利用celebA資料集訓練MTCNN網路
- celebA資料集簡介
- 訓練資料的處理
- 網路和訓練
- 偵測部分
- 結果展示
有問題可以聯系我的郵箱:2487429219@qq.com
關于MTCNN網路可以看我上一篇博客:鏈接: 人臉檢測演算法:mtcnn簡介
celebA資料集簡介
CelebA資料集包含202,599張名人人臉圖片,有人臉框,特征點等標注資訊,資料量大,可以用來訓練mtcnn網路,官方下載鏈接:celebA
下載鏈接里共有多個下載選項,我選擇使用的是In-The-Wild Images,具體每個選擇代表什么含義可以參照網上的celebA資料集詳解,

如果官方的鏈接下載不了或者速度太慢,可以去網上搜bdy鏈接,
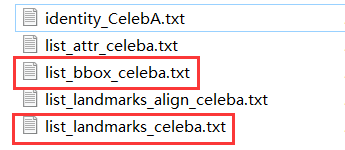
下載完成后會有如下檔案:

其中img_celeba檔案夾里面是202, 599名人圖片,但是圖片不僅僅是包含人的臉部,需要進一步處理,這個后文會說明,

Eval檔案夾里的內容在我訓練mtcnn時并沒有用到,這里不介紹,有興趣可以去查找celebA資料集介紹,
Anno檔案夾里面是對資料的一些標注,在訓練人臉檢測時,我只用到了人臉框和特征點的標注,對應list_bbox_celeba.txt和list_landmarks_celeba.txt
訓練資料的處理
由于我們下載的celebA資料集的資料并非只有人的臉部,所以在資料上我們需要進行一些處理,利用標注好的人臉框從原資料中裁剪出人臉并做好標注,獲得訓練用的資料集,
并且由于PNet,RNet,ONet所需要的資料大小不同(分別對應12,24,48),我們需要為每個網路準備對應的資料,多說無益,代碼如下:
這是iou計算:
import numpy as np
def iou(box, bbox, ismin=False):
"""
:param box: true box
:param bbox: other boxes
:param ismin: Whether to use min mode
:return: iou value
"""
x1, y1, x2, y2 = box[0], box[1], box[2], box[3]
_x1, _y1, _x2, _y2 = bbox[:, 0], bbox[:, 1], bbox[:, 2], bbox[:, 3]
# the area
area1 = (x2 - x1) * (y2 - y1)
area2 = (_x2 - _x1) * (_y2 - _y1)
# find out the intersection
xx1, yy1, xx2, yy2 = np.maximum(x1, _x1), np.maximum(y1, _y1), np.minimum(x2, _x2), np.minimum(y2, _y2)
w, h = np.maximum(0, xx2-xx1), np.maximum(0, yy2-yy1)
inter_area = w*h
# the list to save the iou value
iou_box = np.zeros([bbox.shape[0], ])
# Prevents zeros from being divided.
zero_index = np.nonzero(inter_area == 0)
no_zero = np.nonzero(inter_area)
iou_box[zero_index] = 0
if ismin:
iou_box[no_zero] = inter_area[no_zero] / (np.minimum(area1, area2)[no_zero])
else:
iou_box[no_zero] = inter_area[no_zero] / ((area1 + area2 - inter_area)[no_zero])
return iou_box
if __name__ == '__main__':
box1 = [100, 100, 200, 200]
bbox1 = np.array([[100, 90, 200, 200], [120, 120, 180, 180], [200, 200, 300, 300]])
a = iou(box1, bbox1)
print(a.shape)
print(a)
iou的概念不理解的可以看一下我上一篇博客:鏈接: 人臉檢測演算法:mtcnn簡介
這是獲取資料的檔案:
from PIL import Image
import os
import numpy as np
import utils
def gen_data(path, size):
"""
:param path: the path of images and label files
:param size: the size of the img data
"""
box_file = os.path.join(path, r'Anno/list_bbox_celeba.txt') # the box label file
landmarks_file = os.path.join(path, r'Anno/list_landmarks_celeba.txt') # the landmarks label file
saved_path = r'T:\mtcnn\celebA' # the save path of label files and homologous images
if not os.path.exists(saved_path):
os.makedirs(saved_path)
box_content = open(box_file, 'r', encoding='utf-8').readlines() # the content of the box label file
# the content of the landmarks label file
landmarks_content = open(landmarks_file, 'r', encoding='utf-8').readlines()
if not os.path.exists(os.path.join(saved_path, str(size))):
os.makedirs(os.path.join(saved_path, str(size), r'positive'))
os.makedirs(os.path.join(saved_path, str(size), r'negative'))
os.makedirs(os.path.join(saved_path, str(size), r'part'))
positive_num = 0
negative_num = 0
part_num = 0
