在上一章我們介紹了如何使用BeautifulSoup抓取安徒生童話故事《丑小鴨》,通過一個簡單的例子,大家應該對于python如何進行爬取網頁內容有了一個初步的認識,
在這一章節,我們將延續上一章的內容進行網頁內容的爬取,不過我們將難度提高一點,不再只是抓取一個頁面,而是抓取很多個頁面的內容,
在這里,我們還是以安徒生的童話故事為例進行講解,不過今天的內容是抓取所有的安徒生童話故事,具體內容如下圖所示,鏈接為www.ppzuowen.com
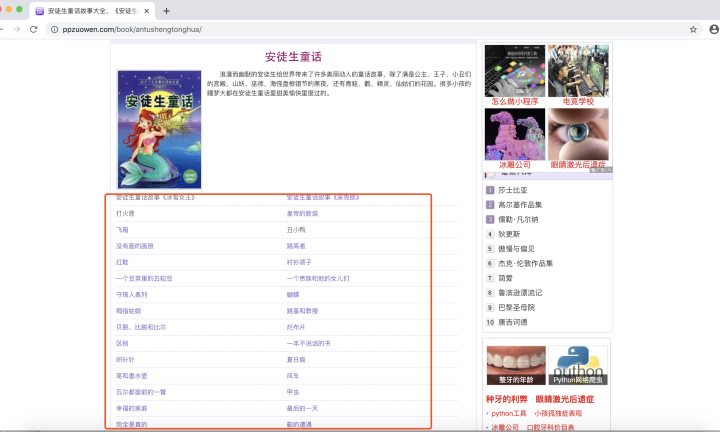
抓取一個單頁面很簡單,知道對應的url,然后在瀏覽器的開發者模式下查看需要的內容所在的標簽在哪里,然后定位抓取,那么對于多頁面的抓取如何進行呢?
思路本質上差不多:首先第一步是找到一個主頁面,然后通過主頁面與目標頁面的關聯跳轉到對應頁面,還記得我們的第一課給的那張爬蟲圖嗎?
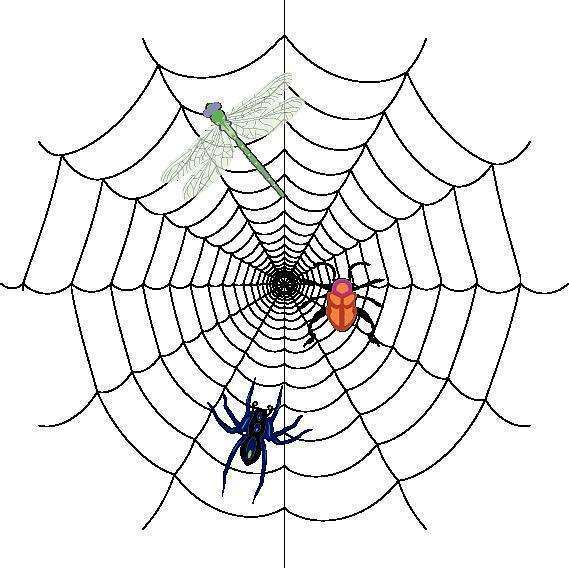
圖中的每個節點相當一個頁面,節點間是通過蛛絲進行關聯的,這個蛛絲通常是一個超鏈接,即url,
通常,如果要訪問整個蛛網有兩種思路:第一種是以一個節點為基準,訪問與它直連的所有的節點,然后再訪問直接的所有節點的所有直連節點,通過這種回圈的方式進行訪問,我們稱之為廣度優先搜索;另一種是以一個節點為基準,訪問與它直連的某一個節點,然后再訪問這個直連節點的某一個直連節點,通過這種遞回的方式進行訪問,我們稱之為深度優先搜索,
通過主頁面與目標頁面間的超鏈接,我們能夠爬取所有的目標內容,理論上,如果服務器的CPU和記憶體足夠大,我們可以爬取互聯網中所有的頁面資料,當然,實際中限于算力,我們一般會對爬取的內容進行裁剪,在本文中我們只爬取安徒生童話故事,
根據上面的分析,第二步我們需要做的就是找到所有主頁面和目標頁面之間的url,然后再對這些url進行再次訪問,就可以訪問每個頁面的內容,最后進行匯總,就能實作我們今天的預期目標,
很顯然,今天我們要采用的搜索方式是兩種中的廣度優先搜索,至于深度優先搜索,我們在后續的例子中進行詳細介紹,
在理清了思路之后,我們進行實際操作,
第一步,使用chrome在開發者模式下查看我們需要找的url在哪里,
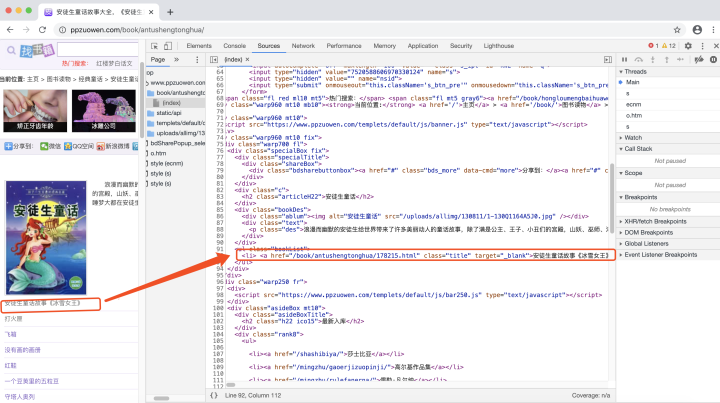
通過分析HTML頁面,我們可以發現我們需要找尋的url在a標簽的href屬性中,并且通過進一步分析,發現我們需要找的url所在的a標簽都有同一個class屬性,這個class屬性值為“title”,
因此第一步定位目標,我們很容易就完成了,事實上,由于前端的開發工程師為了開發的簡便和顯示的統一,對于同型別的內容通常會使用同樣的標簽和css樣式,
與此對應,對于我們的爬取也是非常簡便,
雖然我們能夠通過同一個class屬性找到我們的目標url,但是我們發現決議出來的url為/book/antushengtonghua/178215.html,而實際的url為https://www.ppzuowen.com/book/antushengtonghua/178215.html,
通過對比分析,我們發現只需要對決議出來的url在前面加一個域名https://www.ppzuowen.com即可,字串拼接對于我們來說再容易不過,剩下的就是把昨天的代碼補充在后面即可,
# 請求庫
import requests
# 決議庫
from bs4 import BeautifulSoup
