一、 Set集合概述及特點
因為Set集合的API方法和Collection集合一模一樣,故沒有沒有它的特殊的方法,
所以我們只要學它的兩個子類,一個HashSet和另外一個TreeSet
二、 HashSet存盤字串并遍歷
實作Set介面,由哈希表(實際是一個hashmap物件)支持,它不保證set的迭代順序;特別是它不保證該順序恒久不變,此類允許下使用null元素,
案例:
HashSet<String> hashSet =new HashSet<String>();
boolean b1 = hashSet.add("a");
boolean b2= hashSet.add("a");
boolean b3= hashSet.add("b");
System.out.println(b1);
System.out.println(b2);
System.out.println(b3);
System.out.println(hashSet);
//HashSet的繼承體系中有重寫toString方法
for (String string : hashSet) {
System.out.println(string);
//只要使用那個迭代器迭代,那么就可以使用foreach回圈
}
效果如下:
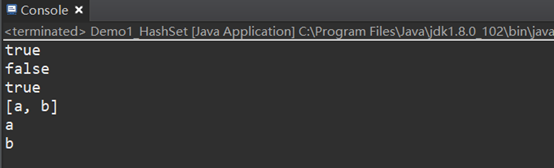
tips:Set集合無索引,不可以重復,無序(存盤不一致)它的繼承系統中有toString方法,故不需要書寫toString()方法,
三、 HashSet存盤自定義物件
存盤自定義物件,并保證元素唯一性,
例:
注意因為set集合不保證元素的有序性,所以每次存盤都是無序的
HashSet<Person> hashSet =new HashSet<Person>();
hashSet.add(new Person("張三",12));
hashSet.add(new Person("張三",12));
hashSet.add(new Person("李四",13));
hashSet.add(new Person("李四",13));
hashSet.add(new Person("李四",13));
System.out.println(hashSet);
效果如下:
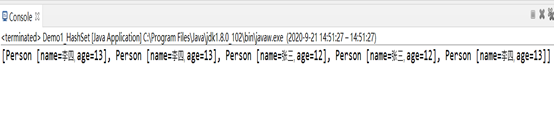
當我們重寫equals方法,使我們出現的姓名和年齡相同就表示存盤人物相同,但是在Set集合中我們并不能用equals方法進行判斷,而是先要設定hasCode的值,
@Override
public boolean equals(Object obj) {
Person person =(Person)obj;
return this.name.equals(person.name) &&this.age ==person.age;
}
@Override
public int hashCode() {
// TODO Auto-generated method stub
return 10;
}
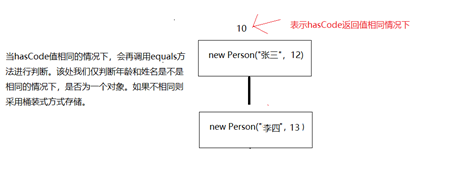
當hasCode回傳值相同時,說明我們記憶體中的存盤的某類物件會處在相同位置,然后才會呼叫equals方法,使用equas方法進行判斷如果我們的姓名和年齡相同則回傳true,不進行物件存盤,如果回傳false,則會采用筒狀式,將物件存盤起來,如圖所示:
但是為了保證程式的效率,我們盡可能的保證hasCode不相同,然后再執行equals方法,當然如果屬性值相同的化,那么它的hasCode的值必然是相同的,屬性不相同的回傳值盡可能不同,Eclipse等編譯器可以自動幫我們生成代碼塊,快捷鍵:ctrl+shifts +h 即可生成,并且我們勾選判斷的屬性,畫圖如下:
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Person other = (Person) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
注意該處為什么prime是31?