# txt to save the label
f_positive = open(os.path.join(saved_path, str(size), 'positive.txt'), 'w', encoding='utf-8')
f_part = open(os.path.join(saved_path, str(size), 'part.txt'), 'w', encoding='utf-8')
f_negative = open(os.path.join(saved_path, str(size), 'negative.txt'), 'w', encoding='utf-8')
f_positive_landmark = open(os.path.join(saved_path, str(size), 'positive_landmark.txt'), 'w', encoding='utf-8')
f_part_landmark = open(os.path.join(saved_path, str(size), 'part_landmark.txt'), 'w', encoding='utf-8')
f_negative_landmark = open(os.path.join(saved_path, str(size), 'negative_landmark.txt'), 'w', encoding='utf-8')
for i, content in enumerate(box_content):
if i < 2: # skip the first two lines
continue
content_list = content.strip().split() # the list to save a line of the box file's content
landmarks_list = landmarks_content[i].strip().split() # the list to save a line of the landmark file's content
img = Image.open(os.path.join(os.path.join(path, r'img_celeba'), content_list[0]))
# the times to use one image
for _ in range(3):
# Gets the coordinates and size of the box starting point
x, y, w, h = int(content_list[1]), int(content_list[2]), int(content_list[3]), int(content_list[4])
x1, y1, x2, y2 = x, y, x+w, y+h
# Randomly crop the picture
cx, cy = int(x + w / 2), int(y + h / 2)
_cx, _cy = cx + np.random.randint(-0.2 * w, 0.2 * w + 1), cy + np.random.randint(-0.2 * h, 0.2 * h + 1)
_w, _h = w + np.random.randint(-0.2 * w, 0.2 * w + 1), h + np.random.randint(-0.2 * h, 0.2 * h + 1)
_x1, _y1, _x2, _y2 = int(_cx - _w / 2), int(_cy - _h / 2), int(_cx + _w / 2), int(_cy + _h / 2)
# get the landmark point
ex1, ey1, ex2, ey2 = int(landmarks_list[1]), int(landmarks_list[2]), int(landmarks_list[3]), int(landmarks_list
[4])
nx1, ny1, mx1, my1 = int(landmarks_list[5]), int(landmarks_list[6]), int(landmarks_list[7]), int(landmarks_list
[8])
mx2, my2 = int(landmarks_list[9]), int(landmarks_list[10])
nex1, ney1, nex2, ney2 = (ex1 - _x1), (ey1 - _y1), (ex2 - _x1), (ey2 - _y1)
nnx1, nny1, nmx1, nmy1 = (nx1 - _x1), (ny1 - _y1), (mx1 - _x1), (my1 - _y1)
nmx2, nmy2 = (mx2 - _x1), (my2 - _y1)
# Cut out pictures
crop_img = img.crop([_x1, _y1, _x2, _y2])
crop_img = crop_img.resize([size, size])
# calculate the iou value
iou = utils.iou([x1, y1, x2, y2], np.array([[_x1, _y1, _x2, _y2]]))
# calculate the offset value
try:
_x1_off, _y1_off, _x2_off, _y2_off = (x1 - _x1)/_w, (y1 - _y1)/_h, (x2 - _x2)/_w, (y2 - _y2)/_h
except ZeroDivisionError:
continue
if iou > 0.65:
crop_img.save(os.path.join(saved_path, str(size), r'positive', r'%s.jpg' % positive_num))
f_positive.write(f'{positive_num}.jpg 1 {_x1_off} {_y1_off} {_x2_off} {_y2_off}\n')
f_positive_landmark.write(f"{positive_num}.jpg {nex1/_w} {ney1/_h} {nex2/_w} {ney2/_h} {nnx1/_w} {nny1/_h} {nmx1/_w} {nmy1/_h} "
f"{nmx2/_w} {nmy2/_h}\n")
f_positive.flush()
positive_num += 1
elif iou > 0.4:
crop_img.save(os.path.join(saved_path, str(size), r'part', r'%s.jpg' % part_num))
f_part.write(f'{part_num}.jpg 2 {_x1_off} {_y1_off} {_x2_off} {_y2_off}\n')
