本文用python在TCP的基礎上實作一個HTTP客戶端, 該客戶端能夠復用TCP連接, 使用HTTP1.1協議.
一. 創建HTTP請求
HTTP是基于TCP連接的, 它的請求報文格式如下:
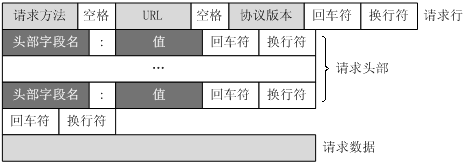
因此, 我們只需要創建一個到服務器的TCP連接, 然后按照上面的格式寫好報文并發給服務器, 就實作了一個HTTP請求.
1. HTTPConnection類
基于以上的分析, 我們首先定義一個HTTPConnection類來管理連接和請求內容:
class HTTPConnection: default_port = 80 _http_vsn = 11 _http_vsn_str = 'HTTP/1.1' def __init__(self, host: str, port: int = None) -> None: self.sock = None self._buffer = [] self.host = host self.port = port if port is not None else self.default_port self._state = _CS_IDLE self._response = None self._method = None self.block_size = 8192 def _output(self, s: Union[str, bytes]) -> None: if hasattr(s, 'encode'): s = s.encode('latin-1') self._buffer.append(s) def connect(self) -> None: self.sock = socket.create_connection((self.host, self.port))
對于這個HTTPConnection物件, 我們只需要創建TCP連接, 然后按照HTTP協議的格式把請求資料寫入buffer中, 最后把buffer中的資料發送出去就行了.
2. 撰寫請求行
請求行的內容比較簡單, 就是說明請求方法, 請求路徑和HTTP協議. 使用下面的方法來撰寫一個請求行:
def put_request(self, method: str, url: str) -> None: self._method = method url = url or '/' request = f'{method} {url} {self._http_vsn_str}' self._output(request)
3. 添加請求頭
HTTP請求頭和python的字典類似, 每行都是一個欄位名與值的映射關系. HTTP協議并不要求設定所有合法的請求頭的值, 我們只需要按照需要, 設定特定的請求頭即可. 使用如下代碼添加請求頭:
def put_header(self, header: Union[bytes, str], value: Union[bytes, str, int]) -> None: if hasattr(header, 'encode'): header = header.encode('ascii') if hasattr(value, 'encode'): value = value.encode('latin-1') elif isinstance(value, int): value = str(value).encode('ascii') header = header + b': ' + value self._output(header)
此外, 在HTTP請求中, Host請求頭欄位是必須的, 否則網站可能會拒絕回應. 因此, 如果用戶沒有設定這個欄位, 這里就應該主動把它加上去:
def _add_host(self, url: str) -> None: # 所有HTTP / 1.1請求報文中必須包含一個Host頭欄位 # 如果用戶沒給,就呼叫這個函式來生成 netloc = '' if url.startswith('http'): nil, netloc, nil, nil, nil = urllib.parse.urlsplit(url) if netloc: try: netloc_enc = netloc.encode('ascii') except UnicodeEncodeError: netloc_enc = netloc.encode('idna') self.put_header('Host', netloc_enc) else: host = self.host port = self.port try: host_enc = host.encode('ascii') except UnicodeEncodeError: host_enc = host.encode('idna') # 對IPv6的地址進行額外處理 if host.find(':') >= 0: host_enc = b'[' + host_enc + b']' if port == self.default_port: self.put_header('Host', host_enc) else: host_enc = host_enc.decode('ascii') self.put_header('Host', f'{host_enc}:{port}')
4. 發送請求正文
我們接受兩種形式的body資料: 一個基于io.IOBase的可讀檔案物件, 或者是一個能通過迭代得到資料的物件. 在傳輸資料之前, 我們首先要確定資料是否采用分塊傳輸:
def request(self, method: str, url: str, headers: dict = None, body: Union[io.IOBase, Iterable] = None, encode_chunked: bool = False) -> None: ... if 'content-length' not in header_names: if 'transfer-encoding' not in header_names: encode_chunked = False content_length = self._get_content_length(body, method) if content_length is None: if body is not None: # 在這種情況下, body一般是個生成器或者可讀檔案之類的東西,應該分塊傳輸 encode_chunked = True self.put_header('Transfer-Encoding', 'chunked') else: self.put_header('Content-Length', str(content_length)) else: # 如果設定了transfer-encoding,則根據用戶給的encode_chunked引數決定是否分塊 pass else: # 只要給了content-length,那么一定不是分塊傳輸 encode_chunked = False ... @staticmethod def _get_content_length(body: Union[str, bytes, bytearray, Iterable, io.IOBase], method: str) -> Optional[int]: if body is None: # PUT,POST,PATCH三個方法默認是有body的 if method.upper() in _METHODS_EXPECTING_BODY: return 0 else: return None if hasattr(body, 'read'): return None try: # 對于bytes或者bytearray格式的資料,通過memoryview獲取它的長度 return memoryview(body).nbytes except TypeError: pass if isinstance(body, str): return len(body) return None
在確定了是否分塊之后, 就可以把正文發出去了. 如果body是一個可讀檔案的話, 就呼叫_read_readable方法把它封裝為一個生成器:
def _send_body(self, message_body: Union[str, bytes, bytearray, Iterable, io.IOBase], encode_chunked: bool) -> None: if hasattr(message_body, 'read'): chunks = self._read_readable(message_body) else: try: memoryview(message_body) except TypeError: try: chunks = iter(message_body) except TypeError: raise TypeError( f'message_body should be a bytes-like object or an iterable, got {repr(type(message_body))}') else: # 如果是位元組型別的,通過一次迭代把它發出去 chunks = (message_body,) for chunk in chunks: if not chunk: continue if encode_chunked: chunk = f'{len(chunk):X}\r\n'.encode('ascii') + chunk + b'\r\n' self.send(chunk) if encode_chunked: self.send(b'0\r\n\r\n') def _read_readable(self, readable: io.IOBase) -> Generator[bytes, None, None]: need_encode = False if isinstance(readable, io.TextIOBase): need_encode = True while True: data_block = readable.read(self.block_size) if not data_block: break if need_encode: data_block = data_block.encode('utf-8') yield data_block
二. 獲取回應資料
HTTP回應報文的格式與請求報文大同小異, 它大致是這樣的:
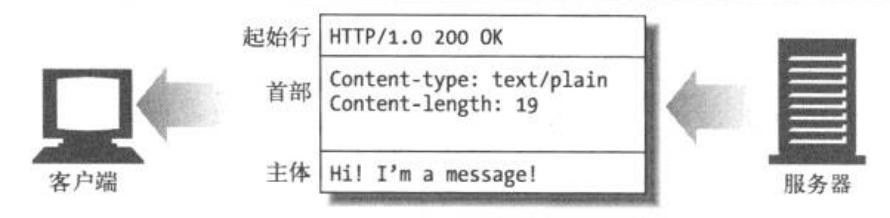
因此, 我們只要用HTTPConnection的socket物件讀取服務器發送的資料, 然后按照上面的格式對資料進行決議就行了.
