在前面我們介紹了如何通過某個頁面爬取與之關聯的外部網頁,當時介紹的是使用廣度優先搜索的方式爬取,
在本節,我們將介紹另一種爬取外部鏈接的方式,即深度優先搜索,爬取網頁的分頁,
由于本人喜歡古詩詞,今天爬取的網頁的內容就是古詩詞,爬取的鏈接為:https://so.gushiwen.org/shiwen/,
如下圖所示:
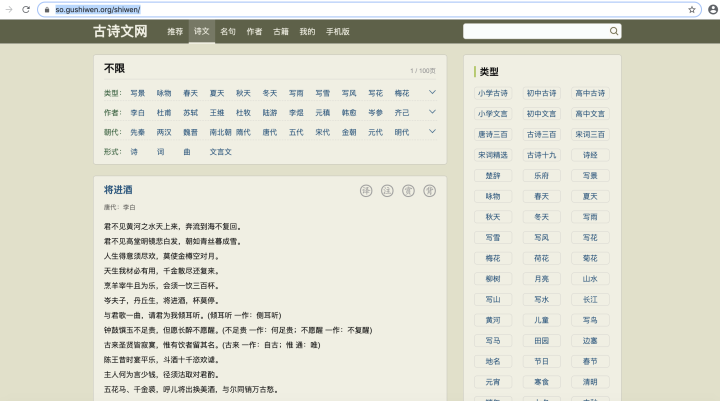
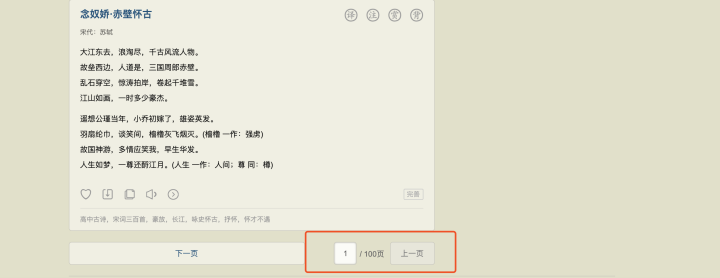
在同一個網頁,內容是通過分頁的形式進行展示,今天介紹如何爬取分頁,
一、思路分析
我們知道,對于網頁的分頁內容訪問,我們通常可以通過點擊“上一頁”或者“下一頁”按鈕訪問關聯的頁面,
因此,在爬取分頁內容的時候,我們可以采用這一思路,進行深度遞回,即可訪問所有的分頁內容,
當然,事實上,由于軟體工程師在編碼程序中會對不同分頁的url做一定的映射,因此除了以上思路,我們可以選擇另外一種解決辦法就是分析這種映射關系是什么,
如果能確定映射關系,那么就不需要進行深度遞回,畢竟作業系統對于編程語言的堆疊的深度是有限制的,比如python最多遞回1000次,超過1000次將報堆疊溢位的錯誤,
在接下來的示例演示中將對兩種方法進行介紹,
二、示例演示
1.深度遞回訪問分頁內容
正如之前一直強調的,在使用網路爬蟲進行網頁爬取的時候,第一步總是先打開目標網頁,然后在開發者模式下分析網頁的特點,然后根據分析的結果進行爬取,
打開目標網頁的結構如下圖所示:
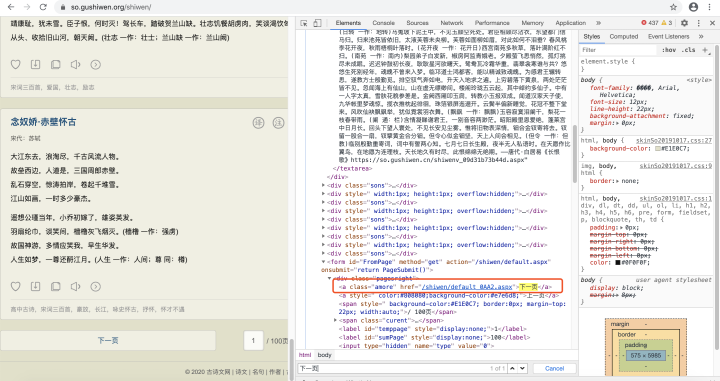
在網頁中搜索“下一頁”按鈕所在的標簽位置,我們可以看到如上的結果,并且通過認真觀察,我們能夠看見“下一頁”所在的標簽是一個超鏈接,因此我們可以猜測,這個鏈接就是用來從當前頁跳轉到下一頁,
為了驗證我們的猜想是否正確,我們可以直接點開“下一頁”按鈕的跳轉頁面是否與我們剛才觀察的url一致,
打開“下一頁”的頁面,我們可以看到url如下:
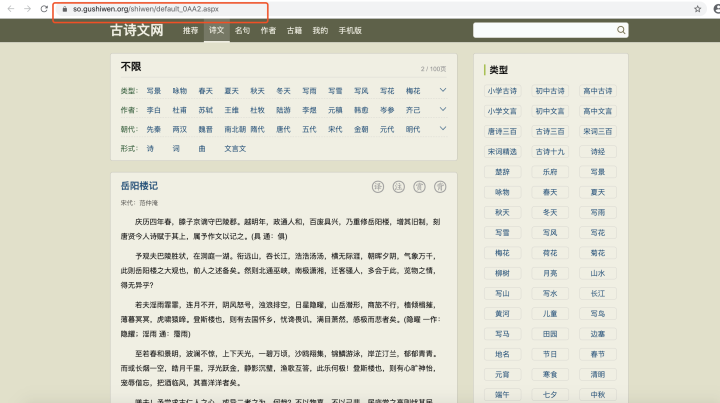
顯然,兩個頁面是存在聯系的,瀏覽器中的url和超鏈接的url除了隔了域名https://so.gushiwen.org/不一樣之外,后半部分都是一致的,
因此證實了我們的猜想是正確的,因此我們只需要獲取頁面中“下一頁”中超鏈接的url,再拼接上域名,就能得到下一頁頁面的url,通過遞回操作,我們能夠爬取所有的頁面,
這里定義一個函式進行實作,使用一個佇列存盤每次獲取的url:
def getNextUrl(url,que):
'''
:return:
'''
if url==None or len(url)==0:
return
try:
html = requests.get(url)
html.encoding = None
new_url = bs.findAll("a", {"class": "amore"})[0].attrs['href']
new_url= domain_prefix+new_url
que.put(new_url)
getNextUrl(new_url,que)
except Exception as e:
print("get attr error!")
在找到不同分頁頁面間的關聯關系之后,接下來就是找到我們的目標內容:古詩詞所在的位置,通過我們前面介紹的知識,我們很容易找到我們的目標內容:
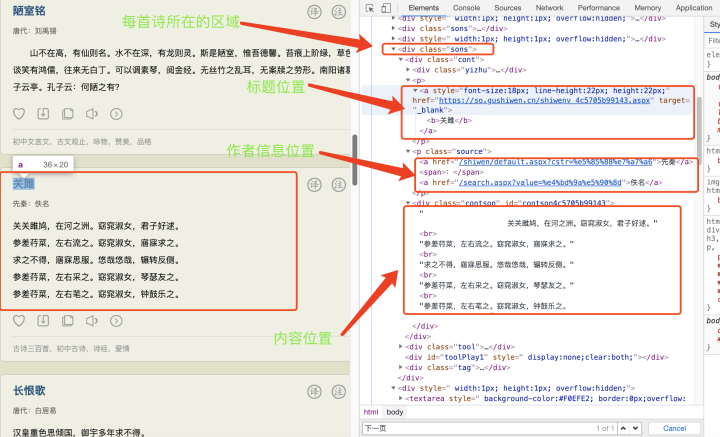
利用我們上一章的講過的標簽定位方法,很容易就可以獲取到目標內容,
