Linux 內核角度探秘 JDK NIO 檔案讀寫本質》 中我們介紹到內核中的檔案描述符 struct file 中定義的 struct file_operations *f_op,里面定義了內核針對檔案操作的函式指標,具體的實作根據不同的檔案型別有所不同,
針對 Socket 檔案型別,這里的 file_operations 指向的是 socket_file_ops,
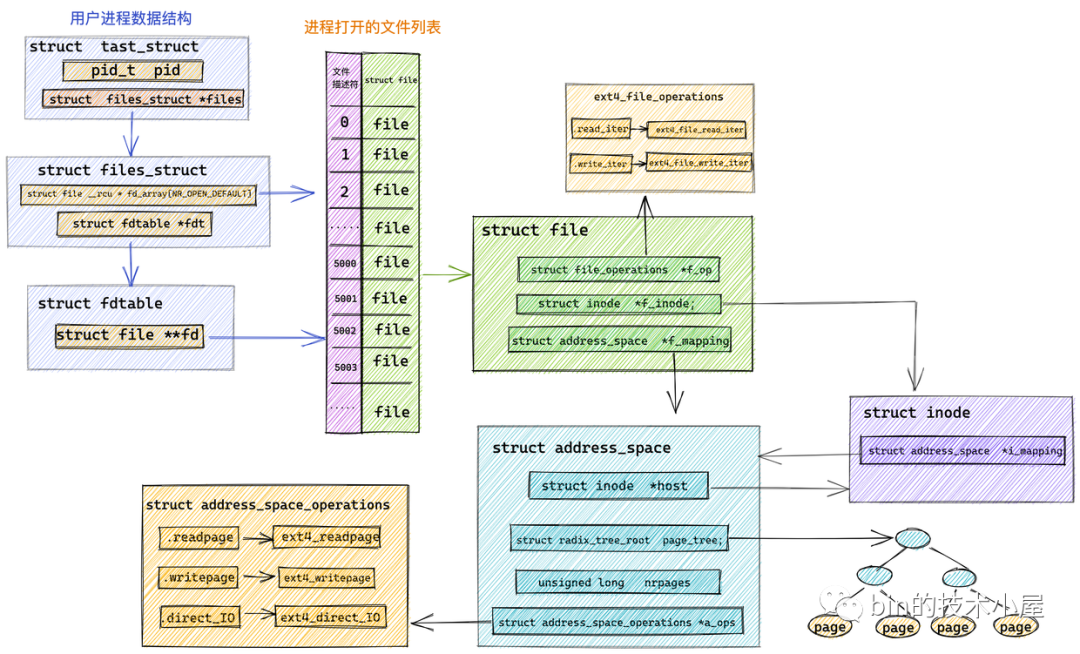
在 ext4 檔案系統中管理的檔案對應的 file_operations 指向 ext4_file_operations,專門用于操作 ext4 檔案系統中的檔案,還有針對 page cache 頁高速快取相關操作定義的 address_space_operations ,
還有我們在 《從 Linux 內核角度看 IO 模型的演變》一文中介紹到,socket 相關的操作介面定義在 inet_stream_ops 函式集合中,負責對上給用戶提供介面,而 socket 與內核協議堆疊之間的操作介面定義在 struct sock 中的 sk_prot 指標上,這里指向 tcp_prot 協議操作函式集合,
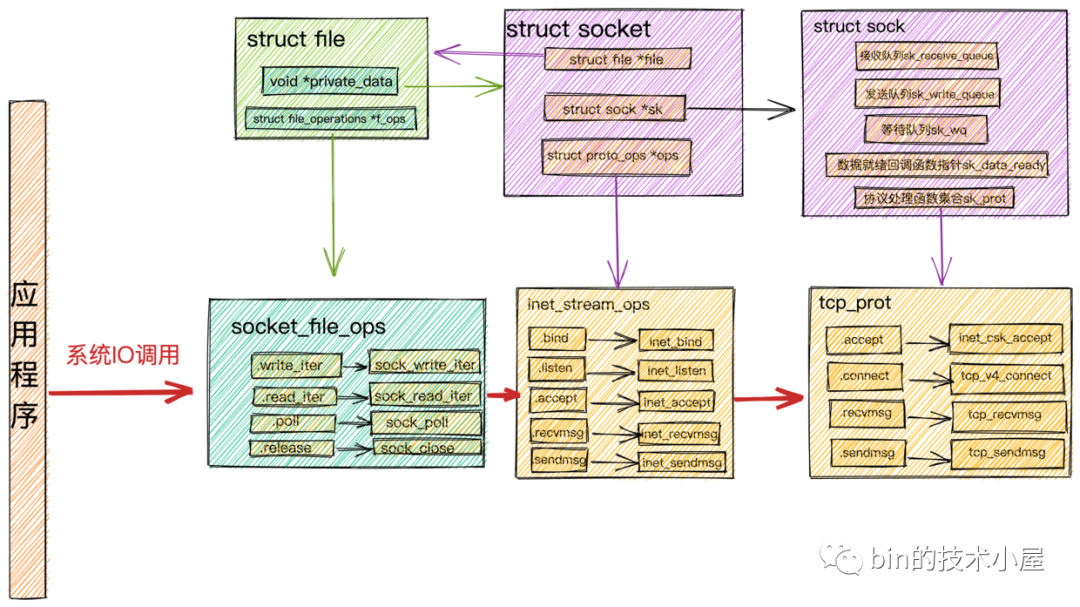
對 socket 發起的系統 IO 呼叫時,在內核中首先會呼叫 socket 的檔案結構 struct file 中的 file_operations 檔案操作集合,然后呼叫 struct socket 中的 ops 指向的 inet_stream_opssocket 操作函式,最終呼叫到 struct sock 中 sk_prot 指標指向的 tcp_prot 內核協議堆疊操作函式介面集合,
5.7 虛擬記憶體區域在內核中是如何被組織的
在上一小節中,我們介紹了內核中用來表示虛擬記憶體區域 VMA 的結構體 struct vm_area_struct ,并詳細為大家剖析了 struct vm_area_struct 中的一些重要的關鍵屬性,
現在我們已經熟悉了這些虛擬記憶體區域,那么接下來的問題就是在內核中這些虛擬記憶體區域是如何被組織的呢?
我們繼續來到 struct vm_area_struct 結構中,來看一下與組織結構相關的一些屬性:
struct vm_area_struct {
struct vm_area_struct *vm_next, *vm_prev;
struct rb_node vm_rb;
struct list_head anon_vma_chain;
struct mm_struct *vm_mm; /* The address space we belong to. */
unsigned long vm_start; /* Our start address within vm_mm. */
unsigned long vm_end; /* The first byte after our end address
within vm_mm. */
/*
* Access permissions of this VMA.
*/
pgprot_t vm_page_prot;
unsigned long vm_flags;
struct anon_vma *anon_vma; /* Serialized by page_table_lock */
struct file * vm_file; /* File we map to (can be NULL). */
unsigned long vm_pgoff; /* Offset (within vm_file) in PAGE_SIZE
units */
void * vm_private_data; /* was vm_pte (shared mem) */
/* Function pointers to deal with this struct. */
const struct vm_operations_struct *vm_ops;
}
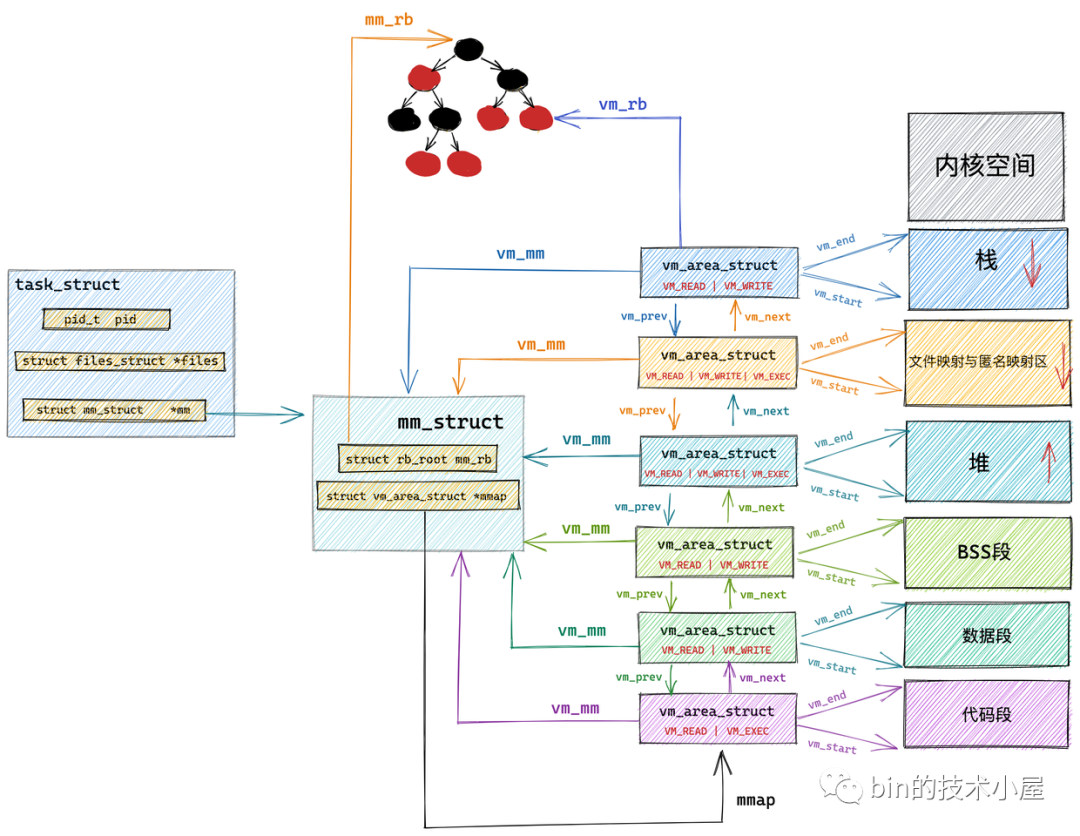
在內核中其實是通過一個 struct vm_area_struct 結構的雙向鏈表將虛擬記憶體空間中的這些虛擬記憶體區域 VMA 串聯起來的,
vm_area_struct 結構中的 vm_next ,vm_prev 指標分別指向 VMA 節點所在雙向鏈表中的后繼節點和前驅節點,內核中的這個 VMA 雙向鏈表是有順序的,所有 VMA 節點按照低地址到高地址的增長方向排序,
雙向鏈表中的最后一個 VMA 節點的 vm_next 指標指向 NULL,雙向鏈表的頭指標存盤在記憶體描述符 struct mm_struct 結構中的 mmap 中,正是這個 mmap 串聯起了整個虛擬記憶體空間中的虛擬記憶體區域,
struct mm_struct {
struct vm_area_struct *mmap; /* list of VMAs */
}
在每個虛擬記憶體區域 VMA 中又通過 struct vm_area_struct 中的 vm_mm 指標指向了所屬的虛擬記憶體空間 mm_struct,
我們可以通過 cat /proc/pid/maps 或者 pmap pid 查看行程的虛擬記憶體空間布局以及其中包含的所有記憶體區域,這兩個命令背后的實作原理就是通過遍歷內核中的這個 vm_area_struct 雙向鏈表獲取的,
內核中關于這些虛擬記憶體區域的操作除了遍歷之外還有許多需要根據特定虛擬記憶體地址在虛擬記憶體空間中查找特定的虛擬記憶體區域,
尤其在行程虛擬記憶體空間中包含的記憶體區域 VMA 比較多的情況下,使用紅黑樹查找特定虛擬記憶體區域的時間復雜度是 O( logN ) ,可以顯著減少查找所需的時間,
所以在內核中,同樣的記憶體區域 vm_area_struct 會有兩種組織形式,一種是雙向鏈表用于高效的遍歷,另一種就是紅黑樹用于高效的查找,
每個 VMA 區域都是紅黑樹中的一個節點,通過 struct vm_area_struct 結構中的 vm_rb 將自己連接到紅黑樹中,
而紅黑樹中的根節點存盤在記憶體描述符 struct mm_struct 中的 mm_rb 中:
struct mm_struct {
struct rb_root mm_rb;
}
6. 程式編譯后的二進制檔案如何映射到虛擬記憶體空間中
經過前邊這么多小節的內容介紹,現在我們已經熟悉了行程虛擬記憶體空間的布局,以及內核如何管理這些虛擬記憶體區域,并對行程的虛擬記憶體空間有了一個完整全面的認識,
現在我們再來回到最初的起點,行程的虛擬記憶體空間 mm_struct 以及這些虛擬記憶體區域 vm_area_struct 是如何被創建并初始化的呢?
