文章目錄
- 1. cache背景知識
- 2. 典型的cache架構
- 3. Cache映射方式
- 3.1 直接映射方式
- 3.2 組相聯映射方式
- 3.3 全相連映射方式
- 4. cache line作為傳輸單位的原因?
- 5. Cache組織方式
- 5.1 虛擬高速快取(VIVT)
- 5.1.1 歧義(ambiguity)
- 5.1.2 別名(alias)
- 5.2 物理高速快取(PIPT)
- 5.3 物理標記的虛擬高速快取(VIPT)
- 5.3.1 VIPT Cache什么情況不存在別名
- 5.3.2 VIPT Cache的別名問題
- 5.3.3 如何解決VIPT Cache別名問題
- 5.3.4 小結
- 6. cache的層級
- 6.1 兩級cache
- 6.2 三級cache
- 7. cache的訪問延時
- 8. cache的策略
- 8.1 cache的分配策略
- 8.2 cache的回寫策略
- 9. 共享域
- 10. PoU和PoC的區別
- 10.1 PoU(Point of Unification - 統一點)
- 10.2 PoC(Point of Coherency - 一致性點)
- 10.3 PoU和PoC的區別
- 11. Cache維護指令
- 12. Cache指令格式
- 13. cache一致性
- 14. linux查看Cache資訊的方式
- 14.1 Linux下查看CPU Cache級數,每級大小
- 14.2 查看Cache的關聯方式
- 14.3 查看cache_line的大小
- 14.4 查看cache的分配策略
- 14.5 查看cache的回寫策略
- 14.5 查看cache的shared_cpu_map
- 14.6 查看cache的shared_cpu_list
1. cache背景知識
為什么的CPU內部需要cache單元?
??主要的原因是CPU的速度和記憶體的速度之間嚴重不匹配,Cpu處理速度極快,而訪問記憶體慢,cache在這個背景下就誕生了,設計人員通過在CPU和記憶體之間建立一個緩沖區,提高訪問的速度,
??建立cache的好處在于:假設CPU和記憶體之間沒有cache,那么CPU每次訪問記憶體,都要從訪問速度較慢的記憶體中讀取,這無疑是很浪費cpu的性能的;但是如果在CPU和記憶體之間設立一個高速的cache,雖然第一次讀,都要從記憶體中讀取,但是第一次讀完成之后,可以把資料放到這個高速cache里;那么第二次讀,我就直接從高速cache里取資料就行,這個高速cache的速度基本上是和CPU匹配的,比記憶體速度快很多,這樣的,CPU第2次,第3次去讀這個資料的時候,就得到加速的效果了,這也是設計cache的最初的初衷,
??cache一般是集成在CPU內部的RAM,相對于外部的記憶體顆粒來說造價昂貴,因此一般cache是很小的RAM,但是訪問速度和CPU是匹配的,此外,如果訪問資料在cache命中的話,不僅僅能提速,提高程式的性能,還能降低功耗(cache命中的情況,不需要去訪問外部的記憶體設備,自然會降低功耗),
2. 典型的cache架構
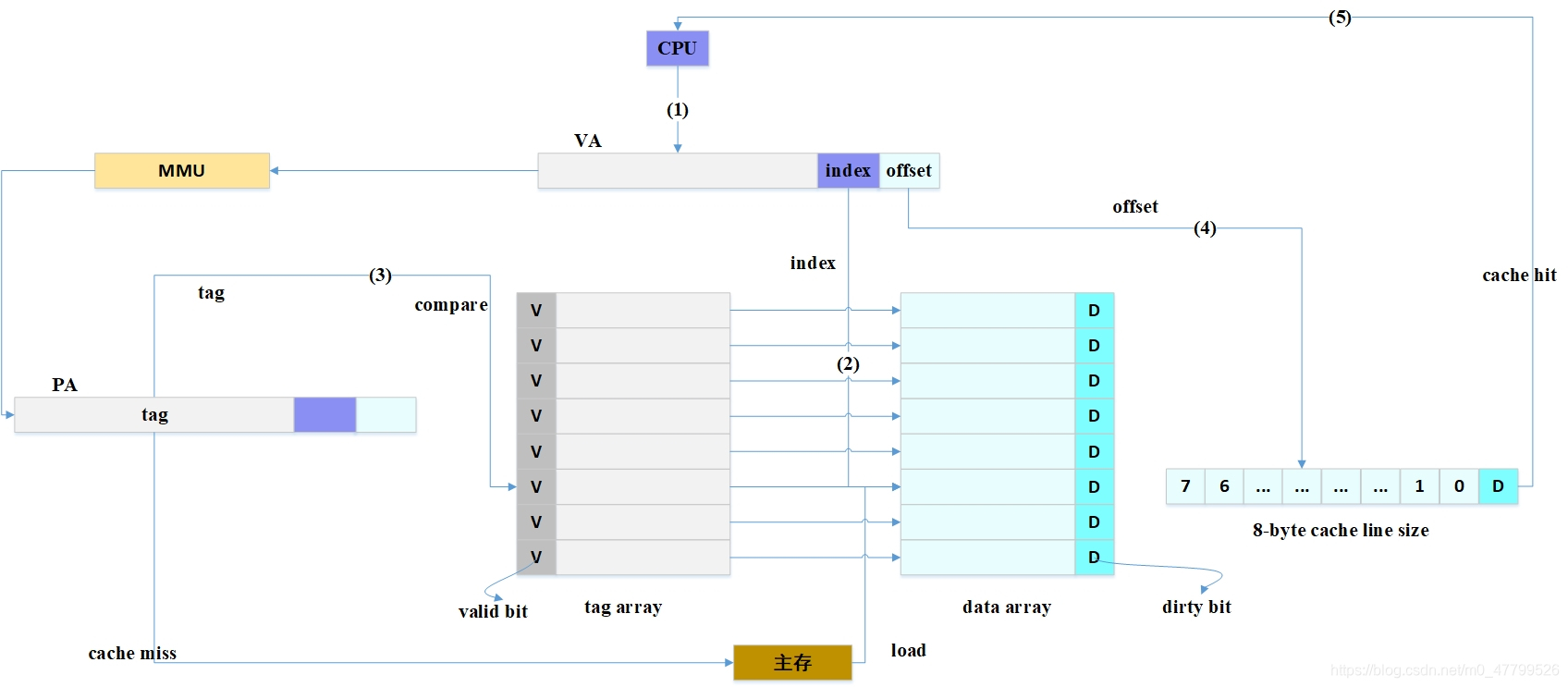
??下圖是一個典型的cache架構,CPU在訪問記憶體的時候,首先發出的虛擬地址,并把這個虛擬地址發送給TLB和cache,TLB是一個用于存盤虛擬地址到物理地址轉換的小快取,處理器先使用EPN(effective page number,有效頁幀號)在TLB中進行查找最終的RPN(Real Page Number,實際頁幀號),如果這期間發生TLB未命中(TLB Miss),處理器需要繼續訪問MMU并且查詢頁表,假設這里TLB 命中(TLB Hit),此時很快獲得期望的RPN,并得到相應的物理地址(Physical Address,PA),
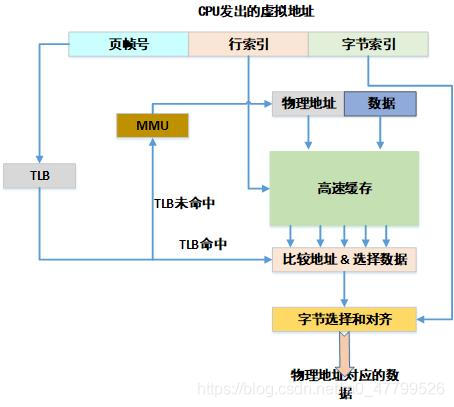