好處:31是一個質數,質數是能被1和自己本身整除的數,并且31不大也不小,
四、 HashSet如何保證元素唯一性的原理
1.HashSet原理(重點)
- 我們使用Set集合都是需要去掉重復元素的, 如果在存盤的時候逐個equals()比較, 效率較低,哈希演算法提高了去重復的效率, 降低了使用equals()方法的次數
- 當HashSet呼叫add()方法存盤物件的時候, 先呼叫物件的hashCode()方法得到一個哈希值, 然后在集合中查找是否有哈希值相同的物件
- 如果沒有哈希值相同的物件就直接存入集合
- 如果有哈希值相同的物件, 就和哈希值相同的物件逐個進行equals()比較,比較結果為false就存入, true則不存
2.將自定義類的物件存入HashSet去重復
- 類中必須重寫hashCode()和equals()方法
- hashCode(): 屬性相同的物件回傳值必須相同, 屬性不同的回傳值盡量不同(提高效率)
- equals(): 屬性相同回傳true, 屬性不同回傳false,回傳false的時候存盤,
五、 LinkedHashSet的概述和使用
LinkedHashSet概述:
- 它的底層是鏈表實作的,是set集合中唯一一個能保證怎么存就怎么取的集合,(因為它是鏈表實作,可以記錄前后繼的地址值,)
- 它是HashSet的子類,所以可以保證元素是唯一的,與HashSet原理一樣,
LinkedHashSet的特點:可以保證怎么存就怎么取,意思就是你是怎么放進去的就可以怎么取出來
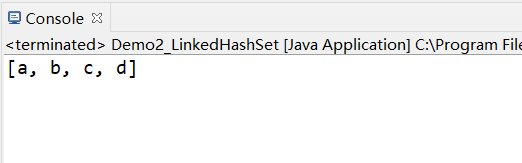
LinkedHashSet<String> linkedHashSet =new LinkedHashSet<String>();
linkedHashSet.add("a");
linkedHashSet.add("a");
linkedHashSet.add("a");
linkedHashSet.add("b");
linkedHashSet.add("b");
linkedHashSet.add("c");
linkedHashSet.add("d");
System.out.println(linkedHashSet);
效果如下:
六、 TreeSet存盤Integer型別的元素并遍歷
TreeSet是用來對元素進行排序的,并且它也是不存盤相同資料的,
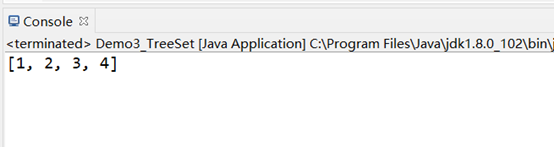
TreeSet<Integer> treeSet =new TreeSet<Integer>(); treeSet.add(1); treeSet.add(1); treeSet.add(3); treeSet.add(3); treeSet.add(2); treeSet.add(2); treeSet.add(4); System.out.println(treeSet);
效果如下:
七、 TreeSet存盤自定義物件
當我們單純的去存盤物件的時候,會進行報錯,因為物件不能用來做比較,所以我們需要給我們bean類添加介面方法,
public class Person implements Comparable<Person>{
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + "]";
}
@Override
public int compareTo(Person o) {
// TODO Auto-generated method stub
return 1;
}
}
TreeSet部分
TreeSet<Person> treeSet =new TreeSet<Person>();
treeSet.add(new Person("張三",12));
treeSet.add(new Person("李四",12));
treeSet.add(new Person("王五",13));
treeSet.add(new Person("趙六",14));
System.out.println(treeSet);
效果如下:

注意:CompareTo方法的回傳值:
如果return回傳的數是正數,集合就是怎么存怎么取,
如果return回傳的數是負數,集合就是倒序存盤,
如果return回傳的數是0,集合中就存在一元素,
八、 TreeSet保證元素唯一和自然排序的原理

當我們按照年齡進行排序
書寫Bean包中的Person物體類
@Override
public int compareTo(Person o) {
// TODO Auto-generated method stub
return this.age -o.age;
}
TreeSet<Person> treeSet =new TreeSet<Person>();
treeSet.add(new Person("張三",12));
treeSet.add(new Person("李四",22));
treeSet.add(new Person("周七",24));
treeSet.add(new Person("王五",10));
treeSet.add(new Person("趙六",24));
System.out.println(treeSet);
原理如下:

