這是指向我的 csv 檔案的 Google Drive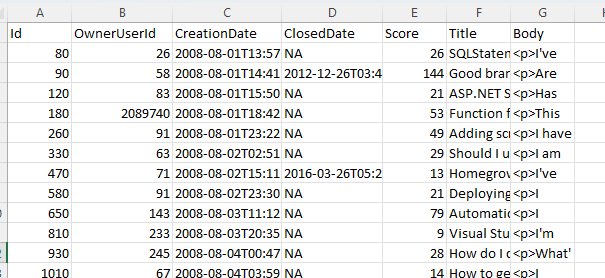
但是當我用 閱讀它時PySpark,它就搞砸了。我認為這是因為 Body 列,它是一個長而復雜的 HTML 字串。你知道如何解決它嗎?我已經更改了定界符選項,但沒有用。
import pyspark
from pyspark.sql import *
from pyspark.sql.functions import *
spark = SparkSession.builder.master("local[*]").getOrCreate()
questionDf = spark.read \
.format('csv')\
.option("header", "true") \
.load("Questions.csv")
questionDf.select("*").filter(col("Id").isNotNull()).limit(100).show()
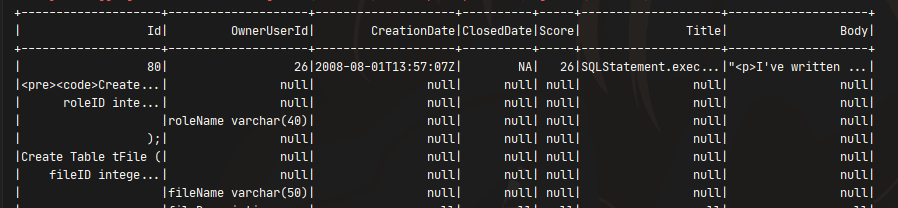
uj5u.com熱心網友回復:
你還需要兩個選項。
# When csv include newlines, parse 1 record that span across multiple lines
.option('multiLine', 'true')
# escape char that is used within quote-wrapped column.
# ex: "hello ""xxx""!" => each side of xxx should have literal 1 double quote.
.option('escape', '"')
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/534884.html
標籤:数据框格式文件阿帕奇火花pysparkapache-spark-sql
上一篇:熊貓排序過濾