??同時,處理器通過高速快取編碼地址的索引域(Index)可以很快找到相應的高速快取行對應的組,但是這里的高速快取行的資料不一定是處理器所需要的,因此有必要進行一些檢查,將高速快取行中存放的標記域和通過虛實地址轉換得到的物理地址的標記域進行比較,如果相同并且狀態位匹配,那么就會發生高速快取命中(cache hit),處理器經過位元組選擇與對齊(byte select and align)部件,最終就可以獲取所需要的資料,如果發生高速快取 未命中(cache miss),處理器需要用物理地址進一步訪問主存盤器來獲得最終資料,資料也會填充到相應的高速快取行中,上述描述的是VIPT(Virtual Index Physical Tag 虛擬索引物理標記)的高速快取組織方式,這個也是經典的cache運行模式了,
3. Cache映射方式
3.1 直接映射方式
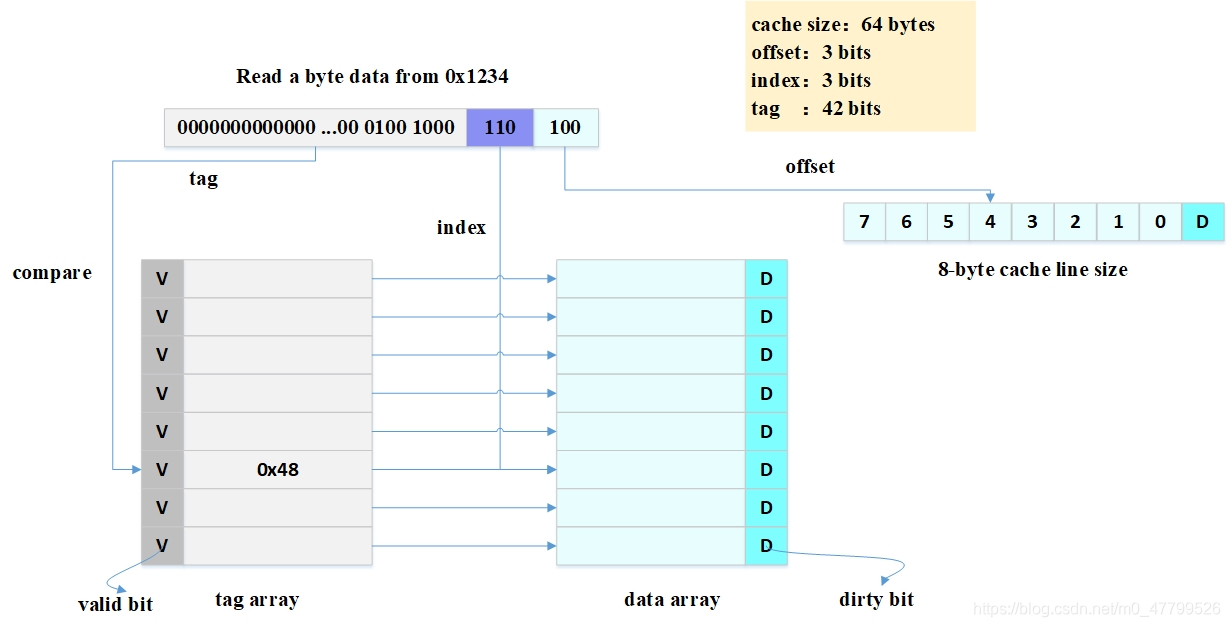
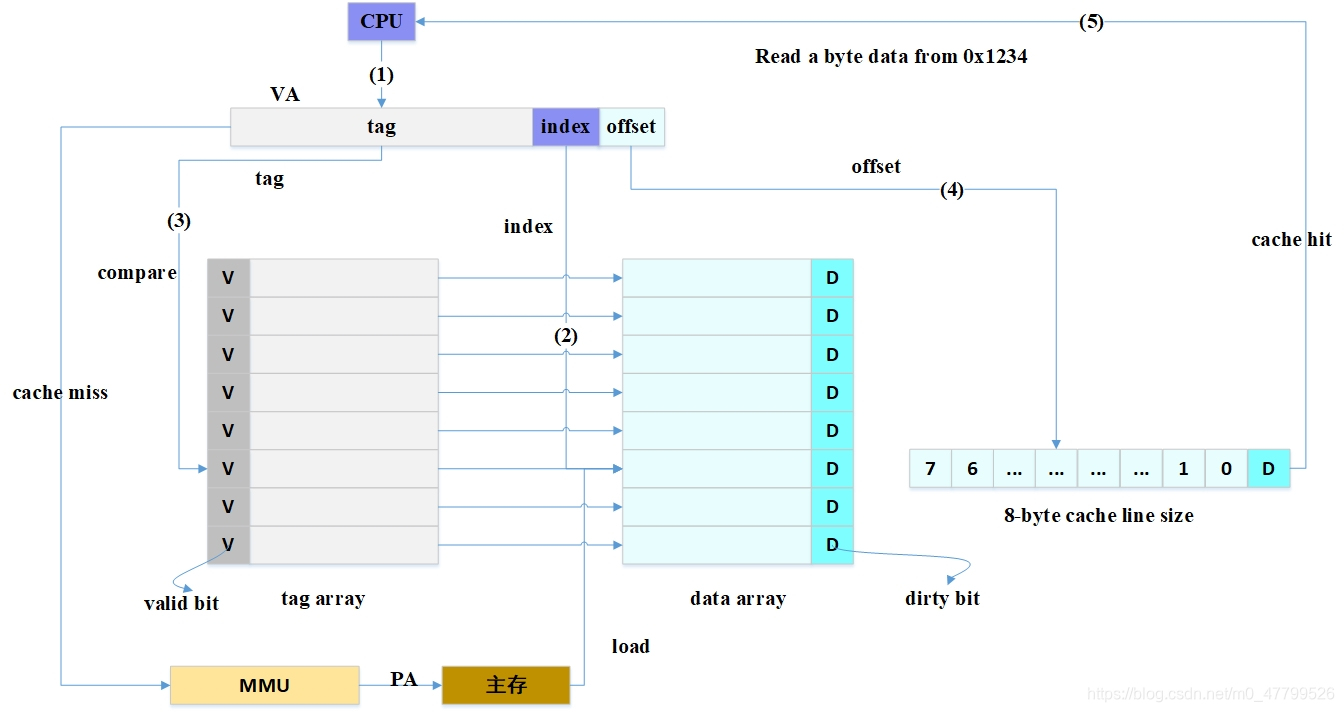
??出于對成本的考慮,cache大小相對于主存來說會小很多,因此cache只能快取主存中極小一部分資料,如何根據地址在有限大小的cache中查找資料呢?硬體采取的做法是對地址進行散列(可以理解成地址取模操作),上圖是CPU從0x1234地址讀取一個位元組的例子:
- 圖中一共有8行cache line,cache line大小是8 Bytes,可以利用地址低3 bits尋址8 bytes中某一位元組,我們稱這部分bit為 offset,
- 8行cache line,為了查找能夠覆寫所有行,需要3 bits查找某一行,我們稱這部分bit為 index,
- 現在如果有兩個不同的地址,其地址的bit[3 - 5]如果完全一樣,那么這兩個地址經過硬體散列之后都會找到同一個cache line,所以,當找到cache line之后,只代表我們訪問的地址對應的資料可能存在這個cache line中,但是也有可能是其它地址對應的資料,所以,又引入 tag array的概念,tag array和data array一一對應,每一個cache line都對應唯一一個tag,tag中保存的是整個地址位寬去除index和offset使用的bit剩余部分,
??tag、index和offset三者組合就可以確定一個唯一的地址了,因此,當我們根據地址中index位找到cache line后,取出當前cache line對應的tag,然后和地址中的tag進行比較,如果相等,這說明cache命中,如果不相等,說明當前cache line存盤的是其它地址的資料,這就是cache缺失(cache miss),在上圖中,我們看到tag的值是0x48 ,和地址中的tag部分相等,因此在本次訪問會命中(cache hit),
tag的引入,解答了之前的一個疑問? “為什么硬體cache line不做成一個位元組?” 因為這樣會導致硬體成本的上升,因為原本8個位元組對應一個tag,現在需要8個tag,占用了很多記憶體,
從圖中看到tag旁邊有一個valid bit,這個bit用來表示cache line中資料是否有效(例如:1代表有效;0代表無效),當系統剛啟動時,cache中的資料都應該是無效的,因為還沒有快取任何資料,cache控制器可以根據valid bit確認當前cache line資料是否有效,所以,上述比較tag確認cache line是否命中之前還會檢查valid bit是否有效,只有在有效的情況下,比較tag才有意義,如果無效,直接判定cache缺失,
從圖中看到8byte的cache line 旁邊有一個D(dirty) bit,這一個dirty bit代表著整個cache line是否被修改的狀態,
直接映射方式快取的優缺點:
(1)優點
直接映射快取在硬體設計上會更加簡單,因此成本上也會較低,
(2)缺點
會造成chche的顛簸,
原因如下:
假設memory的大小為0xc0,根據直接映射快取的作業方式,可以畫出主存地址0x00-0xC0地址對應的cache分布圖,
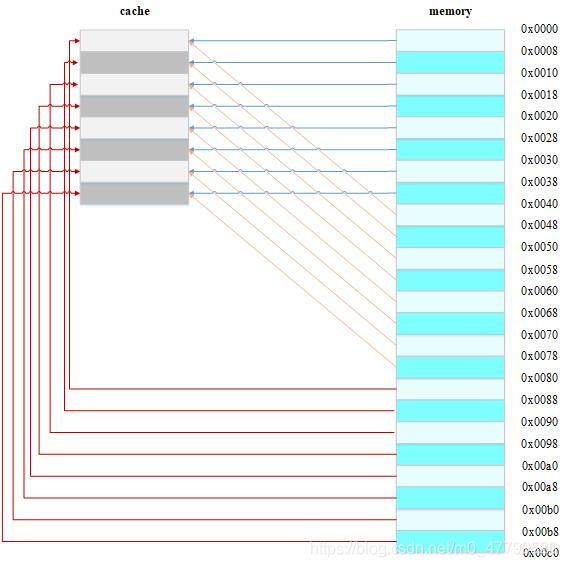
??可以看到,地址0x00-0x40/0x40-0x80/0x80-0xc0地址處對應的資料每一個都可以對應整個cache,現在就出現了一個問題,如果試圖依次訪問地址0x00、0x40、0x80,cache中的資料會發生什么呢?