1. HTTPResponse類
我們首先定義一個簡單的HTTPResponse類. 它的屬性大致上就是socket的檔案物件以及一些請求的資訊等等, 呼叫它的begin方法來決議回應行和回應頭的資料, 然后呼叫read方法讀取回應正文:
class HTTPResponse: def __init__(self, sock: socket.socket, method: str = None) -> None: self.fp = sock.makefile('rb') self._method = method self.headers = None self.version = _UNKNOWN self.status = _UNKNOWN self.reason = _UNKNOWN self.chunked = _UNKNOWN self.chunk_left = _UNKNOWN self.length = _UNKNOWN self.will_close = _UNKNOWN def begin(self) -> None: ... def read(self, amount: int = None) -> bytes: ...
2. 決議狀態行
狀態行的決議比較簡單, 我們只需要讀取回應的第一行資料, 然后把它決議為HTTP協議版本,狀態碼和原因短語三部分就行了:
def _read_status(self) -> Tuple[str, int, str]: line = str(self._read_line(), 'latin-1') if not line: raise RemoteDisconnected('Remote end closed connection without response') try: version, status, reason = line.split(None, 2) except ValueError: # reason只是給人看的, 一般和status對應, 所以它有可能不存在 try: version, status = line.split(None, 1) reason = '' except ValueError: version, status, reason = '', '', '' if not version.startswith('HTTP/'): self._close_conn() raise BadStatusLine(line) try: status = int(status) if status < 100 or status > 999: raise BadStatusLine(line) except ValueError: raise BadStatusLine(line) return version, status, reason.strip()
如果狀態碼為100, 則客戶端需要決議多個回應狀態行. 它的原理是這樣的: 在請求資料過大的時候, 有的客戶端會先不發送請求資料, 而是先在header中添加一個Expect: 100-continue, 如果服務器愿意接收資料, 會回傳100的狀態碼, 這時候客戶端再把資料發過去. 因此, 如果讀取到100的狀態碼, 那么后面往往還會收到一個正式的回應資料, 應該繼續讀取回應頭. 這部分的代碼如下:
def begin(self) -> None: while True: version, status, reason = self._read_status() if status != HTTPStatus.CONTINUE: break # 跳過100狀態碼部分的回應頭 while True: skip = self._read_line().strip() if not skip: breakself.status = status self.reason = reason if version in ('HTTP/1.0', 'HTTP/0.9'): self.version = 10 elif version.startswith('HTTP/1.'): self.version = 11 else: # HTTP2還沒研究, 這里就不寫了 raise UnknownProtocol(version) ...
3. 決議回應頭
決議回應頭比回應行還要簡單. 因為每個header欄位占一行, 我們只需要一直呼叫read_line方法讀取欄位, 直到讀完header為止就行了.
