str本質
Python str的本質可以通過help命令查看
>>> help(str)
可以看到
Help on class str in module __builtin__:
class str(basestring)
| str(object='') -> string
|
| Return a nice string representation of the object.
| If the argument is a string, the return value is the same object.
|
| Method resolution order:
| str
| basestring
| object
|
| Methods defined here:
......
str的本質是Python模塊__builtin__中的一個類,里面定義了很多的方法,
str特性
Python strings是不能改變的,字串的值是固定的,因此,給一個字串的具體下表位置賦值是會出錯的:
>>> word='Python'
>>> word[0] = 'J'
...
TypeError: 'str' object does not support item assignment
>>> word[2:] = 'py'
...
TypeError: 'str' object does not support item assignment
如果要得到一個不同的字串,那就得創建一個新的:
>>> 'J' + word[1:]
'Jython'
>>> word[:2] + 'py'
'Pypy'
可以使用模塊__builtin__中的一個內建函式len()獲得字串的長度:
>>> help(len)
Help on built-in function len in module __builtin__:
len(...)
len(object) -> integer
Return the number of items of a sequence or collection.
>>> s = 'supercalifragilisticexpialidocious'
>>> len(s)
34
字串是可迭代物件
>>> s = 'I love Python'
>>> list(s)
['I', ' ', 'l', 'o', 'v', 'e', ' ', 'P', 'y', 't', 'h', 'o', 'n']
>>> for c in s:
... print(c)
...
I
l
o
v
e
P
y
t
h
o
n
>>>
str method
以下函式均為str類里面的成員函式按照功能分類的結果
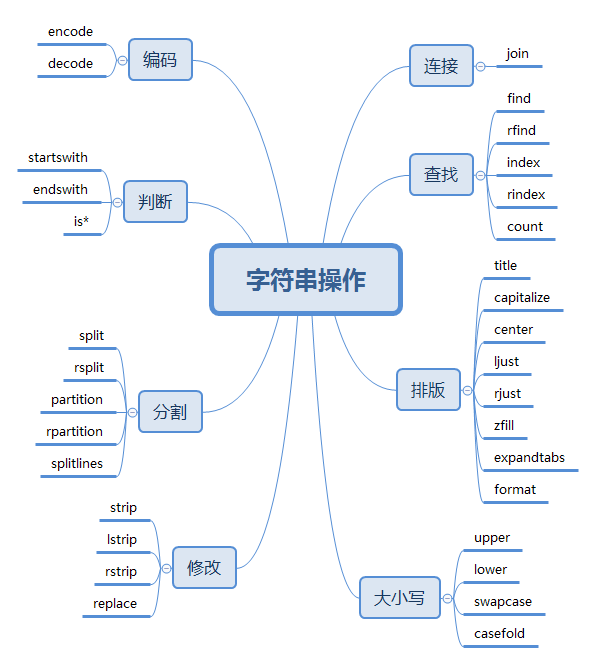
xmind檔案可點這里下載
連接
str.join(iterable)
S.join(iterable) -> string
函式功能
將序列iterable中的元素以指定的字符S連接生成一個新的字串,
函式示例
>>> iter="apple"
>>> s="-"
>>> s.join(iter)
'a-p-p-l-e'
查找
str.find(sub[, start[, end]])
S.find(sub [,start [,end]]) -> int
函式功能
和C++的字串的find函式功能一樣,檢測字串中是否存在子字串sub,如果存在,則回傳找到的第一個子串的下標,如果找不到,則回傳-1,而C++回傳的是string::nops,
函式示例
>>> s="this is my dog, i love this dog and it's a good dog!"
>>> s.find("dog")
11
>>> s.find("dog",12,len(s)-1)
28
>>> s.find("dog",12,20)
-1
str.rfind(sub[, start[, end]])
S.rfind(sub [,start [,end]]) -> int
函式功能
和C++的字串的find函式功能一樣,檢測字串中是否存在子字串sub,如果存在,則回傳找到的最后一個子串的下標,如果找不到,則回傳-1,而C++回傳的是string::nops,
函式示例
>>> s="this is my dog, i love this dog and it's a good dog!"