- 首先由于0x00、0x40、0x80地址中index部分是一樣的,因此,這3個地址對應的cache line是同一個,當首次訪問0x00地址時,cache會缺失,然后資料會從主存中加載到cache中第1行的cache line,
- 當繼續訪問0x40地址時,依然索引到cache中第0行cache line,由于此時cache line中存盤的是地址0x00地址對應的資料,所以此時依然會cache缺失,然后又要從主存中加載0x40地址資料到第1行cache line中,
- 同理,繼續訪問0x80地址,依然會cache缺失,這就相當于每次訪問資料都要從主存中讀取,這種情況下cache的存在并沒有對性能有什么提升,
訪問0x40/0x80地址時,就會把0x00地址快取的資料替換,這種現象叫做cache 顛簸(cache thrashing),
3.2 組相聯映射方式
路(way)的概念:將cache平均分成多份,每一份就是一路,本小節我們依然假設cache size為64 Bytes ,cache line size是8 Bytes,以兩路相連快取為例(兩路組相連快取就是將cache平均分成2份,每份32 Bytes),如下圖所示:
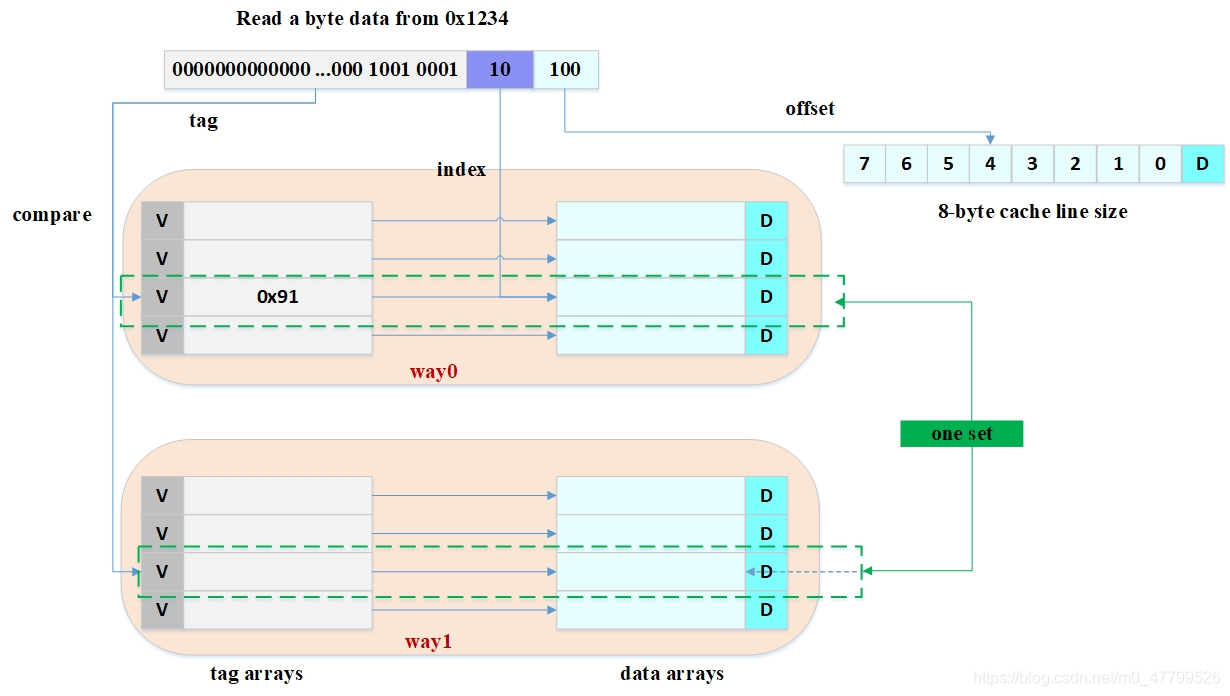
??cache被分成2路,每路包含4行cache line,所有索引一樣的cache line組合在一起稱之為 組(set),上圖中一個組有兩個cache line,總共4個組,我們依然假設從地址0x1234地址讀取一個位元組資料:由于cache line size是8 Bytes,因此offset需要3 bits,這和之前直接映射快取一樣,不一樣的地方是index,在兩路組相連快取中,index只需要2 bits,因為一路只有4行cache line,上圖中根據index找到第3行cache line,第3行對應2個cache line,分別對應way 0和way 1,因此index也可以稱作 set index(組索引),先根據index找到set,然后將組內的所有cache line對應的tag取出來和地址中的tag部分對比,如果其中一個相等就意味著命中,
兩路組相連快取優缺點:
??兩路組相連快取較直接映射快取最大的差異就是:一個地址對應的資料可以對應2個cache line,而直接映射快取一個地址只對應一個cache line,
(1)缺點
??兩路組相連快取的硬體成本相對于直接映射快取更高,因為其每次比較tag的時候需要比較多個cache line對應的tag(某些硬體可能還會做并行比較,增加比較速度,這就增加了硬體設計復雜度),
(2)優點
??有助于降低cache顛簸可能性,
原因如下:
??根據兩路組相連快取的作業方式,可以畫出主存地址0x00-0x60地址對應的cache分布圖,
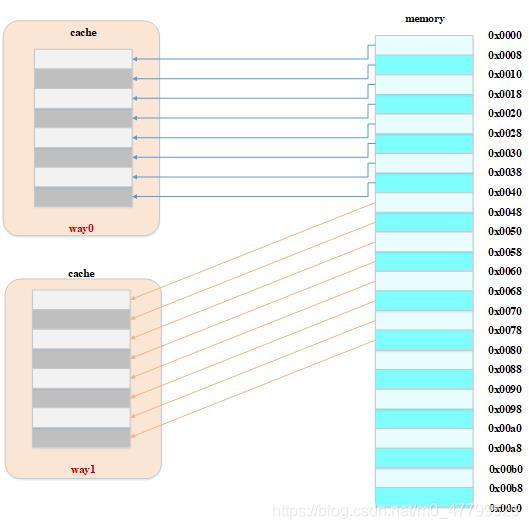
對于兩路組相連映射方式,如果一個程式試圖依次訪問地址0x00、0x40、0x80時:
??0x00地址的資料可以被加載到way 0,0x40可以被加載到way 1(0x80地址資料占不考慮),這樣就在一定程度上避免了直接映射快取的顛簸現象,在兩路組相連快取的情況下,0x00和0x40地址的資料都可以被同時快取在cache中,假設,如果我們是N路(多路)組相連快取,后面繼續訪問0x80,也可以同時快取在cache中,
??因此,當cache size一定的情況下,組相連快取對性能的提升最差情況下也和直接映射快取一樣,在大部分情況下組相連快取效果比直接映射快取好,同時,其降低了cache顛簸的頻率,從某種程度上來說,直接映射快取是組相連快取的一種特殊情況,每個組只有一個cache line而已,因此, 直接映射快取也可以稱作單路組相連快取,
3.3 全相連映射方式
??上一節描述了組相連快取的優缺點,可以發現優點遠遠大于缺點,那么如果所有的cache line都在一個組內,豈不是性能更好,是的,這種快取就是全相連快取(Full associative cache),本小節我們依然假設cache size為64 Bytes ,cache line size是8 Bytes為例進行說明,
??由于所有的cache line都在一個組內,因此地址中不需要set index部分,因為,只有一個組可以被選擇,根據地址中的tag部分和所有的cache line對應的tag進行比較(硬體上可能并行比較也可能串行比較),哪個tag比較相等,就意味著命中某個cache line,因此,在全相連快取中,任意地址的資料可以快取在任意的cache line中,所以,這可以最大程度的降低cache顛簸的頻率,但是硬體成本上也是更高,
??因此,綜合成本的問題,同時為了解決直接映射高速快取中的高速快取顛簸問題,組相聯(set associative)的高速快取結構在現代處理器中得到廣泛應用,
4. cache line作為傳輸單位的原因?
為什么cache line大小是cache控制器和主存之間資料傳輸的最小單位呢?
因為每個cache line只有一個dirty bit,這一個dirty bit代表著整個cache line是否被修改的狀態,
5. Cache組織方式
cache控制器根據地址查找判斷是否命中,這里的地址究竟是虛擬地址(virtual address,VA)還是物理地址(physical address,PA)?
