前言
本文主要介紹的是ELK日志系統中的Logstash快速入門
ELK介紹
ELK是三個開源軟體的縮寫,分別表示:Elasticsearch , Logstash, Kibana , 它們都是開源軟體,新增了一個FileBeat,它是一個輕量級的日志收集處理工具(Agent),Filebeat占用資源少,適合于在各個服務器上搜集日志后傳輸給Logstash,官方也推薦此工具,
-
Elasticsearch是個開源分布式搜索引擎,提供搜集、分析、存盤資料三大功能,它的特點有:分布式,零配置,自動發現,索引自動分片,索引副本機制,restful風格介面,多資料源,自動搜索負載等,
-
Logstash 主要是用來日志的搜集、分析、過濾日志的工具,支持大量的資料獲取方式,一般作業方式為c/s架構,client端安裝在需要收集日志的主機上,server端負責將收到的各節點日志進行過濾、修改等操作在一并發往elasticsearch上去,
-
Kibana 也是一個開源和免費的工具,Kibana可以為 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以幫助匯總、分析和搜索重要資料日志,
-
Filebeat是一個輕量型日志采集器,可以方便的同kibana集成,啟動filebeat后,可以直接在kibana中觀看對日志檔案進行detail的程序,
Logstash介紹
Logstash是一個資料流引擎:
它是用于資料物流的開源流式ETL引擎,在幾分鐘內建立資料流管道,具有水平可擴展及韌性且具有自適應緩沖,不可知的資料源,具有200多個集成和處理器的插件生態系統,使用Elastic Stack監視和管理部署
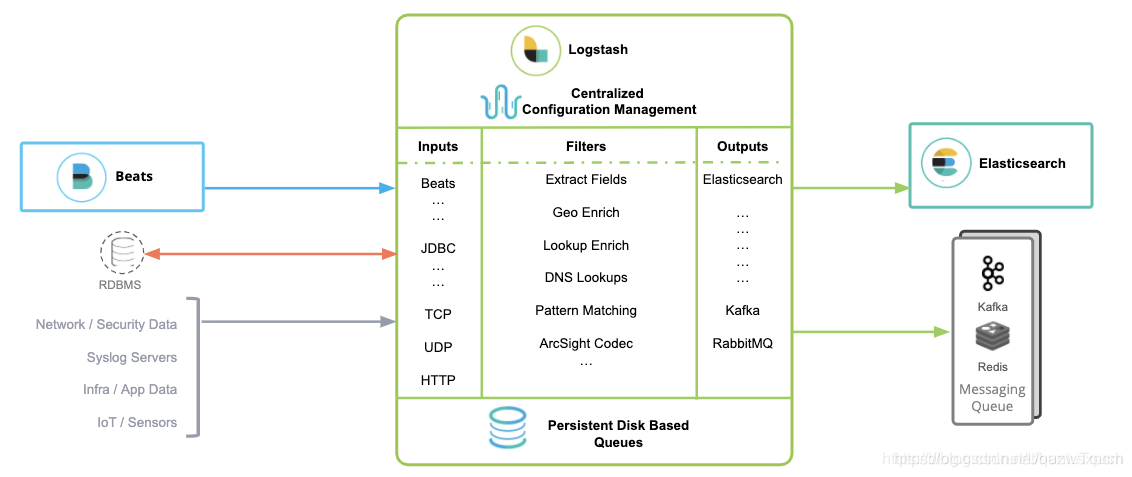
Logstash包含3個主要部分: 輸入(inputs),過濾器(filters)和輸出(outputs),
inputs主要用來提供接收資料的規則,比如使用采集檔案內容;
filters主要是對傳輸的資料進行過濾,比如使用grok規則進行資料過濾;
outputs主要是將接收的資料根據定義的輸出模式來進行輸出資料,比如輸出到ElasticSearch中.