在 《3. 行程虛擬記憶體空間》小節中,我們介紹行程的虛擬記憶體空間時提到,我們寫的程式代碼編譯之后會生成一個 ELF 格式的二進制檔案,這個二進制檔案中包含了程式運行時所需要的元資訊,比如程式的機器碼,程式中的全域變數以及靜態變數等,
這個 ELF 格式的二進制檔案中的布局和我們前邊講的虛擬記憶體空間中的布局類似,也是一段一段的,每一段包含了不同的元資料,
磁盤檔案中的段我們叫做 Section,記憶體中的段我們叫做 Segment,也就是記憶體區域,
磁盤檔案中的這些 Section 會在行程運行之前加載到記憶體中并映射到記憶體中的 Segment,通常是多個 Section 映射到一個 Segment,
比如磁盤檔案中的 .text,.rodata 等一些只讀的 Section,會被映射到記憶體的一個只讀可執行的 Segment 里(代碼段),而 .data,.bss 等一些可讀寫的 Section,則會被映射到記憶體的一個具有讀寫權限的 Segment 里(資料段,BSS 段),
那么這些 ELF 格式的二進制檔案中的 Section 是如何加載并映射進虛擬記憶體空間的呢?
內核中完成這個映射程序的函式是 load_elf_binary ,這個函式的作用很大,加載內核的是它,啟動第一個用戶態行程 init 的是它,fork 完了以后,呼叫 exec 運行一個二進制程式的也是它,當 exec 運行一個二進制程式的時候,除了決議 ELF 的格式之外,另外一個重要的事情就是建立上述提到的記憶體映射,
static int load_elf_binary(struct linux_binprm *bprm)
{
...... 省略 ........
// 設定虛擬記憶體空間中的記憶體映射區域起始地址 mmap_base
setup_new_exec(bprm);
...... 省略 ........
// 創建并初始化堆疊對應的 vm_area_struct 結構,
// 設定 mm->start_stack 就是堆疊的起始地址也就是堆疊底,并將 mm->arg_start 是指向堆疊底的,
retval = setup_arg_pages(bprm, randomize_stack_top(STACK_TOP),
executable_stack);
...... 省略 ........
// 將二進制檔案中的代碼部分映射到虛擬記憶體空間中
error = elf_map(bprm->file, load_bias + vaddr, elf_ppnt,
elf_prot, elf_flags, total_size);
...... 省略 ........
// 創建并初始化堆對應的的 vm_area_struct 結構
// 設定 current->mm->start_brk = current->mm->brk,設定堆的起始地址 start_brk,結束地址 brk, 起初兩者相等表示堆是空的
retval = set_brk(elf_bss, elf_brk, bss_prot);
...... 省略 ........
// 將行程依賴的元件 .so 檔案映射到虛擬記憶體空間中的記憶體映射區域
elf_entry = load_elf_interp(&loc->interp_elf_ex,
interpreter,
&interp_map_addr,
load_bias, interp_elf_phdata);
...... 省略 ........
// 初始化記憶體描述符 mm_struct
current->mm->end_code = end_code;
current->mm->start_code = start_code;
current->mm->start_data = https://www.cnblogs.com/binlovetech/archive/2022/10/25/start_data;
current->mm->end_data = end_data;
current->mm->start_stack = bprm->p;
...... 省略 ........
}
-
setup_new_exec 設定虛擬記憶體空間中的記憶體映射區域起始地址 mmap_base
-
setup_arg_pages 創建并初始化堆疊對應的 vm_area_struct 結構,置 mm->start_stack 就是堆疊的起始地址也就是堆疊底,并將 mm->arg_start 是指向堆疊底的,
-
elf_map 將 ELF 格式的二進制檔案中.text ,.data,.bss 部分映射到虛擬記憶體空間中的代碼段,資料段,BSS 段中,
-
set_brk 創建并初始化堆對應的的 vm_area_struct 結構,設定
current->mm->start_brk = current->mm->brk,設定堆的起始地址 start_brk,結束地址 brk, 起初兩者相等表示堆是空的, -
load_elf_interp 將行程依賴的元件 .so 檔案映射到虛擬記憶體空間中的記憶體映射區域
-
初始化記憶體描述符 mm_struct
7. 內核虛擬記憶體空間
現在我們已經知道了行程虛擬記憶體空間在內核中的布局以及管理,那么內核態的虛擬記憶體空間又是什么樣子的呢?本小節筆者就帶大家來一層一層地拆開這個黑盒子,
之前在介紹行程虛擬記憶體空間的時候,筆者提到不同行程之間的虛擬記憶體空間是相互隔離的,彼此之間相互獨立,相互感知不到其他行程的存在,使得行程以為自己擁有所有的記憶體資源,
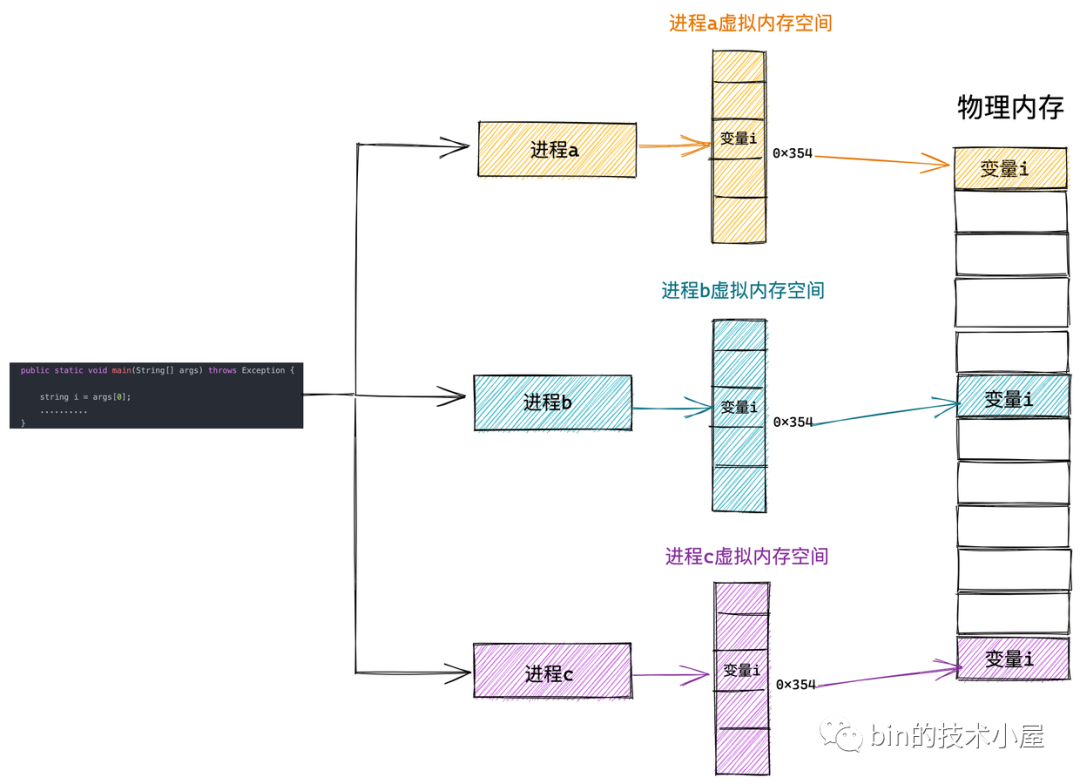
而內核態虛擬記憶體空間是所有行程共享的,不同行程進入內核態之后看到的虛擬記憶體空間全部是一樣的,
什么意思呢?比如上圖中的行程 a,行程 b,行程 c 分別在各自的用戶態虛擬記憶體空間中訪問虛擬地址 x ,由于行程之間的用戶態虛擬記憶體空間是相互隔離相互獨立的,雖然在行程a,行程b,行程c 訪問的都是虛擬地址 x 但是看到的內容卻是不一樣的(背后可能映射到不同的物理記憶體中),
但是當行程 a,行程 b,行程 c 進入到內核態之后情況就不一樣了,由于內核虛擬記憶體空間是各個行程共享的,所以它們在內核空間中看到的內容全部是一樣的,比如行程 a,行程 b,行程 c 在內核態都去訪問虛擬地址 y,這時它們看到的內容就是一樣的了,
這里筆者和大家澄清一個經常被誤解的概念:由于內核會涉及到物理記憶體的管理,所以很多人會想當然地認為只要進入了內核態就開始使用物理地址了,這就大錯特錯了,千萬不要這樣理解,行程進入內核態之后使用的仍然是虛擬記憶體地址,只不過在內核中使用的虛擬記憶體地址被限制在了內核態虛擬記憶體空間范圍中,這也是本小節筆者要為大家介紹的主題,
在清楚了這個基本概念之后,下面筆者分別從 32 位體系 和 64 位體系下為大家介紹內核態虛擬記憶體空間的布局,
7.1 32 位體系內核虛擬記憶體空間布局