??我們應該清楚CPU發出對某個地址的資料訪問,這個地址其實是虛擬地址,虛擬地址經過MMU轉換成物理地址,最終從這個物理地址讀取資料,因此cache的硬體設計既可以采用虛擬地址也可以采用物理地址甚至是取兩者地址部分組合作為查找cache的依據,
5.1 虛擬高速快取(VIVT)
虛擬高速快取,這種cache硬體設計簡單,在cache誕生之初,大部分的處理器都使用這種方式,虛擬高速快取以虛擬地址作為查找物件,如下圖所示,
??虛擬地址直接送到cache控制器,如果cache hit,直接從cache中回傳資料給CPU,如果cache miss,則把虛擬地址發往MMU,經過MMU轉換成物理地址,根據物理地址從主存(main memory)讀取資料,由于根據虛擬地址查找高速快取,所以是用虛擬地址中部分位域作為索引(index),找到對應的的cacheline,然后根據虛擬地址中部分位域作為標記(tag)來判斷cache是否命中,因此,針對這種index和tag都取自虛擬地址的高速快取稱為虛擬高速快取,簡稱VIVT(Virtually Indexed Virtually Tagged),
虛擬高速快取(VIVT)優缺點:
(1)優點
??虛擬高速快取的優點是不需要每次讀取或者寫入操作的時候把虛擬地址經過MMU轉換為物理地址,這在一定的程度上提升了訪問cache的速度,畢竟MMU轉換虛擬地址需要時間,同時硬體設計也更加簡單,
(2)缺點
??正是使用了虛擬地址作為tag,引入很多軟體使用上的問題, 作業系統在管理高速快取正確作業的程序中, 主要會面臨兩個問題,歧義(ambiguity)和別名(alias),為了保證系統的正確作業,作業系統負責避免出現歧義和別名,
5.1.1 歧義(ambiguity)
歧義是指不同的資料在cache中具有相同的tag和index,cache控制器判斷是否命中cache的依據就是tag和index,這種情況下,cache控制器根本沒辦法區分不同的資料,這就產生了歧義,
什么情況下發生歧義呢?
不同的物理地址存盤不同的資料,只要相同的虛擬地址映射不同的物理地址就會出現歧義,
例如兩個獨立的行程,就可能出現相同的虛擬地址映射不同的物理地址的場景:
??假設A行程虛擬地址0x1234映射的物理地址為0x2000,B行程虛擬地址0x1234映射的物理地址為0x3000,當A行程運行時,訪問0x1234地址會將物理地址0x2000的資料加載到cacheline中,當A行程切換到B行程的時候,B行程訪問0x1234時,會直接出現cache hit,此時B行程就訪問了錯誤的資料,B行程本來想得到物理地址0x3000對應的資料,但是卻由于cache hit得到了物理地址0x2000的資料,
??作業系統如何避免歧義的發生呢?當我們切換行程的時候,可以選擇flush所有的cache,flush cache操作有兩種可選的操作方式:(1)使主存盤器有效,針對write back高速快取(先更新快取,替換時將修改過的塊寫回記憶體),首先應該使主存盤器有效,保證已經修改資料的cacheline寫回主存盤器,避免修改的資料丟失,(2)使高速快取無效,保證切換后的行程不會錯誤的命中上一個行程的快取資料,
因此,切換后的行程剛開始執行的時候,將會由于大量的cache miss導致性能損失,所以,VIVT高速快取明顯的缺點之一就是經常需要flush cache以保證歧義不會發生,最終導致性能的損失,
5.1.2 別名(alias)
當不同的虛擬地址映射相同的物理地址,而這些虛擬地址的index不同,此時就發生了別名現象(多個虛擬地址被稱為別名),通俗點來說就是指同一個物理地址的資料被加載到不同的cacheline中就會出現別名現象, 考慮這樣的一個例子,虛擬地址0x1000和0x4000都映射到相同的物理地址0xa000,這意味著行程既可以從0x1000讀取資料,也能從地址0x4000讀取資料,假設系統使用的是直接映射VIVT高速快取,cache更新策略采用寫回機制,并且使用虛擬地址的位<15…4>作為index,那么虛擬地址0x1000和虛擬地址0x4000的index分別是0x100和0x400,這意味同一個物理地址的資料會加載到不同的cacheline,假設物理地址0xa000存盤的資料是0x55aa,程式先訪問0x1000把資料0x55aa加載到第0x100(index)行cacheline中,接著訪問0x4000,會將0x55aa再一次的加載到第0x400(index)行cacheline中,現在程式將0x1000地址資料修改成0xaaff,由于采用的是寫回策略,因此修改的資料依然保留在cacheline中,并未刷回主存,當程式試圖訪問0x4000的時候由于cache hit導致讀取到舊的資料0x55aa,這就造成了資料不一致現象,這不是我們想要的結果,可以選擇下面的方法避免這個問題,
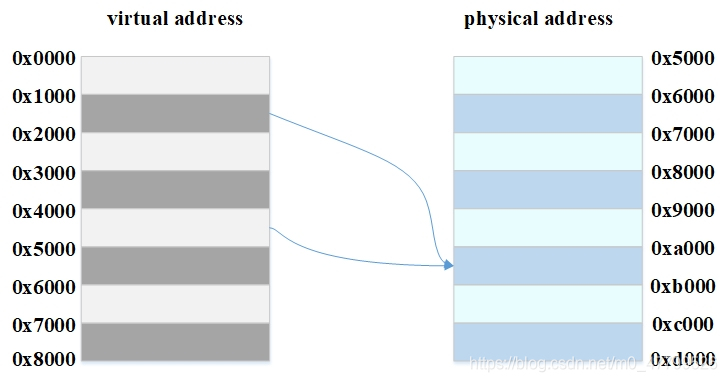
別名的規避方法
??針對共享資料所在頁的映射方式采用nocache映射,例如上面的例子中,0x1234和0x5678映射物理地址0xa000的時候都采用nocache的方式,這樣不通過cache的訪問,肯定可以避免這種問題,但是這樣就損失了cache帶來的性能好處,這種方法既適用于不同行程共享資料,也適用于同一個行程共享資料,
??如果是不同行程之間共享資料,還可以在行程切換時主動flush cache(使主存盤器有效和使高速快取無效)的方式避免別名現象,但是,如果是同一個行程共享資料該怎么辦?除了nocache映射之外,還可以有另一種解決方案,這種方法只針對直接映射高速快取,并且使用了寫分配機制有效,在建立共享資料映射時,保證每次分配的虛擬地址都索引到相同的cacheline,這種方式,后面還會重點說,
5.2 物理高速快取(PIPT)
??通過對VIVT高速快取的了解,可以知道VIVT高速快取存在歧義和名別兩大問題,主要問題原因是:tag取自虛擬地址導致歧義,index取自虛擬地址導致別名,所以,如果想讓作業系統少操心,最簡單的方法是tag和index都取自物理地址,物理的地址tag部分是獨一無二的,因此肯定不會導致歧義,而針對同一個物理地址,index也是唯一的,因此加載到cache中也是唯一的cacheline,所以也不會存在別名,我們稱這種cache為物理高速快取,簡稱PIPT(Physically Indexed Physically Tagged),PIPT作業原理如下圖所示:
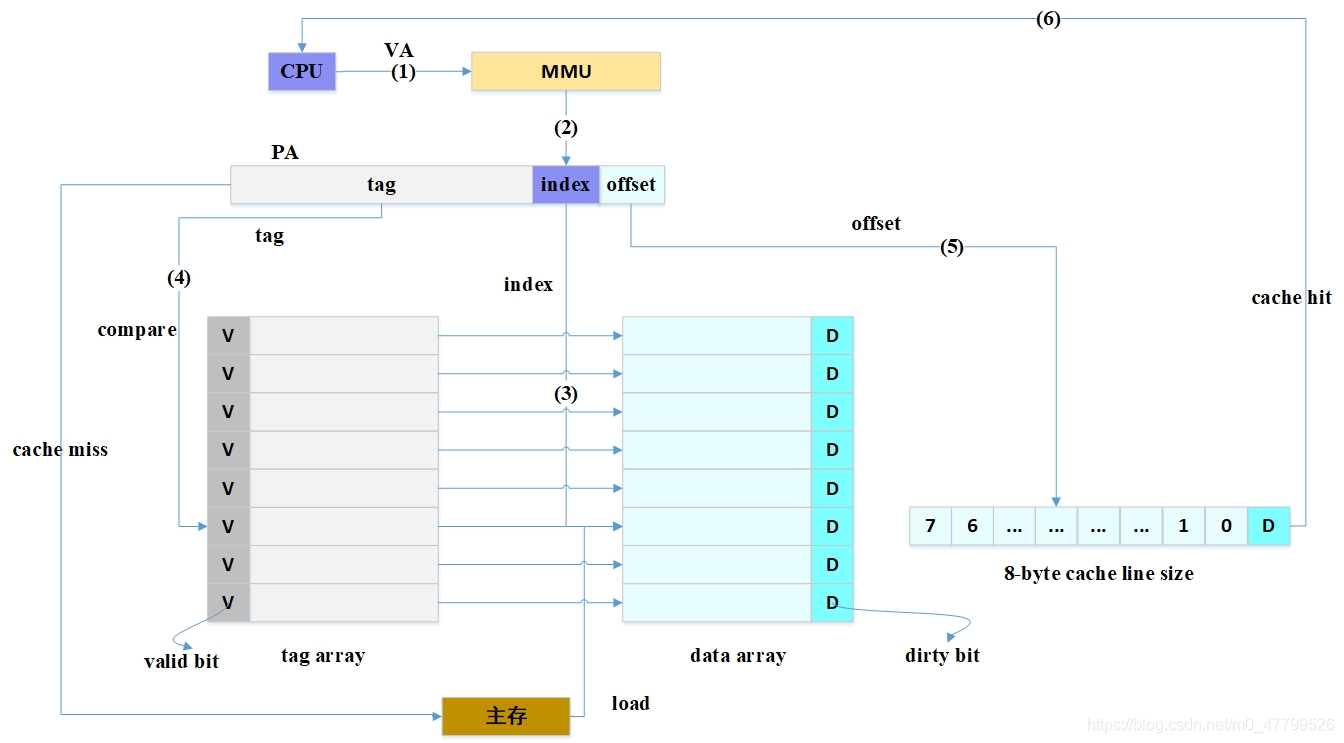
??CPU發出的虛擬地址經過MMU轉換成物理地址,物理地址發往cache控制器查找確認是否命中cache,雖然PIPT方式在軟體層面基本不需要維護,但是硬體設計上比VIVT復雜很多,因此硬體成本也更高,同時,由于虛擬地址每次都要翻譯成物理地址,因此在查找性能上沒有VIVT方式簡潔高效,畢竟PIPT方式需要等待虛擬地址轉換物理地址完成后才能去查找cache,而且,為了加快MMU翻譯虛擬地址的速度,硬體上也會加入一塊cache,作用是快取虛擬地址和物理地址的映射關系,這塊cache稱之為TLB(Translation Lookaside Buffer),當MMU需要轉換虛擬地址時,首先從TLB中查找,如果cache hit,則直接回傳物理地址,如果cache miss則需要MMU查找頁表,這樣就加快了虛擬地址轉換物理地址的速度,如果系統采用的PIPT的cache,那么軟體層面基本不需要任何的維護就可以避免歧義和別名問題,這是PIPT最大的優點,現在的CPU很多都是采用PIPT高速快取設計,在Linux內核中,可以看到針對PIPT高速快取的管理函式都是空函式,無需任何的管理,
5.3 物理標記的虛擬高速快取(VIPT)
??為了提升cache查找性能,通常不想等到虛擬地址轉換物理地址完成后才去查找cache,因此,可以使用虛擬地址對應的index位查找cache,與此同時(硬體上同時進行)將虛擬地址發到MMU轉換成物理地址,當MMU轉換完成,同時cache控制器也查找完成,此時比較cacheline對應的tag和物理地址tag域,以此判斷是否命中cache,我們稱這種高速快取為物理標記的虛擬高速快取VIPT(Virtually Indexed Physically Tagged),