# 爬取的網頁鏈接
prefix = r"https://www.ppzuowen.com/"
url = r"https://www.ppzuowen.com/book/antushengtonghua/"
r = requests.get(url)
r.encoding = None
result = r.text
# 再次封裝,獲取具體標簽內的內容
bs = BeautifulSoup(result, 'html.parser')
# 具體標簽
a = {}
# 獲取已爬取內容中的script標簽內容
data = https://www.cnblogs.com/turing09/p/bs.find_all('a', {"class": "title"})
# 回圈列印輸出
for link in data:
link = link.get('href')
target_link = prefix + link
print(target_link)
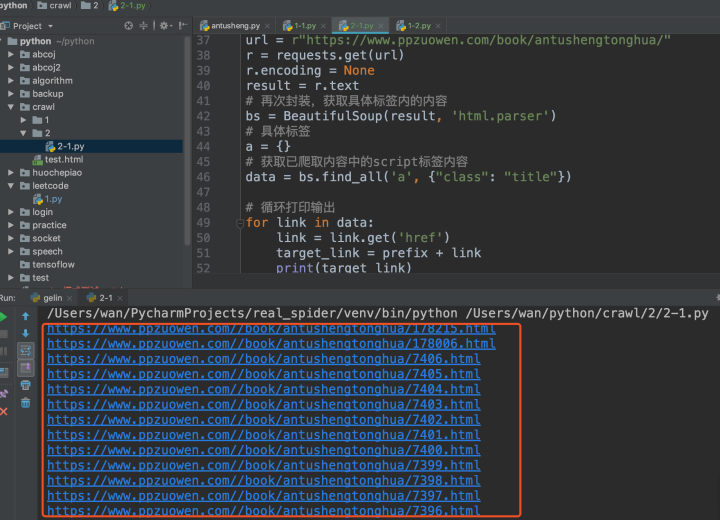
由于昨天的代碼可以看作一個單獨的功能,因此我們可以把它定義為一個函式,方便后面呼叫,
def getStory(url):
'''
獲取每個童話故事內容
:param url:
:return:
'''
r = requests.get(url)
r.encoding = None
result = r.text
# 再次封裝,獲取具體標簽內的內容
bs = BeautifulSoup(result, 'html.parser')
# 具體標簽
print("---------決議后的資料---------------")
a = {}
# 獲取已爬取內容中的p簽內容
data = https://www.cnblogs.com/turing09/p/bs.find_all('p')
result = ''
# 回圈列印輸出
for tmp in data:
if '皮皮作文網' in tmp.text:
break
result += tmp.text
return result
根據以上思路,我們得到的代碼如下:
# 請求庫
import requests
# 決議庫
from bs4 import BeautifulSoup
def getStory(url):
'''
獲取每個童話故事內容
:param url:
:return:
'''
r = requests.get(url)
r.encoding = None
result = r.text
# 再次封裝,獲取具體標簽內的內容
bs = BeautifulSoup(result, 'html.parser')
# 具體標簽
print("---------決議后的資料---------------")
a = {}
# 獲取已爬取內容中的p簽內容
data = https://www.cnblogs.com/turing09/p/bs.find_all('p')
result = ''
# 回圈列印輸出
for tmp in data:
if '皮皮作文網' in tmp.text:
break
result += tmp.text
return result
# 爬取的網頁鏈接
prefix = r"https://www.ppzuowen.com/"
url = r"https://www.ppzuowen.com/book/antushengtonghua/"