在前邊《5.1 內核如何劃分用戶態和內核態虛擬記憶體空間》小節中我們提到,內核在 /arch/x86/include/asm/page_32_types.h 檔案中通過 TASK_SIZE 將行程虛擬記憶體空間和內核虛擬記憶體空間分割開來,
/*
* User space process size: 3GB (default).
*/
#define TASK_SIZE __PAGE_OFFSET
__PAGE_OFFSET 的值在 32 位系統下為 0xC000 000
在 32 位體系結構下行程用戶態虛擬記憶體空間為 3 GB,虛擬記憶體地址范圍為:0x0000 0000 - 0xC000 000 ,內核態虛擬記憶體空間為 1 GB,虛擬記憶體地址范圍為:0xC000 000 - 0xFFFF FFFF,
本小節我們主要關注 0xC000 000 - 0xFFFF FFFF 這段虛擬記憶體地址區域也就是內核虛擬記憶體空間的布局情況,
7.1.1 直接映射區
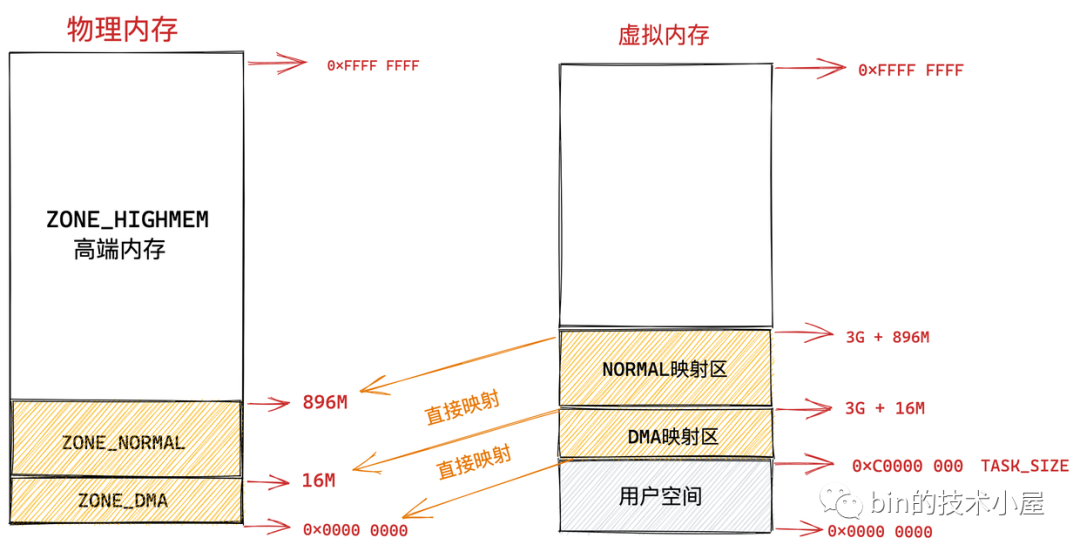
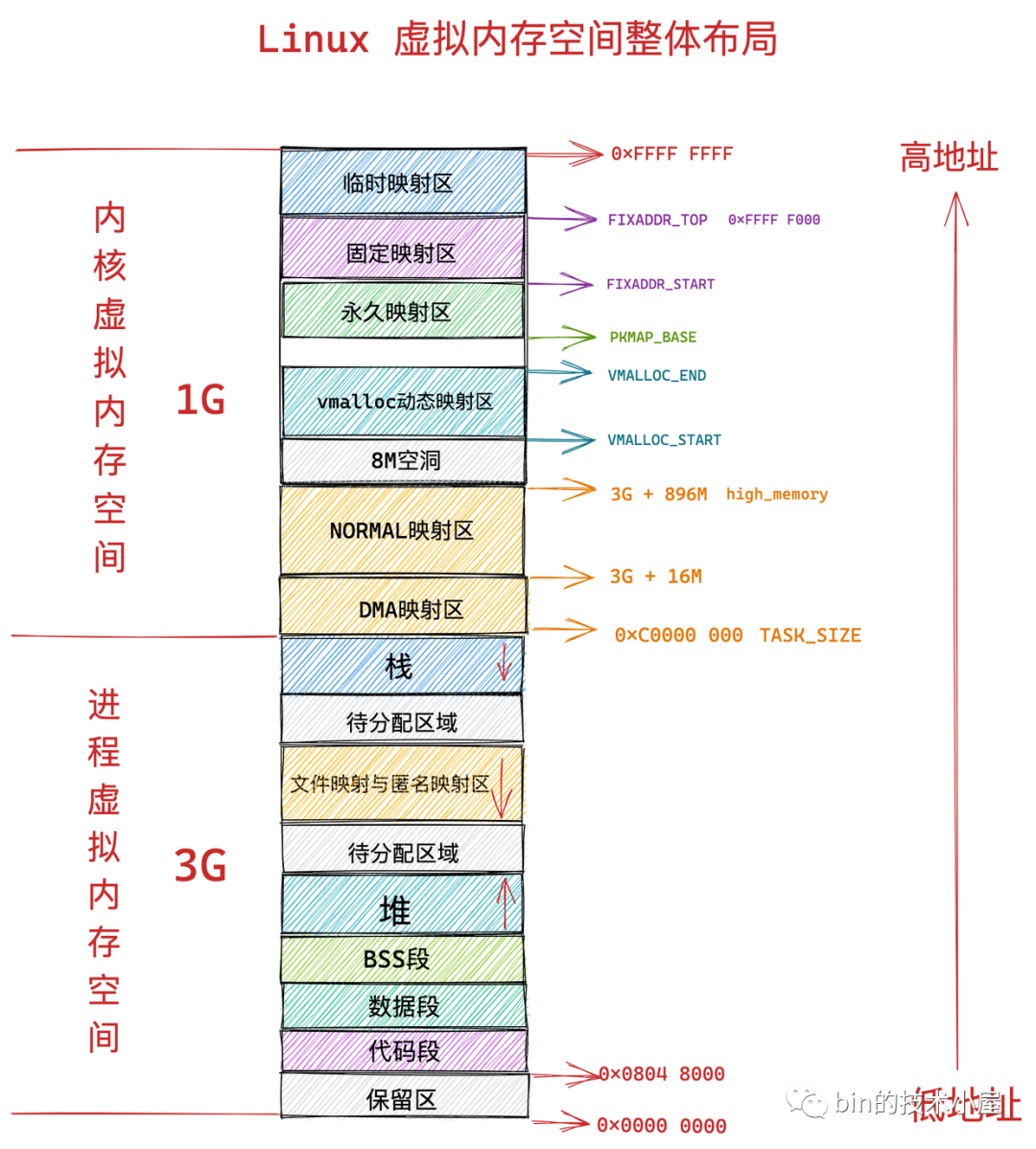
在總共大小 1G 的內核虛擬記憶體空間中,位于最前邊有一塊 896M 大小的區域,我們稱之為直接映射區或者線性映射區,地址范圍為 3G -- 3G + 896m ,
之所以這塊 896M 大小的區域稱為直接映射區或者線性映射區,是因為這塊連續的虛擬記憶體地址會映射到 0 - 896M 這塊連續的物理記憶體上,
也就是說 3G -- 3G + 896m 這塊 896M 大小的虛擬記憶體會直接映射到 0 - 896M 這塊 896M 大小的物理記憶體上,這塊區域中的虛擬記憶體地址直接減去 0xC000 0000 (3G) 就得到了物理記憶體地址,所以我們稱這塊區域為直接映射區,
為了方便為大家解釋,我們假設現在機器上的物理記憶體為 4G 大小
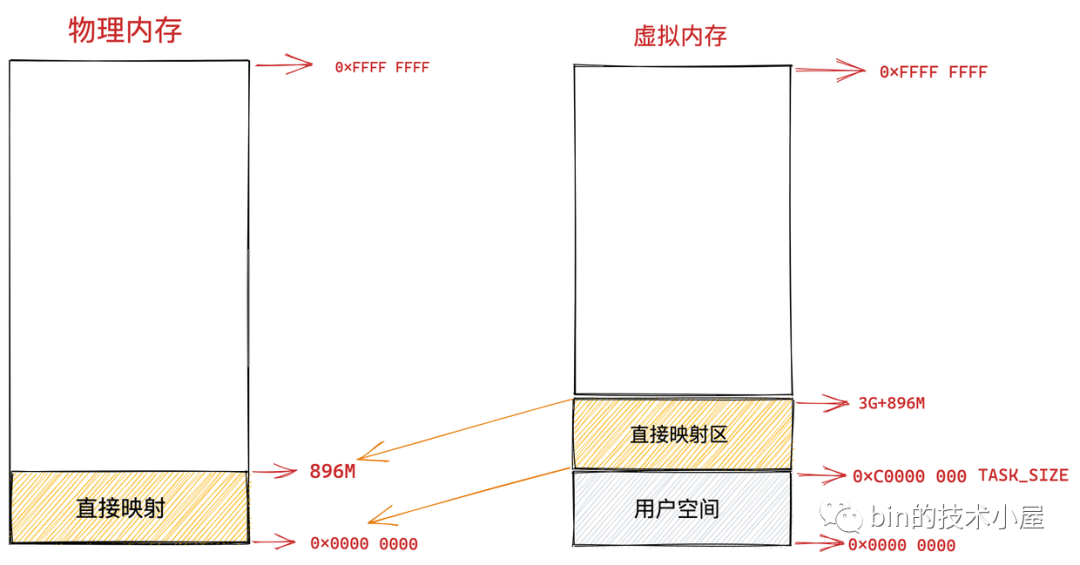
雖然這塊區域中的虛擬地址是直接映射到物理地址上,但是內核在訪問這段區域的時候還是走的虛擬記憶體地址,內核也會為這塊空間建立映射頁表,關于頁表的概念筆者后續會為大家詳細講解,這里大家只需要簡單理解為頁表保存了虛擬地址到物理地址的映射關系即可,
大家這里只需要記得內核態虛擬記憶體空間的前 896M 區域是直接映射到物理記憶體中的前 896M 區域中的,直接映射區中的映射關系是一比一映射,映射關系是固定的不會改變,
明白了這個關系之后,我們接下來就看一下這塊直接映射區域在物理記憶體中究竟存的是什么內容~~~
在這段 896M 大小的物理記憶體中,前 1M 已經在系統啟動的時候被系統占用,1M 之后的物理記憶體存放的是內核代碼段,資料段,BSS 段(這些資訊起初存放在 ELF格式的二進制檔案中,在系統啟動的時候被加載進記憶體),
我們可以通過
cat /proc/iomem命令查看具體物理記憶體布局情況,
當我們使用 fork 系統呼叫創建行程的時候,內核會創建一系列行程相關的描述符,比如之前提到的行程的核心資料結構 task_struct,行程的記憶體空間描述符 mm_struct,以及虛擬記憶體區域描述符 vm_area_struct 等,
這些行程相關的資料結構也會存放在物理記憶體前 896M 的這段區域中,當然也會被直接映射至內核態虛擬記憶體空間中的 3G -- 3G + 896m 這段直接映射區域中,
當行程被創建完畢之后,在內核運行的程序中,會涉及內核堆疊的分配,內核會為每個行程分配一個固定大小的內核堆疊(一般是兩個頁大小,依賴具體的體系結構),每個行程的整個呼叫鏈必須放在自己的內核堆疊中,內核堆疊也是分配在直接映射區,
與行程用戶空間中的堆疊不同的是,內核堆疊容量小而且是固定的,用戶空間中的堆疊容量大而且可以動態擴展,內核堆疊的溢位危害非常巨大,它會直接悄無聲息的覆寫相鄰記憶體區域中的資料,破壞資料,
通過以上內容的介紹我們了解到內核虛擬記憶體空間最前邊的這段 896M 大小的直接映射區如何與物理記憶體進行映射關聯,并且清楚了直接映射區主要用來存放哪些內容,
寫到這里,筆者覺得還是有必要再次從功能劃分的角度為大家介紹下這塊直接映射區域,
我們都知道內核對物理記憶體的管理都是以頁為最小單位來管理的,每頁默認 4K 大小,理想狀況下任何種類的資料頁都可以存放在任何頁框中,沒有什么限制,比如:存放內核資料,用戶資料,緩沖磁盤資料等,
但是實際的計算機體系結構受到硬體方面的限制制約,間接導致限制了頁框的使用方式,
比如在 X86 體系結構下,ISA 總線的 DMA (直接記憶體存取)控制器,只能對記憶體的前16M 進行尋址,這就導致了 ISA 設備不能在整個 32 位地址空間中執行 DMA,只能使用物理記憶體的前 16M 進行 DMA 操作,
因此直接映射區的前 16M 專門讓內核用來為 DMA 分配記憶體,這塊 16M 大小的記憶體區域我們稱之為 ZONE_DMA,
用于 DMA 的記憶體必須從 ZONE_DMA 區域中分配,
而直接映射區中剩下的部分也就是從 16M 到 896M(不包含 896M)這段區域,我們稱之為 ZONE_NORMAL,從字面意義上我們可以了解到,這塊區域包含的就是正常的頁框(使用沒有任何限制),
ZONE_NORMAL 由于也是屬于直接映射區的一部分,對應的物理記憶體 16M 到 896M 這段區域也是被直接映射至內核態虛擬記憶體空間中的 3G + 16M 到 3G + 896M 這段虛擬記憶體上,
注意這里的 ZONE_DMA 和 ZONE_NORMAL 是內核針對物理記憶體區域的劃分,
現在物理記憶體中的前 896M 的區域也就是前邊介紹的 ZONE_DMA 和 ZONE_NORMAL 區域到內核虛擬記憶體空間的映射筆者就為大家介紹完了,它們都是采用直接映射的方式,一比一就行映射,
7.1.2 ZONE_HIGHMEM 高端記憶體
而物理記憶體 896M 以上的區域被內核劃分為 ZONE_HIGHMEM 區域,我們稱之為高端記憶體,
本例中我們的物理記憶體假設為 4G,高端記憶體區域為 4G - 896M = 3200M,那么這塊 3200M 大小的 ZONE_HIGHMEM 區域該如何映射到內核虛擬記憶體空間中呢?
由于內核虛擬記憶體空間中的前 896M 虛擬記憶體已經被直接映射區所占用,而在 32 體系結構下內核虛擬記憶體空間總共也就 1G 的大小,這樣一來內核剩余可用的虛擬記憶體空間就變為了 1G - 896M = 128M,
顯然物理記憶體中 3200M 大小的 ZONE_HIGHMEM 區域無法繼續通過直接映射的方式映射到這 128M 大小的虛擬記憶體空間中,
這樣一來物理記憶體中的 ZONE_HIGHMEM 區域就只能采用動態映射的方式映射到 128M 大小的內核虛擬記憶體空間中,也就是說只能動態的一部分一部分的分批映射,先映射正在使用的這部分,使用完畢解除映射,接著映射其他部分,
知道了 ZONE_HIGHMEM 區域的映射原理,我們接著往下看這 128M 大小的內核虛擬記憶體空間究竟是如何布局的?
