在上一章節我們介紹了什么是爬蟲,以及爬蟲的用處,同時我們也介紹了在學習爬蟲之前需要對網頁的基本構成有一個大體認識,
為了幫助沒有前端基礎的童鞋能夠更好的進入開發狀態,這一章節將對網頁的結構,以及涉及的html、css、js和http協議進行一個簡單的介紹,
在開始學習之前建議大家安裝chrome瀏覽器,當然其他瀏覽器也行,只不過chrome在這方面做的相對比較好,課程中也將基本使用chrome瀏覽器,
在chrome瀏覽器中,一般按F12快捷鍵能夠進入開發者模式,查看當前頁面的構成,這對于大家學習爬蟲,使用爬蟲大有益處,
1.HTML和超文本標記語言
如果我們曾經使用開發者模式打開網頁的話,那么我們一定見過如下圖所示的景象:
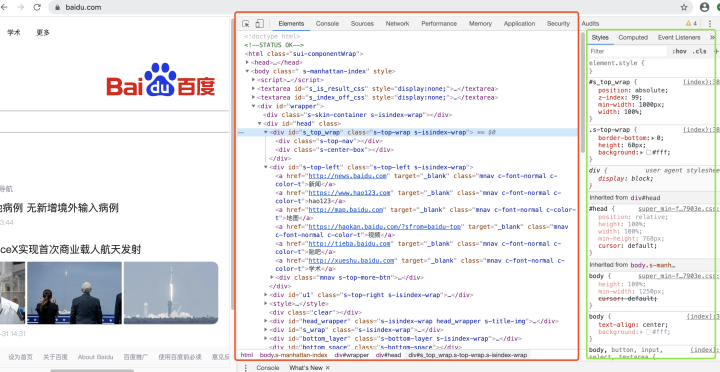
在圖中標紅的區域,我們能夠看到大量以XXX開頭和/XXX結尾的標簽對(XXX代表一個字串),例如div和/div,這些標簽,我們稱之為HTML 標簽 (HTML tag),
HTML 是用來描述網頁的一種語言,全稱是超文本標記語言 (Hyper Text Markup Language),HTML是它的英文縮寫,而這些由尖括號包圍的關鍵詞,正是HTML標記語言的重要組成部分,類似于python中的def、class這些關鍵字,
HTML 標簽通常是成對出現的,比如 div和/div,標簽對中的第一個標簽是開始標簽,第二個標簽是結束標簽,
一個最簡單的HTML標記語言的例子如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<p>Hello World!</p>
</body>
</html>
<html> 與 </html>
之間的文本描述網頁,head 與 /head之間一般定義表頭和一些元資料,<body> 與 </body> 之間的文本是可見的頁面內容,<p> 與 </p> 之間的文本被顯示為段落,
顯示效果如下:
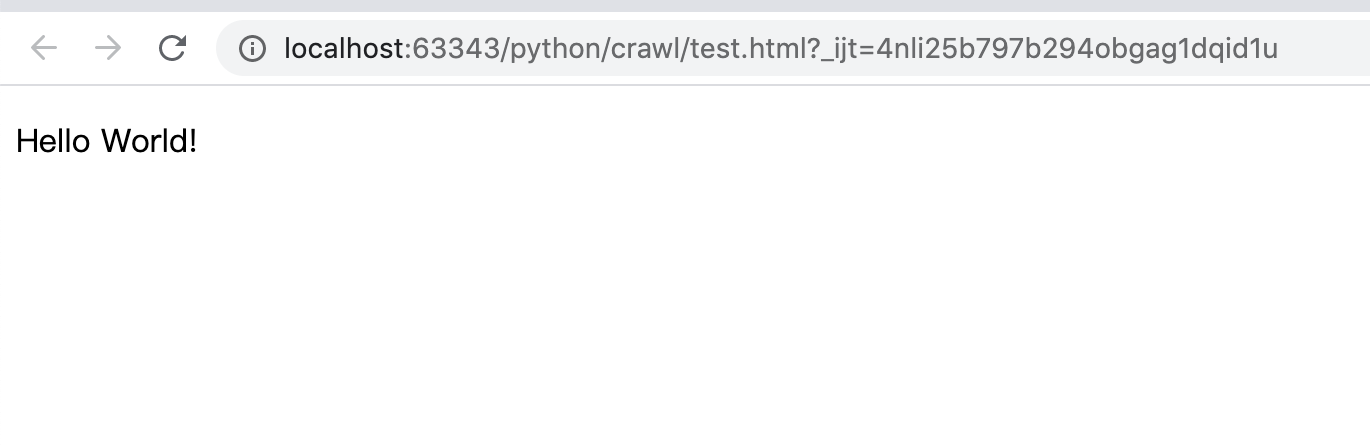
從上面最簡單的例子我們可以看出,一個最簡單的頁面通常至少會有三個標簽:一個是html代表這是一個html頁面,一個head代表頁面的一些元資料資訊,一個body代表頁面內容,