def _parse_header(self) -> None: headers = {} while True: line = self._read_line() if len(headers) > _MAX_HEADERS: raise HTTPException('got more than %d headers' % _MAX_HEADERS) if line in _EMPTY_LINE: break line = line.decode('latin-1') i = line.find(':') if i == -1: raise BadHeaderLine(line) # 這里默認沒有重名的情況 key, value = https://www.cnblogs.com/q1214367903/p/line[:i].lower(), line[i + 1:].strip() headers[key] = value self.headers = headers
4. 接收回應正文
在接收回應正文之前, 首先要確定它的傳輸方式和長度:
def _set_chunk(self) -> None: transfer_encoding = self.get_header('transfer-encoding') if transfer_encoding and transfer_encoding.lower() == 'chunked': self.chunked = True self.chunk_left = None else: self.chunked = False def _set_length(self) -> None: # 首先要知道資料是否是分塊傳輸的 if self.chunked == _UNKNOWN: self._set_chunk() # 如果狀態碼是1xx或者204(無回應內容)或者304(使用上次快取的內容),則沒有回應正文 # 如果這是個HEAD請求,那么也不能有回應正文 if (self.status == HTTPStatus.NO_CONTENT or self.status == HTTPStatus.NOT_MODIFIED or 100 <= self.status < 200 or self._method == 'HEAD'): self.length = 0 return length = self.get_header('content-length') if length and not self.chunked: try: self.length = int(length) except ValueError: self.length = None else: if self.length < 0: self.length = None else: self.length = None
然后, 我們實作一個read方法, 從body中讀取指定大小的資料:
def read(self, amount: int = None) -> bytes: if self.is_closed(): return b'' if self._method == 'HEAD': self.close() return b'' if amount is None: return self._read_all() return self._read_amount(amount)
如果沒有指定需要的資料大小, 就默認讀取所有資料:
def _read_all(self) -> bytes: if self.chunked: return self._read_all_chunk() if self.length is None: s = self.fp.read() else: try: s = self._read_bytes(self.length) except IncompleteRead: self.close() raise self.length = 0 self.close() return s def _read_all_chunk(self) -> bytes: assert self.chunked != _UNKNOWN value = [] try: while True: chunk = self._read_chunk() if chunk is None: break value.append(chunk) return b''.join(value) except IncompleteRead: raise IncompleteRead(b''.join(value)) def _read_chunk(self) -> Optional[bytes]: try: chunk_size = self._read_chunk_size() except ValueError: raise IncompleteRead(b'') if chunk_size == 0: self._read_and_discard_trailer() self.close() return None chunk = self._read_bytes(chunk_size) # 每塊的結尾會有一個\r\n,這里把它讀掉 self._read_bytes(2) return chunk def _read_chunk_size(self) -> int: line = self._read_line(error_message='chunk size') i = line.find(b';') if i >= 0: line = line[:i] try: return int(line, 16) except ValueError: self.close() raise def _read_and_discard_trailer(self) -> None: # chunk的尾部可能會掛一些額外的資訊,比如MD5值,過期時間等等,一般會在header中用trailer欄位說明 # 當chunk讀完之后呼叫這個函式, 這些資訊就先舍棄掉得了 while True: line = self._read_line(error_message='chunk size') if line in _EMPTY_LINE: break
否則的話, 就讀取部分資料, 如果正好是分塊資料的話, 就比較復雜了. 簡單來說, 就是用bytearray制造一個所需大小的陣列, 然后依次讀取chunk把資料往里面填, 直到填滿或者沒資料為止. 然后用chunk_left記錄下當前塊剩余的量, 以便下次讀取.
def _read_amount(self, amount: int) -> bytes: if self.chunked: return self._read_amount_chunk(amount) if isinstance(self.length, int) and amount > self.length: amount = self.length container = bytearray(amount) n = self.fp.readinto(container) if not n and container: # 如果讀不到位元組了,也就可以關了 self.close() elif self.length is not None: self.length -= n if not self.length: self.close() return memoryview(container)[:n].tobytes() def _read_amount_chunk(self, amount: int) -> bytes: # 呼叫這個方法,讀取amount大小的chunk型別資料,不足就全部讀取 assert self.chunked != _UNKNOWN total_bytes = 0 container = bytearray(amount) mvb = memoryview(container) try: while True: # mvb可以理解為容器的空的那一部分 # 這里一直呼叫_full_readinto把資料填進去,讓mvb越來越小,同時記錄填入的量 # 等沒資料或者當前資料足夠把mvb填滿之后,跳出回圈 chunk_left = self._get_chunk_left() if chunk_left is None: break if len(mvb) <= chunk_left: n = self._full_readinto(mvb) self.chunk_left = chunk_left - n total_bytes += n break temp_mvb = mvb[:chunk_left] n = self._full_readinto(temp_mvb) mvb = mvb[n:] total_bytes += n self.chunk_left = 0 except IncompleteRead: raise IncompleteRead(bytes(container[:total_bytes])) return memoryview(container)[:total_bytes].tobytes() def _full_readinto(self, container: memoryview) -> int: # 回傳讀取的量.如果沒能讀滿,這個方法會報警 amount = len(container) n = self.fp.readinto(container) if n < amount: raise IncompleteRead(bytes(container[:n]), amount - n) return n def _get_chunk_left(self) -> Optional[int]: # 如果當前塊讀了一半,那么直接回傳self.chunk_left就行了 # 否則,有三種情況 # 1). chunk_left為None,說明body壓根沒開始讀,于是回傳當前這一整塊的長度 # 2). chunk_left為0,說明這塊讀完了,于是回傳下一塊的長度 # 3). body資料讀完了,回傳None,順便做好善后作業 chunk_left = self.chunk_left if not chunk_left: if chunk_left == 0: # 如果剩余零,說明上一塊已經讀完了,這里把\r\n讀掉 # 如果是None,就說明chunk壓根沒開始讀 self._read_bytes(2) try: chunk_left = self._read_chunk_size() except ValueError: raise IncompleteRead(b'') if chunk_left == 0: self._read_and_discard_trailer() self.close() chunk_left = None self.chunk_left = chunk_left return chunk_left
三. 復用TCP連接
HTTP通信本質上是基于TCP連接發送和接收HTTP請求和回應, 因此, 只要TCP連接不斷開, 我們就可以繼續用它進行HTTP請求, 這樣就避免了創建和銷毀TCP連接產生的消耗.
