前面我們針對電影評論撰寫了二分類問題的解決方案,
這里對前面的這個方案進行一些改進,
分批訓練
model.fit(x_train, y_train, epochs=20, batch_size=512)
這里在訓練時增加了一個引數batch_size,使用 512 個樣本組成的小批量,將模型訓練 20 個輪次,
這個引數可以看成是在訓練時不一次性在全部的訓練集上進行,而是針對其中的512個題目分批次進行訓練,有點類似做512道題目進行訓練,然后看結果進行調整,而不是一次性做好25000道題目然后再對答案看哪里有問題,
這樣的結果是訓練的速度有很明顯的提高,原先在我的機器上訓練一個輪次要6秒,增加了這個批次引數后,訓練一個輪次只要1秒,
資料集再分類
首先我們對資料集進行一下再分類,
前面我們使用了訓練集和測驗集,
訓練集是用來訓練資料的,有點類似學習中的練習題;
測驗集有點類似考試題,
一般來講測驗集對我們是未知的,我們不知道要考什么試題,
為了能夠在練習時我們也能知道當前的學習狀況,因此我們會把練習題分出一部分來當做單元測驗,這樣我們不必等到未知的考題中來了解自己的學習狀況,
這里的單元測驗題就是驗證集,
代碼實作為:
# 分解驗證集
x_val = x_train[:10000]
y_val = y_train[:10000]
x_train = x_train[10000:]
y_train = y_train[10000:]
#編譯模型
model.compile(optimizer=keras.optimizers.RMSprop(), loss=keras.losses.binary_crossentropy, metrics=[keras.metrics.binary_accuracy])
#訓練模型
model.fit(x_train, y_train, epochs=20, batch_size=512, validation_data=https://www.cnblogs.com/dreampursuer/archive/2020/09/24/(x_val, y_val))
繪制訓練圖形
在訓練程序中控制臺中會列印出如下的資訊:
Train on 15000 samples, validate on 10000 samples
Epoch 1/20
15000/15000 [==============================] - 5s 317us/sample - loss: 0.5072 - binary_accuracy: 0.7900 - val_loss: 0.3850 - val_binary_accuracy: 0.8713
Epoch 2/20
15000/15000 [==============================] - 1s 66us/sample - loss: 0.3022 - binary_accuracy: 0.9020 - val_loss: 0.3317 - val_binary_accuracy: 0.8628
Epoch 3/20
15000/15000 [==============================] - 1s 52us/sample - loss: 0.2223 - binary_accuracy: 0.9283 - val_loss: 0.2890 - val_binary_accuracy: 0.8851
Epoch 4/20
15000/15000 [==============================] - 1s 52us/sample - loss: 0.1773 - binary_accuracy: 0.9424 - val_loss: 0.3087 - val_binary_accuracy: 0.8766
Epoch 5/20
15000/15000 [==============================] - 1s 53us/sample - loss: 0.1422 - binary_accuracy: 0.9546 - val_loss: 0.2819 - val_binary_accuracy: 0.8882
Epoch 6/20
15000/15000 [==============================] - 1s 57us/sample - loss: 0.1203 - binary_accuracy: 0.9635 - val_loss: 0.2935 - val_binary_accuracy: 0.8846
Epoch 7/20
15000/15000 [==============================] - 1s 57us/sample - loss: 0.0975 - binary_accuracy: 0.9709 - val_loss: 0.3163 - val_binary_accuracy: 0.8809
Epoch 8/20
15000/15000 [==============================] - 1s 53us/sample - loss: 0.0799 - binary_accuracy: 0.9778 - val_loss: 0.3383 - val_binary_accuracy: 0.8781
Epoch 9/20
15000/15000 [==============================] - 1s 52us/sample - loss: 0.0666 - binary_accuracy: 0.9814 - val_loss: 0.3579 - val_binary_accuracy: 0.8766
Epoch 10/20
15000/15000 [==============================] - 1s 56us/sample - loss: 0.0519 - binary_accuracy: 0.9879 - val_loss: 0.3926 - val_binary_accuracy: 0.8808
Epoch 11/20
15000/15000 [==============================] - 1s 57us/sample - loss: 0.0430 - binary_accuracy: 0.9899 - val_loss: 0.4163 - val_binary_accuracy: 0.8712
Epoch 12/20
15000/15000 [==============================] - 1s 58us/sample - loss: 0.0356 - binary_accuracy: 0.9921 - val_loss: 0.5044 - val_binary_accuracy: 0.8675
Epoch 13/20
15000/15000 [==============================] - 1s 54us/sample - loss: 0.0274 - binary_accuracy: 0.9943 - val_loss: 0.4995 - val_binary_accuracy: 0.8748
Epoch 14/20
15000/15000 [==============================] - 1s 53us/sample - loss: 0.0225 - binary_accuracy: 0.9957 - val_loss: 0.5040 - val_binary_accuracy: 0.8748