??VIPT以物理地址部分位域作為tag,因此不會存在歧義問題,但是,采用了虛擬地址作為index,所以可能依然存在別名問題,是否存在別名問題,需要考慮cache的結構,我們需要分情況考慮,
5.3.1 VIPT Cache什么情況不存在別名
我們知道VIPT的優點是查找cache和MMU轉換虛擬地址同時進行,所以性能上有所提升,歧義問題雖然不存在了,但是別名問題依舊可能存在,那么什么情況下別名問題不會存在呢?Linux系統中映射最小的單位是頁,頁大小通常有4KB、16KB、64KB,本小節以4KB頁大小為例,此時虛擬地址和其映射的物理地址的位<11…0>是一樣的,
- 針對直接映射高速快取,如果 cache的size小于等于4KB,這就意味著無論使用虛擬地址還是物理地址的低位查找cache結果都是一樣的,因為虛擬地址和物理地址對應的index是一樣的,這種情況,VIPT實際上相當于PIPT,軟體維護上和PIPT一樣,
- 如果是一個四路組相連高速快取,只要滿足 一路的cache的大小小于等于4KB,那么VIPT方式的cache也不會出現別名問題,
5.3.2 VIPT Cache的別名問題
??假設系統使用的是直接映射高速快取,cache大小是8KB,cacheline大小是256位元組,這種情況下的VIPT就存在別名問題,因為index來自虛擬地址位<12…8>,虛擬地址和物理地址的位<11…8>是一樣的,但是bit12卻不一定相等, 假設虛擬地址0x0000和虛擬地址0x1000都映射相同的物理地址0x4000,那么程式讀取0x0000時,系統將會從物理地址0x4000的資料加載到第0x00行cacheline,然后程式讀取0x1000資料,再次把物理地址0x4000的資料加載到第0x10行cacheline,別名問題就出現了,相同物理地址的資料被加載到不同cacheline中,
5.3.3 如何解決VIPT Cache別名問題
??針對共享映射,我們需要想辦法避免相同的物理地址資料加載到不同的cacheline中,對于5.3.2中的 例子,就要避免0x1000映射0x4000的情況發生,我們可以將虛擬地址0x2000映射到物理地址0x4000,而不是用虛擬地址0x1000,0x2000對應第0x00行cacheline,這樣就避免了別名現象出現,
??因此,在建立共享映射的時候,返回的 虛擬地址都是按照cache大小對齊的地址,這樣就沒問題了,如果是多路組相連高速快取的話,回傳的虛擬地址必須是滿足一路cache大小對齊,在Linux的實作中,就是通過這種方法解決別名問題,
5.3.4 小結
??VIVT Cache問題太多,軟體維護成本過高,是最難管理的高速快取,所以現在基本只存在歷史的文章中,現在我們基本看不到硬體還在使用這種方式的cache,現在使用的方式是PIPT或者VIPT,如果多路組相連高速快取的一路的大小小于等于4KB,一般硬體采用VIPT方式,因為這樣相當于PIPT,,當然,如果一路大小大于4KB,一般采用PIPT方式,也不排除VIPT方式,這就需要作業系統多操點心了,
6. cache的層級
6.1 兩級cache
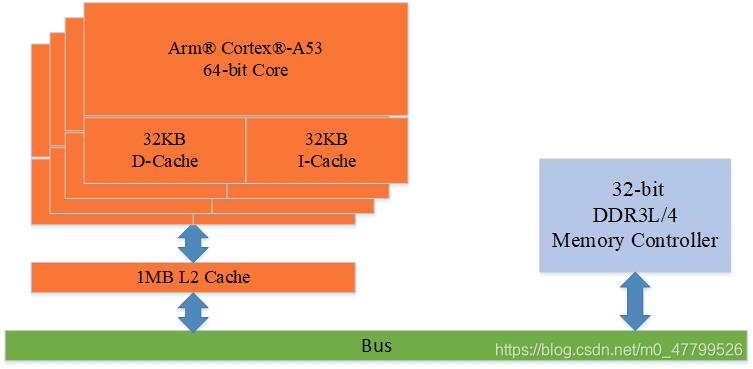
??下圖是一個兩級cache的框圖,可以看到,CPU核心會內置了L1 的data cache和L1的指令cache,然后在外面4個core會有一個共享的L2的cache,L2的cache連接到系統總線上,
6.2 三級cache
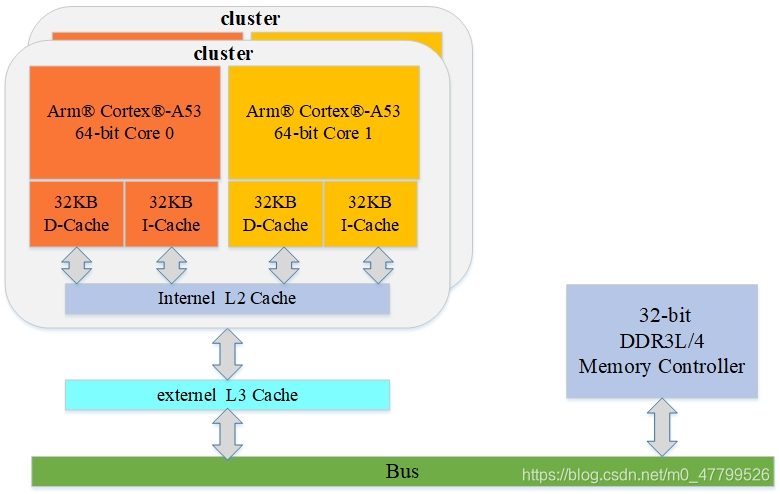
??下圖是三級cache的情況,這個圖是arm一個經典的多cluster架構圖,每個cluster里有多個core,比如這個圖上,一個cluster里有兩個core,core0和core1,每個core都有自己獨立的L1 cache,Core0和core1共享L2 cache,然后兩個cluster還共享一個external Level 3 cache,L3 cache連接到系統總線上,包括記憶體DDR也是連接到系統總線上,
7. cache的訪問延時
??從CPU的角度來看:各級cache的訪問時間,越靠近cpu那邊,訪問速度是越快的,越靠近記憶體那邊,訪問速度是越慢,以下表格是Core i7 Xeon 5500 Series Data Source Latency (approximate)的測驗資料(arm相關的資料未找到),不過這個不要緊,重要的是我們去理解多級cache訪問延遲的一個概念,
| 訪問型別 | 延遲 |
|---|---|
| local L1 CACHE hit | ~4 cycles ( 2.1 - 1.2 ns ) |
| local L2 CACHE hit | ~10 cycles ( 5.3 - 3.0 ns ) |
| local L3 CACHE hit, line unshared | ~40 cycles ( 21.4 - 12.0 ns ) |
| local L3 CACHE hit, shared line in another core | ~65 cycles( 34.8 - 19.5 ns ) |
| local L3 CACHE hit, modified in another core | ~75 cycles( 40.2 - 22.5 ns ) |
| remote L3 CACHE | ~100-300 cycles ( 160.7 - 30.0 ns ) |
| local DRAM | ~60 ns |
| remote L3 CACHE | ~100 ns |
??從表中可以看到,如果L1 cache命中的話,CPU訪問大概4個時鐘周期,如果L2 cache命中的話,大約10個時鐘周期,從這可以看出,L2 cache比L1 cache慢一倍以上,如果L3 cache命中,這里還分了好幾種情況,基本上是根據MESI協議來分的,比如cache line沒有共享,那就是獨占狀態,那么大約40個時鐘周期,如果cache line和其他CPU共享,那么需要65個時鐘周期,如果cache line被其他CPU修改過,那么需要75個時鐘周期,因為MESI協議需要消耗一部分總線帶寬,如果訪問遠端的L3 cache,這里遠端指的是遠端NUMA節點的L3 cache,大概要100~300時鐘周期,如果訪問本地記憶體ddr,大約需要60納秒,所以,你可以對比一下,如果訪問一個資料,L1 cache命中和直接訪問記憶體之間的速度的差距,相差很大,最后一行,訪問遠端NUMA節點的延遲更長,
8. cache的策略
8.1 cache的分配策略
??cache的分配策略是指我們什么情況下應該為資料分配cache line,cache分配策略分為讀和寫兩種情況,
| 型別 | 說明 |
|---|---|
| read allocate | 當CPU讀資料時,發生cache缺失,這種情況下都會分配一個cache line快取從主存讀取的資料,默認情況下,cache都支持讀分配, |
| write allocate | 當CPU寫資料發生cache缺失時,才會考慮寫分配策略,當我們不支持寫分配的情況下,寫指令只會更新主存資料,然后就結束了,當支持寫分配的時候,我們首先從主存中加載資料到cache line中(相當于先做個讀分配動作),然后會更新cache line中的資料, |
此外:
- Write-Back,write-through,Non-cacheable 主要講的是回寫的策略,
- Shareability主要講的cache的共享屬性和范圍,比如后面講到的inner share,outer share,POC和POU等概念,
通常,cache的相關策略是在MMU頁表里進行配置的,還有一點很重要就是只有normal的記憶體才能被cacheable,