示例圖:
Logstash安裝使用
一、環境選擇
Logstash采用JRuby語言撰寫,運行在jvm中,因此安裝Logstash前需要先安裝JDK,如果是6.x的版本,jdk需要在8以上,如果是7.x的版本,則jdk版本在11以上,如果Elasticsearch集群是7.x的版本,可以使用Elasticsearch自身的jdk,
Logstash下載地址推薦使用清華大學或華為的開源鏡像站,
下載地址:
https://mirrors.huaweicloud.com/logstash
https://mirrors.tuna.tsinghua.edu.cn/ELK
ELK7.3.2百度網盤地址:
鏈接:https://pan.baidu.com/s/1tq3Czywjx3GGrreOAgkiGg
提取碼:cxng
二、JDK安裝
注:JDK版本請以自身Elasticsearch集群的版本而定,
1,檔案準備
解壓下載下來的JDK
tar -xvf jdk-8u144-linux-x64.tar.gz
移動到opt/java檔案夾中,沒有就新建,然后將檔案夾重命名為jdk1.8
mv jdk1.8.0_144 /opt/java
mv jdk1.8.0_144 jdk1.8
2,環境配置
首先輸入 java -version
查看是否安裝了JDK,如果安裝了,但版本不適合的話,就卸載
輸入
rpm -qa | grep java
查看資訊
然后輸入:
rpm -e --nodeps “你要卸載JDK的資訊”
如: rpm -e --nodeps java-1.7.0-openjdk-1.7.0.99-2.6.5.1.el6.x86_64

確認沒有了之后,解壓下載下來的JDK
tar -xvf jdk-8u144-linux-x64.tar.gz
移動到opt/java檔案夾中,沒有就新建,然后將檔案夾重命名為jdk1.8,
mv jdk1.8.0_144 /opt/java
mv jdk1.8.0_144 jdk1.8
然后編輯 profile 檔案,添加如下配置
輸入: vim /etc/profile
export JAVA_HOME=/opt/java/jdk1.8
export JRE_HOME=/opt/java/jdk1.8/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
export PATH=.:${JAVA_HOME}/bin:$PATH
添加成功之后,輸入:
source /etc/profile
使配置生效,然后查看版本資訊輸入:
java -version
三、Logstash安裝
1,檔案準備
將下載下來的logstash-7.3.2.tar.gz的組態檔進行解壓
在linux上輸入:
tar -xvf logstash-7.3.2.tar.gz
然后移動到/opt/elk 里面,然后將檔案夾重命名為 logstash-7.3.2
輸入
mv logstash-7.3.2.tar /opt/elk
mv logstash-7.3.2.tar logstash-7.3.2
2,配置修改
這里簡單介紹一下 inputs,filters、outputs三個主要配置,
inputs
inputs主要使用的幾個配置項:
-
path:必選項,讀取檔案的路徑,基于glob匹配語法, exclude:可選項,陣列型別,排除不想監聽的檔案規則,基于glob匹配語法,
-
sincedb_path:可選項,記錄sinceddb檔案路徑以及檔案讀取資訊位置的資料檔案,
-
start_position:可選項,可以配置為beginning/end,是否從頭讀取檔案,默認從尾部值為:end,
-
stat_interval:可選項,單位為秒,定時檢查檔案是否有更新,默認是1秒,
-
discover_interval:可選項,單位為秒,定時檢查是否有新檔案待讀取,默認是15秒
-
ignore_older:可選項,單位為秒,掃描檔案串列時,如果該檔案上次更改時間超過設定的時長,則不做處理,但依然會監控是否有新內容,默認關閉,
-
close_older:可選項,單位為秒,如果監聽的檔案在超過該設定時間內沒有新內容,會被關閉檔案句柄,釋放資源,但依然會監控是否有新內容,默認3600秒,即1小時,
-
tags :可選項,在資料處理程序中,由具體的插件來添加或者洗掉的標記, type :可選項,自定義處理時間型別,比如nginxlog,
一個簡單的input輸入示例:
input {
file {
path => "/home/logs/mylog.log"
}
}
上述這段配置表示采集/home/logs/mylog.log的日志,如果是采集整個目錄的話,則可以通過*通配符來進行匹配,如
path => "/home/logs/*.log"
表示采集該目錄下所有后綴名為.log的日志,
通過logstash-input-file插件匯入了一些本地日志檔案時,logstash會通過一個名為sincedb的獨立檔案中來跟蹤記錄每個檔案中的當前位置,這使得停止和重新啟動Logstash成為可能,并讓它在不丟失在停止Logstashwas時添加到檔案中的行數的情況下繼續運行,
在除錯的時候,我們可能希望取消sincedb的記錄功能,使檔案每次都能從頭開始讀取,此時,我們可以這樣來做
示例:
input {
file {
path => "/home/logs/mylog.log"
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
如果想使用HTTP輸入,可以將型別改成http,只不過里面的引數有不同而已,tcp、udp、syslog和beats等等同理,
示例:
input {
http {
port => 埠號
}
}
filter
filter主要是實作過濾的功能,比如使用grok實作日志內容的切分等等,