為了方便查看,我們把每首詩的內容使用檔案進行存盤,代碼實作如下:
def get_poetry(bs):
'''
獲取每首詩的內容
:param url:
:return:
'''
# 將所有詩詞內容寫入文本
poetry_set = bs.findAll("div", {"class": "sons"})
for poetry in poetry_set:
titles = poetry.findAll('b')
if len(titles)==0:
break
title=titles[0].text.split('/')[-1].strip()
res=''+title
with open('./book/'+title+".txt", 'w') as fo:
info = poetry.findAll('p', {'class': 'source'})
for i in info:
fo.write(i.get_text())
res+=','+i.get_text()
content = poetry.findAll('div', {'class': 'contson'})
for i in content:
fo.write(i.get_text())
res += ','+i.get_text()
為了提高執行效率,我們可以把頁面內容提取和url訪問分開,使用多執行緒進行并行操作,同時,要考慮到訪問程序中會存在訪問出錯的情況,因此需要捕獲例外,
最終得到的完整代碼如下:
# 請求庫
import requests
# 決議庫
from bs4 import BeautifulSoup
from queue import Queue
import threading
import os
import re
domain_prefix=r"https://so.gushiwen.org"
def get_poetry(bs):
'''
獲取每首詩的內容
:param url:
:return:
'''
# 將所有詩詞內容寫入文本
poetry_set = bs.findAll("div", {"class": "sons"})
for poetry in poetry_set:
titles = poetry.findAll('b')
if len(titles)==0:
break
title=titles[0].text.split('/')[-1].strip()
res=''+title
with open('./book/'+title+".txt", 'w') as fo:
info = poetry.findAll('p', {'class': 'source'})
for i in info:
fo.write(i.get_text())
res+=','+i.get_text()
content = poetry.findAll('div', {'class': 'contson'})
for i in content:
fo.write(i.get_text())
res += ','+i.get_text()
def getNextUrl(url,que):
'''
:return:
'''
if url==None or len(url)==0:
return
try:
html = requests.get(url)
html.encoding = None
bs = BeautifulSoup(html.text, 'html.parser')
#啟動一個子執行緒進行內容處理