Epoch 15/20
15000/15000 [==============================] - 1s 53us/sample - loss: 0.0149 - binary_accuracy: 0.9984 - val_loss: 0.5316 - val_binary_accuracy: 0.8703
Epoch 16/20
15000/15000 [==============================] - 1s 52us/sample - loss: 0.0137 - binary_accuracy: 0.9984 - val_loss: 0.5672 - val_binary_accuracy: 0.8676
Epoch 17/20
15000/15000 [==============================] - 1s 51us/sample - loss: 0.0116 - binary_accuracy: 0.9985 - val_loss: 0.6013 - val_binary_accuracy: 0.8680
Epoch 18/20
15000/15000 [==============================] - 1s 52us/sample - loss: 0.0060 - binary_accuracy: 0.9998 - val_loss: 0.6460 - val_binary_accuracy: 0.8636
Epoch 19/20
15000/15000 [==============================] - 1s 51us/sample - loss: 0.0067 - binary_accuracy: 0.9993 - val_loss: 0.6791 - val_binary_accuracy: 0.8673
Epoch 20/20
15000/15000 [==============================] - 1s 53us/sample - loss: 0.0074 - binary_accuracy: 0.9987 - val_loss: 0.7243 - val_binary_accuracy: 0.8645
這里會顯示出訓練集和驗證集對應的損失值和精度,
數值上來看不是很直觀,我們可以通過圖形的方式來進行查看,
在呼叫model.fit()函式后會有一個回傳值:
history = model.fit(x_train, y_train, epochs=20, batch_size=512, validation_data=https://www.cnblogs.com/dreampursuer/archive/2020/09/24/(x_val, y_val))
這個物件有一個成員 history,它是一個字典,包含訓練程序中的所有資料,我們來看一下,
history = model.fit(x_train, y_train, epochs=20, batch_size=512, validation_data=https://www.cnblogs.com/dreampursuer/archive/2020/09/24/(x_val, y_val))
history_map = history.history
print("history_map:", history_map)
這里的history_map其中的key為:loss,val_loss,binary_accuracy,val_binary_accuracy
我們可以繪制一下訓練集和驗證集的損失值:loss,val_loss
#訓練模型
history = model.fit(x_train, y_train, epochs=20, batch_size=512, validation_data=https://www.cnblogs.com/dreampursuer/archive/2020/09/24/(x_val, y_val))
history_map = history.history
print("history_map:", history_map)
# 繪制訓練集和驗證集的損失值
loss_values = history_map['loss']
val_loss_values = history_map['val_loss']
epochs = range(1, len(loss_values) + 1)
import matplotlib.pyplot as plt
plt.plot(epochs, loss_values, label='Training loss')
plt.plot(epochs, val_loss_values, label='Validation loss')
plt.title("Training and validation loss")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend()
plt.show()
運行上述代碼時發生了如下的錯誤:
OMP: Error #15: Initializing libomp.dylib, but found libiomp5.dylib already initialized.
OMP: Hint This means that multiple copies of the OpenMP runtime have been linked into the program. That is dangerous, since it can degrade performance or cause incorrect results. The best thing to do is to ensure that only a single OpenMP runtime is linked into the process, e.g. by avoiding static linking of the OpenMP runtime in any library. As an unsafe, unsupported, undocumented workaround you can set the environment variable KMP_DUPLICATE_LIB_OK=TRUE to allow the program to continue to execute, but that may cause crashes or silently produce incorrect results. For more information, please see http://openmp.llvm.org/
需要在繪制圖形前設定如下的值:
import os
os.environ['KMP_DUPLICATE_LIB_OK']='True'
這樣顯示的損失值圖形為:
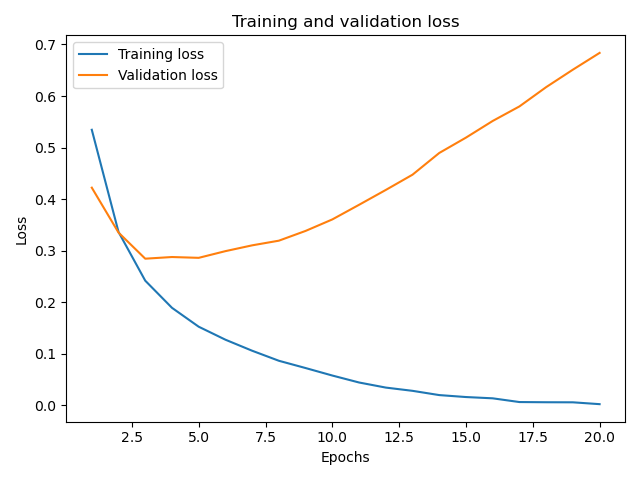
從這個圖形中我們發現隨著訓練迭代次數的增加,訓練集中的損失值在不停減小,但是對于驗證集的損失值在3-4次時反而增加了,
顯示訓練集和驗證集精度圖形