>>> s.rfind("dog")
48
>>> s.rfind("dog",0,len(s)-10)
28
str.index(sub[, start[, end]])
S.index(sub [,start [,end]]) -> int
函式功能
與 python find()方法的功能一樣,只不過如果子串sub不在S中會報一個例外(ValueError: substring not found),
函式示例
>>> s="this is my dog, i love this dog and it's a good dog!"
>>> s.index("dog")
11
>>> s.index("digw")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: substring not found
str.rindex(sub[, start[, end]])
S.rindex(sub [,start [,end]]) -> int
函式功能
與 python rfind()方法的功能一樣,只不過如果子串sub不在S中會報一個例外(ValueError: substring not found),
函式示例
>>> s="this is my dog, i love this dog and it's a good dog!"
>>> s.rindex("dog")
48
>>> s.rfind("dog")
48
>>> s.rindex("oihofa")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: substring not found
str.count(sub[, start[, end]])
S.count(sub[, start[, end]]) -> int
函式功能
在字串中查找某個子串出現的次數,start和end是兩個可選的引數,表示起止下標位置,python默認下標位置是從0開始的,
函式示例
>>> s="this is my dog, i love this dog and it's a good dog!"
>>> print s
this is my dog, i love this dog and it's a good dog!
>>> s.count("dog")
3
>>> s.count(" ")
12
>>> s.count("dog",15)
2
>>> s.count("dog",15,32)
1
排版
str.capitalize()
S.capitalize() -> string
- Return a copy of the string S with only its first character capitalized.
函式功能
首字符是字母,回傳第一個字母大寫,其他不變
函式示例
>>> s='linux'
>>> s.capitalize()
'Linux'
>>> s='790873linux'
>>> s.capitalize()
'790873linux'
str.center(width[, fillchar])
S.center(width[, fillchar]) -> string
函式功能
已字串S為中心,回傳width長度的字串,其中多余部分都是用fillchar來填充,如果width小于或者等于len(S),則回傳str本身,如果不給定fillchar這個引數,那么默認填充空格
函式示例
>>> s='linux'
>>> a=s.center(len(s)+1,'m')
>>> print a
linuxm
>>> a=s.center(len(s)+2,'m')
>>> print a
mlinuxm
>>> a=s.center(len(s)+3,'m')
>>> print a
mlinuxmm
>>> a=s.center(len(s)+4,'m')
>>> print a
mmlinuxmm
>>> a=s.center(len(s)-1,'m')
>>> print a
linux
str.ljust(width[, fillchar])
S.ljust(width[, fillchar]) -> string
函式功能
回傳一個原字串左對齊,并使用字符fillchar填充至指定長度width的新字串,
width -- 指定字串長度
fillchar -- 填充字符,默認為空格
函式示例
>>> a="apple"
>>> a.ljust(10)
'apple '
>>> a.ljust(10,'.')
'apple.....'
>>> a.ljust(3,'2')
'apple'
str.rjust(width[, fillchar])
S.rjust(width[, fillchar]) -> string
函式功能
回傳一個原字串右對齊,并使用字符fillchar填充至指定長度width的新字串,
width -- 指定字串長度
fillchar -- 填充字符,默認為空格
函式示例
>>> a="apple"
>>> a.rjust(10)
' apple'
>>> a.rjust(10,'.')
'.....apple'
>>> a.rjust(3,'.')
