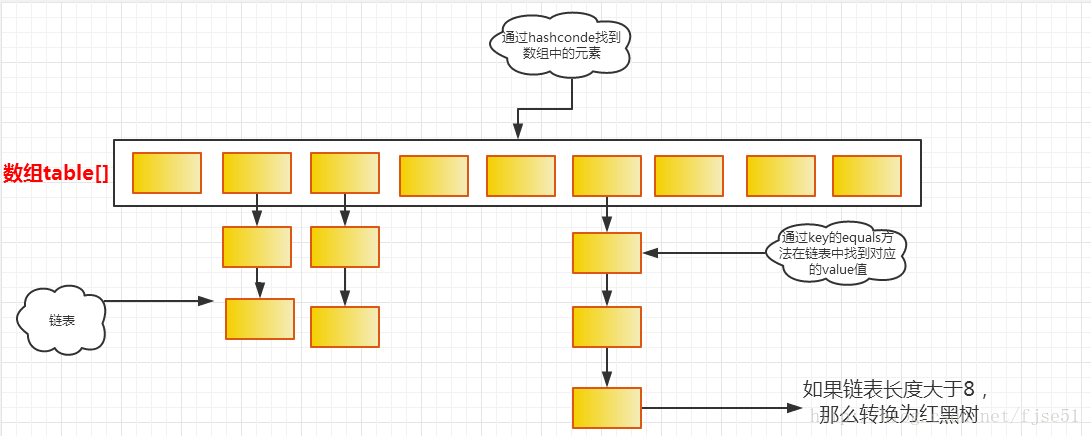
剛才我在看hashmap陣列結構的時候,看到這張圖,,然后有點疑惑?
我看這幅圖理解的是,陣列table[]存的是key,,鏈表用來存對應的value,一般情況下不是一個key對應一個value嘛,那如果一個key對應一個鏈表的話,value對應的是不是就是一個arrayList之類的資料結構,然后當arrayList存盤的長度大于8以后,鏈表這個資料結構重組為紅黑樹?
不知道我的這個理解對不對?如果有問題,麻煩幫我指點一下,有點迷。。
uj5u.com熱心網友回復:
陣列table[]里存的是key經過hash計算后得到的值(街道),鏈表里存的是對應的key-value這種鍵值對(門牌號-人),但是有可能多個不同的key經過hash計算后得到的值相同(不同的人可能會住同一個街道,但是門牌號不一樣),這樣我們找資料的時候(找人),先找key經過hash計算后得到的值(找到街道),然后用equals()找到對應的key(門牌號),最后就找到了相應的資料(人)uj5u.com熱心網友回復:
我的理解是table[]存盤的是<key,value>,鏈表應該是個linkList,主要是用來解決hash沖突的,在JDK1.8之后鏈表才會因為長度的原因重組成紅黑樹,因為鏈表查詢效率太慢了,如果鏈表足夠長的話 很影響效率uj5u.com熱心網友回復:
樓上說的不錯,hash在給定的key足夠多的情況下,碰撞概率還是比較高的。
在key的hash值相同時,value就放在陣列里。
一般的小規模應用場景,資料量不會太大,碰撞概率幾乎可以忽略。
所以很多文章都介紹說 HashMap的時間復雜度近似于O(1)
uj5u.com熱心網友回復:
Map<String,String> map=new HashMap<>();
map.put("姓名","張三");
map.put("姓名","李四");
System.out.println(map.get("姓名"));
按照您的意思,這種情況下是不是為了解決hash沖突,然后張三,李四都存盤在了這個linkList中了呢,如果是,那要怎么得到張三呢?