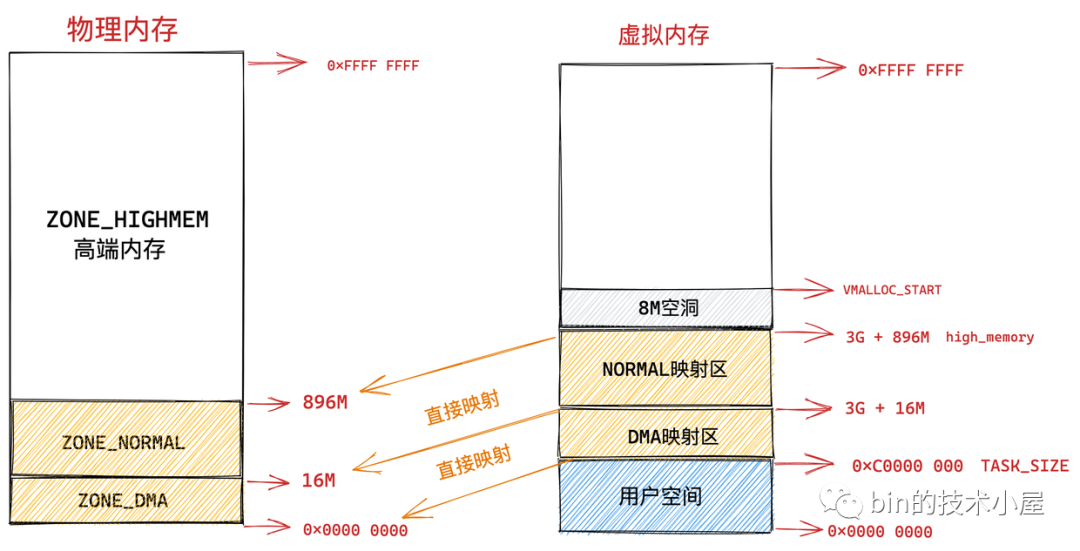
內核虛擬記憶體空間中的 3G + 896M 這塊地址在內核中定義為 high_memory,high_memory 往上有一段 8M 大小的記憶體空洞,空洞范圍為:high_memory 到 VMALLOC_START ,
VMALLOC_START 定義在內核原始碼 /arch/x86/include/asm/pgtable_32_areas.h 檔案中:
#define VMALLOC_OFFSET (8 * 1024 * 1024)
#define VMALLOC_START ((unsigned long)high_memory + VMALLOC_OFFSET)
7.1.3 vmalloc 動態映射區
接下來 VMALLOC_START 到 VMALLOC_END 之間的這塊區域成為動態映射區,采用動態映射的方式映射物理記憶體中的高端記憶體,
#ifdef CONFIG_HIGHMEM
# define VMALLOC_END (PKMAP_BASE - 2 * PAGE_SIZE)
#else
# define VMALLOC_END (LDT_BASE_ADDR - 2 * PAGE_SIZE)
#endif
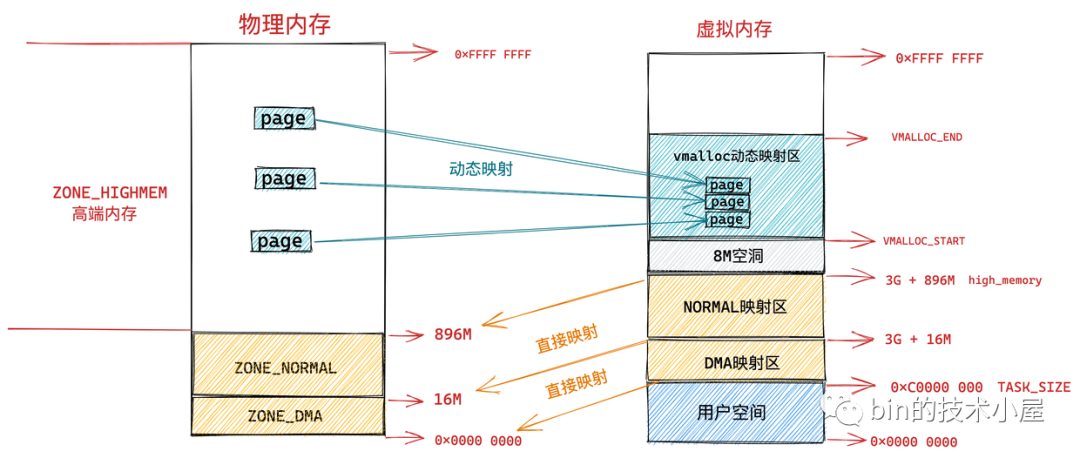
和用戶態行程使用 malloc 申請記憶體一樣,在這塊動態映射區內核是使用 vmalloc 進行記憶體分配,由于之前介紹的動態映射的原因,vmalloc 分配的記憶體在虛擬記憶體上是連續的,但是物理記憶體是不連續的,通過頁表來建立物理記憶體與虛擬記憶體之間的映射關系,從而可以將不連續的物理記憶體映射到連續的虛擬記憶體上,
由于 vmalloc 獲得的物理記憶體頁是不連續的,因此它只能將這些物理記憶體頁一個一個地進行映射,在性能開銷上會比直接映射大得多,
關于 vmalloc 分配記憶體的相關實作原理,筆者會在后面的文章中為大家講解,這里大家只需要明白它在哪塊虛擬記憶體區域中活動即可,
7.1.4 永久映射區
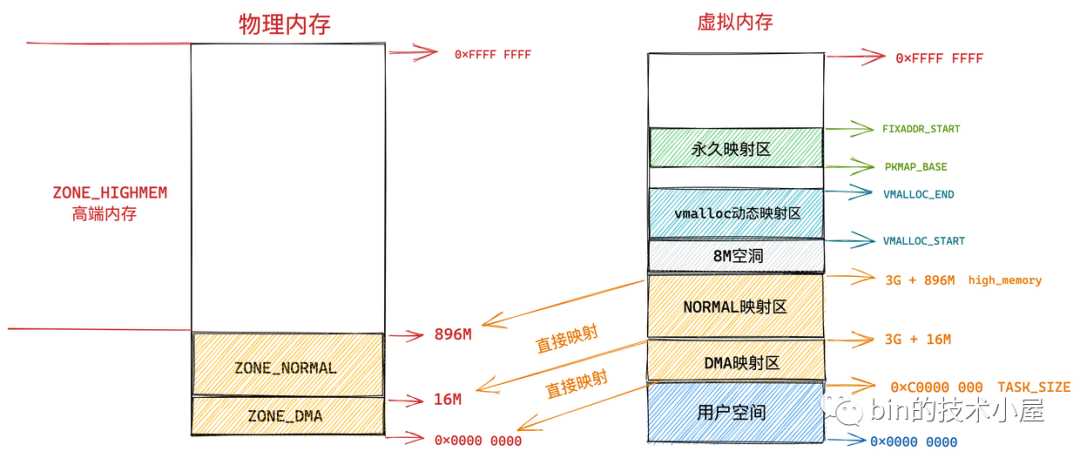
而在 PKMAP_BASE 到 FIXADDR_START 之間的這段空間稱為永久映射區,在內核的這段虛擬地址空間中允許建立與物理高端記憶體的長期映射關系,比如內核通過 alloc_pages() 函式在物理記憶體的高端記憶體中申請獲取到的物理記憶體頁,這些物理記憶體頁可以通過呼叫 kmap 映射到永久映射區中,
LAST_PKMAP 表示永久映射區可以映射的頁數限制,
#define PKMAP_BASE \
((LDT_BASE_ADDR - PAGE_SIZE) & PMD_MASK)
#define LAST_PKMAP 1024
8.1.5 固定映射區
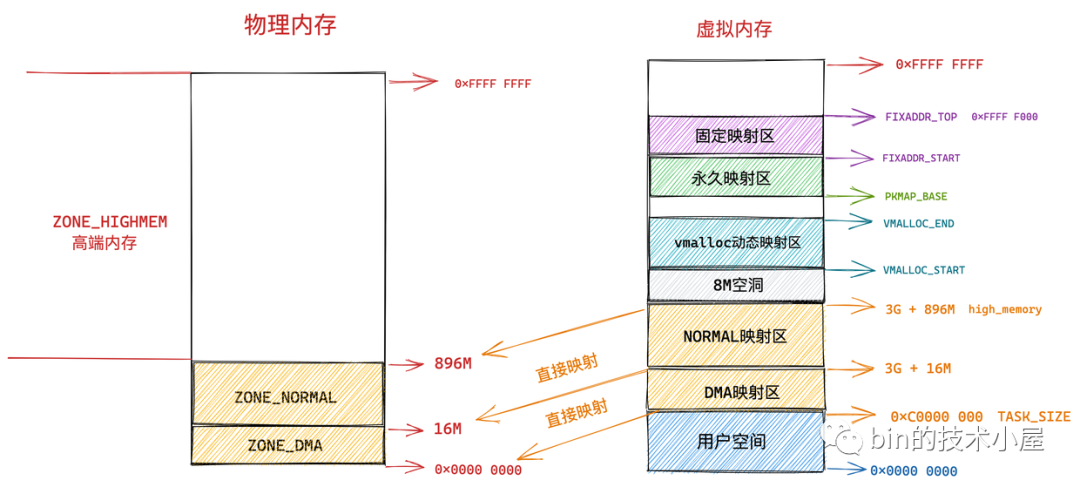
內核虛擬記憶體空間中的下一個區域為固定映射區,區域范圍為:FIXADDR_START 到 FIXADDR_TOP,
FIXADDR_START 和 FIXADDR_TOP 定義在內核原始碼 /arch/x86/include/asm/fixmap.h 檔案中:
#define FIXADDR_START (FIXADDR_TOP - FIXADDR_SIZE)
extern unsigned long __FIXADDR_TOP; // 0xFFFF F000
#define FIXADDR_TOP ((unsigned long)__FIXADDR_TOP)
在內核虛擬記憶體空間的直接映射區中,直接映射區中的虛擬記憶體地址與物理記憶體前 896M 的空間的映射關系都是預設好的,一比一映射,
在固定映射區中的虛擬記憶體地址可以自由映射到物理記憶體的高端地址上,但是與動態映射區以及永久映射區不同的是,在固定映射區中虛擬地址是固定的,而被映射的物理地址是可以改變的,也就是說,有些虛擬地址在編譯的時候就固定下來了,是在內核啟動程序中被確定的,而這些虛擬地址對應的物理地址不是固定的,采用固定虛擬地址的好處是它相當于一個指標常量(常量的值在編譯時確定),指向物理地址,如果虛擬地址不固定,則相當于一個指標變數,
那為什么會有固定映射這個概念呢 ? 比如:在內核的啟動程序中,有些模塊需要使用虛擬記憶體并映射到指定的物理地址上,而且這些模塊也沒有辦法等待完整的記憶體管理模塊初始化之后再進行地址映射,因此,內核固定分配了一些虛擬地址,這些地址有固定的用途,使用該地址的模塊在初始化的時候,將這些固定分配的虛擬地址映射到指定的物理地址上去,
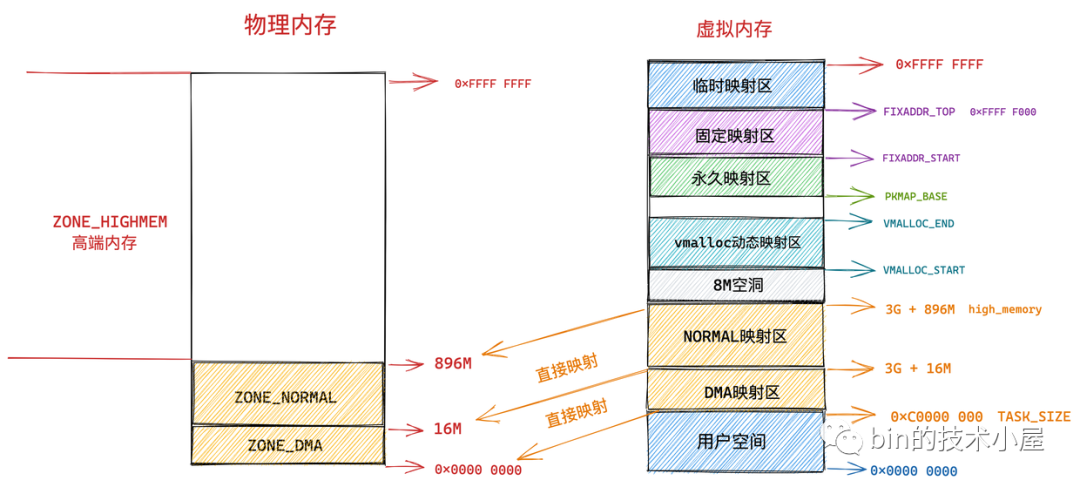
7.1.6 臨時映射區
在內核虛擬記憶體空間中的最后一塊區域為臨時映射區,那么這塊臨時映射區是用來干什么的呢?