8.2 cache的回寫策略
??一般cache有三種回寫策略,一個是Non-cacheable,一個是write back,另外一個是write throuhgt,(準確的講應該是兩種,因為第一種是Non-cacheable)
| 型別 | 說明 |
|---|---|
| Non-cacheable | 不使用快取,直接更新記憶體 |
| Write-Throuth Cacheable | 當CPU執行store指令并在cache命中時,我們更新cache中的資料并且更新主存中的資料,cache和主存的資料始終保持一致, |
| Write-Back Cacheable | 當CPU執行store指令并在cache命中時,我們只更新cache中的資料,并且每個cache line中會有一個bit位記錄資料是否被修改過,稱之為dirty bit(前面的圖片,cache line旁邊有一個D就是dirty bit),我們會將dirty bit置位,主存中的資料只會在cache line被替換或者顯式的clean操作時更新,因此,主存中的資料可能是未修改的資料,而修改的資料躺在cache中,cache和主存的資料可能不一致, |
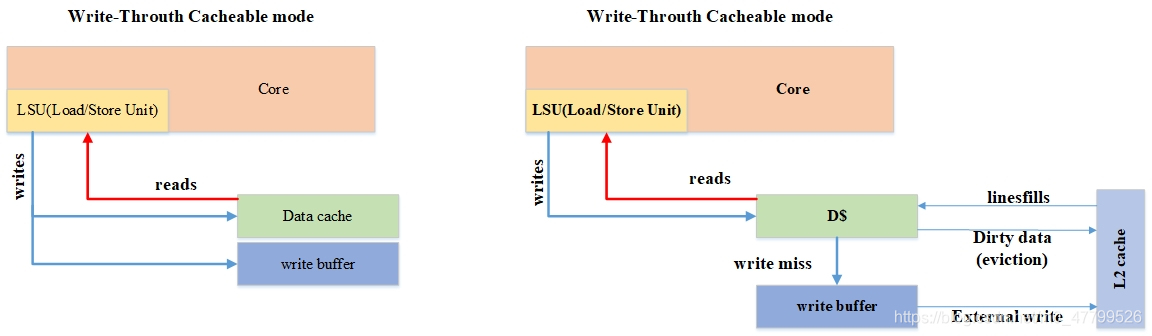
- 對于WT(Write-Throuth)寫直通模式:進行寫操作時,資料同時寫入當前的高速快取、下一級高速快取或主存盤器中,直寫模式可以降低高速快取一致性的實作難度,其最大的缺點是消耗比較多的總線帶寬,對于arm處理器來說,把WT模式看成Non-cacheable,因為在內部實作來看,里面有一個write buffer的部件,WT模式相當于把write buffer部件給disable了,
- Write-Back 回寫模式:在進行寫操作時,資料直接寫入當前高速快取,而不會繼續傳遞,當該高速快取行被替換出去時,被改寫的資料才會更新到下一級高速快取或主存盤器中,該策略增加了高速快取一致性的實作難度,但是有效降低了總線帶寬需求,
9. 共享域
為了支持資料一致性協議 ,需要增加硬體很多開銷,會降低系統的性能,同時也會增加系統的功耗,但是,很多時候并不需要系統中的所有模塊之間都保持資料一致性,而只需要在系統中的某些模塊之間保證資料一致性就行了,因此,需要對系統中的所有模塊,根據資料一致性的要求,做出更細粒度的劃分,ARMv8架構將這種劃分稱作為域(Domain)
共享域一共劃分成了四類:
| 共享域型別 | 說明 |
|---|---|
| 非共享域(Non-shareable) | 處于這個域中的記憶體只由當前CPU核訪問,所以,如果一個記憶體區域是非共享的,系統中沒有任何硬體會保證其快取一致性,如果一不小心共享出去了,別的CPU核可以訪問了,那必須由軟體自己來保證其一致性, |
| 內部共享域(Inner Shareable) | (1) 處于這個域中的記憶體可以由系統中的多個模塊同時訪問,并且系統硬體保證對于這段記憶體,對于處于同一個內部共享域中的所有模塊,保證快取一致性, (2) 一個系統中可以同時存在多個內部共享域,對一個內部共享域做出的操作不會影響另外一個內部共享域, |
| 外部共享域(Outer Shareable) | (1) 處于這個域中的記憶體也可以由系統中的多個模塊同時訪問,并且系統硬體保證對于這段記憶體,對于處于同一個外部共享域中的所有模塊,保證快取一致性,外部共享域可以包含一個或多個內部共享域,但是一個內部共享域只能屬于一個外部共享域,不能被多個外部共享域共享, (2) 對一個外部共享域做出的操作會影響到其包含的所有的內部共享域, |
| 全系統共享域(Full System) | 表示對記憶體的修改可以被系統中的所有模塊都感知到 |
??在一個具體的系統中,不同域的劃分是由硬體平臺設計者決定的,不由軟體控制,并且,Arm的檔案中也沒有提及具體要怎么劃分,但有一些指導原則,一般在一個作業系統中可以看到的所有CPU核要分配在一個內部域里面,如下圖所示:
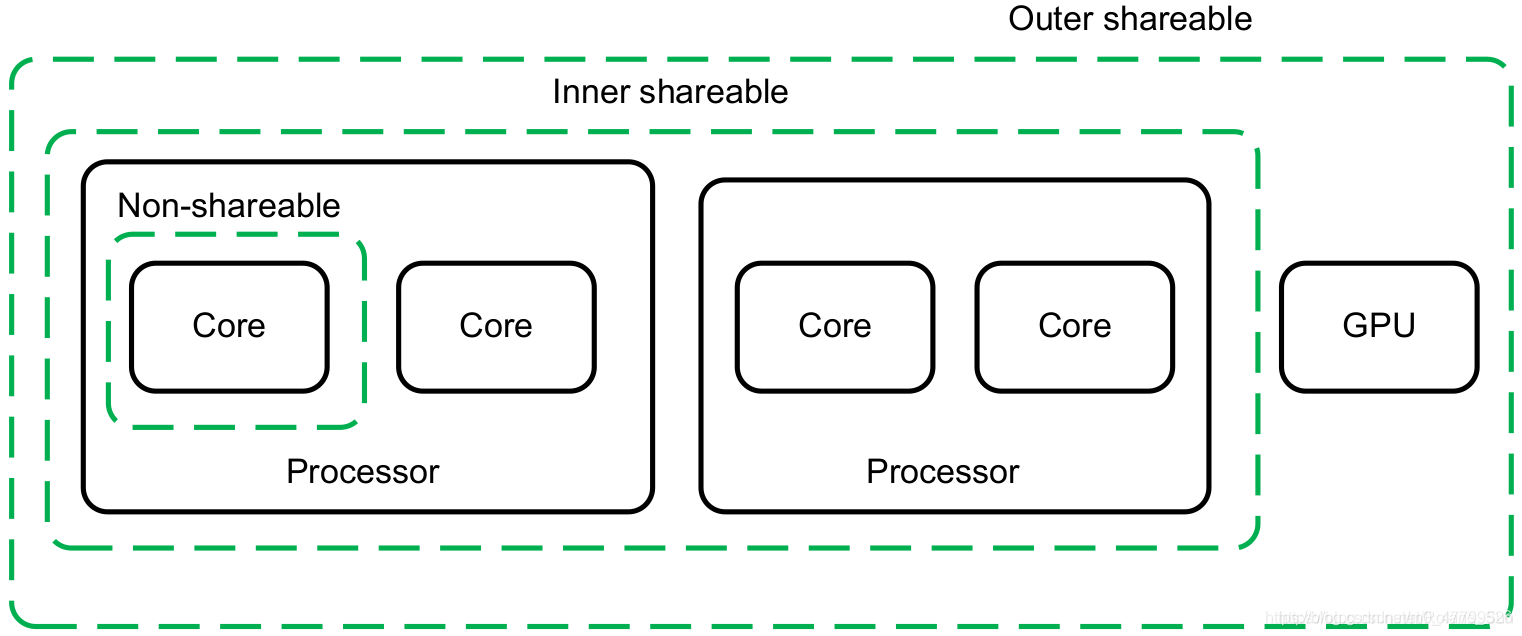
??這些域的劃分只是為了更細粒度的管理記憶體的快取一致性,理論上所有記憶體都可以放到全系統共享域中,從功能上說也可以,但會影響性能,
?? 可快取性和共享性一定是對普通記憶體才有的概念,設備記憶體一定是不支持快取的,且是外部共享的,
inner share和outer share:
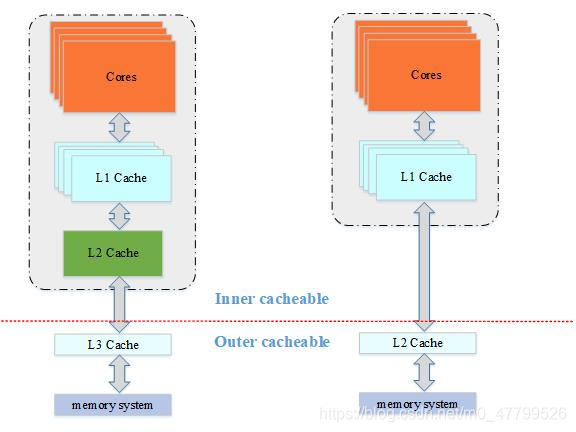
??怎么去區分inner share還是outer share呢,arm手冊里講了,不同的SOC設計有不同的區分方法,不過有一個通用的規則: inner share通常是CPU IP集成的caches,包括CPU IP集成的L1 data cache和L2 cache,而outer share是通過總線連接到cache,比如外接的L3 cache等,
??下面這個圖,比較直觀,這個圖,虛線分成了兩部分,上半部都是inner share,下半部都是outershare,上半部表示是CPU IP集成的cache,左側的cores集成了L1和L2cache,而右側的core集成了L1 cache,那虛線框出來的都是inner share,我們再來看虛線下面,通過總線外接了L2 cache或者L3 cache,都是outer share,
10. PoU和PoC的區別
10.1 PoU(Point of Unification - 統一點)
Point of Unification (PoU)
The PoU for a PE is the point by which the instruction and data caches and the translation table walks of that PE are guaranteed to see the same copy of a memory location. In many cases, the Point of Unification is the point in a uniprocessor memory system by which the instruction and data caches and the translation table walks have merged. The PoU for an Inner Shareable shareability domain is the point by which the instruction and data caches and the translation table walks of all the PEs in that Inner Shareable shareability domain are guaranteed to see the same copy of a memory location. Defining this point permits self-modifying software to ensure future instruction fetches are associated with the modified version of the software by using the standard correctness policy of:
1. Clean data cache entry by address.
2. Invalidate instruction cache entry by address
PoU: 表示一個CPU中的指令cache,資料cache還有MMU,TLB等看到的是同一份的記憶體拷貝,
- PoU for a PE,是說保證PE看到的I/D cache和MMU是同一份拷貝,大多數情況下,PoU是站在單核系統的角度來觀察的,
- PoU for inner share,是說在內部共享域里面的所有CPU核都能看到相同的一份拷貝,