'apple'
str.expandtabs([tabsize])
S.expandtabs([tabsize]) -> string
函式功能
把字串中的 tab 符號('\t')轉為空格,tab 符號('\t')默認的空格數是8,tabsize -- 指定轉換字串中的 tab 符號('\t')轉為空格的字符數,
函式示例
>>> s = "today is a good d\tay"
>>> print s
today is a good d ay
>>> s.expandtabs()
'today is a good d ay'
>>> s.expandtabs(4)
'today is a good d ay'
>>> s.expandtabs(1)
'today is a good d ay'
>>> s.expandtabs(0)
'today is a good day'
str.format(*args, **kwargs)
S.format(*args, **kwargs) -> string
函式功能
格式化字串變數,2.7版本和3.1版本之后才支持{}這種格式,老版本會報錯
ValueError: zero length field name in format
參見:ValueError: zero length field name in format python
函式示例
>>> name = 'StivenWang'
>>> fruit = 'apple'
>>> print 'my name is {},I like {}'.format(name,fruit)
my name is StivenWang,I like apple
>>> print 'my name is {1},I like {0}'.format(fruit,name)
my name is StivenWang,I like apple
>>> print 'my name is {mingzi},I like{shuiguo}'.format(shuiguo=fruit,mingzi=name)
my name is StivenWang,I like apple
大小寫
str.lower()
S.lower() -> string
轉換字串中所有大寫字符為小寫
>>> a="oiawh92dafawFAWF';;,"
>>> a.lower()
"oiawh92dafawfawf';;,"
str.upper()
S.upper() -> string
轉換字串中所有小寫字符為大寫
>>> a="oiawh92dafawFAWF';;,"
>>> a.upper()
"OIAWH92DAFAWFAWF';;,"
str.swapcase()
S.swapcase() -> string
函式功能
將字串的大小寫轉換,小寫轉大寫,大寫轉小寫
函式示例
>>> s="ugdwAWDgu2323"
>>> s.swapcase()
'UGDWawdGU2323'
分割
str.split([sep[, maxsplit]])
S.split([sep [,maxsplit]]) -> list of strings
函式功能
通過指定分隔符sep對字串進行切片,如果引數maxsplit有指定值,則僅分隔 maxsplit個子字串,如果分隔符sep沒有給定,則默認以空格分割,
函式示例
>>> s="sys:x:3:3:Ownerofsystemfiles:/usr/sys:"
>>> s.split(":")
['sys', 'x', '3', '3', 'Ownerofsystemfiles', '/usr/sys', '']
>>> s.strip(":").split(":")
['sys', 'x', '3', '3', 'Ownerofsystemfiles', '/usr/sys']
>>> len(s.strip(":").split(":"))
6
>>> s="sa aa aa as"
>>> s.split()
['sa', 'aa', 'aa', 'as']
str.splitlines([keepends])
S.splitlines(keepends=False) -> list of strings
函式功能
按照行分隔,回傳一個包含各行作為元素的串列,如果引數keepends=False后者為慷訓者為0,則不包含"\n",否則包含"\n"
函式示例
>>> s="Line1-a b c d e f\nLine2- a b c\n\nLine4- a b c d"
>>> print s.splitlines()
['Line1-a b c d e f', 'Line2- a b c', '', 'Line4- a b c d']
>>> print s.splitlines(0)
['Line1-a b c d e f', 'Line2- a b c', '', 'Line4- a b c d']
>>> print s.splitlines(1)
['Line1-a b c d e f\n', 'Line2- a b c\n', '\n', 'Line4- a b c d']
>>> print s.splitlines(2)
['Line1-a b c d e f\n', 'Line2- a b c\n', '\n', 'Line4- a b c d']
>>> print s.splitlines(3)
['Line1-a b c d e f\n', 'Line2- a b c\n', '\n', 'Line4- a b c d']
>>> print s.splitlines(4)
['Line1-a b c d e f\n', 'Line2- a b c\n', '\n', 'Line4- a b c d']
str.partition(sep)
S.partition(sep) -> (head, sep, tail)
函式功能
根據指定的分隔符sep將字串進行分割(回傳一個3元的元組,第一個為分隔符左邊的子串,第二個為分隔符本身,第三個為分隔符右邊的子串),且分隔符不能為空也不能為空串,否則會報錯,
函式示例
>>> s="are you know:lilin is lowser"
>>> s.partition("lilin")
('are you know:', 'lilin', ' is lowser')
>>> s.partition("")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: empty separator
>>> s.partition()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: partition() takes exactly one argument (0 given)
修改
