我們知道在 Linux 中,“一切皆檔案”,作為系統管理員或者程式員我們每天都需要和大量的文本檔案打交道,Linux 系統為我們提供了三個文本處理工具:grep, sed, 和 awk,它們也被稱為 Linux 文本處理的三劍客被大家廣泛使用,今天先和大家介紹一下 grep 的以及正則運算式的用法,因為 grep 只有和正則運算式結合在一起才會發揮出它強大的威力,
Grep 的用法
grep 是一個強大的文本搜索工具,可以用于在文本檔案中搜索指定格式(正則運算式)的字串,并將匹配的行輸出,它的用法如下:
#grep [選項] 查找條件 目標檔案
比如我們有一個文本檔案,littlestar.txt,它的內容如下:
TWINKLE, twinkle, little star,
How I wonder what you are!
Up above the world so high,
Like a diamond in the sky.
(1) 查找一個字串
比如要查找“twinkle”
#grep "twinkle" littlestar.txt

匹配上的字串用紅色突出顯示出來了,
(2) “-i”忽略大小寫
#grep -i "twinkle" littlestar.txt
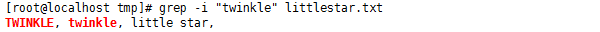
結果可以看到TWINKLE 和 twinkle 都匹配上了
(3) “-n”顯示行號
#grep -n "twinkle" littlestar.txt

發現在結果的最左側顯示行號
(4) “-c”僅顯示匹配到的行號
#grep -c "twinkle" littlestar.txt

結果僅顯示 1,表示第 1 行匹配到了查找的字串
(5) “-o” 僅顯示匹配到的字串,不顯示同行的其他內容
#grep -o "twinkle" littlestar.txt

結果僅顯示 twinkle
(6) “-w”精確匹配單詞
#grep -w "twinkle" littlestar.txt 查找twinkle
#grep -w "twink" littlestar.txt 查找twink

結果顯示完整的單詞 twinkle 可以匹配到,如果只查找 twink 則沒有匹配上
(7) “-v“ 反轉查找,顯示不包含關鍵字的行
#grep -v "twink" littlestar.txt

結果除了第一行,其他都匹配成功了
正則運算式
正則運算式(Regular Expression)是一種描述字串匹配模式的方式,它的應用非常廣泛,幾乎所有的主流編程語音里都有正則運算式的實作,比如 Java,C#,Python等等,當然 Linux 的 Shell 對它也有很好的支持,我們很多時候想要做的是模糊查找,比如以133開頭的手機號,這個時候 grep 就需要用到正則運算式了,
正則運算式有兩個版本,基本正則運算式(BRE)和它的升級版--擴展正則運算式(ERE),我們主要了解一下擴展版,grep 命令需要加上 -E 選項,或者使用 egrep 命令,
正則運算式中用來匹配字串模式的字符被稱作元字符,學習正則運算式主要就是學會元字符的組合運用,元字符主要有下面幾種:
-
用于位置錨定:"^" 和 "$"
-
用于字符匹配:".","[ ]"
-
用于匹配次數:"*","+","?","{ }"
-
用于分組:"( )"
可能看到這里已經有很多人一頭霧水了,正則運算式到底長什么樣呢?下面我們就看一下具體的例子吧,
(1) 位置錨定元字符:
^ 表示以某個字串開頭,$ 表示以某個字串結尾
比如查找以 “TWINK” 開頭的行
#grep -E "^TWINK" littlestar.txt

查找以 “star,” 結尾的行
#grep "star,$" littlestar.txt

(2) 字符匹配元字符:
“.”表示匹配任意單個字符,“[ ]”用來匹配指定范圍內的單個字符
比如 "s..r" 可以匹配以s開頭,r結尾的單詞
#grep "s..r" littlestar.txt

"[ ]" 當中可以放具體的字符,比如 "[Tt]"表示匹配大寫或者小寫的 t
#grep "^[Tt]" littlestar.txt

"[ ]" 也可以用來表示一個范圍,比如 [0-9]表示單個數字,[a-z]表示單個小寫字母,[A-Z]表示一個大寫字母,[a-zA-Z]表示一個字母,包括大小寫,比如 "[A-Z][a-z][a-z][a-z]" 表示首字母大寫,四個字母的一個單詞:
#grep -E "[A-Z][a-z][a-z][a-z]" littlestar.txt
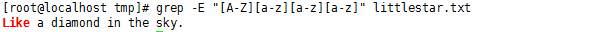
"^"用來表示不在指定范圍內的其他字符,比如[^a-zA-Z]表示所有非字母的字符
#grep -E "[^a-zA-Z]" littlestar.txt

(3)匹配次數元字符
"?" 表示匹配到 0 次或 1 次,比如 "w?in" 表示 w 被匹配到 0 次或 1 次,所以 "win" 或者 "in" 都可以被匹配到
#grep -E "w?in" littlestar.txt

"+" 表示匹配到至少 1 次,比如 "w+in" 就表示至少得有一個字母 w,可以是 "win" 或者 "wwin",但是 "in" 就不能匹配上了
#grep -E "w+in" littlestar.txt

"*" 表示匹配到任意次,可以是 0 次,可以是 1 次,也可以是多次,比如 "w*in" 可以匹配到 "in",也可以匹配到 "win" 或者 "wwin"
#grep -E "w*in" littlestar.txt

"*" 經常與 "." 搭配使用,".*" 表示匹配任意數量的任意字符,比如 "T.*E" 可以匹配到任何以 T 開頭,以 E 結尾的單詞
#grep -E "T.*E" littlestar.txt

"{ }" 可以用于表示明確的匹配次數,比如 "lit{2}le",就表示 "little",中間要匹配 2 個字母 t
#grep -E "lit{2}le" littlestar.txt

"{ }" 也可以指定一個匹配次數的范圍,比如 "{2,3}" 表示匹配 2 次到 3 次,"{2, }" 表示匹配至少 2 次,最多則不限
#grep -E "lit{2,}le" littlestar.txt

(4) 分組元字符
"( )" 可以將幾個字符組合在一起作為一個整體處理,比如我們想對 "twinkle," 這個字串做為一個整體,匹配它是否出現過兩次,可以寫成 "(twinkle){2}"
#grep -E -i "(twinkle,){2}" littlestar.txt
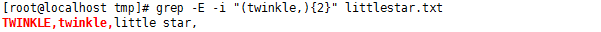
最后
文本處理往往是需要命令列工具和正則運算式結合使用,正則運算式相對來說比較抽象,但實際上正則運算式的使用就是對元字符的組合運用,所以掌握每個元字符對學好正則運算式至關重要,
推薦閱讀:
《Linux的運行級別與目標》
《軟鏈接 vs. 硬鏈接》
《Linux 目錄詳解》
《虛擬機安裝 Linux 最完整攻略》
《Xshell 與 Xftp 的安裝與使用》
《Linux,Unix,GNU 到底有什么樣的淵源?》

- The End -
轉載請註明出處,本文鏈接:https://www.uj5u.com/caozuo/71480.html
標籤:Linux