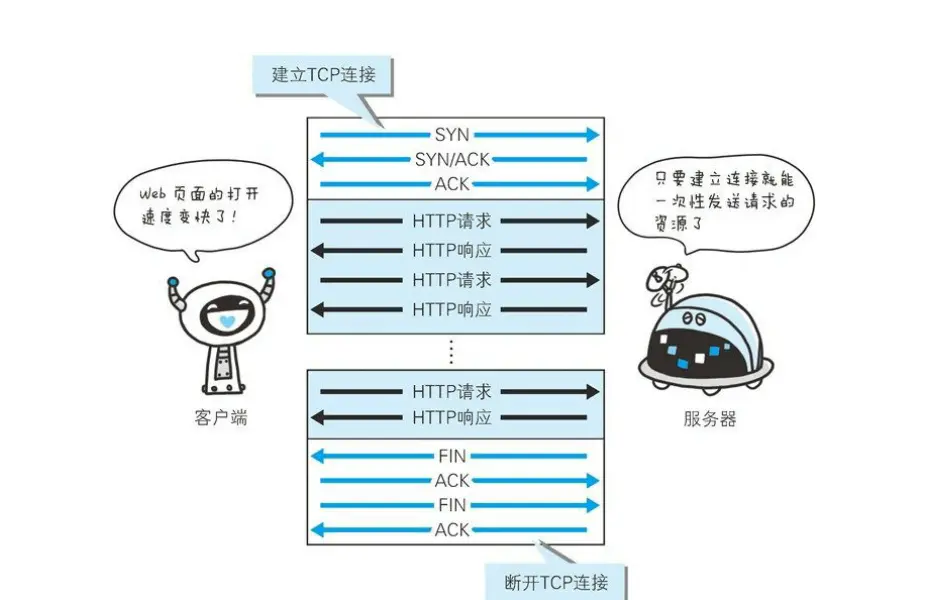
1. 判斷連接是否會斷開
在下面幾種情況中, 服務端會自動斷開連接:
- HTTP協議小于1.1且沒有在頭部設定了keep-alive
- HTTP協議大于等于1.1但是在頭部設定了connection: close
- 資料沒有分塊傳輸, 也沒有說明資料的長度, 這種情況下, 服務器一般會在發送完成后斷開連接, 讓客戶端知道資料發完了
根據上面列出來的幾種情況, 通過下面的代碼來判斷連接是否會斷開:
def _check_close(self) -> bool: conn = self.get_header('connection') if not self.chunked and self.length is None: return True if self.version == 11: if conn and 'close' in conn.lower(): return True return False else: if self.headers.get('keep-alive'): return False if conn and 'keep-alive' in conn.lower(): return False return True
2. 正確地關閉HTTPResponse物件
由于TCP連接的復用, 一個HTTPConnection可以產生多個HTTPResponse物件, 而這些物件在同一個TCP連接上, 會共用這個連接的讀緩沖區. 這就導致, 如果上一個HTTPResponse物件沒有把它的那部分資料讀完, 就會對下一個回應產生影響.
另一方面來看, 我們也需要及時地關閉與這個TCP關聯的檔案物件來避免占用資源. 因此, 我們定義如下的close方法關閉一個HTTPResponse物件:
def close(self) -> None: if self.is_closed(): return fp = self.fp self.fp = None fp.close() def is_closed(self) -> bool: return self.fp is None
用戶呼叫HTTPResponse物件的read方法, 把緩沖區資料讀完之后, 就會自動呼叫close方法(具體實作見上一章的第四節: 讀取回應資料這部分). 因此, 在獲取下一個回應資料之前, 我們只需要呼叫這個物件的is_closed方法, 就能判斷讀緩沖區是否已經讀完, 能否繼續接收回應了.
3. HTTP請求的生命周期
對于HTTP/1.1以及更低版本的HTTP協議來說, 不同的HTTP請求必須按次序進行, 相互之間不能重疊. 基于這個原因, 我們為HTTPConnection物件設定IDLE, REQ_STARTED和REQ_SENT三種狀態, 一個完整的請求應該經歷這幾種狀態:
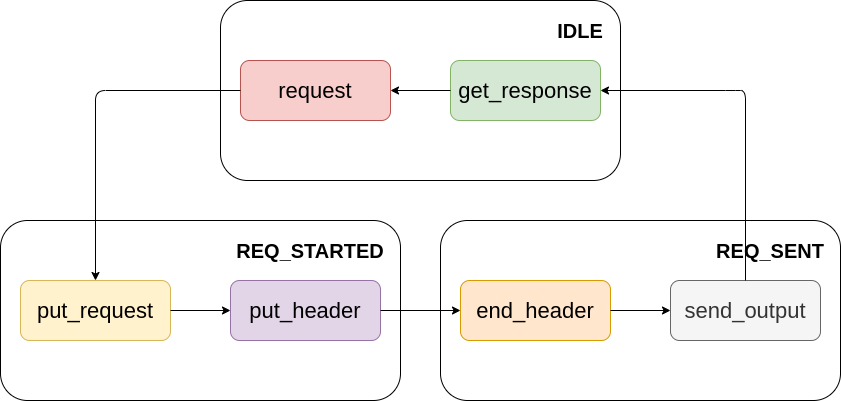
根據上面的流程, 對HTTPConnection中對應的方法進行修改:
def get_response(self) -> HTTPResponse: if self._response and self._response.is_closed(): self._response = None if self._state != _CS_REQ_SENT or self._response: raise ResponseNotReady(self._state) response = HTTPResponse(self.sock, method=self._method) try: try: response.begin() except ConnectionError: self.close() raise assert response.will_close != _UNKNOWN self._state = _CS_IDLE if response.will_close: self.close() else: self._response = response return response except Exception as _: response.close() raise def put_request(self, method: str, url: str) -> None: # 呼叫這個函式開始新一輪的請求,它負責寫好請求行輸出到快取里面去 # 呼叫它的前提是當前處于空閑狀態 # 如果之前的response還在并且已結束,會自動把它消除掉 if self._response and self._response.is_closed(): self._response = None if self._state == _CS_IDLE: self._state = _CS_REQ_STARTED else: raise CannotSendRequest(self._state) ... def put_header(self, header: Union[bytes, str], value: Union[bytes, str, int]) -> None: if self._state != _CS_REQ_STARTED: raise CannotSendHeader() ... def end_headers(self, message_body=None, encode_chunked=False) -> None: if self._state == _CS_REQ_STARTED: self._state = _CS_REQ_SENT else: raise CannotSendHeader() ...
需要注意的是, 如果第二個請求已經進入到獲取回應的階段了, 而上一個請求的回應還沒關閉, 那么就應該直接報錯, 否則讀取到的會是上一個請求剩余的回應部分資料, 導致決議回應出現問題.