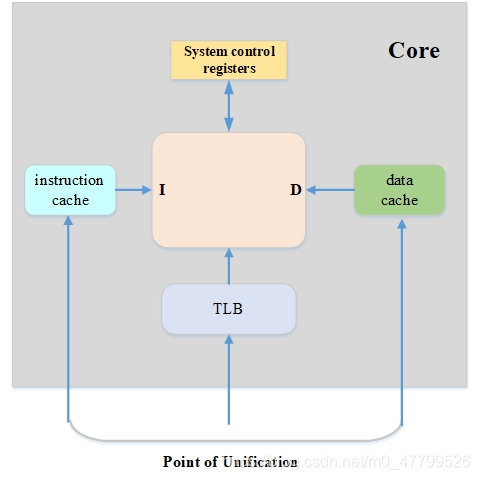
所以,PoU有兩個觀察點,一個是PoU for a PE,PE就是cpu core,另外一個是PoU for inner share,關于PoU的描述,請參閱《Arm? Architecture Reference Manual Armv8, for Armv8-A architecture profile - The AArch64 System Level Memory Model D4.4 Cache support》,
其中,提到self-modifing code在PoU for inner share里,使用下面兩條簡單的指令就能保證data cache和指令cache的一致性,如果不是PoU for inner share,要保證data cache和指令cache的一致性,需要額外的memory barrier的指令,
10.2 PoC(Point of Coherency - 一致性點)
Point of Coherency (PoC)
The point at which all agents that can access memory are guaranteed to see the same copy of a memory location for accesses of any memory type or cacheability attribute. In many cases this is effectively the main system memory, although the architecture does not prohibit the implementation of caches beyond the PoC that have no effect on the coherency between memory system agents.
PoC: 是對于不同的Master看到的一致性的記憶體; 例如對于cores,DSP,DMA他們一致性的記憶體就是main memory,所以main memory是PoC這個點,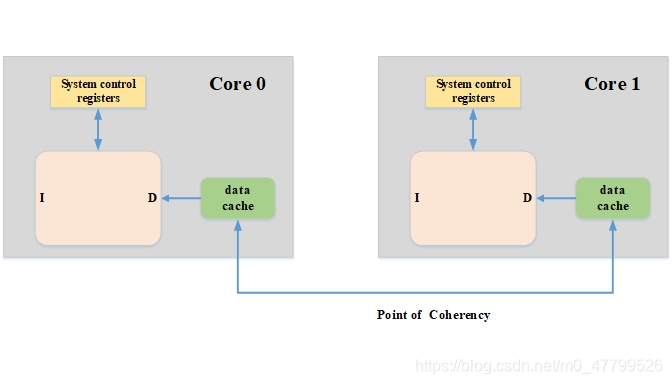
10.3 PoU和PoC的區別
??最大的一個區別就是PoC是系統一個概念,和系統配置相關,它包含了系統所有有能力訪問記憶體的設備,包括cpu,gpu,dma等,這些都稱為observer,觀察者( 全域快取一致性角度),而PoU是個區域的概念( 處理器快取一致性角度),
??系統配置的不同可能會影響PoU的范圍,我們舉個例子,在Cortex-A53可以配置L2 cache和沒有L2 cache,可能會影響PoU的范圍,為什么會這樣,因為我們支持PoU有一個重要的觀察點 - PoU for inner share,而inner share的劃分和 這個cache是不是 CPU IP集成有關,
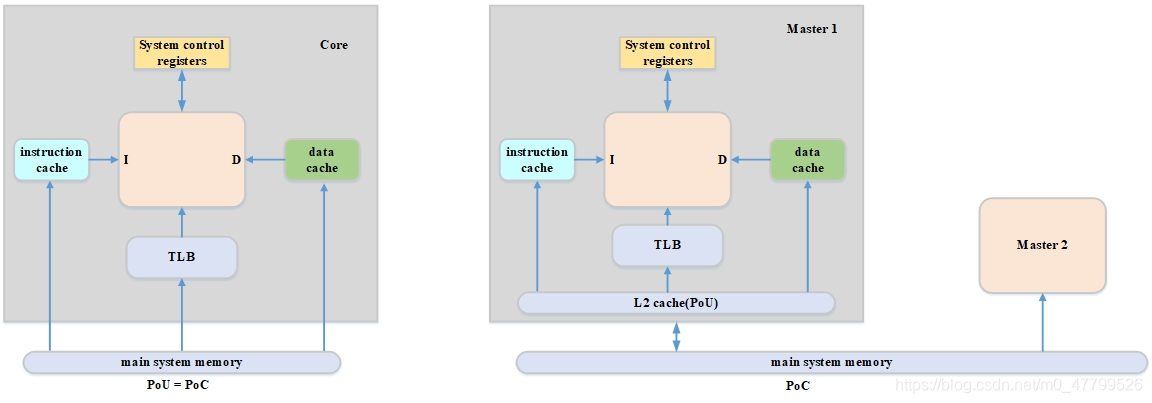
比如下面這個圖,左邊,沒有集成L2 cache,那么這時候POU等于了POC,而且也沒有其他的master,右邊那個圖,CORE里集成了L2 cache,那么core,L1 cache和L2 cache構成了PoU for inner share,而master a和master b和系統記憶體構成了PoC,
11. Cache維護指令
Armv8里定義的Cache的管理的操作有三種:
| 訪問型別 | 延遲 |
|---|---|
| 無效(Invalidate) | 整個高速快取或者某個高速快取行,高速快取上的資料會被丟棄, |
| 清除(Clean) | 整個高速快取或者某個高速快取行,相應的高速快取行會被標記為臟,資料會寫回到下一級高速快取中或者主存盤器中, |
| 清零(Zero)操作 | 在某些情況下,對高速快取進行清零操作起到一個預取和加速的功效,比如當程式需要使用一大塊臨時記憶體,在初始化階段對這個記憶體進行清零操作,這時高速快取控制器會主動把這些零資料寫入高速快取行中,若程式主動使用高速快取的清零操作,那么將大大減少系統內部總線的帶寬, |
對高速快取的操作可以指定不同的范圍:
- 整塊高速快取,
- 某個虛擬地址,
- 特定的高速快取行或者組和路,
12. Cache指令格式
參見:
13. cache一致性
??由于快取存在于cpu與記憶體中間,所以任何外設對記憶體的修改并不能保證cache中也得到同樣的更新,同樣處理器對快取中內容的修改也不能保證記憶體中的資料 得到更新,這種快取中資料與記憶體中資料的不同步和不一致現象將可能導致使用DMA 傳輸資料時 或 處理器運行自修改代碼時產生錯誤,
出現不一致的原因有三個:共享可寫的資料、行程遷移和I/O傳輸,
??cache一致性關注的是同一個資料在多個高速快取和記憶體中的一致性問題,解決多處理機Cache一致性問題提出了兩種解決辦法:偵聽一致性協議和基于目錄的一致性協議,由于多數SMP(對稱多處理機)結構是采用總線互連的,偵聽一致性協議是基于偵聽總線事務來保持Cache一致性的協議,所以多數產品采用偵聽協議,
??基于總線互連的SMP是通過高速共享總線將若干個商用的微處理器(包括高速快取)與共享存盤器連接起來,因此,可以利用總線來實作高速快取一致性,總線上的每個設備都能偵聽到總線上出現的事務,當一個處理器向存盤系統發出一個讀/寫請求時,它的本地高速快取控制器將檢查自己的狀態,并采取相應的動作,所有的高速緩沖器都偵聽總線上出現的事務,一旦發現與自己有關的事務,就執行相應的動作來保證高速快取的一致性,
偵聽一致性協議是利用總線的一下兩個特點來實作一致性的:
- 一是總線上的所有事務對所有的高速快取控制器都是可見的,
- 二是總線上所有事務以相同的次序內所有的高速快取控制器可見,
關于總線監聽協議,作者暫時也沒搞懂,有興趣的可以參考:Linux記憶體管理:ARM64體系結構與編程之cache(3):cache一致性協議(MESI、MOESI)、cache偽共享,
14. linux查看Cache資訊的方式
14.1 Linux下查看CPU Cache級數,每級大小
1. 第一種方法:
dmesg | grep cache
[ 0.000000] Detected VIPT I-cache on CPU0
[ 0.000000] Dentry cache hash table entries: 131072(order: 8,1048576 bytes)
[ 0.000000] Inode-cache hash table entries: 65536(order: 524288 bytes)
[ 0.000283] Mount-cache hash table entries: 2048(order: 16384 bytes)
[ 0.000290] Mountponit-cache hash table entries: 2048(order: 16384 bytes)
[ 0.040049] Detected VIPT I-cache on CPU1
[ 0.052061] Detected VIPT I-cache on CPU2
[ 0.064080] Detected VIPT I-cache on CPU3
2. 第二種方法:
# ls /sys/devices/system/cpu/cpu0/cache/index
index0/ index1/ index2/
其中index0和index1分別是L1 Cache的DCache和ICache,
(1) 一級cache, Data cache
# cat /sys/devices/system/cpu/cpu0/cache/index0/level
1
# cat /sys/devices/system/cpu/cpu0/cache/index0/type
Data
# cat /sys/devices/system/cpu/cpu0/cache/index0/size
32K