str.strip([chars])
S.strip([chars]) -> string or unicode
函式功能
用于移除字串頭尾指定的字符(默認為空格),如果字符為unicode的,則先把字串轉化為unicode的再進行strip操作,
函式示例
>>> s="egg is a apple"
>>> print s.strip("e")
gg is a appl
>>> s="\negg is a apple\n"
>>> print s
egg is a apple
>>> print s.strip("\n")
egg is a apple
str.lstrip([chars])
S.lstrip([chars]) ->string or unicode
函式功能
用于截掉字串左邊的空格或指定字符,
函式示例
>>> s="egg is a apple"
>>> print s.lstrip("e")
gg is a apple
>>> s="\negg is a apple\n"
>>> print s.lstrip("\n")
egg is a apple
>>>
str.rstrip([chars])
S.rstrip([chars]) -> string or unicode
函式功能
用于截掉字串右邊的空格或指定字符,
函式示例
>>> s="egg is a apple"
>>> print s.rstrip("e")
egg is a appl
>>> s="\negg is a apple\n"
>>> print s.rstrip("\n")
egg is a apple
>>>
str.replace(old, new[, count])
S.replace(old, new[, count]) -> unicode
函式功能
把字串中的 old(舊字串)替換成 new(新字串),如果指定第三個引數max,則替換不超過 count次,
函式示例
>>> s="saaas"
>>> s.replace("aaa","aa")
'saas'
>>> s="saaaas"
>>> s.replace("aaa","aa")
'saaas'
>>> s="saaaaas"
>>> s.replace("aaa","aa")
'saaaas'
>>> s="saaaaaas"
>>> s.replace("aaa","aa")
'saaaas'
以上替換并不會遞回替換,每次都是找到3個a之后替換成兩個a,然后繼續從3個a后面的位置開始遍歷,而不是從頭開始遍歷,
編碼
和編碼相關的函式總共就兩個str.decode([encoding[, errors]])hestr.encode([encoding[, errors]])
首先了解下和編碼相關的幾個概念
- str是文本序列
- bytes是位元組序列
- 文本是有編碼的 (utf-8, gbk, GB18030等)
- 位元組沒有編碼這種說法
- 文本的編碼指的是字符如何使用位元組來表示
- Python3字串默認使用utf-8編碼
>>> s = '劉亦菲'
>>> type(s)
<class 'str'>
>>> help(s.encode)
Help on built-in function encode:
encode(...) method of builtins.str instance
S.encode(encoding='utf-8', errors='strict') -> bytes
Encode S using the codec registered for encoding. Default encoding
is 'utf-8'. errors may be given to set a different error
handling scheme. Default is 'strict' meaning that encoding errors raise
a UnicodeEncodeError. Other possible values are 'ignore', 'replace' and
'xmlcharrefreplace' as well as any other name registered with
codecs.register_error that can handle UnicodeEncodeErrors.
# 默認的編碼是utf-8,以下按照默認編碼
>>> s.encode()
b'\xe5\x88\x98\xe4\xba\xa6\xe8\x8f\xb2'
>>> '劉'.encode()
b'\xe5\x88\x98'
>>> '亦'.encode()
b'\xe4\xba\xa6'
>>> '菲'.encode()
b'\xe8\x8f\xb2'
>>> bin(0xe5)
'0b11100101'
>>> bin(0x88)
'0b10001000'
>>> bin(0x98)
'0b10011000'
>>> b = s.encode()
>>> b
b'\xe5\x88\x98\xe4\xba\xa6\xe8\x8f\xb2'
>>> b.decode()
'劉亦菲'
#以下為指定編碼為GBK
>>> b = s.encode('GBK')
>>> b
b'\xc1\xf5\xd2\xe0\xb7\xc6'
>>> b.decode('GBK')
'劉亦菲'
>>> b.decode()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc1 in position 0: invalid start byte
以上對encode和decode的方法的使用中出現了bytes型別,以下是對該型別的簡單介紹
- bytes 由str通過 encode方法轉化得到
- 通過 b前綴定義bytes
>>> b = b'\xe5\x88\x98'
>>> type(b)
<class 'bytes'>
>>> b
b'\xe5\x88\x98'
>>> b.decode()
'劉'
除了encode外, str操作,都有對應bytes的版本, 但是傳入引數也必須是bytes
bytes的可變版本bytearray
bytearray 是可變,在影像處理中經常會用到變化的bytes,相對bytes來說, bytearray多了 insert, append, extend, pop, remove, clear reverse這些操作,并且可以索引操作,
判斷
str.startswith(prefix[, start[, end]])
函式功能
用于判斷字串是否以指定前綴開頭,如果以指定后綴結尾回傳True,否則回傳False,可選引數"start"與"end"為檢索字串的開始與結束位置,prefix可為tuple,
函式示例
>>> s = "I am Mary,what's your name ?"