效果如下:

此時我們會發現,少一個趙六的元素,很簡單,因為我們只進行了年齡判斷,所以后面存盤的年齡相同的元素不會被存盤進來,
如果我們進行升級:按照年齡進行排序
@Override
public int compareTo(Person o) {
// TODO Auto-generated method stub
int num =this.age -o.age;
return num == 0? this.name.compareTo(o.name):num;
}
該方法會進行完整的排序,
九、TreeSet存盤自定義物件并遍歷練習1(按照姓名排序)
@Override
public int compareTo(Person o) {
int num = this.name.compareTo(o.name);
//按照姓名排序
return num== 0? this.age -o.age :num;
//年齡是次要條件
}
TreeSet<Person> treeSet =new TreeSet<Person>();
treeSet.add(new Person("李四",22));
treeSet.add(new Person("張三",12));
treeSet.add(new Person("周七",24));
treeSet.add(new Person("王五",10));
treeSet.add(new Person("趙六",24));
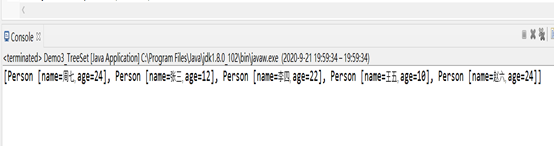
System.out.println(treeSet);
效果如下:
十、 TreeSet存盤自定義物件并遍歷練習2(按照姓名的長度排序)
@Override
public int compareTo(Person o) {
// TODO Auto-generated method stub
int length =this.name.length() - o.name.length();
//比較姓名長度
int num =length == 0 ?this.name.compareTo(o.name):length;
//完全有一種可能,名字長度一樣,內容是不一樣的
return num==0? this.age -o.age:num;
//完全有一種可能,姓名和長度均相同
}
十一、 TreeSet保證元素唯一和比較器排序的原理
TreeSet(Collection <? super E> comparator):構造一個新的空TreeSet,他根據指定比較器進行排序
需求:將字串按照長度排序
TreeSet<String> treeSet =new TreeSet<String>(new CompareByLen());
//Comparator c = new CompareByLen();
treeSet.add("aaaaaaaaaa");
treeSet.add("z");
treeSet.add("wc");
treeSet.add("nba");
treeSet.add("cba");
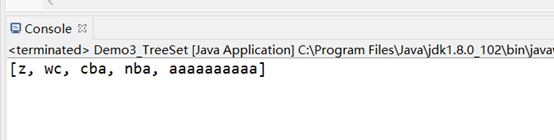
System.out.println(treeSet);
新建一個類
class CompareByLen implements Comparator<String>{
@Override
public int compare(String s1, String s2) {
//按照字串的長度比較
// TODO Auto-generated method stub
int num = s1.length() -s2.length();
//長度為主要條件
return num==0? s1.compareTo(s2): num ;
//內容為次要條件
}
}
效果如下:
原理如下:
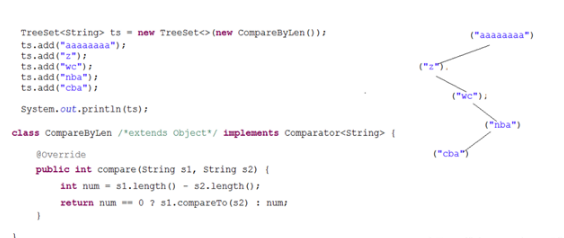
依次從左邊就先取出,如果沒有的話就取出其右邊,
十二、 TreeSet原理
1.特點
TreeSet是用來排序的, 可以指定一個順序, 物件存入之后會按照指定的順序排列
2.使用方式
a.自然順序(Comparable)
- TreeSet類的add()方法中會把存入的物件提升為Comparable型別
- 呼叫物件的compareTo()方法和集合中的物件比較
- 根據compareTo()方法回傳的結果進行存盤
b.比較器順序(Comparator)
- 創建TreeSet的時候可以制定 一個Comparator
- 如果傳入了Comparator的子類物件, 那么TreeSet就會按照比較器中的順序排序
- add()方法內部會自動呼叫Comparator介面中compare()方法排序
- 呼叫的物件是compare方法的第一個引數,集合中的物件是compare方法的第二個引數
c.兩種方式的區別
- TreeSet建構式什么都不傳, 默認按照類中Comparable的順序(沒有就報錯ClassCastException)
- TreeSet如果傳入Comparator, 就優先按照Comparator
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/119175.html
標籤:其他