四. 總結
1. 完整代碼
HTTPConnection的完整代碼如下:


class HTTPConnection: default_port = 80 _http_vsn = 11 _http_vsn_str = 'HTTP/1.1' def __init__(self, host: str, port: int = None) -> None: self.sock = None self._buffer = [] self.host = host self.port = port if port is not None else self.default_port self._state = _CS_IDLE self._response = None self._method = None self.block_size = 8192 def request(self, method: str, url: str, headers: dict = None, body: Union[io.IOBase, Iterable] = None, encode_chunked: bool = False) -> None: self.put_request(method, url) headers = headers or {} header_names = frozenset(k.lower() for k in headers.keys()) if 'host' not in header_names: self._add_host(url) if 'content-length' not in header_names: if 'transfer-encoding' not in header_names: encode_chunked = False content_length = self._get_content_length(body, method) if content_length is None: if body is not None: encode_chunked = True self.put_header('Transfer-Encoding', 'chunked') else: self.put_header('Content-Length', str(content_length)) else: # 如果設定了transfer-encoding,則根據用戶給的encode_chunked引數決定是否分塊 pass else: # 只要給了content-length,那么一定不是分塊傳輸 encode_chunked = False for hdr, value in headers.items(): self.put_header(hdr, value) if isinstance(body, str): body = _encode(body) self.end_headers(body, encode_chunked=encode_chunked) def send(self, data: bytes) -> None: if self.sock is None: self.connect() self.sock.sendall(data) def get_response(self) -> HTTPResponse: if self._response and self._response.is_closed(): self._response = None if self._state != _CS_REQ_SENT or self._response: raise ResponseNotReady(self._state) response = HTTPResponse(self.sock, method=self._method) try: try: response.begin() except ConnectionError: self.close() raise assert response.will_close != _UNKNOWN self._state = _CS_IDLE if response.will_close: self.close() else: self._response = response return response except Exception as _: response.close() raise def connect(self) -> None: self.sock = socket.create_connection((self.host, self.port)) def close(self) -> None: self._state = _CS_IDLE try: sock = self.sock if sock: self.sock = None sock.close() finally: response = self._response if response: self._response = None response.close() def put_request(self, method: str, url: str) -> None: # 呼叫這個函式開始新一輪的請求,它負責寫好請求行輸出到快取里面去 # 呼叫它的前提是當前處于空閑狀態 # 如果之前的response還在并且已結束,會自動把它消除掉 if self._response and self._response.is_closed(): self._response = None if self._state == _CS_IDLE: self._state = _CS_REQ_STARTED else: raise CannotSendRequest(self._state) self._method = method url = url or '/' request = f'{method} {url} {self._http_vsn_str}' self._output(request) def put_header(self, header: Union[bytes, str], value: Union[bytes, str, int]) -> None: if self._state != _CS_REQ_STARTED: raise CannotSendHeader() if hasattr(header, 'encode'): header = header.encode('ascii') if hasattr(value, 'encode'): value = value.encode('latin-1') elif isinstance(value, int): value = str(value).encode('ascii') header = header + b': ' + value self._output(header) def end_headers(self, message_body=None, encode_chunked=False) -> None: if self._state == _CS_REQ_STARTED: self._state = _CS_REQ_SENT else: raise CannotSendHeader() self._send_output(message_body, encode_chunked=encode_chunked) def _add_host(self, url: str) -> None: # 所有HTTP / 1.1請求報文中必須包含一個Host頭欄位 # 如果用戶沒給,就呼叫這個函式來生成 netloc = '' if url.startswith('http'): nil, netloc, nil, nil, nil = urlsplit(url) if netloc: try: netloc_enc = netloc.encode('ascii') except UnicodeEncodeError: netloc_enc = netloc.encode('idna') self.put_header('Host', netloc_enc) else: host = self.host port = self.port try: host_enc = host.encode('ascii') except UnicodeEncodeError: host_enc = host.encode('idna') # 對IPv6的地址進行額外處理 if host.find(':') >= 0: host_enc = b'[' + host_enc + b']' if port == self.default_port: self.put_header('Host', host_enc) else: host_enc = host_enc.decode('ascii') self.put_header('Host', f'{host_enc}:{port}') def _output(self, s: Union[str, bytes]) -> None: # 將資料添加到緩沖區 if hasattr(s, 'encode'): s = s.encode('latin-1') self._buffer.append(s) def _send_output(self, message_body=None, encode_chunked=False) -> None: # 發送并清慷訓沖資料.