f_part_landmark.write(f"{part_num}.jpg {nex1/_w} {ney1/_h} {nex2/_w} {ney2/_h} {nnx1/_w} {nny1/_h} {nmx1/_w} {nmy1/_h} "
f"{nmx2/_w} {nmy2/_h}\n")
f_part.flush()
part_num += 1
elif iou < 0.29:
crop_img.save(os.path.join(saved_path, str(size), r'negative', r'%s.jpg' % negative_num))
f_negative.write(f'{negative_num}.jpg 0 0 0 0 0\n')
f_negative_landmark.write(f'{negative_num}.jpg 0 0 0 0 0 0 0 0 0 0\n')
negative_num += 1
# get the negative data
w, h = img.size
_x1, _y1 = np.random.randint(0, w), np.random.randint(0, h)
_w, _h = np.random.randint(0, w - x1), np.random.randint(0, h - y1)
_x2, _y2 = x1 + _w, y1 + _h
crop_img1 = img.crop([_x1, _y1, _x2, _y2])
crop_img1 = crop_img1.resize((size, size))
iou = utils.iou(np.array([x1, y1, x2, y2]), np.array([[_x1, _y1, _x2, _y2]]))
if iou < 0.29:
crop_img1.save(os.path.join(saved_path, str(size), r'negative', r'%s.jpg' % negative_num))
f_negative.write(f'{negative_num}.jpg 0 0 0 0 0\n')
f_negative_landmark.write(f'{negative_num}.jpg 0 0 0 0 0 0 0 0 0 0\n')
negative_num += 1
if i % 1000 == 0:
print("%s/202599" % (i+1))
# close the file
f_positive.close()
f_positive_landmark.close()
f_part.close()
f_part_landmark.close()
f_negative.close()
f_negative_landmark.close()
if __name__ == '__main__':
gen_data(r'F:\\', 12)
這邊我注釋可能寫的不太清楚,我對一些地方稍作解釋:
-
我獲取的不僅僅是正樣本資料,即有人臉的資料,為了訓練網路,我需要給網路投喂一些負樣本資料,部分樣本資料其實可以不需要,獲取正樣本和負樣本資料的方法是,在人臉所在框附近小范圍隨機裁剪,再和原框位置計算iou,iou大于0.65的記為正樣本,0.4到0.65之間的記為部分樣本,

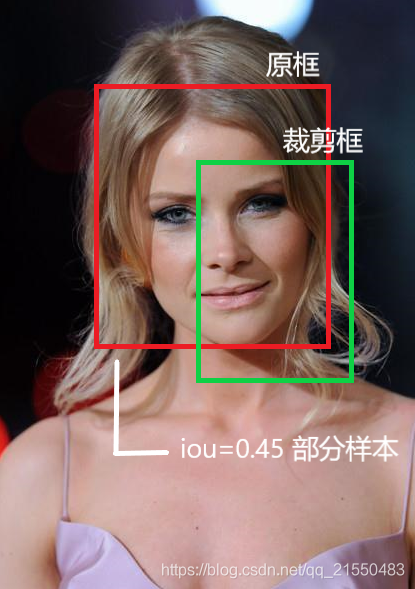
獲取負樣本的方法則較為簡單,直接在圖片中隨機裁剪,iou小于0.29的記為負樣本,
用這樣的方法獲取樣本,可以獲取更多的資料,利于訓練, -
每張圖片我們裁剪多次,以充分利用資料,裁剪后resize成對應大小,
-
記錄框和特征點的坐標時,采用的是記錄偏移量,這樣可以提高準確度,網路輸出的也是偏移量,所以最后偵測的時候需要反算一波,
網路和訓練
下面是網路,這部分沒什么好介紹的,看網路結構對著寫就可以:
import torch.nn as nn
import torch
class PNet(nn.Module):
def __init__(self):
super(PNet, self).__init__()
self.pre_layer = nn.Sequential(
nn.Conv2d(3, 10, kernel_size=3, stride=1, padding=1),
nn.PReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(10, 16, kernel_size=3, stride=1),
nn.PReLU(),
nn.Conv2d(16, 32, kernel_size=3, stride=1),
nn.PReLU(),
)
self.offset_layer = nn.Conv2d(32, 4, kernel_size=1, stride=1)
self.landmark_layer = nn.Conv2d(32, 10, kernel_size=1, stride=1)
self.confidence_layer = nn.Conv2d(32, 1, kernel_size=1, stride=1)
def forward(self, x):
x = self.pre_layer(x)
offset = self.offset_layer(x)
landmark = self.landmark_layer(x)
confidence = torch.sigmoid(self.confidence_layer(x))
return offset, landmark, confidence
class RNet(nn.Module):
def __init__(self):
super(RNet, self).__init__()
self.pre_layer = nn.Sequential(
nn.Conv2d(3, 28, kernel_size=3, stride=1, padding=1),
nn.PReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(28, 48, kernel_size=3, stride=1),
nn.PReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(48, 64, kernel_size=2, stride=1),
nn.PReLU(),
)
self.linear = nn.Sequential(
nn.Linear(64 * 3 * 3, 128),
nn.PReLU()
)
self.offset = nn.Linear(128, 4)
self.landmark = nn.Linear(128, 10)
self.confidence = nn.Linear(128, 1)