筆者在之前文章 《從 Linux 內核角度探秘 JDK NIO 檔案讀寫本質》 的 “ 12.3 iov_iter_copy_from_user_atomic ” 小節中介紹在 Buffered IO 模式下進行檔案寫入的時候,在下圖中的第四步,內核會呼叫 iov_iter_copy_from_user_atomic 函式將用戶空間緩沖區 DirectByteBuffer 中的待寫入資料拷貝到 page cache 中,
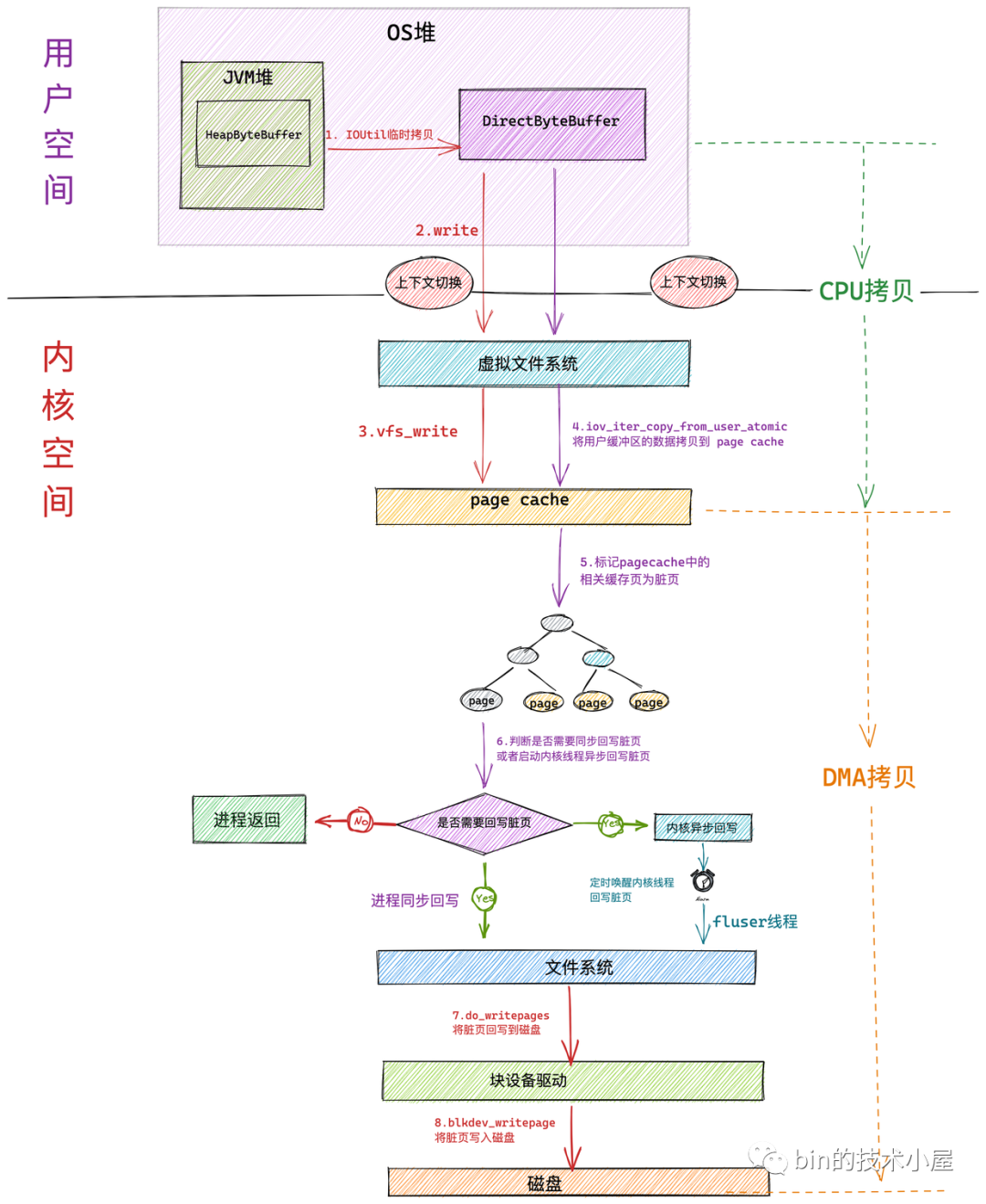
但是內核又不能直接進行拷貝,因為此時從 page cache 中取出的快取頁 page 是物理地址,而在內核中是不能夠直接操作物理地址的,只能操作虛擬地址,
那怎么辦呢?所以就需要使用 kmap_atomic 將快取頁臨時映射到內核空間的一段虛擬地址上,這段虛擬地址就位于內核虛擬記憶體空間中的臨時映射區上,然后將用戶空間快取區 DirectByteBuffer 中的待寫入資料通過這段映射的虛擬地址拷貝到 page cache 中的相應快取頁中,這時檔案的寫入操作就已經完成了,
由于是臨時映射,所以在拷貝完成之后,呼叫 kunmap_atomic 將這段映射再解除掉,
size_t iov_iter_copy_from_user_atomic(struct page *page,
struct iov_iter *i, unsigned long offset, size_t bytes)
{
// 將快取頁臨時映射到內核虛擬地址空間的臨時映射區中
char *kaddr = kmap_atomic(page),
*p = kaddr + offset;
// 將用戶快取區 DirectByteBuffer 中的待寫入資料拷貝到檔案快取頁中
iterate_all_kinds(i, bytes, v,
copyin((p += v.iov_len) - v.iov_len, v.iov_base, v.iov_len),
memcpy_from_page((p += v.bv_len) - v.bv_len, v.bv_page,
v.bv_offset, v.bv_len),
memcpy((p += v.iov_len) - v.iov_len, v.iov_base, v.iov_len)
)
// 解除內核虛擬地址空間與快取頁之間的臨時映射,這里映射只是為了臨時拷貝資料用
kunmap_atomic(kaddr);
return bytes;
}
7.1.7 32位體系結構下 Linux 虛擬記憶體空間整體布局
到現在為止,整個內核虛擬記憶體空間在 32 位體系下的布局,筆者就為大家詳細介紹完畢了,我們再次結合前邊《4.1 32 位機器上行程虛擬記憶體空間分布》小節中介紹的行程虛擬記憶體空間和本小節介紹的內核虛擬記憶體空間來整體回顧下 32 位體系結構 Linux 的整個虛擬記憶體空間的布局:
7.2 64 位體系內核虛擬記憶體空間布局
內核虛擬記憶體空間在 32 位體系下只有 1G 大小,實在太小了,因此需要精細化的管理,于是按照功能分類劃分除了很多內核虛擬記憶體區域,這樣就顯得非常復雜,
到了 64 位體系下,內核虛擬記憶體空間的布局和管理就變得容易多了,因為行程虛擬記憶體空間和內核虛擬記憶體空間各自占用 128T 的虛擬記憶體,實在是太大了,我們可以在這里邊隨意翱翔,隨意揮霍,
因此在 64 位體系下的內核虛擬記憶體空間與物理記憶體的映射就變得非常簡單,由于虛擬記憶體空間足夠的大,即便是內核要訪問全部的物理記憶體,直接映射就可以了,不在需要用到《7.1.2 ZONE_HIGHMEM 高端記憶體》小節中介紹的高端記憶體那種動態映射方式,
在前邊《5.1 內核如何劃分用戶態和內核態虛擬記憶體空間》小節中我們提到,內核在 /arch/x86/include/asm/page_64_types.h 檔案中通過 TASK_SIZE 將行程虛擬記憶體空間和內核虛擬記憶體空間分割開來,
#define TASK_SIZE (test_thread_flag(TIF_ADDR32) ? \
IA32_PAGE_OFFSET : TASK_SIZE_MAX)
#define TASK_SIZE_MAX task_size_max()
#define task_size_max() ((_AC(1,UL) << __VIRTUAL_MASK_SHIFT) - PAGE_SIZE)
#define __VIRTUAL_MASK_SHIFT 47
64 位系統中的 TASK_SIZE 為 0x00007FFFFFFFF000
在 64 位系統中,只使用了其中的低 48 位來表示虛擬記憶體地址,其中用戶態虛擬記憶體空間為低 128 T,虛擬記憶體地址范圍為:0x0000 0000 0000 0000 - 0x0000 7FFF FFFF F000 ,
內核態虛擬記憶體空間為高 128 T,虛擬記憶體地址范圍為:0xFFFF 8000 0000 0000 - 0xFFFF FFFF FFFF FFFF ,
本小節我們主要關注 0xFFFF 8000 0000 0000 - 0xFFFF FFFF FFFF FFFF 這段內核虛擬記憶體空間的布局情況,