然后,如果有請求正文,就也順便發送 self._buffer.extend((b'', b'')) msg = b'\r\n'.join(self._buffer) self._buffer.clear() self.send(msg) if message_body is not None: self._send_body(message_body, encode_chunked) def _send_body(self, message_body: Union[bytes, str, bytearray, Iterable, io.IOBase], encode_chunked: bool) -> None: if hasattr(message_body, 'read'): chunks = self._read_readable(message_body) else: try: memoryview(message_body) except TypeError: try: chunks = iter(message_body) except TypeError: raise TypeError( f'message_body should be a bytes-like object or an iterable, got {repr(type(message_body))}') else: # 如果是位元組型別的,通過一次迭代把它發出去 chunks = (message_body,) for chunk in chunks: if not chunk: continue if encode_chunked: chunk = f'{len(chunk):X}\r\n'.encode('ascii') + chunk + b'\r\n' self.send(chunk) if encode_chunked: self.send(b'0\r\n\r\n') def _read_readable(self, readable: io.IOBase) -> Generator[bytes, None, None]: need_encode = False if isinstance(readable, io.TextIOBase): need_encode = True while True: data_block = readable.read(self.block_size) if not data_block: break if need_encode: data_block = data_block.encode('utf-8') yield data_block @staticmethod def _get_content_length(body: Union[str, bytes, bytearray, Iterable, io.IOBase], method: str) -> Optional[int]: if body is None: # PUT,POST,PATCH三個方法默認是有body的 if method.upper() in _METHODS_EXPECTING_BODY: return 0 else: return None if hasattr(body, 'read'): return None try: # 對于bytes或者bytearray格式的資料,通過memoryview獲取它的長度 return memoryview(body).nbytes except TypeError: pass if isinstance(body, str): return len(body) return NoneHTTPConnection
HTTPResponse的完整代碼如下:
class HTTPResponse: def __init__(self, sock: socket.socket, method: str = None) -> None: self.fp = sock.makefile('rb') self._method = method self.headers = None self.version = _UNKNOWN self.status = _UNKNOWN self.reason = _UNKNOWN self.chunked = _UNKNOWN self.chunk_left = _UNKNOWN self.length = _UNKNOWN self.will_close = _UNKNOWN def begin(self) -> None: if self.headers is not None: return self._parse_status_line() self._parse_header() self._set_chunk() self._set_length() self.will_close = self._check_close() def _read_line(self, limit: int = _MAX_LINE + 1, error_message: str = '') -> bytes: # 注意,這個方法默認不去除line尾部的\r\n line = self.fp.readline(limit) if len(line) > _MAX_LINE: raise LineTooLong(error_message) return line def _read_bytes(self, amount: int) -> bytes: data = self.fp.read(amount) if len(data) < amount: raise IncompleteRead(data, amount - len(data)) return data def _parse_status_line(self) -> None: while True: version, status, reason = self._read_status() if status != HTTPStatus.CONTINUE: break while True: skip = self._read_line(error_message='header line').strip() if not skip: break self.status = status self.reason = reason if version in ('HTTP/1.0', 'HTTP/0.9'): self.version = 10 elif version.startswith('HTTP/1.'): self.version = 11 else: raise UnknownProtocol(version) def _read_status(self) -> Tuple[str, int, str]: line = str(self._read_line(error_message='status line'), 'latin-1') if not line: raise RemoteDisconnected('Remote end closed connection without response') try: version, status, reason = line.split(None, 2) except ValueError: # reason只是給人看的, 和status對應, 所以它有可能不存在 try: version, status = line.split(None, 1) reason = '' except ValueError: version, status, reason = '', '', '' if not version.startswith('HTTP/'): self.close() raise BadStatusLine(line) try: status = int(status) if status < 100 or status > 999: raise BadStatusLine(line) except ValueError: raise BadStatusLine(line) return version, status, reason.strip() def _parse_header(self) -> None: headers = {} while True: line = self._read_line(error_message='header line') if len(headers) > _MAX_HEADERS: raise HTTPException('got more than %d headers' % _MAX_HEADERS) if line in _EMPTY_LINE: break line = line.decode('latin-1') i = line.find(':') if i == -1: raise BadHeaderLine(line) # 這里默認沒有重名的情況 key, value = https://www.cnblogs.com/q1214367903/p/line[:i].lower(), line[i + 1:].strip() headers[key] = value self.headers = headers def _set_chunk(self) -> None: transfer_encoding = self.get_header('transfer-encoding') if transfer_encoding and transfer_encoding.lower() == 'chunked': self.chunked = True self.chunk_left = None else: self.chunked = False def _set_length(self) -> None: # 首先要知道資料是否是分塊傳輸的 if self.chunked == _UNKNOWN: self._set_chunk() # 如果狀態碼是1xx或者204(無回應內容)或者304(使用上次快取的內容),則沒有回應正文 # 如果這是個HEAD請求,那么也不能有回應正文 assert isinstance(self.status, int) if (self.status == HTTPStatus.NO_CONTENT or self.status == HTTPStatus.NOT_MODIFIED or 100 <= self.status < 200 or self._method == 'HEAD'): self.length = 0 return length = self.get_header('content-length') if length and not self.chunked: try: self.length = int(length) except ValueError: self.length = None else: if self.length < 0: self.length = None else: self.length = None def _check_close(self) -> bool: conn = self.get_header('connection') if not self.chunked