# 顯示訓練集和驗證集的精度
binary_accuracy_values = history_map['binary_accuracy']
val_binary_accuracy_values = history_map['val_binary_accuracy']
plt.clf() #清空影像
plt.plot(epochs, binary_accuracy_values, label='Training accuracy')
plt.plot(epochs, val_binary_accuracy_values, label='Validation accuracy')
plt.title("Training and validation accuracy")
plt.xlabel("Epochs")
plt.ylabel("Accuracy")
plt.legend()
plt.show()
圖形顯示為:
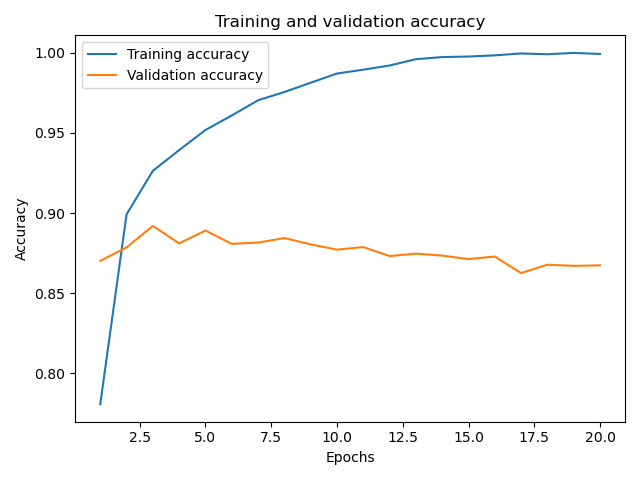
可以看到隨著迭代次數的增加,訓練集的精度一直在提高,但是驗證集的精度在迭代3-4次之后并沒有一個顯著的提高,
這里就可能存在一個過擬合的現象,也就是在訓練集中模型有很好的表現,但在驗證集和測驗集中模型的結果并沒有很好的表現,
在這種情況下,為了防止過擬合,我們可以在 4 輪之后停止訓練,通常來說,我們可以使用許多方法來降低過擬合,我們將在后面的博文中再來介紹,
目前完整的代碼為:
import tensorflow.keras as keras
(x_train, y_train), (x_test, y_test) = keras.datasets.imdb.load_data(num_words=10000)
# print("x_train:", x_train, "y_train:", y_train)
# data = https://www.cnblogs.com/dreampursuer/archive/2020/09/24/keras.datasets.imdb.get_word_index()
# word_map = dict([(value, key) for (key,value) in data.items()])
# words = []
# for word_index in x_train[0]:
# words.append(word_map[word_index])
# print(" ".join(words))
import numpy as np
def vectorize_sequence(data, words_size = 10000):
words_vector = np.zeros((len(data), words_size))
for row, word_index in enumerate(data):
words_vector[row, word_index] = 1.0
return words_vector
x_train = vectorize_sequence(x_train)
x_test = vectorize_sequence(x_test)
#構建模型
model = keras.models.Sequential()
model.add(keras.layers.Dense(16, activation=keras.activations.relu, input_shape=(10000, )))
model.add(keras.layers.Dense(16, activation=keras.activations.relu))
model.add(keras.layers.Dense(1, activation=keras.activations.sigmoid))
# 分解驗證集
x_val = x_train[:10000]
y_val = y_train[:10000]
x_train = x_train[10000:]
y_train = y_train[10000:]
#編譯模型
model.compile(optimizer=keras.optimizers.RMSprop(), loss=keras.losses.binary_crossentropy, metrics=[keras.metrics.binary_accuracy])
#訓練模型
history = model.fit(x_train, y_train, epochs=20, batch_size=512, validation_data=https://www.cnblogs.com/dreampursuer/archive/2020/09/24/(x_val, y_val))
history_map = history.history
print("history_map:", history_map)
# 繪制訓練集和驗證集的損失值
loss_values = history_map['loss']
val_loss_values = history_map['val_loss']
epochs = range(1, len(loss_values) + 1)
import os
os.environ['KMP_DUPLICATE_LIB_OK']='True'
import matplotlib.pyplot as plt
plt.plot(epochs, loss_values, label='Training loss')
plt.plot(epochs, val_loss_values, label='Validation loss')
plt.title("Training and validation loss")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend()
plt.show()
# 顯示訓練集和驗證集的精度
binary_accuracy_values = history_map['binary_accuracy']
val_binary_accuracy_values = history_map['val_binary_accuracy']
plt.clf() #清空影像
plt.plot(epochs, binary_accuracy_values, label='Training accuracy')
plt.plot(epochs, val_binary_accuracy_values, label='Validation accuracy')
plt.title("Training and validation accuracy")
plt.xlabel("Epochs")
plt.ylabel("Accuracy")
plt.legend()
plt.show()
# 測驗
results = model.evaluate(x_test, y_test)
print(results)
# 預測
results = model.predict(x_test)
print(results)
為了調優模型,你可以嘗試著增加更多的隱藏層,調整隱藏層中的單元個數,調整損失函式,調整激活函式,調整這些引數之后再來看下模型的精度的變化,
更多參考系列文章:老魚學機器學習&深度學習目錄
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/118180.html
標籤:其他