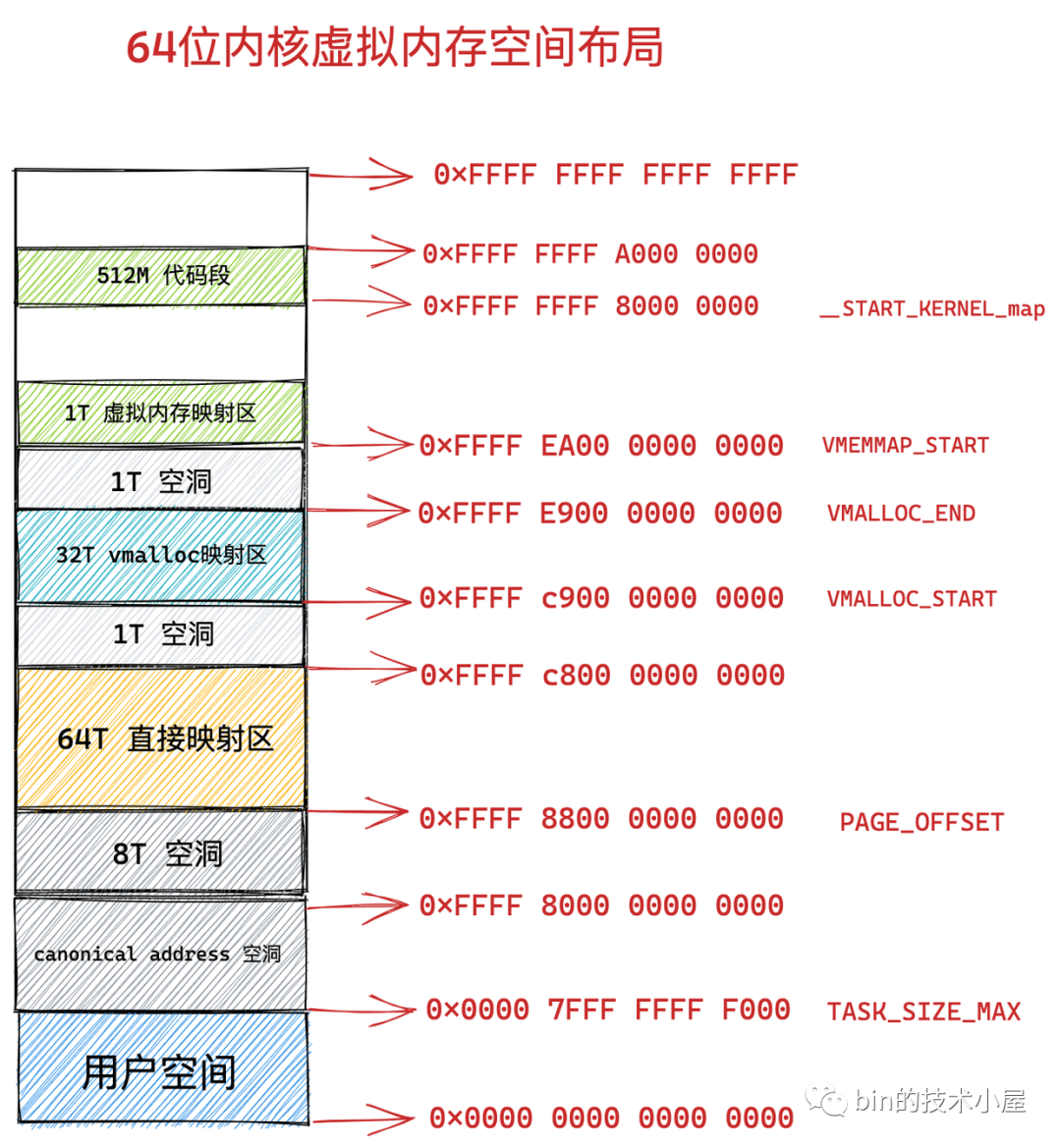
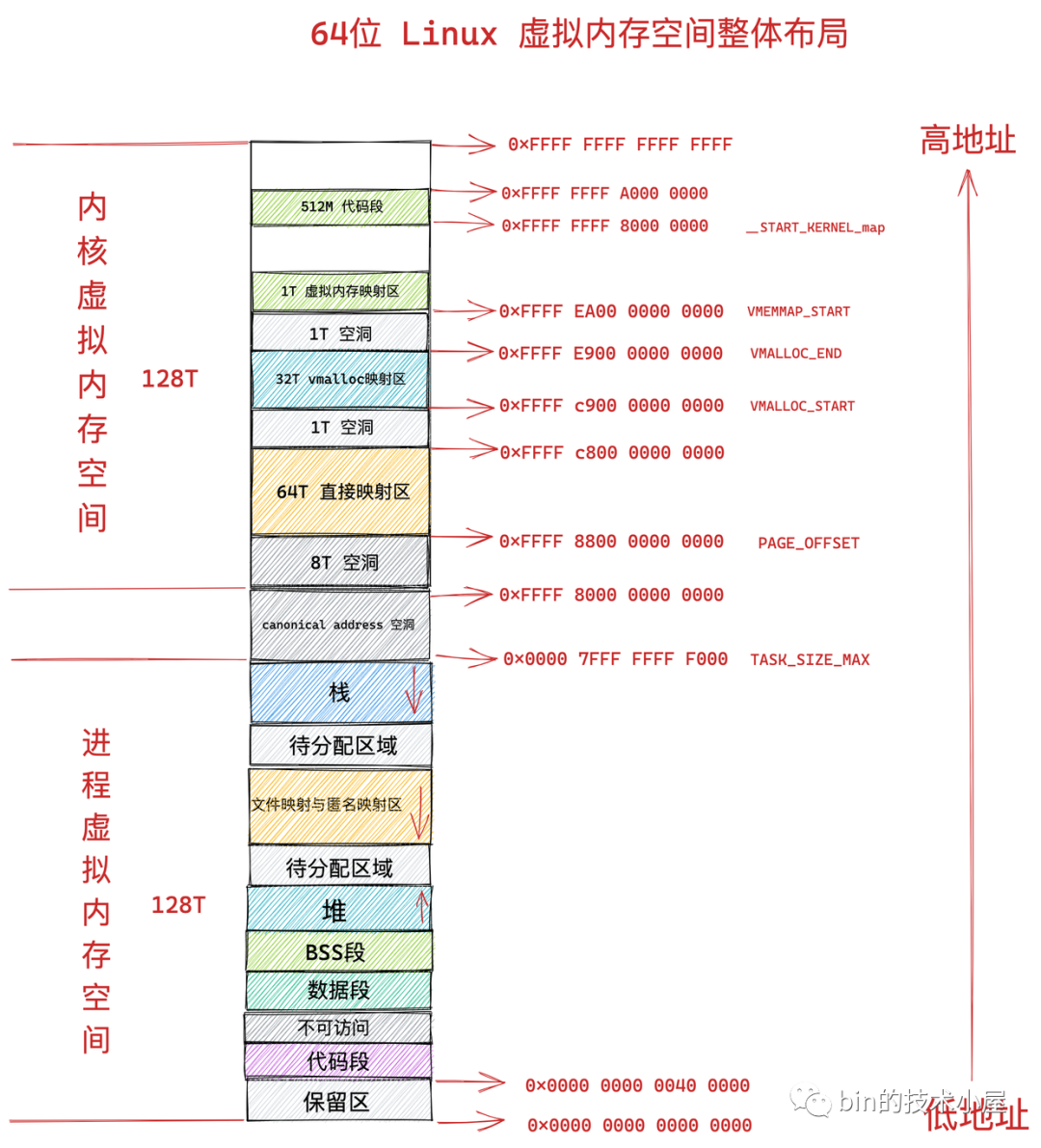
64 位內核虛擬記憶體空間從 0xFFFF 8000 0000 0000 開始到 0xFFFF 8800 0000 0000 這段地址空間是一個 8T 大小的記憶體空洞區域,
緊著著 8T 大小的記憶體空洞下一個區域就是 64T 大小的直接映射區,這個區域中的虛擬記憶體地址減去 PAGE_OFFSET 就直接得到了物理記憶體地址,
PAGE_OFFSET 變數定義在 /arch/x86/include/asm/page_64_types.h 檔案中:
#define __PAGE_OFFSET_BASE _AC(0xffff880000000000, UL)
#define __PAGE_OFFSET __PAGE_OFFSET_BASE
從圖中 VMALLOC_START 到 VMALLOC_END 的這段區域是 32T 大小的 vmalloc 映射區,這里類似用戶空間中的堆,內核在這里使用 vmalloc 系統呼叫申請記憶體,
VMALLOC_START 和 VMALLOC_END 變數定義在 /arch/x86/include/asm/pgtable_64_types.h 檔案中:
#define __VMALLOC_BASE_L4 0xffffc90000000000UL
#define VMEMMAP_START __VMEMMAP_BASE_L4
#define VMALLOC_END (VMALLOC_START + (VMALLOC_SIZE_TB << 40) - 1)
從 VMEMMAP_START 開始是 1T 大小的虛擬記憶體映射區,用于存放物理頁面的描述符 struct page 結構用來表示物理記憶體頁,
VMEMMAP_START 變數定義在 /arch/x86/include/asm/pgtable_64_types.h 檔案中:
#define __VMEMMAP_BASE_L4 0xffffea0000000000UL
# define VMEMMAP_START __VMEMMAP_BASE_L4
從 __START_KERNEL_map 開始是大小為 512M 的區域用于存放內核代碼段、全域變數、BSS 等,這里對應到物理記憶體開始的位置,減去 __START_KERNEL_map 就能得到物理記憶體的地址,這里和直接映射區有點像,但是不矛盾,因為直接映射區之前有 8T 的空洞區域,早就過了內核代碼在物理記憶體中加載的位置,
__START_KERNEL_map 變數定義在 /arch/x86/include/asm/page_64_types.h 檔案中:
#define __START_KERNEL_map _AC(0xffffffff80000000, UL)
7.2.1 64位體系結構下 Linux 虛擬記憶體空間整體布局
到現在為止,整個內核虛擬記憶體空間在 64 位體系下的布局筆者就為大家詳細介紹完畢了,我們再次結合前邊《4.2 64 位機器上行程虛擬記憶體空間分布》小節介紹的行程虛擬記憶體空間和本小節介紹的內核虛擬記憶體空間來整體回顧下 64 位體系結構 Linux 的整個虛擬記憶體空間的布局:
8. 到底什么是物理記憶體地址
聊完了虛擬記憶體,我們接著聊一下物理記憶體,我們平時所稱的記憶體也叫隨機訪問存盤器( random-access memory )也叫 RAM ,而 RAM 分為兩類:
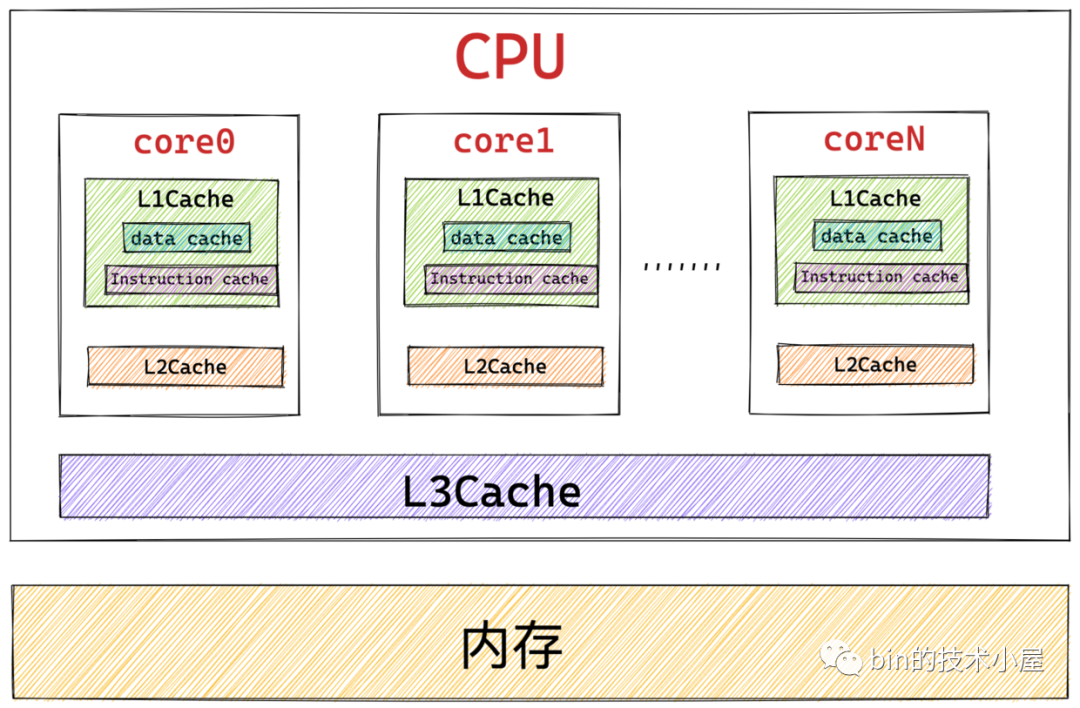
- 一類是靜態 RAM(
SRAM),這類 SRAM 用于 CPU 高速快取 L1Cache,L2Cache,L3Cache,其特點是訪問速度快,訪問速度為 1 - 30 個時鐘周期,但是容量小,造價高,
- 另一類則是動態 RAM (
DRAM),這類 DRAM 用于我們常說的主存上,其特點的是訪問速度慢(相對高速快取),訪問速度為 50 - 200 個時鐘周期,但是容量大,造價便宜些(相對高速快取),
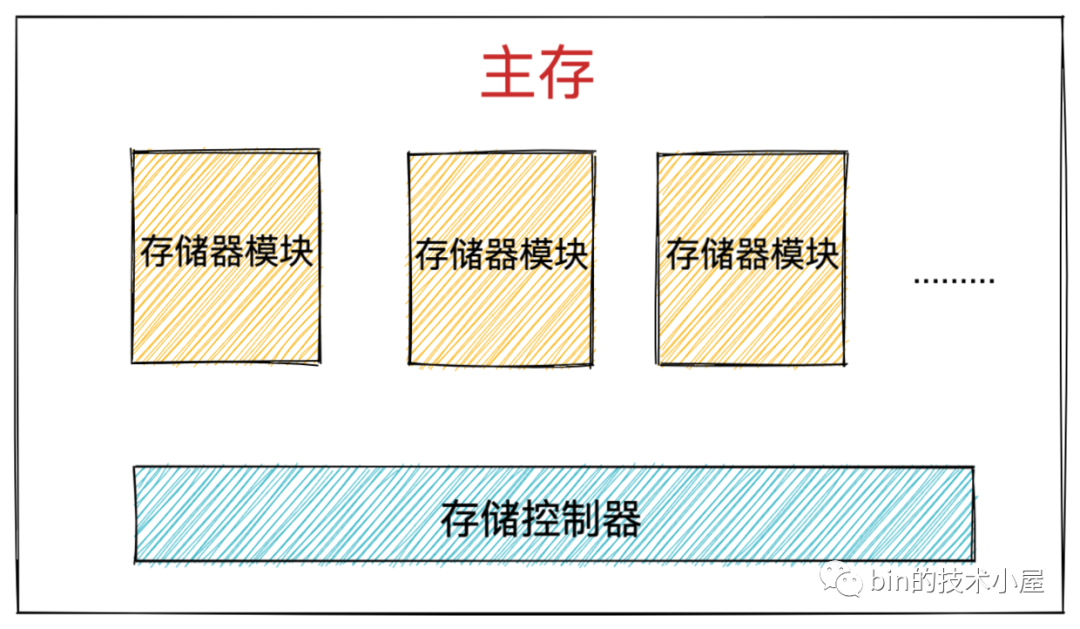
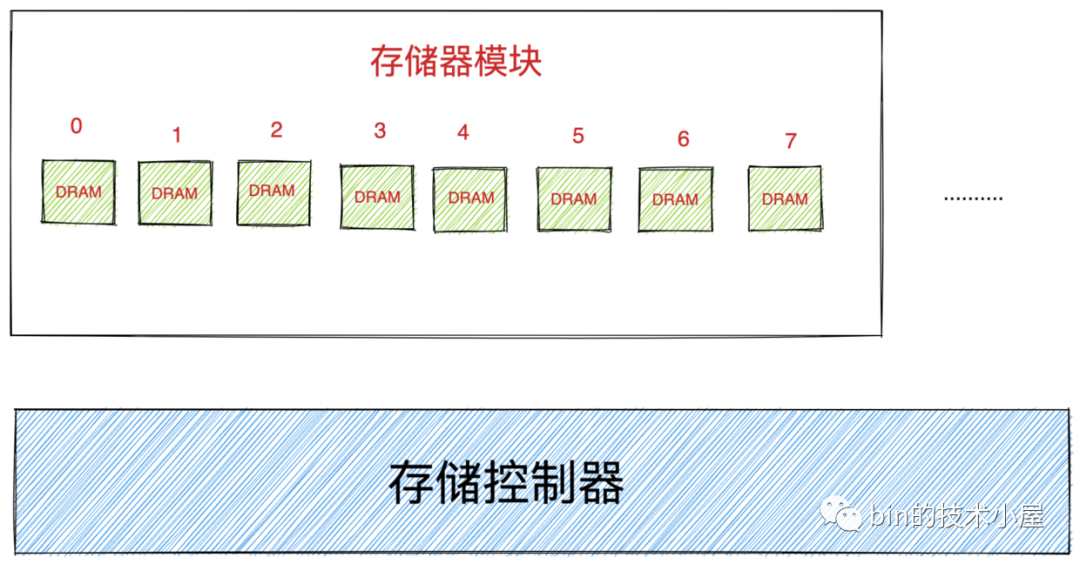
記憶體由一個一個的存盤器模塊(memory module)組成,它們插在主板的擴展槽上,常見的存盤器模塊通常以 64 位為單位( 8 個位元組)傳輸資料到存盤控制器上或者從存盤控制器傳出資料,

如圖所示記憶體條上黑色的元器件就是存盤器模塊(memory module),多個存盤器模塊連接到存盤控制器上,就聚合成了主存,
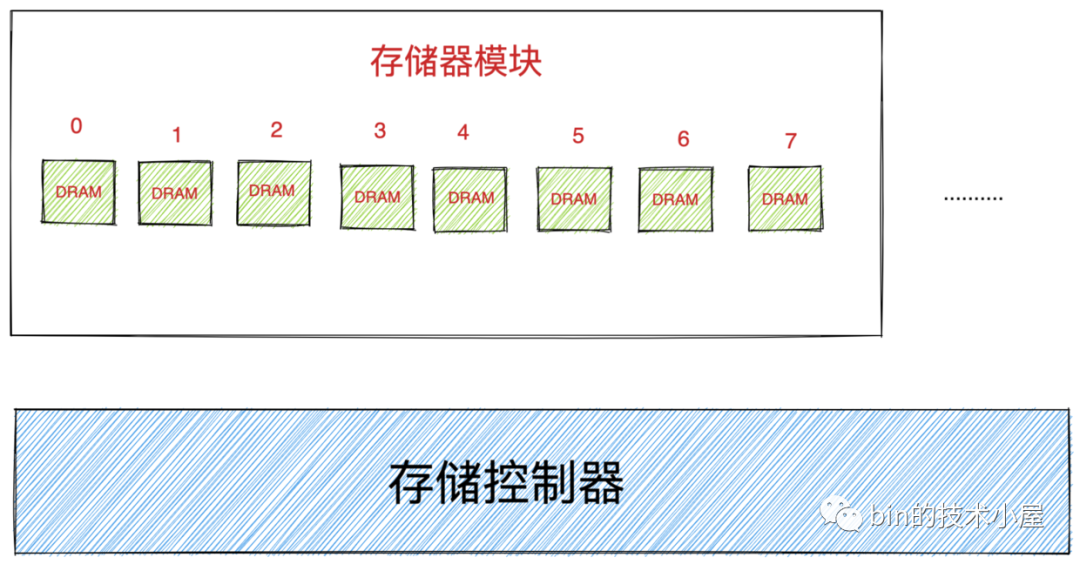
而 DRAM 芯片就包裝在存盤器模塊中,每個存盤器模塊中包含 8 個 DRAM 芯片,依次編號為 0 - 7 ,
而每一個 DRAM 芯片的存盤結構是一個二維矩陣,二維矩陣中存盤的元素我們稱為超單元(supercell),每個 supercell 大小為一個位元組(8 bit),每個 supercell 都由一個坐標地址(i,j),
i 表示二維矩陣中的行地址,在計算機中行地址稱為 RAS (row access strobe,行訪問選通脈沖),