r = requests.get(url)
r.encoding = None
result = r.text
# 再次封裝,獲取具體標簽內的內容
bs = BeautifulSoup(result, 'html.parser')
# 具體標簽
a = {}
# 獲取已爬取內容中的script標簽內容
data = https://www.cnblogs.com/turing09/p/bs.find_all('a', {"class": "title"})
# 回圈列印輸出
for link in data:
link = link.get('href')
target_link = prefix + link
# print(target_link)
result=getStory(target_link)
print(result)
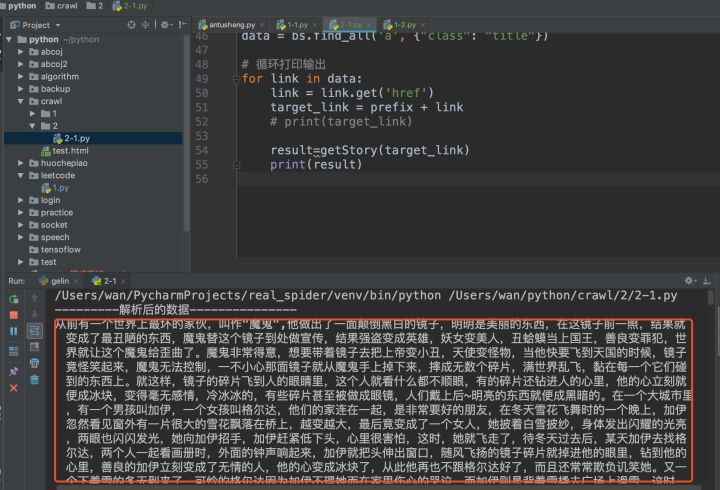
由于列印的內容較多,在控制臺上顯得的很亂,不方便查看,在這里我們可以使用檔案的存起來,檔案的名字為童話故事的名字,
修改后的代碼如下:
# 請求庫
import requests
# 決議庫
from bs4 import BeautifulSoup
def getStory(url):
'''
獲取每個童話故事內容
:param url:
:return:
'''
r = requests.get(url)
r.encoding = None
result = r.text
# 再次封裝,獲取具體標簽內的內容
bs = BeautifulSoup(result, 'html.parser')
# 具體標簽
print("---------決議后的資料---------------")
a = {}
# 獲取已爬取內容中的p簽內容
title=bs.find_all('h2', {"class": "articleH2"})[0].text
data = https://www.cnblogs.com/turing09/p/bs.find_all('p')
result = ''
# 回圈列印輸出
for tmp in data:
if '皮皮作文網' in tmp.text:
break
result += tmp.text
return title,result
# 爬取的網頁鏈接
prefix = r"https://www.ppzuowen.com/"
url = r"https://www.ppzuowen.com/book/antushengtonghua/"
r = requests.get(url)
r.encoding = None
result = r.text
# 再次封裝,獲取具體標簽內的內容
bs = BeautifulSoup(result, 'html.parser')
# 具體標簽
a = {}
# 獲取已爬取內容中的script標簽內容
data = https://www.cnblogs.com/turing09/p/bs.find_all('a', {"class": "title"})
# 回圈列印輸出
for link in data:
link = link.get('href')
target_link = prefix + link
# print(target_link)
result=getStory(target_link)
fd=open(result[0]+".txt",'w')
fd.write(result[1])