>>> s.startswith("I am")
True
>>> s.startswith("I are")
False
>>> s.startswith("I am",1,5)
False
str.endswith(suffix[, start[, end]])
S.endswith(suffix[, start[, end]]) -> bool
函式功能
用于判斷字串是否以指定后綴結尾,如果以指定后綴結尾回傳True,否則回傳False,可選引數"start"與"end"為檢索字串的開始與結束位置,suffix可為tuple,
函式示例
>>> s = "I am Mary,what's your name ?"
>>> print s
I am Mary,what's your name ?
>>> s.endswith("name ?")
True
>>> s.endswith("mame ?")
False
>>> s.endswith("name ?",0,len(s)-2)
False
str.isalnum()
S.isalnum() -> bool
函式功能
檢測字串是否由字母或數字組成,如果是,回傳True,如果有別的字符,則回傳False,
字串不為空,如果為空,則回傳False,
函式示例
>>> a="123"
>>> a.isalnum()
True
>>> a="daowihd"
>>> a.isalnum()
True
>>> a="ofaweo2131giu"
>>> a.isalnum()
True
>>> a="douha ioh~w80"
>>> a.isalnum()
False
>>> a=""
>>> a.isalnum()
False
str.isalpha()
S.isalpha() -> bool
函式功能
檢測字串是否只由字母組成,字串不為空,如果為空,則回傳False,
函式示例
>>> a="123"
>>> a.isalpha()
False
>>> a="uuagwifo"
>>> a.isalpha()
True
>>> a="oiwhdaw899hdw"
>>> a.isalpha()
False
>>> a=""
>>> a.isalpha()
False
str.isdigit()
S.isdigit() -> bool
函式功能
檢測字串是否只由數字組成,字串不為空,如果為空,則回傳False,
函式示例
>>> a="123"
>>> a.isdigit()
True
>>> a="dowaoh90709"
>>> a.isdigit()
False
>>> a=""
>>> a.isdigit()
False
str.islower()
S.islower() -> bool
函式功能
檢測字串是否由小寫字母組成,
函式示例
>>> a="uigfa"
>>> a.islower()
True
>>> a="uiuiga123141a"
>>> a.islower()
True
>>> a="uiuiga12314WATA"
>>> a.islower()
False
>>> a=""
>>> a.islower()
False
>>> a="doiowhoid;'"
>>> a.islower()
True
str.isupper()
S.isupper() -> bool
函式功能
檢測字串是否由大寫字母組成,
函式示例
>>> a="SGS"
>>> a.isupper()
True
>>> a="SGSugdw"
>>> a.isupper()
False
>>> a="SGS123908;',"
>>> a.isupper()
True
str.isspace()
S.isspace() -> bool
函式功能
檢測字串是否只由空格組成
函式示例
>>> a=" "
>>> a.isspace()
True
>>> a=" 12 dw "
>>> a.isspace()
False
參考資料
1、Python 2.7.12 documentation
2、Shaw Blog--Python str方法總結
3、hc-Python字串操作
記得幫我點贊哦!
精心整理了計算機各個方向的從入門、進階、實戰的視頻課程和電子書,按照目錄合理分類,總能找到你需要的學習資料,還在等什么?快去關注下載吧!!!

念念不忘,必有回響,小伙伴們幫我點個贊吧,非常感謝,
我是職場亮哥,YY高級軟體工程師、四年作業經驗,拒絕咸魚爭當龍頭的斜杠程式員,
聽我說,進步多,程式人生一把梭
如果有幸能幫到你,請幫我點個【贊】,給個關注,如果能順帶評論給個鼓勵,將不勝感激,
職場亮哥文章串列:更多文章

本人所有文章、回答都與著作權保護平臺有合作,著作權歸職場亮哥所有,未經授權,轉載必究!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/113539.html
標籤:Python