(2) 一級cache, Instruction cache
[root@gc15 ~]# cat /sys/devices/system/cpu/cpu0/cache/index1/level
1
# cat /sys/devices/system/cpu/cpu0/cache/index1/type
Instruction
# cat /sys/devices/system/cpu/cpu0/cache/index1/size
32K
(3) index2為L2cache的資訊,同物理CPU共享的
# cat /sys/devices/system/cpu/cpu0/cache/index2/level
2
# cat /sys/devices/system/cpu/cpu0/cache/index3/type
Unified
# cat /sys/devices/system/cpu/cpu0/cache/index2/size
1024K
14.2 查看Cache的關聯方式
在 /sys/devices/system/cpu/中查看相應的檔案夾
(1) 如查看cpu0的一級快取中有多少路(Cache被平均分成了幾份)
$cat /sys/devices/system/cpu/cpu0/cache/index0/ways_of_associativity
$4
(2) 如查看cpu0 的一級快取中的有多少組(每一份中有多少個cacheline)
$ cat /sys/devices/system/cpu/cpu0/cache/index0/number_of_sets
$128
14.3 查看cache_line的大小
上面以ls1043的cpu一級快取為例知道了cpu0的一級快取的大小:32k,其包含128個(sets)組,每組有4(ways),則可以算出每一個way(cache_line)的大小 cache_line = 321024/(1284)=64 bytes,當然我們也可以通過以下命令查出cache_line的大小(單位是位元組)
# cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_siz
64
14.4 查看cache的分配策略
# cat /sys/devices/system/cpu/cpu0/cache/index0/alloction_policy ReadWriteAllocate# cat /sys/devices/system/cpu/cpu0/cache/index1/alloction_policy
ReadAllocate
# cat /sys/devices/system/cpu/cpu0/cache/index2/alloction_policy
ReadWriteAllocate
14.5 查看cache的回寫策略
# cat /sys/devices/system/cpu/cpu0/cache/index0/write_policy WriteBack# cat /sys/devices/system/cpu/cpu0/cache/index1/write_policy
cat:can't open 'write_policy':No such file or directory
# cat /sys/devices/system/cpu/cpu0/cache/index2/write_policy
WriteBack
14.5 查看cache的shared_cpu_map
# cat /sys/devices/system/cpu/cpu0/cache/index0/shared_cpu_map 1 # cat /sys/devices/system/cpu/cpu0/cache/index1/shared_cpu_map 1 # cat /sys/devices/system/cpu/cpu0/cache/index2/shared_cpu_map f# cat /sys/devices/system/cpu/cpu1/cache/index0/shared_cpu_map
2
# cat /sys/devices/system/cpu/cpu1/cache/index1/shared_cpu_map
2
# cat /sys/devices/system/cpu/cpu1/cache/index2/shared_cpu_map
f# cat /sys/devices/system/cpu/cpu2/cache/index0/shared_cpu_map
4
# cat /sys/devices/system/cpu/cpu2/cache/index1/shared_cpu_map
4
# cat /sys/devices/system/cpu/cpu2/cache/index2/shared_cpu_map
f
# cat /sys/devices/system/cpu/cpu3/cache/index0/shared_cpu_map
8
# cat /sys/devices/system/cpu/cpu3/cache/index1/shared_cpu_map
8
# cat /sys/devices/system/cpu/cpu3/cache/index2/shared_cpu_map
f
14.6 查看cache的shared_cpu_list
# cat /sys/devices/system/cpu/cpu0/cache/index0/shared_cpu_list 0 # cat /sys/devices/system/cpu/cpu0/cache/index1/shared_cpu_list 0 # cat /sys/devices/system/cpu/cpu0/cache/index2/shared_cpu_list 0-3# cat /sys/devices/system/cpu/cpu1/cache/index0/shared_cpu_list
1
# cat /sys/devices/system/cpu/cpu1/cache/index1/shared_cpu_list
1
# cat /sys/devices/system/cpu/cpu1/cache/index2/shared_cpu_list
0-3# cat /sys/devices/system/cpu/cpu2/cache/index0/shared_cpu_list
2
# cat /sys/devices/system/cpu/cpu2/cache/index1/shared_cpu_list
2
# cat /sys/devices/system/cpu/cpu2/cache/index2/shared_cpu_list
0-3
# cat /sys/devices/system/cpu/cpu3/cache/index0/shared_cpu_list
3
# cat /sys/devices/system/cpu/cpu3/cache/index1/shared_cpu_list
3
# cat /sys/devices/system/cpu/cpu3/cache/index2/shared_cpu_list
0-3
部分章節摘自:
(1) Linux記憶體管理:ARM64體系結構與編程之cache(1)
(2) Linux記憶體管理:ARM64體系結構與編程之cache(2):cache一致性
(3) Cache的基本知識
(4) 《Arm? Architecture Reference Manual Armv8, for Armv8-A architecture profile - The AArch64 System Level Memory Model D4.4 Cache support》
(5) DMA和cache一致性問題
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/533473.html
標籤:嵌入式
上一篇:第四章 linux字符設備驅動一