如果我們使用一些工具打開剛才的頁面內容,比如pycharm或者notepad++,通常會提供一種折疊效果,如下圖所示:

如果我們點擊html標簽進行折疊的話,我們發現最后只能顯示一個元素,如下圖所示:
這顯示的最后一個,我們稱之為這個頁面檔案的根結點,其他的節點我們稱之為這個根節點的子節點,這說法是不是有種似曾相識的感覺?對,在我們前面的資料結構章節我們對于樹形結構就有類似的說法,
對于所有的網頁頁面檔案,我們本質上可以看作一個樹形結構,即DOM樹,DOM樹,原意為檔案物件模型(Document Object Model,簡稱DOM),是W3C制定的標準介面規范,是一種處理HTML和XML檔案的標準API,
DOM提供了對整個檔案的訪問模型,將檔案作為一個樹形結構,樹的每個結點表示了一個HTML標簽或標簽內的文本項,DOM樹結構精確地描述了HTML檔案中標簽間的相互關聯性,將HTML或XML檔案轉化為DOM樹的程序稱為決議(parse),
我們使用爬蟲爬取網頁,獲取資料,本質上就是先獲得這個頁面的DOM樹,然后通過決議這棵DOM樹來獲取我們想要的資料,
2.css層疊樣式表
上面給出的最簡單的例子顯示的頁面內容形式過于簡單,字體的大小、顏色、位置等資訊都沒有設定,在HTML標記語言中,一般是采用一種叫做CSS層疊樣式表的東西給它添加美化效果,如下圖所示:
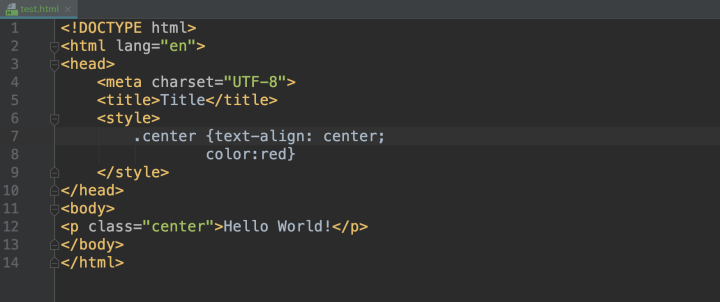
對于css,我們一般比較關注class這個屬性,一般我們叫做類屬性,通過這個屬性,我們能夠根據一個標簽的css樣式很快的訪問到這個標簽,
關于css的語法細節,這里就不多贅述,有興趣的可以登錄W3C school自行進行學習,
3.JavaScript簡介
對于一個靜態的網頁,為了讓它顯得有趣,會加入各種動態效果,比如頁面彈窗、圖片切換等,這種動態效果一般是借助一種叫做JavaScript的語言進行實作的,既然頁面使用了這種語言,那么了解它,對于抓取頁面資訊就會錦上添花,
JavaScript 本身跟python一樣,也是一種弱型別語言,它可以收集用戶的跟蹤資料,不需要多載頁面直接提交表單,在頁面嵌入多媒體檔案,甚至運行網頁游戲,那些看起來非常簡單的頁面背后通常使用了許多 JavaScript 檔案,
你可以在網頁源代碼的 <script> 標簽之間看到它們