def forward(self, x):
x = self.pre_layer(x)
x = x.view(x.size(0), -1)
x = self.linear(x)
offset = self.offset(x)
landmark = self.landmark(x)
confidence = torch.sigmoid(self.confidence(x))
return offset, landmark, confidence
class ONet(nn.Module):
def __init__(self):
super(ONet, self).__init__()
self.pre_layer = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1),
nn.PReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(32, 64, kernel_size=3, stride=1),
nn.PReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 64, kernel_size=3, stride=1),
nn.PReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(64, 128, kernel_size=2, stride=1),
nn.PReLU(),
)
self.linear = nn.Sequential(
nn.Linear(128*3*3, 256),
nn.PReLU()
)
self.offset = nn.Linear(256, 4)
self.landmark = nn.Linear(256, 10)
self.confidence = nn.Linear(256, 1)
def forward(self, x):
x = self.pre_layer(x)
x = x.view(x.size(0), -1)
x = self.linear(x)
offset = self.offset(x)
landmark = self.landmark(x)
confidence = torch.sigmoid(self.confidence(x))
return offset, landmark, confidence
這是訓練:
from torch.utils.data import DataLoader
import torch
import sample
import os
import nets
import torch.nn as nn
class Trainer:
def __init__(self, net, save_path, dataset_path, iscuda=True):
"""
:param net: the net to train
:param save_path: the param's save path
:param dataset_path: dataset path
:param iscuda: is to use cuda
"""
self.net = net # nets to train
self.save_path = save_path # the path to save the trained model
self.dataset_path = dataset_path # the dataset path
self.iscuda = iscuda
# use cuda to speed up
if iscuda:
self.net.cuda()
# load the saved model
if os.path.exists(self.save_path):
self.net.load_state_dict(torch.load(self.save_path))
# confidence loss function
self.conf_loss = nn.BCELoss() # 二分類交叉熵損失函式
# offset and landmark loss function
self.label_loss = nn.MSELoss() # 均方損失函式
# optimizer
self.optimizer = torch.optim.Adam(self.net.parameters())
def train(self):
face_data = sample.FaceDataSet(self.dataset_path) # get the sample
# get the face loader
face_loader = DataLoader(face_data, batch_size=512, shuffle=True, num_workers=4, drop_last=True)
for _ in range(50):
for i, (img, offset, landmark, conf) in enumerate(face_loader):
if self.iscuda:
img = img.cuda()
offset = offset.cuda()
landmark = landmark.cuda()
conf = conf.cuda()
# use net to predict
_offset, _landmark, _conf = self.net(img)
_offset, _landmark, _conf = _offset.view(-1, 4), _landmark.view(-1, 10), _conf.view(-1, 1)
# print(_conf)
# get the positive and index
label_index = torch.nonzero(conf > 0)
# get the loss
offset_loss = self.label_loss(_offset[label_index[:, 0]], offset[label_index[:, 0]])
landmark_loss = self.label_loss(_landmark[label_index[:, 0]], landmark[label_index[:, 0]])
# get the positive and negative index
conf_index = torch.nonzero(conf < 2)
# get the loss
conf_loss = self.conf_loss(_conf[conf_index[:, 0]], conf[conf_index[:, 0]])
# all loss
loss = offset_loss + landmark_loss + conf_loss