uj5u.com熱心網友回復:
在key的hash值相同時,value就放在陣列里。
你這一句說的我更懵了。。。
uj5u.com熱心網友回復:
完全不對,你還是沒理解HashMap,在執行 map.put("姓名","李四"); 之后,張三已經被拋棄了,陣列里已經沒有張三了。
HashMap,會先計算“姓名”.hashCode,然后去Map里找陣列,找到陣列后,遍歷陣列,找“姓名”,如果存在,就覆寫,不存在,就在陣列的最后一個位置插入“姓名:張三”
uj5u.com熱心網友回復:
1,像hashMap這種java經典的資料結構最好是自己去看看原始碼,table[]陣列存的不是key,而是Node(jdk1.7以前叫entry),node是鏈表結構,也就是table[]存的是鏈表,node主要有三個屬性,key,value和hash2,并不是鏈表長度到8就一定會樹化,還有一個條件是陣列長度必須大于等于64,樹化是為了增加查詢效率,在鏈表長度到達8,但是陣列長度小于64時,hashMap會進行擴容操作,因為擴容可以減少hash沖突,一樣能提高查詢效率
uj5u.com熱心網友回復:
不要只看圖,建議除錯一下下面的代碼結合原始碼學習,下面的代碼就是哈希沖突的示例
HashMap<String,Integer> map=new HashMap<>();
// 以下這些key的哈希值全部都相同,也就是所謂的哈希碰撞的情況
String[] keys = {"AaAaAaAa", "AaAaBBBB", "AaAaAaBB", "AaAaBBAa",
"BBBBAaAa", "BBBBBBBB", "BBBBAaBB", "BBBBBBAa",
"AaBBAaAa", "AaBBBBBB", "AaBBAaBB", "AaBBBBAa",
"BBAaAaAa", "BBAaBBBB", "BBAaAaBB", "BBAaBBAa",};
for(int i=0;i<keys.length;i++){
String key = keys[i];
System.out.println(key+":"+key.hashCode());
map.put(key,i);
}
System.out.println(map);
uj5u.com熱心網友回復:
我的理解是這樣,不知對不對? 當我們put(key,value)時,key會經過哈希運算映射到一個數,這個數就是陣列的id,比如put("姓名","李四")時,假設"姓名"的哈希值是1001,那么put("姓名","李四")就相當于table[1001]=new Object[3];table[1001][0][0]="姓名";table[1001][0][1]="李四",table[1001][0][2]=null。當我們name=get("姓名"),直接就相當于name=table[1001][0][1],所以是不用查找而直接取得資料的,故這時時間復雜度便是O(1)。而當我們再次put("姓名","王五")時,這時id=1001這個單元已經被開辟了,而且有table[1001][0][0]=="姓名",故這時便是table[1001][0][1]="王五",“李四”這個值已經被覆寫掉了。假如我們put("車名","寶馬"),而我們再假設"車名"這個key的哈希值也是1001,因為id=1001這個單元已經被開辟了,而table[1001][0][0]!="車名",于是這種情形就是發生了哈希碰撞了,而這時我們總不能table[1001][0][0]="車名",table[1001][0][1]="寶馬"吧,那么怎么辦呢?那就是要建鏈表了,即執行table[1001][0][2]=new Object[3],table[1001][0][2][0]="車名",table[1001][0][2][1]="寶馬",table[1001][0][2][2]=null,依此類推。當這個鏈表太長時,就把鏈表轉成紅黑樹。uj5u.com熱心網友回復:
table里存的時hash值,也就是插入一個<k, v>,先對k進行取hash,找到在table的位置,然后再看這個位置下的鏈表有沒有同樣key的資料,有就覆寫,沒有就插入鏈表uj5u.com熱心網友回復:
比如說 table[] 表長為8, table的下標就是 0-7 , 具體map存在哪個table的下標中,是先求得該map值的hash值,然后通過該hash值對8求余數,
余數會得到0-7 ,8個結果。余數相同的就依次存入對應的table下標的Linklist中。
uj5u.com熱心網友回復:
所以不同的k值也會再同一個table下標中存盤,但是相同的key值肯定會被新的替換,所以不可能再次得到張三的值、uj5u.com熱心網友回復:

 大概就是這樣子的,至于更深入的了解,一起學習哈
大概就是這樣子的,至于更深入的了解,一起學習哈
uj5u.com熱心網友回復:
哈值不可能小到只有1-4,這個是哈值相對陣列長度取余的結果,所以不只是哈值相等才會編入一組,取余相等也會編入一組。
uj5u.com熱心網友回復:
所以當陣列擴容后,會重新排列,原來在一組的資料,擴容后可能不在同一組。uj5u.com熱心網友回復:
說一下我的理解,首先你圖中的情況我一般是在存盤物件的時候出現,在存盤的時候會首先進行hash值計算,通過hash來定位(圖中第一排的位置),但是hash不一定每一次都生成唯一的,因為容器物件是有限的,所以在hash值計算一樣的時候就會出現在同一位置,這個時候通過equals來比較這個位置是否已經存在,不存在的時候就會生成一個鏈表,但是鏈表都知道,遍歷是需要從頭到尾進行遍歷查找的,所以在一定長度就進行轉換紅黑樹,用紅黑樹的計算方式進行快速定位。所以,這就是為什么我們在存盤物件的時候要重寫hashcode和equals方法,因為不重寫equals方法的話,在通過hash進行定位到同一位置,equals進行判斷是否存在物件的時候,默認呼叫object的equals,判斷是的是物件地址。
希望可以幫到你
uj5u.com熱心網友回復:
樓主啊,理解的好像有點問題。鏈表里面有表頭的概念,還記得嗎?