比如對apache的日志進行grok過濾
樣例資料:
127.0.0.1 - - [13/Apr/2015:17:22:03 +0800] "GET /router.php HTTP/1.1" 404 285 "-" "curl/7.19.7 (x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.15.3 zlib/1.2.3 libidn/1.18 libssh2/1.4.2"
grok:
%{COMBINEDAPACHELOG}
這里我們可以使用kibana的grok來進行分析,grok在開發工具中,當然也可以在http://grokdebug.herokuapp.com/網站進行匹配除錯,
使用示例:
filter {
grok {
match => ["message", "%{COMBINEDAPACHELOG}"]
}
}
示例圖:
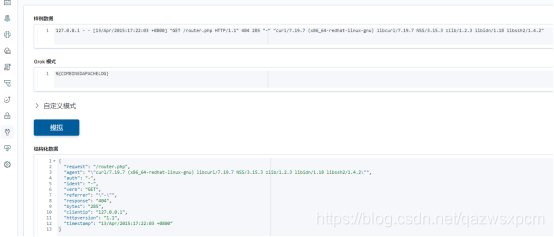
如果沒有這方面的需求,可以不配做filter,
output
output主要作用是將資料進行輸出,比如輸出到檔案,或者elasticsearch中,
這里將資料輸出到ElasticSearch中,如果是集群,通過逗號可以配置多個節點,
output {
elasticsearch {
hosts => ["127.0.0.1:9200"]
}
}
如果想在控制臺進行日志輸出的話,可以加上stdout配置,如果想自定義輸出的index話,也可以加上對應的索引庫名稱,不存在則根據資料內容進行創建,也可以自動按天創建索引庫,
示例如下:
output {
stdout {
codec => rubydebug
}
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "mylogs-%{+YYYY.MM.dd}"
}
}
更多logstash配置:https://www.elastic.co/guide/en/logstash/current/index.html
3,使用
demo
在/home/logs/目錄下添加一個日志檔案, 然后在logstash檔案夾中創建一個logstash-test.conf檔案,然后在該檔案中添加如下配置:
input {
file {
path => "/home/logs/mylog.log"
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
filter {
}
output {
stdout {
codec => rubydebug
}
elasticsearch {
hosts => ["127.0.0.1:9200"]
}
}
然后在logstash 目錄輸入如下命令進行啟動:
./bin/logstash -f logstash-test.conf
后臺啟動:
nohup ./bin/logstash -f logstash-test.conf >/dev/null 2>&1 &
熱配置加載啟動:
nohup ./bin/logstash -f logstash-test.conf --config.reload.automatic >/dev/null 2>&1 &
啟動成功之后,如果是非后臺啟動,可以在控制臺查看資料的傳輸,如果是后臺啟動,則可以在logstash的log目錄中進行查看,
在kibana展示
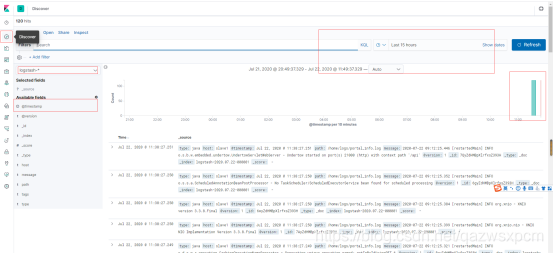
打開kibana,創建一個索引模板,操作如下圖所示:
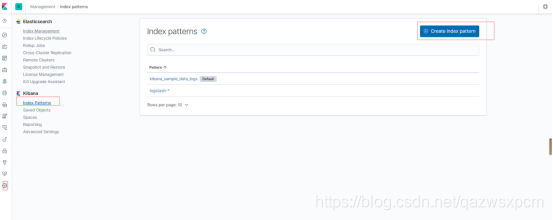
這里因為未指定索引庫,logstash使用的是logstash默認的模板,這里選擇它就可,
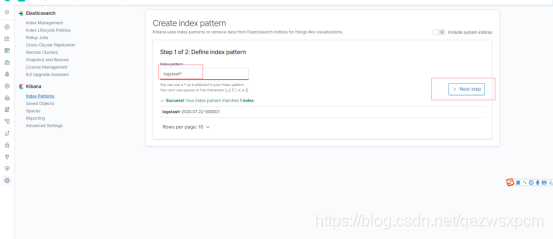
然后創建一個儀表盤,選擇剛剛創建的索引庫模板,就可以查看資料的情況了,
其它
參考:https://elasticstack.blog.csdn.net/article/details/105973985
ElasticSearch實戰系列:
- ElasticSearch實戰系列一: ElasticSearch集群+Kinaba安裝教程
- ElasticSearch實戰系列二: ElasticSearch的DSL陳述句使用教程---圖文詳解
- ElasticSearch實戰系列三: ElasticSearch的JAVA API使用教程
- ElasticSearch實戰系列四: ElasticSearch理論知識介紹
- ElasticSearch實戰系列四: ElasticSearch理論知識介紹
- ElasticSearch實戰系列五: ElasticSearch的聚合查詢基礎使用教程之度量(Metric)聚合
音樂推薦
<iframe frameborder="no" border="0" marginwidth="0" marginheight="0" width="330" height="86" src="https://www.cnblogs.com//music.163.com/outchain/player?type=2&id=5330830&auto=0&height=66"></iframe>原創不易,如果感覺不錯,希望給個推薦!您的支持是我寫作的最大動力!
著作權宣告:
作者:虛無境
博客園出處:http://www.cnblogs.com/xuwujing
CSDN出處:http://blog.csdn.net/qazwsxpcm
個人博客出處:http://www.panchengming.com
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/117769.html
標籤:Java