and self.length is None: return True if self.version == 11: if conn and 'close' in conn.lower(): return True return False else: if self.headers.get('keep-alive'): return False if conn and 'keep-alive' in conn.lower(): return False return True def close(self) -> None: if self.is_closed(): return fp = self.fp self.fp = None fp.close() def is_closed(self) -> bool: return self.fp is None def read(self, amount: int = None) -> bytes: if self.is_closed(): return b'' if self._method == 'HEAD': self.close() return b'' if amount is None: return self._read_all() print(amount, amount is None) return self._read_amount(amount) def _read_all(self) -> bytes: if self.chunked: return self._read_all_chunk() if self.length is None: s = self.fp.read() else: try: s = self._read_bytes(self.length) except IncompleteRead: self.close() raise self.length = 0 self.close() return s def _read_all_chunk(self) -> bytes: assert self.chunked != _UNKNOWN value = [] try: while True: chunk = self._read_chunk() if chunk is None: break value.append(chunk) return b''.join(value) except IncompleteRead: raise IncompleteRead(b''.join(value)) def _read_chunk(self) -> Optional[bytes]: try: chunk_size = self._read_chunk_size() except ValueError: raise IncompleteRead(b'') if chunk_size == 0: self._read_and_discard_trailer() self.close() return None chunk = self._read_bytes(chunk_size) # 每塊的結尾會有一個\r\n,這里把它讀掉 self._read_bytes(2) return chunk def _read_chunk_size(self) -> int: line = self._read_line(error_message='chunk size') i = line.find(b';') if i >= 0: line = line[:i] try: return int(line, 16) except ValueError: self.close() raise def _read_and_discard_trailer(self) -> None: # chunk的尾部可能會掛一些額外的資訊,比如MD5值,過期時間等等,一般會在header中用trailer欄位說明 # 當chunk讀完之后呼叫這個函式, 這些資訊就先舍棄掉得了 while True: line = self._read_line(error_message='chunk size') if line in _EMPTY_LINE: break def _read_amount(self, amount: int) -> bytes: if self.chunked: return self._read_amount_chunk(amount) if isinstance(self.length, int) and amount > self.length: amount = self.length container = bytearray(amount) n = self.fp.readinto(container) if not n and container: # 如果讀不到位元組了,也就可以關了 self.close() elif self.length is not None: self.length -= n if not self.length: self.close() return memoryview(container)[:n].tobytes() def _read_amount_chunk(self, amount: int) -> bytes: # 呼叫這個方法,讀取amount大小的chunk型別資料,不足就全部讀取 assert self.chunked != _UNKNOWN total_bytes = 0 container = bytearray(amount) mvb = memoryview(container) try: while True: # mvb可以理解為容器的空的那一部分 # 這里一直呼叫_full_readinto把資料填進去,讓mvb越來越小,同時記錄填入的量 # 等沒資料或者當前資料足夠把mvb填滿之后,跳出回圈 chunk_left = self._get_chunk_left() if chunk_left is None: break if len(mvb) <= chunk_left: n = self._full_readinto(mvb) self.chunk_left = chunk_left - n total_bytes += n break temp_mvb = mvb[:chunk_left] n = self._full_readinto(temp_mvb) mvb = mvb[n:] total_bytes += n self.chunk_left = 0 except IncompleteRead: raise IncompleteRead(bytes(container[:total_bytes])) return memoryview(container)[:total_bytes].tobytes() def _full_readinto(self, container: memoryview) -> int: # 回傳讀取的量.如果沒能讀滿,這個方法會報警 amount = len(container) n = self.fp.readinto(container) if n < amount: raise IncompleteRead(bytes(container[:n]), amount - n) return n def _get_chunk_left(self) -> Optional[int]: # 如果當前塊讀了一半,那么直接回傳self.chunk_left就行了 # 否則,有三種情況 # 1). chunk_left為None,說明body壓根沒開始讀,于是回傳當前這一整塊的長度 # 2). chunk_left為0,說明這塊讀完了,于是回傳下一塊的長度 # 3). body資料讀完了,回傳None,順便做好善后作業 chunk_left = self.chunk_left if not chunk_left: if chunk_left == 0: # 如果剩余零,說明上一塊已經讀完了,這里把\r\n讀掉 # 如果是None,就說明chunk壓根沒開始讀 self._read_bytes(2) try: chunk_left = self._read_chunk_size() except ValueError: raise IncompleteRead(b'') if chunk_left == 0: self._read_and_discard_trailer() self.close() chunk_left = None self.chunk_left = chunk_left return chunk_left def get_header(self, name, default: str = None) -> Optional[str]: if self.headers is None: raise ResponseNotReady() return self.headers.get(name, default) @property def info(self) -> str: return repr(self.headers)HTTPResponse
這兩個類應該放到同一個py檔案中, 同時這個檔案內還有其他一些輔助性質的代碼:
import io import socket from typing import Generator, Iterable, Optional, Tuple, Union from urllib.parse import urlsplit _CS_IDLE = 'Idle' _CS_REQ_STARTED = 'Request-started' _CS_REQ_SENT = 'Request-sent' _METHODS_EXPECTING_BODY = {'PATCH', 'POST', 'PUT'} _UNKNOWN = 'UNKNOWN' _MAX_LINE = 65536 _MAX_HEADERS = 100 _EMPTY_LINE = (b'\r\n', b'\n', b'') class HTTPStatus: CONTINUE = 100 SWITCHING_PROTOCOLS = 101 PROCESSING = 102 OK = 200 CREATED = 201 ACCEPTED = 202 NON_AUTHORITATIVE_INFORMATION = 203 NO_CONTENT = 204 RESET_CONTENT = 205 PARTIAL_CONTENT = 206 MULTI_STATUS = 207 ALREADY_REPORTED = 208 IM_USED = 226 MULTIPLE_CHOICES = 300 MOVED_PERMANENTLY = 301 FOUND = 302 SEE_OTHER = 303 NOT_MODIFIED = 304 USE_PROXY = 305 TEMPORARY_REDIRECT = 307 PERMANENT_REDIRECT = 308 BAD_REQUEST = 400 UNAUTHORIZED = 401 PAYMENT_REQUIRED = 402 FORBIDDEN = 403 NOT_FOUND = 404 METHOD_NOT_ALLOWED = 405 NOT_ACCEPTABLE = 406 PROXY_AUTHENTICATION_REQUIRED = 407 REQUEST_TIMEOUT = 408 CONFLICT = 409 GONE = 410 LENGTH_REQUIRED = 411 PRECONDITION_FAILED = 412 REQUEST_ENTITY_TOO_LARGE = 413 REQUEST_URI_TOO_LONG = 414 UNSUPPORTED_MEDIA_TYPE = 415 REQUESTED_RANGE_NOT_SATISFIABLE = 416 EXPECTATION_FAILED = 417 MISDIRECTED_REQUEST = 421 UNPROCESSABLE_ENTITY = 422 LOCKED = 423 FAILED_DEPENDENCY = 424 UPGRADE_REQUIRED = 426 PRECONDITION_REQUIRED = 428 TOO_MANY_REQUESTS = 429 REQUEST_HEADER_FIELDS_TOO_LARGE = 431 UNAVAILABLE_FOR_LEGAL_REASONS = 451 INTERNAL_SERVER_ERROR = 500 NOT_IMPLEMENTED = 501 BAD_GATEWAY = 502 SERVICE_UNAVAILABLE = 503 GATEWAY_TIMEOUT = 504 HTTP_VERSION_NOT_SUPPORTED = 505 VARIANT_ALSO_NEGOTIATES = 506 INSUFFICIENT_STORAGE = 507 LOOP_DETECTED = 508 NOT_EXTENDED = 510 NETWORK_AUTHENTICATION_REQUIRED = 511 class HTTPResponse: ... class HTTPConnection: ... def _encode(data: str, encoding: str = 'latin-1', name: str = 'data') -> bytes: # 給請求正文等不知道能怎么轉碼的東西轉碼時用這個,默認使用latin-1編碼 # 它的好處是,轉碼失敗后能拋出詳細的錯誤資訊,一目了然 try: return data.encode(encoding) except UnicodeEncodeError as err: raise UnicodeEncodeError( err.encoding, err.object, err.start, err.end, "{} ({:.20!r}) is not valid {}. Use {}.encode('utf-8') if you want to send it encoded in UTF-8.".format( name.title(), data[err.start:err.end], encoding, name) ) from None class HTTPException(Exception): pass class ImproperConnectionState(HTTPException): pass class CannotSendRequest(ImproperConnectionState): pass class CannotSendHeader(ImproperConnectionState): pass class CannotCloseStream(ImproperConnectionState): pass class ResponseNotReady(ImproperConnectionState): pass class LineTooLong(HTTPException): def __init__(self, line_type): HTTPException.__init__(self, 'got more than %d bytes when reading %s' % (_MAX_LINE, line_type)) class BadStatusLine(HTTPException): def __init__(self, line): if not line: line = repr(line) self.args = line, self.line = line class BadHeaderLine(HTTPException): def __init__(self, line): if not line: line = repr(line) self.args = line, self.line = line class RemoteDisconnected(ConnectionResetError, BadStatusLine): def __init__(self, *args, **kwargs): BadStatusLine.__init__(self, '') ConnectionResetError.__init__(self, *args, **kwargs) class UnknownProtocol(HTTPException): def __init__(self, version): self.args = version, self.version = version class UnknownTransferEncoding(HTTPException): pass class IncompleteRead(HTTPException): def __init__(self, partial, expected=None): self.args = partial, self.partial = partial self.expected = expected def __repr__(self): if self.expected is not None: e = f', {self.expected} more expected' else: e = '' return f'{self.__class__.__name__}({len(self.partial)} bytes read{e})' __str__ = object.__str__client.py
2. 需要注意的點
總的來說, 本文的內容不算復雜, 畢竟HTTP屬于不難理解, 但知識點很多很雜的型別. 這里把本文中一些需要注意的點總結一下:
- 請求和回應資料的結構大致相同, 都是狀態行+頭部+正文, 狀態行和頭部的每個欄位都用一個\r\n分割, 與正文之間用兩個分割;
- 狀態行是必須的, 請求頭則最少需要host這個欄位, 同時為了大家的方便, 你最好也設定一下Accept-encoding和Accept來限制服務器回傳給你的資料內容和格式;
- 正文不是必須的, 特別是對于除了3P(PATCH, POST, PUT)之外的方法來說. 如果你有正文, 你最好在header中使用Content-Length說明正文的長度, 如果是分塊發送, 則使用Transfer-Encoding欄位說明;
- 如果對正文使用分塊傳輸, 每塊的格式是: 16進制的資料長度+\r\n+資料+\r\n, 使用0\r\n\r\n來收尾. 收尾之后, 你還可以放一個trailer, 里面放資料的MD5值或者過期時間什么的, 這時候最好在header中設定trailer欄位;
- 在一個請求的生命周期完成后, TCP連接是否會斷開取決于三點: 回應資料的HTTP版本, 回應頭中的Connection和Keep-Alive欄位, 是否知道回應正文的長度;
- 最最重要的一點, HTTP協議只是一個約定而非限制, 這就和礦泉水的建議零售價差不多, 你可以選擇遵守, 也可以不遵守, 后果自負.
3. 結果測驗
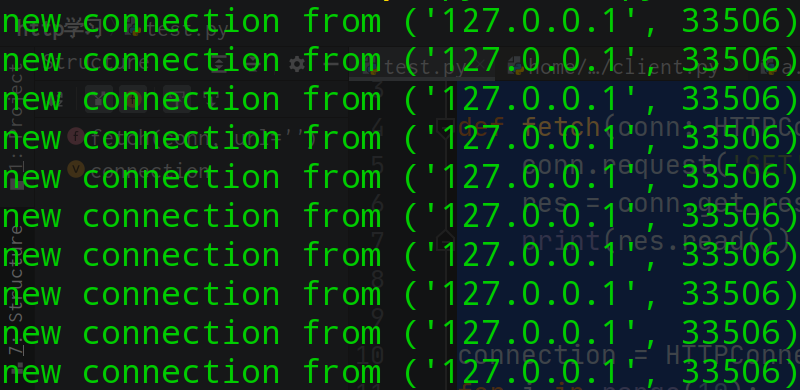
首先, 我們用tornado寫一個簡單的服務器, 它會顯示客戶端的地址和介面;
import tornado.web import tornado.ioloop class IndexHandler(tornado.web.RequestHandler): def get(self) -> None: print(f'new connection from {self.request.connection.context.address}') self.write('hello world') app = tornado.web.Application([(r'/', IndexHandler)]) app.listen(8888) tornado.ioloop.IOLoop.current().start()
然后, 使用我們剛寫好的客戶端進行測驗:
from client import HTTPConnection def fetch(conn: HTTPConnection, url: str = '') -> None: conn.request('GET', url) res = conn.get_response() print(res.read()) connection = HTTPConnection('127.0.0.1', 8888) for i in range(10): fetch(connection)
結果如下:
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/117834.html
標籤:Python
上一篇:pickle存盤和讀取資料