fd.close()
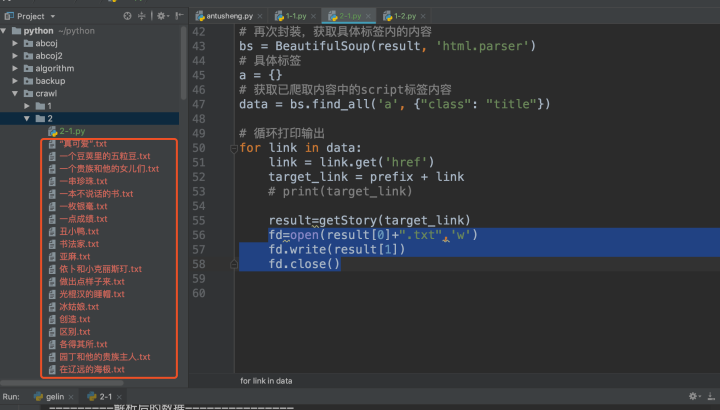
由于爬取的資料過多,效率不高,我們可以使用多執行緒進行操作,進一步優化代碼性能,修改后的代碼如下:
# 請求庫
import requests
# 決議庫
from bs4 import BeautifulSoup
import threading
from queue import Queue
#定義一個執行緒安全佇列,用來保存資料
que=Queue()
def getStory():
'''
獲取每個童話故事內容
:param url:
:return:
'''
while not que.empty():
url=que.get()
r = requests.get(url)
r.encoding = None
result = r.text
# 再次封裝,獲取具體標簽內的內容
bs = BeautifulSoup(result, 'html.parser')
# 具體標簽
print("---------決議后的資料---------------")
a = {}
# 獲取已爬取內容中的p簽內容
title=bs.find_all('h2', {"class": "articleH2"})[0].text
data = https://www.cnblogs.com/turing09/p/bs.find_all('p')
result = ''
# 回圈列印輸出
for tmp in data:
if '皮皮作文網' in tmp.text:
break
result += tmp.text
with open(title+".txt", 'w') as fo:
fo.write(result)
# 爬取的網頁鏈接
prefix = r"https://www.ppzuowen.com/"
url = r"https://www.ppzuowen.com/book/antushengtonghua/"
r = requests.get(url)
r.encoding = None
result = r.text
# 再次封裝,獲取具體標簽內的內容
bs = BeautifulSoup(result, 'html.parser')
# 具體標簽
a = {}
# 獲取已爬取內容中的script標簽內容
data = https://www.cnblogs.com/turing09/p/bs.find_all('a', {"class": "title"})
# 回圈列印輸出
for link in data:
link = link.get('href')
target_link = prefix + link
que.put(target_link)
print(target_link)
# 定義多執行緒
for i in range(10):
t = threading.Thread(target=getStory)
t.start()
t.join()
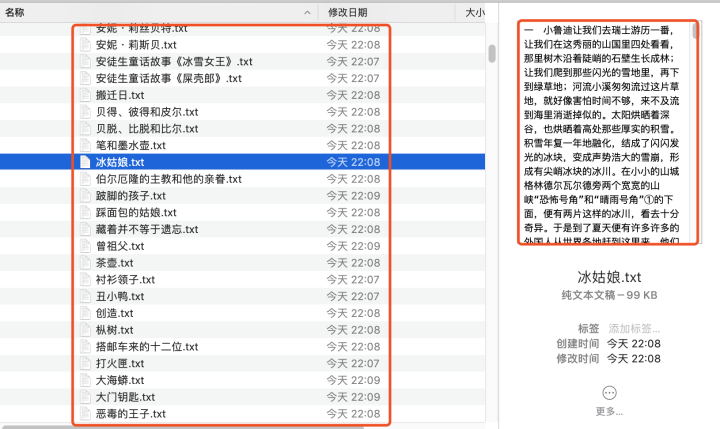
以上我們講解了如何利用廣度優先搜索的方式爬取多個網頁資訊,同時,為了提高爬取效率,我們采用多執行緒優化了代碼,并將結果存入到檔案中,方便后期查看,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/116870.html
標籤:Python
上一篇:初試爬蟲