j 表示二維矩陣中的列地址,在計算機中列地址稱為 CAS (column access strobe,列訪問選通脈沖),
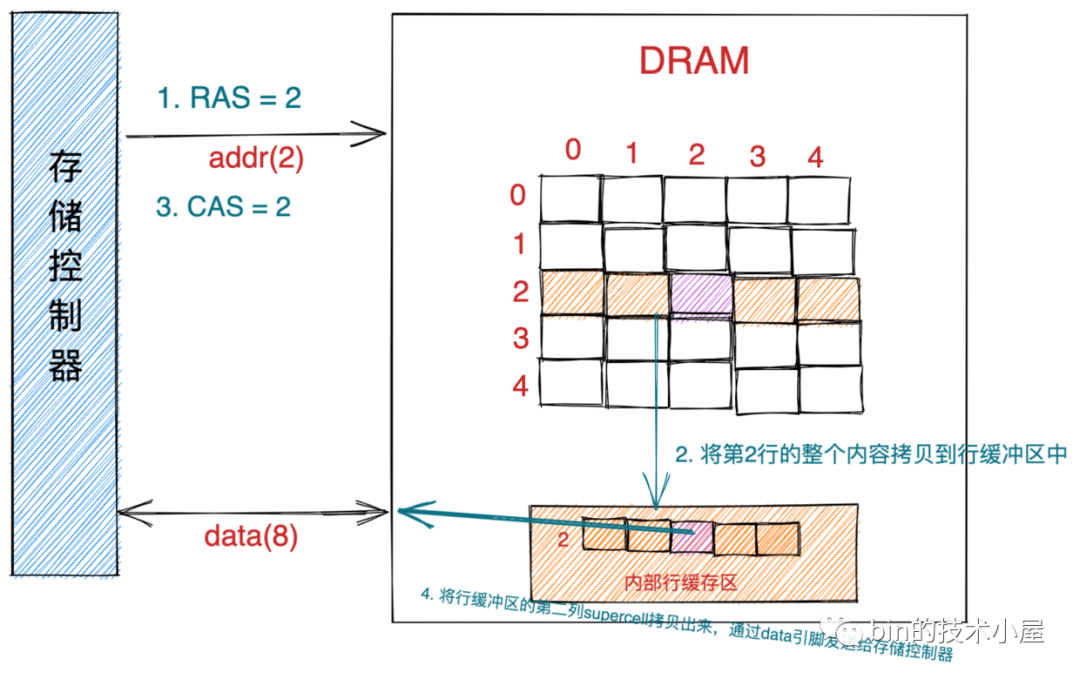
下圖中的 supercell 的 RAS = 2,CAS = 2,
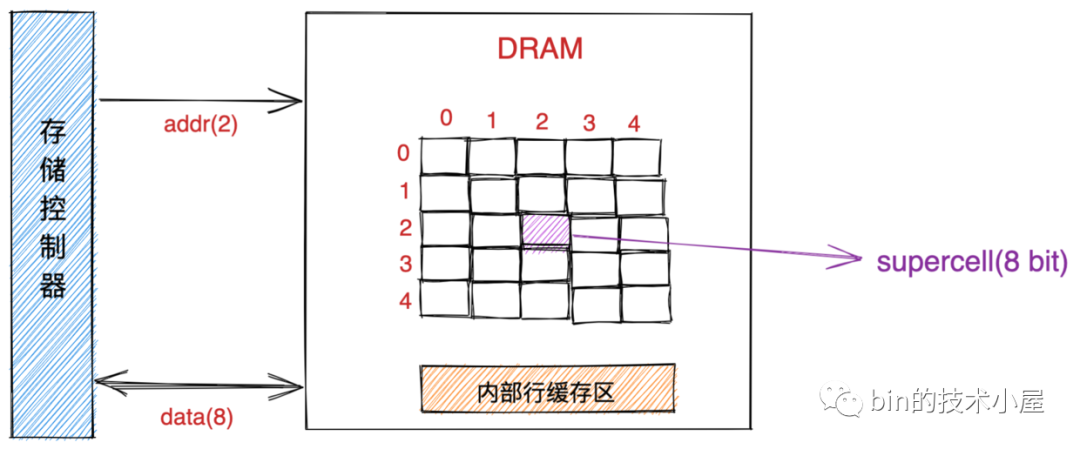
DRAM 芯片中的資訊通過引腳流入流出 DRAM 芯片,每個引腳攜帶 1 bit的信號,
圖中 DRAM 芯片包含了兩個地址引腳( addr ),因為我們要通過 RAS,CAS 來定位要獲取的 supercell ,還有 8 個資料引腳(data),因為 DRAM 芯片的 IO 單位為一個位元組(8 bit),所以需要 8 個 data 引腳從 DRAM 芯片傳入傳出資料,
注意這里只是為了解釋地址引腳和資料引腳的概念,實際硬體中的引腳數量是不一定的,
8.1 DRAM 芯片的訪問
我們現在就以讀取上圖中坐標地址為(2,2)的 supercell 為例,來說明訪問 DRAM 芯片的程序,
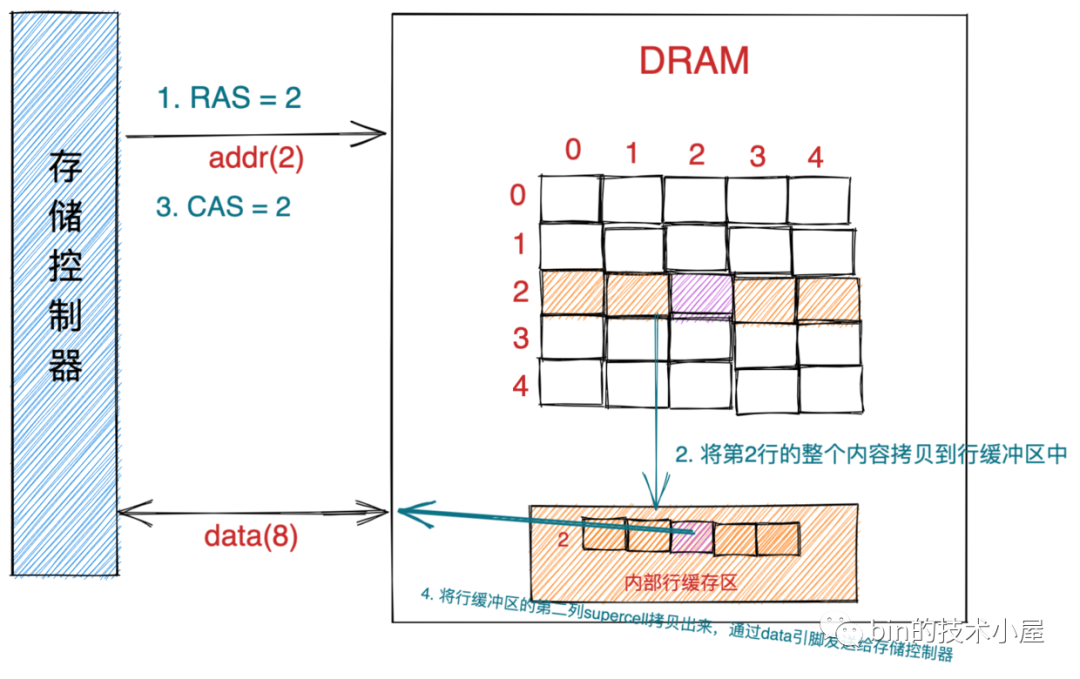
-
首先存盤控制器將行地址 RAS = 2 通過地址引腳發送給 DRAM 芯片,
-
DRAM 芯片根據 RAS = 2 將二維矩陣中的第二行的全部內容拷貝到內部行緩沖區中,
-
接下來存盤控制器會通過地址引腳發送 CAS = 2 到 DRAM 芯片中,
-
DRAM芯片從內部行緩沖區中根據 CAS = 2 拷貝出第二列的 supercell 并通過資料引腳發送給存盤控制器,
DRAM 芯片的 IO 單位為一個 supercell ,也就是一個位元組(8 bit),
8.2 CPU 如何讀寫主存
前邊我們介紹了記憶體的物理結構,以及如何訪問記憶體中的 DRAM 芯片獲取 supercell 中存盤的資料(一個位元組),本小節我們來介紹下 CPU 是如何訪問記憶體的:
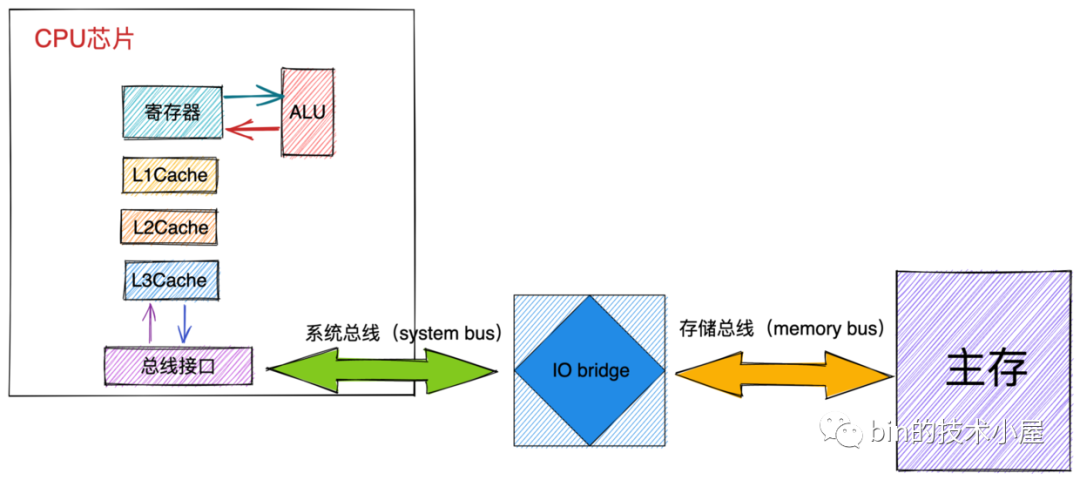
CPU 與記憶體之間的資料互動是通過總線(bus)完成的,而資料在總線上的傳送是通過一系列的步驟完成的,這些步驟稱為總線事務(bus transaction),
其中資料從記憶體傳送到 CPU 稱之為讀事務(read transaction),資料從 CPU 傳送到記憶體稱之為寫事務(write transaction),
總線上傳輸的信號包括:地址信號,資料信號,控制信號,其中控制總線上傳輸的控制信號可以同步事務,并能夠標識出當前正在被執行的事務資訊:
- 當前這個事務是到記憶體的?還是到磁盤的?或者是到其他 IO 設備的?
- 這個事務是讀還是寫?
- 總線上傳輸的地址信號(物理記憶體地址),還是資料信號(資料)?,
這里大家需要注意總線上傳輸的地址均為物理記憶體地址,比如:在 MESI 快取一致性協議中當 CPU core0 修改欄位 a 的值時,其他 CPU 核心會在總線上嗅探欄位 a 的物理記憶體地址,如果嗅探到總線上出現欄位 a 的物理記憶體地址,說明有人在修改欄位 a,這樣其他 CPU 核心就會失效欄位 a 所在的 cache line ,
如上圖所示,其中系統總線是連接 CPU 與 IO bridge 的,存盤總線是來連接 IO bridge 和主存的,
IO bridge 負責將系統總線上的電子信號轉換成存盤總線上的電子信號,IO bridge 也會將系統總線和存盤總線連接到IO總線(磁盤等IO設備)上,這里我們看到 IO bridge 其實起的作用就是轉換不同總線上的電子信號,
8.3 CPU 從記憶體讀取資料程序
假設 CPU 現在需要將物理記憶體地址為 A 的內容加載到暫存器中進行運算,
大家需要注意的是 CPU 只會訪問虛擬記憶體,在操作總線之前,需要把虛擬記憶體地址轉換為物理記憶體地址,總線上傳輸的都是物理記憶體地址,這里省略了虛擬記憶體地址到物理記憶體地址的轉換程序,這部分內容筆者會在后續文章的相關章節詳細為大家講解,這里我們聚焦如果通過物理記憶體地址讀取記憶體資料,
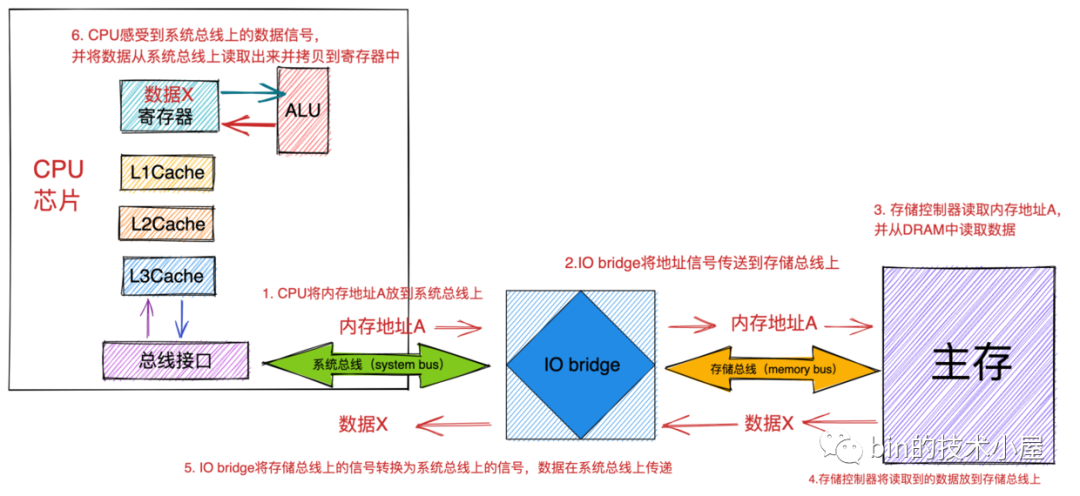
首先 CPU 芯片中的總線介面會在總線上發起讀事務(read transaction), 該讀事務分為以下步驟進行:
-
CPU 將物理記憶體地址 A 放到系統總線上,隨后 IO bridge 將信號傳遞到存盤總線上,
-
主存感受到存盤總線上的地址信號并通過存盤控制器將存盤總線上的物理記憶體地址 A 讀取出來,
-
存盤控制器通過物理記憶體地址 A 定位到具體的存盤器模塊,從 DRAM 芯片中取出物理記憶體地址 A 對應的資料 X,
-
存盤控制器將讀取到的資料 X 放到存盤總線上,隨后 IO bridge 將存盤總線上的資料信號轉換為系統總線上的資料信號,然后繼續沿著系統總線傳遞,
-
CPU 芯片感受到系統總線上的資料信號,將資料從系統總線上讀取出來并拷貝到暫存器中,
以上就是 CPU 讀取記憶體資料到暫存器中的完整程序,
但是其中還涉及到一個重要的程序,這里我們還是需要攤開來介紹一下,那就是存盤控制器如何通過物理記憶體地址 A 從主存中讀取出對應的資料 X 的?