表頭一般不存放資料,只是表示鏈表的開始(雙向鏈表還表示結束)。使用表頭,可以化簡鏈表增刪時的操作代碼,使得代碼簡潔,更容易被理解。
HashMap里面,陣列里面存放的就是表頭,它的意思是,我有一個陣列的表頭,也就是陣列的每一個元素,都將會是一個鏈表。
那么,問題來了,我要是有一個鍵值對,想保存到 HashMap 中,怎么放呢?
首先,計算 Key 物件的 hashCode 值,然后,將這個值對陣列的size取余,得到的就是陣列的下角標,或者說,鏈表的編號(如果從0開始編號的話)。
能理解嘛? Key 物件的 hashCode 值,就是為了找到鏈表的。
然后,找到對應的鏈表之后,將 鍵值對 封裝成 Entity 物件,放入鏈表中,記住啊,鏈表中存放的是鍵值對。
經過多次的添加操作之后,由于存入的 key 值不同,key 對應的 hashCode 值也會不同,你會發現,這些鍵值對會被分配到不同的鏈表中進行保存。
什么?可能有不同key的鍵值對,保存到了同一個鏈表里面?對啊,鏈表可以存放多個物件(鍵值對),而且,可以很靈活的存放多個物件。
問題的關鍵不是鏈表保存了多個物件,而是,陣列中的鏈表,保存物件的個數不太平均,這樣的話,會影響查找的速度的。
怎樣通過 Key 的值,得到 Value 值?
首先,計算 Key 物件的 hashCode 值,然后,將 hashCode 對 陣列的 size 取余,得到陣列的下角標,也就是鏈表的表頭。
然后,順著 鏈表 呼叫 Key 物件 equals 方法,比較 和 Key 相同的鍵值對,找到之后,將 Value 取出即可。
如果鏈表很長,查找速度就會降低。這就涉及到一個優化方式的問題。
加載因子 loadFactor。(一般是 3/4 )
什么意思?
就是 HashMap 最多能夠存放陣列長度的 3/4 個鍵值對,當然,浮點數要進行取整運算才行。
明白了嗎?
為了提高HashMap 的查詢性能,我們盡量讓陣列后面的鏈表長度等于一,這樣的話,我們一下就可以找到了。
根據經驗而談,3/4 是個不錯的數字。
當然啦,如果你的 HashMap 非常大的話,陣列建的太大,也會浪費記憶體,那就需要你稍微調大一點 加載因子,讓它更趨近1一些。
如果現在我們的 HashMap 陣列只有16個的大小,那么,其實最多可以存放12個鍵值對。
那么,超出12個怎么辦?
擴容唄,
新生成一個表頭陣列(比如32個大小的陣列),然后,把以前的老 HashMap 中的 鍵值對 都重新計算一遍,填入到新的 表頭陣列中,生成新的 HashMap 。
是物件內部的結構調整,物件本身并沒有變動,只是容量變大了。
明白了嗎?
HashMap在自動擴容的時候,也是很費計算力的。所有,我們在編程的時候,如果已經知道未來 HashMap 要存放多少個 鍵值對了,那么,在 new HashMap 的時候,可以指定 HashMap 的容量,當然,我們還要除以3/4 。
uj5u.com熱心網友回復:
我對key ,value的理解是這樣的, key 只是用來通過計算hashcode,來找對應的entry陣列下標的, 然后再將value值插進去,一個節點除了頭(尾)指標外,資料域只存的value, 所以,他的hashmap的遍歷方式才會有通過entry去找key,和value的方式; 而且一個key 對應一個鏈表的說法,不準確 , 不同key通過與運算也有可能插入同一個桶中(hash碰撞);而且它對應的不是arraylist , 應該是單鏈表吧, 也不是其中一個桶鏈表長度大于8時候就得轉 ,好像還有個條件, 忘了 = =uj5u.com熱心網友回復:
嗯嗯,假設一下轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/11260.html
標籤:Java SE