t = threading.Thread(target=get_poetry, args=(bs,))
t.start()
t.join()
new_url = bs.findAll("a", {"class": "amore"})[0].attrs['href']
new_url= domain_prefix+new_url
que.put(new_url)
getNextUrl(new_url,que)
except Exception as e:
print("get attr error!")
爬取的網頁鏈接
url=r"https://so.gushiwen.org/shiwen/"
html=requests.get(url)
html.encoding=None
bs=BeautifulSoup(html.text,'html.parser')
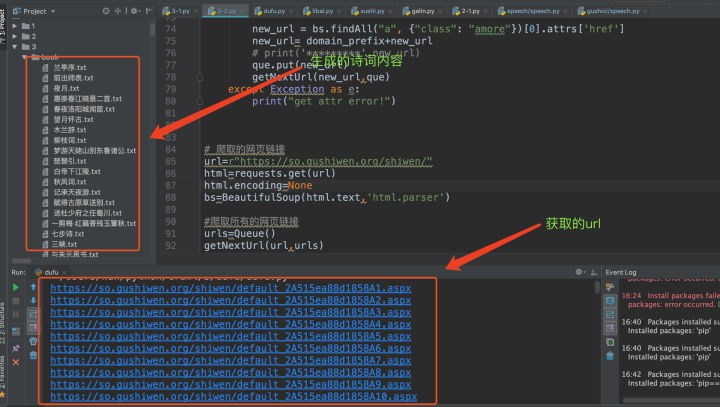
#爬取所有的網頁鏈接
urls=Queue()
getNextUrl(url,urls)
最終得到的結果如下:
2.研究映射關系快速訪問
通過遞回的方式獲取所有的url思路很清晰,也很簡單,但是效率不高,因此,為了提高效率,我們可以比較分析不同的特點,找出規律,
摘取部分url展示如下:

通過細細比較,我們可以很容易發現,這些url除了最后的1位或者兩位數字不同之外,其他的都是相同的,并且這些數字存在一個以1為步長的線性增長關系,
因此我們完全可以通過一個回圈來生成所有的url,代碼實作如下:
#所有的網頁鏈接
urls=Queue()
for i in range(1,101,1):
tmp=url.replace("1.aspx",str(i)+".aspx")
print(tmp)
urls.put(tmp)
在得到所有的URL之后,接下來我們只需要抓取每個頁面的url的HTML頁面,然后獲取內容皆可,除了獲取url的方式不同之外,其他抓取的方式與深度遞回方式差不多,如下所示:
def get_poetry(que):
'''
獲取每首詩的內容
:param url:
:return:
'''
while not que.empty():
url=que.get()
try:
html = requests.get(url)
html.encoding = None
bs = BeautifulSoup(html.text, 'html.parser')
# 將所有詩詞內容寫入文本
poetry_set = bs.findAll("div", {"class": "sons"})
for poetry in poetry_set:
titles = poetry.findAll('b')
if len(titles)==0:
break
title=titles[0].text.split('/')[-1].strip()
print(title)
res=''+title
with open('./book/'+title+".txt", 'w') as fo:
info = poetry.findAll('p', {'class': 'source'})
for i in info:
fo.write(i.get_text())
res+=','+i.get_text()
content = poetry.findAll('div', {'class': 'contson'})
for i in content:
fo.write(i.get_text())
res += ','+i.get_text()
except Exception as e:
print(url)
print("get attr error!")
因為抓取的頁面之間不存在先后關系,因此可以并行執行,這里采用多執行緒的方式來提高抓取的效率,
得到最終的代碼如下:
# 請求庫
import requests
# 決議庫
from bs4 import BeautifulSoup
from queue import Queue
import threading
import pyttsx3
import os
import re
domain_prefix=r"https://so.gushiwen.org"
def get_poetry(que):
'''
獲取每首詩的內容
:param url:
:return:
'''
while not que.empty():
url=que.get()
try:
html = requests.get(url)
html.encoding = None
bs = BeautifulSoup(html.text, 'html.parser')
# 將所有詩詞內容寫入文本
poetry_set = bs.findAll("div", {"class": "sons"})
for poetry in poetry_set:
titles = poetry.findAll('b')
if len(titles)==0:
break
title=titles[0].text.split('/')[-1].strip()
print(title)
res=''+title
with open('./book/'+title+".txt", 'w') as fo:
info = poetry.findAll('p', {'class': 'source'})
for i in info:
fo.write(i.get_text())
res+=','+i.get_text()
content = poetry.findAll('div', {'class': 'contson'})
for i in content:
fo.write(i.get_text())
res += ','+i.get_text()
except Exception as e:
print(url)
print("get attr error!")
# 爬取的網頁鏈接
url=r"https://so.gushiwen.org/shiwen/default_2A515ea88d1858A1.aspx"
#爬取所有的網頁鏈接
urls=Queue()
# urls.put(url)
for i in range(1,101,1):
tmp=url.replace("1.aspx",str(i)+".aspx")
print(tmp)
urls.put(tmp)
# 定義多執行緒
for i in range(10):
t = threading.Thread(target=get_poetry, args=(urls,))
t.start()
t.join()
通過執行對比分析,我們很容易就可以發現第二種方法比第一種方法不僅代碼更為簡潔,效率也更高,
當然,抓取內容只是整個資料分析的基本操作,為了對資料進行更深入的理解,我們需要借助一些資料分析的工具對資料進行處理和分析,
由于涉及的內容較多,難度也更大,將在后續的篇章逐漸給大家進行介紹,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/116875.html
標籤:Python
下一篇:selenium自動化操作