# clear the gradient
self.optimizer.zero_grad()
# calculate the gradient
loss.backward()
# optimizer
self.optimizer.step()
# save the model
if (i + 1) % 300 == 0:
print(f"i:{i//300} loss:{loss.cpu().data} conf:{conf_loss.cpu().data} offset:"
f"{offset_loss.cpu().data} landmark:{landmark_loss.cpu().data}")
torch.save(self.net.state_dict(), self.save_path)
print("Save successfully")
if __name__ == '__main__':
save_path1 = r'./param/rnet.pt'
dataset_path1 = r'T:\mtcnn\24'
net = nets.RNet()
t = Trainer(net, save_path1, dataset_path1, True)
t.train()
訓練時,我是用的對于置信度和特征點的損失函式是均方差損失函式,對偏移量的損失函式是二分類交叉熵損失函式,
偵測部分
偵測部分我只列出比較重要的部分
這是p網路偵測部分,包含影像金字塔,不了解的可以看我上一篇:
def p_detect(self, img):
scale = 1 # the scaling value
w, h = img.size # the size of img
min_length = min(w, h) # the min edge
box_list = [] # to save box
while min_length >= 12:
img_data = self.transforms(img) # to tensor
if self.iscuda:
img_data = img_data.cuda()
img_data.unsqueeze_(0) # Raise a dimension
_offset, _landmark, _conf = self.pnet(img_data) # predict
_offset, _landmark, _conf = _offset[0].cpu().data, _landmark[0].cpu().data, _conf[0][0].cpu().data
positive_index = torch.nonzero(_conf > 0.6)
# 這部分是特征反算
for idx in positive_index:
# The location in the original image
_x1 = (idx[1].float() * 2) / scale
_y1 = (idx[0].float() * 2) / scale
_x2 = (idx[1].float() * 2 + 12) / scale
_y2 = (idx[0].float() * 2 + 12) / scale
# The original image size
_w, _h = _x2 - _x1, _y2 - _y1
offset = _offset[:, idx[0], idx[1]] # offset
landmark = _landmark[:, idx[0], idx[1]] # landmark
# box in the original image
x1 = offset[0] * _w + _x1
y1 = offset[1] * _h + _y1
x2 = offset[2] * _h + _x2
y2 = offset[3] * _w + _y2
# landmark in the image
ex1, ey1, ex2, ey2 = landmark[0]*_w + x1, landmark[1]*_h + y1, landmark[2]*_w + x1, landmark[3]*_h + y1
nx, ny = landmark[4]*_w + x1, landmark[5]*_h + y1
mx1, my1, mx2, my2 = landmark[6]*_w + x1, landmark[7]*_h + y1, landmark[8]*_w + x1, landmark[9]*_h + y1
box_list.append([_conf[idx[0], idx[1]], ex1, ey1, ex2, ey2, nx, ny, mx1, my1, mx2, my2, x1, y1, x2, y2])
# 縮放
scale *= 0.7
min_length *= 0.7
w, h = int(w*0.7), int(h*0.7)
img = img.resize([w, h])
return utils.nms(np.array(box_list), 0.5)
下面是nms:
def nms(boxes, thresh=0.3, ismin=False):
"""
:param boxes: 框
:param thresh: 閾值
:param ismin: 是否除以最小值
:return: nms抑制后的框
"""
if boxes.shape[0] == 0: # 框為空時防止報錯
return np.array([])
# 根據置信度從大到小排序(argsort默認從小到大,加負號從大到小)
_boxes = boxes[(-boxes[:, 0]).argsort()]
r_box = [] # 用于存放抑制后剩余的框
while _boxes.shape[0] > 1: # 當剩余框大與0個時
r_box.append(_boxes[0]) # 添加第一個框
abox = _boxes[0][11:]
bbox = _boxes[1:][:, 11:]
idxs = np.where(iou(abox, bbox, ismin) < thresh) # iou小于thresh框的索引
_boxes = _boxes[1:][idxs] # 取出iou小于thresh的框
if _boxes.shape[0] > 0:
r_box.append(_boxes[0]) # 添加最后一個框
return np.stack(r_box)
剩余的偵測可以仿照PNet的偵測完成,這部分就大家自己寫了,
結果展示
下面給幾張檢測的結果:



以上測驗圖片來自網路,
那么,本文到此結束了,有問題可以聯系我的郵箱:2487429219@qq.com
文章有錯誤的話歡迎大佬指正,不甚感激,
都看到這了,點個贊唄…QwQ…
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/113220.html
標籤:java