<script>
alert("hello world!");
</script>
一般現在很少有人會使用原始的JavaScript語法,一般會借助第三方庫,比如JQuery、Node.js和Vue.js,進行二次開發,
關于js的語法細節,這里就不多贅述,有興趣的可以登錄W3C school自行進行學習,
4.http協議
在上一章介紹過,在web網頁間的通信,采用的是http協議或者https協議,https協議除了多了一個加密的功能之外,其他的基本跟http差不多,這里就不分開介紹,有興趣的可以自行百度學習,
一個http協議通常有三部分構成:第一部分是方法、url和版本資訊,典型的方法有get、post、delete、put等;第二部分是頭部資訊,一般定義的是主機資訊、連接狀態、內容編碼和內容長度等;第三部分是內容,所謂內容,就是請求的資訊和回應的資訊,不同方法的內部部分略有差異,有興趣的,可以進一步自行學習,
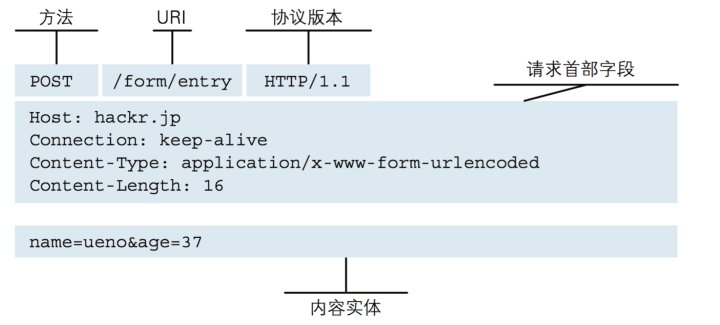
了解http協議有什么用呢?正如我們在前面講過,有爬蟲就有反爬蟲機制,那反爬蟲是實作呢?基本上是從http協議頭部資訊的角度入手,識別究竟是人操作還是腳本自動操作,
因此對http協議進行了解,就可以反反爬蟲,擴大自己的爬取資料范圍,
5.一個實體
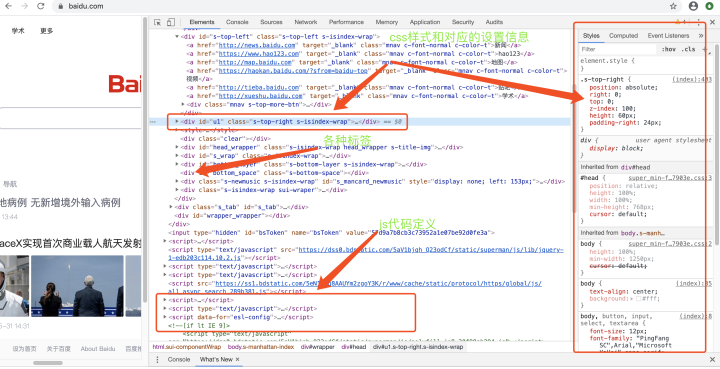
前面講了那么多,在文章的末尾,我們就以百度的首頁為例,看下html標簽、css、js和http協議在實際中是什么樣的,
頁面部分:
http協議部分:
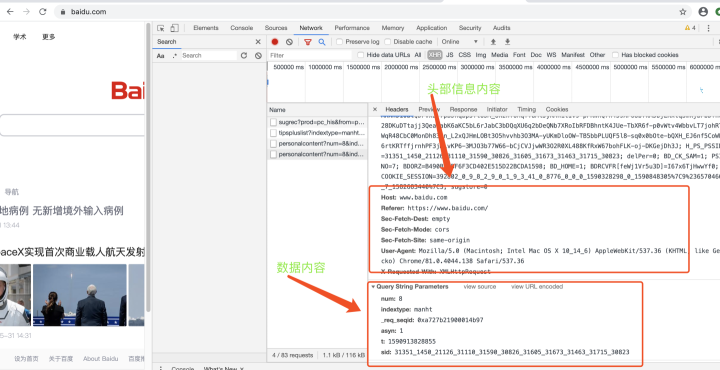
當然,在實際中如果要對http協議進行分析,一般不贊成使用chrome去查看,這種只能用于查看簡單的ajax請求報文資訊,
如果想要對http協議報文進行深入分析,建議使用第三方專業的抓包工具,比如fiddler、wireshark、burysuit等,不僅更專業,還會有額外的附加功能,是日常網路管理必備工具之一,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/116863.html
標籤:Python
下一篇:初試爬蟲