接下來我們結合前邊介紹的記憶體結構以及從 DRAM 芯片讀取資料的程序,來總體介紹下如何從主存中讀取資料,
8.4 如何根據物理記憶體地址從主存中讀取資料
前邊介紹到,當主存中的存盤控制器感受到了存盤總線上的地址信號時,會將記憶體地址從存盤總線上讀取出來,
隨后會通過記憶體地址定位到具體的存盤器模塊,還記得記憶體結構中的存盤器模塊嗎 ?
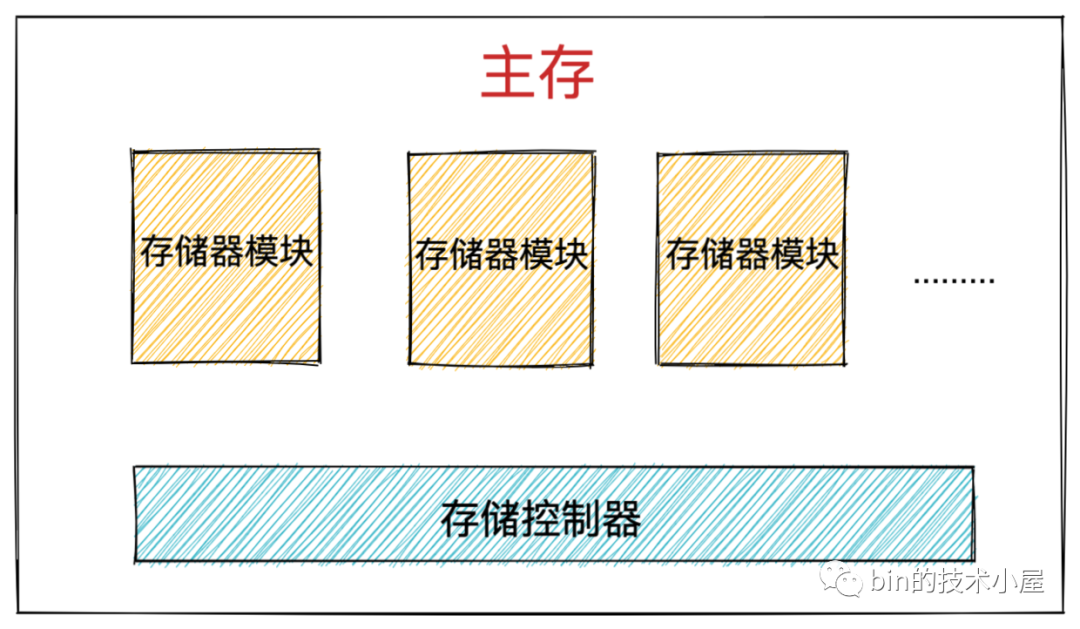
而每個存盤器模塊中包含了 8 個 DRAM 芯片,編號從 0 - 7 ,
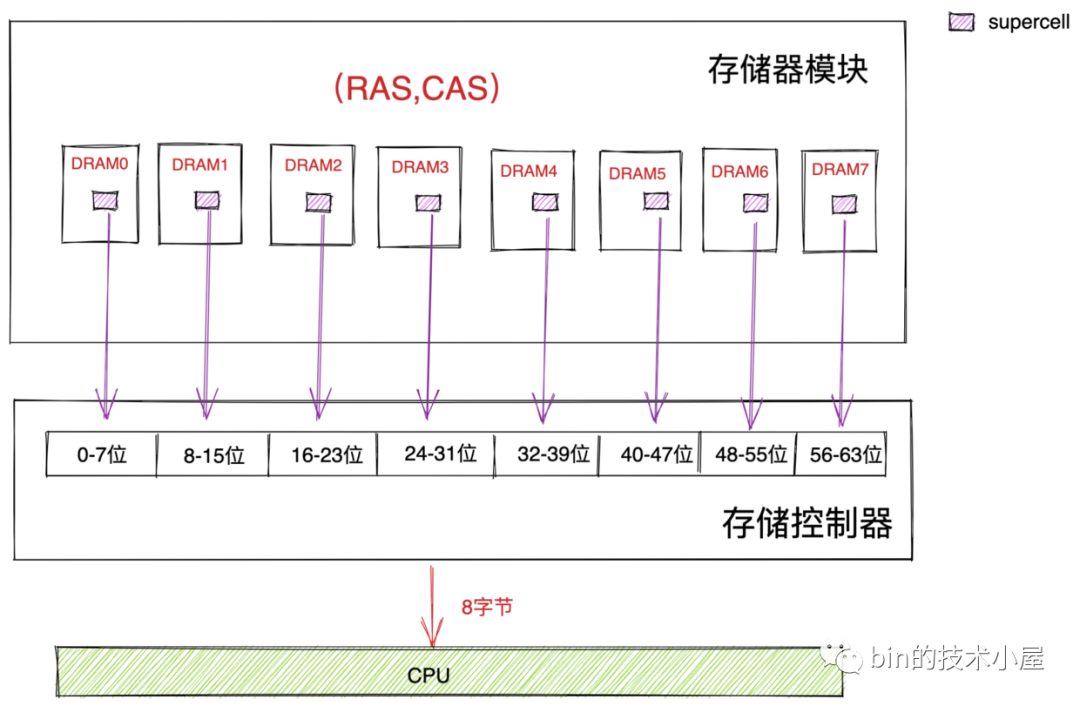
存盤控制器會將物理記憶體地址轉換為 DRAM 芯片中 supercell 在二維矩陣中的坐標地址(RAS,CAS),并將這個坐標地址發送給對應的存盤器模塊,隨后存盤器模塊會將 RAS 和 CAS 廣播到存盤器模塊中的所有 DRAM 芯片,依次通過 (RAS,CAS) 從 DRAM0 到 DRAM7 讀取到相應的 supercell ,
我們知道一個 supercell 存盤了一個位元組( 8 bit ) 資料,這里我們從 DRAM0 到 DRAM7 依次讀取到了 8 個 supercell 也就是 8 個位元組,然后將這 8 個位元組回傳給存盤控制器,由存盤控制器將資料放到存盤總線上,
CPU 總是以 word size 為單位從記憶體中讀取資料,在 64 位處理器中的 word size 為 8 個位元組,64 位的記憶體每次只能吞吐 8 個位元組,
CPU 每次會向記憶體讀寫一個 cache line 大小的資料( 64 個位元組),但是記憶體一次只能吞吐 8 個位元組,
所以在物理記憶體地址對應的存盤器模塊中,DRAM0 芯片存盤第一個低位位元組( supercell ),DRAM1 芯片存盤第二個位元組,......依次類推 DRAM7 芯片存盤最后一個高位位元組,
由于存盤器模塊中這種由 8 個 DRAM 芯片組成的物理存盤結構的限制,記憶體讀取資料只能是按照物理記憶體地址,8 個位元組 8 個位元組地順序讀取資料,所以說記憶體一次讀取和寫入的單位是 8 個位元組,
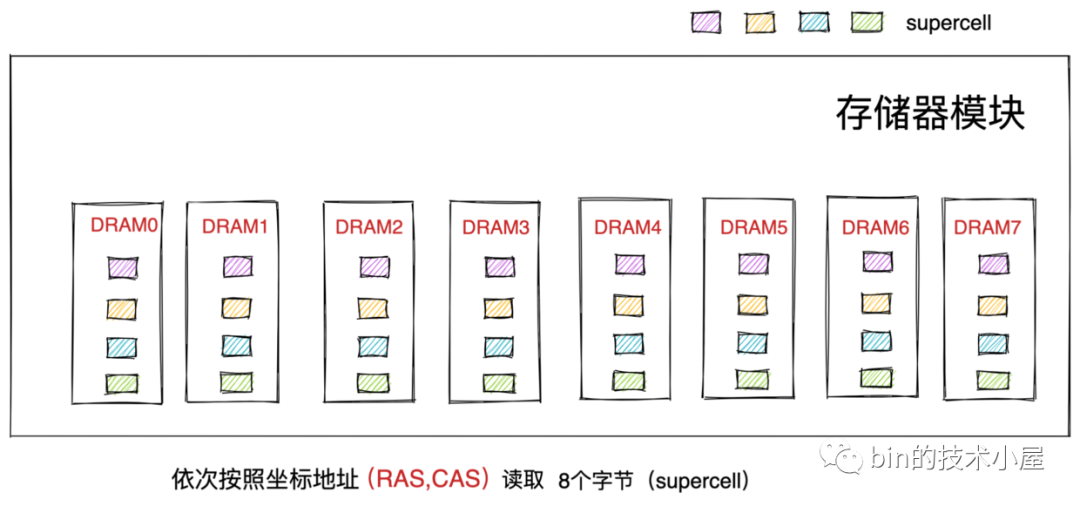
而且在程式員眼里連續的物理記憶體地址實際上在物理上是不連續的,因為這連續的 8 個位元組其實是存盤于不同的 DRAM 芯片上的,每個 DRAM 芯片存盤一個位元組(supercell)
8.5 CPU 向記憶體寫入資料程序
我們現在假設 CPU 要將暫存器中的資料 X 寫到物理記憶體地址 A 中,同樣的道理,CPU 芯片中的總線介面會向總線發起寫事務(write transaction),寫事務步驟如下:
-
CPU 將要寫入的物理記憶體地址 A 放入系統總線上,
-
通過 IO bridge 的信號轉換,將物理記憶體地址 A 傳遞到存盤總線上,
-
存盤控制器感受到存盤總線上的地址信號,將物理記憶體地址 A 從存盤總線上讀取出來,并等待資料的到達,
-
CPU 將暫存器中的資料拷貝到系統總線上,通過 IO bridge 的信號轉換,將資料傳遞到存盤總線上,
-
存盤控制器感受到存盤總線上的資料信號,將資料從存盤總線上讀取出來,
-
存盤控制器通過記憶體地址 A 定位到具體的存盤器模塊,最后將資料寫入存盤器模塊中的 8 個 DRAM 芯片中,
總結

本文我們從虛擬記憶體地址開始聊起,一直到物理記憶體地址結束,包含的資訊量還是比較大的,首先筆者通過一個行程的運行實體為大家引出了內核引入虛擬記憶體空間的目的及其需要解決的問題,
在我們有了虛擬記憶體空間的概念之后,筆者又近一步為大家介紹了內核如何劃分用戶態虛擬記憶體空間和內核態虛擬記憶體空間,并在次基礎之上分別從 32 位體系結構和 64 位體系結構的角度詳細闡述了 Linux 虛擬記憶體空間的整體布局分布,
-
我們可以通過
cat /proc/pid/maps或者pmap pid命令來查看行程用戶態虛擬記憶體空間的實際分布, -
還可以通過
cat /proc/iomem命令來查看行程內核態虛擬記憶體空間的的實際分布,
在我們清楚了 Linux 虛擬記憶體空間的整體布局分布之后,筆者又介紹了 Linux 內核如何對分布在虛擬記憶體空間中的各個虛擬記憶體區域進行管理,以及每個虛擬記憶體區域的作用,在這個程序中還介紹了相關的內核資料結構,近一步從內核原始碼實作角度加深大家對虛擬記憶體空間的理解,
最后筆者介紹了物理記憶體的結構,以及 CPU 如何通過物理記憶體地址來讀寫記憶體中的資料,這里筆者需要特地再次強調的是 CPU 只會訪問虛擬記憶體地址,只不過在操作總線之前,通過一個地址轉換硬體將虛擬記憶體地址轉換為物理記憶體地址,然后將物理記憶體地址作為地址信號放在總線上傳輸,由于地址轉換的內容和本文主旨無關,考慮到文章的篇幅以及復雜性,筆者就沒有過多的介紹,
好了,本文的全部內容到這里就結束了,感謝大家的收看,我們下篇文章見~~~
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/519222.html
標籤:其他