Scrapy快速入門
Scrapy是一個為了爬取網站資料,提取結構性資料而撰寫的應用框架,它使用Twisted這個異步網路庫來處理網路通訊,架構清晰,并且包含了各種中間件介面,可以靈活的完成各種需求,個人認為Scrapy是Python世界里面最強大的爬蟲框架,沒有之一,它比BeautifulSoup更加完善,BeautifulSoup可以說是輪子,而Scrapy則是車子,不需要你關注太多細節,Scrapy不僅支持Python2.7,Python3也支持,
- scrapy是框架,類似于車子,會開車,
- 采用異步框架,實作高效率的網路采集,
- 最強大的框架,沒有之一,
安裝和檔案:
- 安裝:通過
pip install Scrapy即可安裝, - Scrapy官方檔案:http://doc.scrapy.org/en/latest
- Scrapy中文檔案:https://www.osgeo.cn/scrapy/
注意:
1 在ubuntu上安裝scrapy之前,需要先安裝以下依賴:
sudo apt-get install python-dev python-pip libxml2-dev libxslt-dev zliblg-dev libffi-dev libssl-dev,然后在通過pip install scrapy安裝,2 如果在
windows系統下,提示這個錯誤ModuleNotFoundError:No module named 'win32api',那么使用以下命令可以解決:
pip install pypiwin32或pip install pywin32遇到問題
VC++14.0 Twisted解決辦法:離線安裝twisted
https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
pip install xxx.whl [twsited.whl的路徑]安裝完成執行
scrapy bencn運行測驗
Scrapy原理
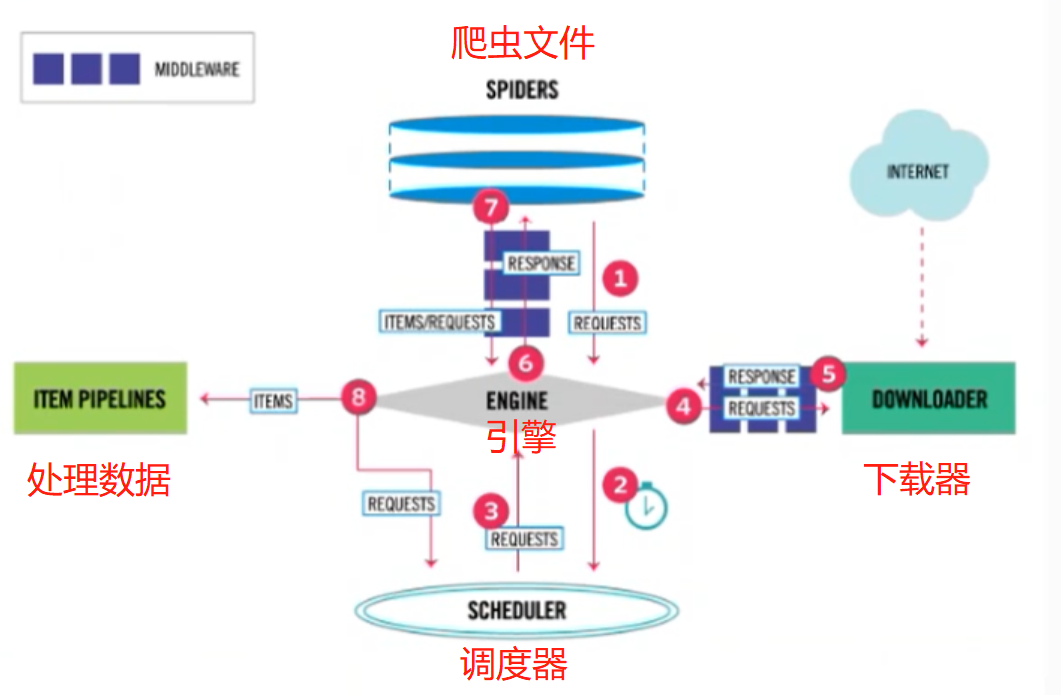
Scrapy主要包含以下組件:
- 引擎:處理整個系統的資料流,觸發事務(框架核心)
- 調度器:用來接收引擎發過來的請求,壓入佇列中,并在引擎在此請求的時候回傳,由它來決定下一個要抓取的網址是什么,同時去除重復的網址,
- 下載器:用于下載網頁內容,并將網頁內容回傳給蜘蛛,
- Scrapy下載器是建立在Twisted這個搞笑的異步模型上的,
- 爬蟲:爬蟲主要是干活的,用于從特定的網頁中提取自己需要的資訊,即所謂的物體,用戶也可以從中提取出鏈接,讓Scrapy繼續抓取下一個頁面,
- 專案管道:負責處理爬蟲從網頁中抽取的物體,主要的功能是持久化物體、驗證物體的有效性、清楚不需要的資訊,當頁面被爬蟲決議后,將被發送到專案管道,并經過幾個特定的次序處理資料,
- 下載器中間件:位于Scrapy引擎和下載器直接的框架,主要是處理Scrapy引擎與下載器直接的請求及回應,
- 爬蟲中間件:介于Scrapy引擎和爬蟲直接的框架,主要作業是處理蜘蛛的回應輸入和請求輸出,
- 調度中間件:介于Scrapy引擎和調度器直接的中間件,從Scrapy引擎發送到調度的請求和回應,
Scrapy的運行流程大概如下
- 引擎從調度器中取出一個鏈接(URL)用于接下來的抓取
- 引擎把URL封裝成一個請求(Request)傳給下載器
- 下載器把資源下載下來,并封裝成應答包(Response)
- 爬蟲決議Response
- 決議出物體(Item),則交給物體管道進行進一步的處理
- 決議出的是鏈接(URL),則把URL交給調度器等待抓取
創建專案
Windows下,打開命令提示符視窗,進入到打算存盤代碼的目錄中,使用下面的命令創建一個scrapy專案
scrapy startproject 專案名
專案結構
scrapy.cfg:專案的組態檔- 專案名/:該專案的python模塊,之后我們將在此加入代碼,
- 專案名/
items.py:用來存放爬蟲爬取下來資料的模型, - 專案名/
pipelines.py:用來將items的模型存盤到本地磁盤中, - 專案名/
settings.py: 本爬蟲的一些配置資訊(比如請求頭、多久發送一次請求、ip代理池等), - 專案名/
middlewares.py: 用來存放各種中間件的檔案, - 專案名/spiders包:以后所有的爬蟲,都是存放到這個里面
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/110799.html
標籤:Python
下一篇:02.Scrapy-Demo