python爬蟲如何學習?匯集眾多程式員學習經驗總結出的爬蟲最適合大多數人的學習路線分享!
爬蟲的一周學習計劃:
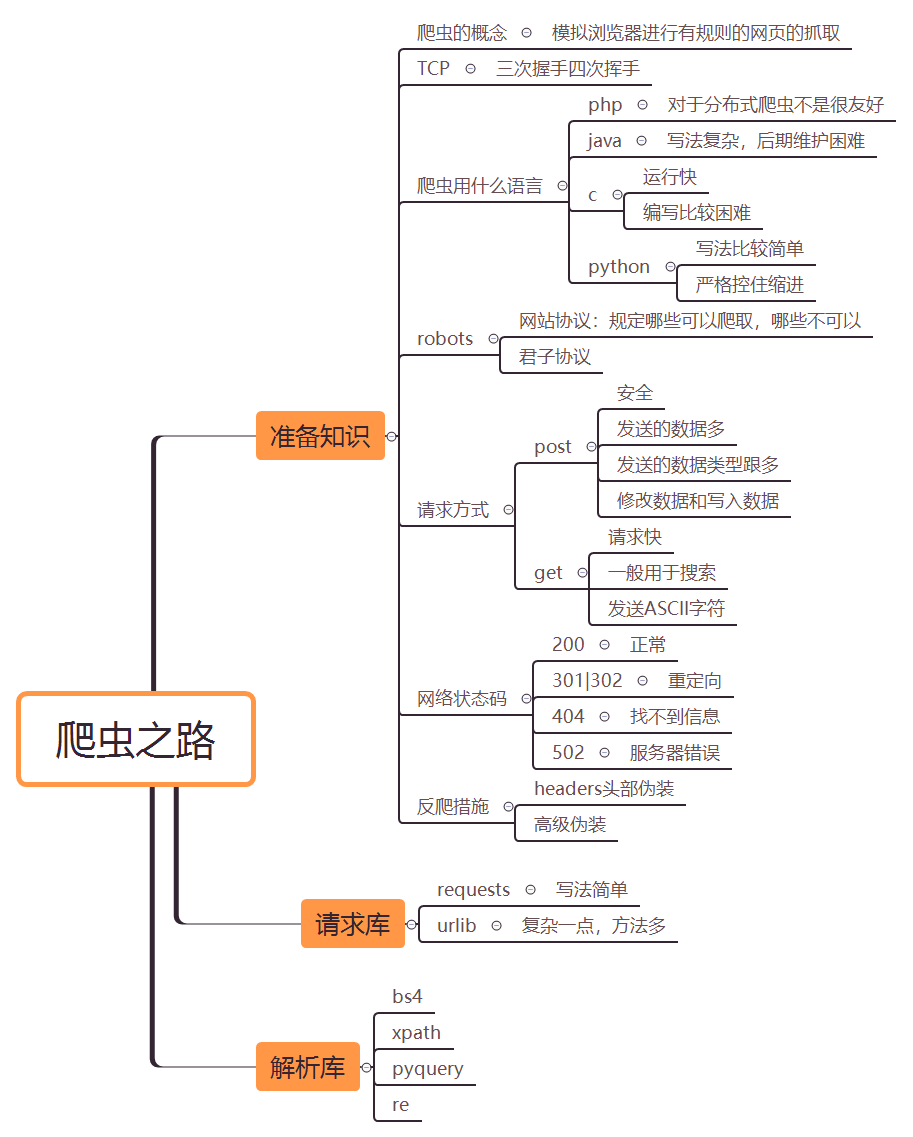
下圖是爬蟲的準備
爬蟲爬取快代理案例:
網站的url=“https://www.kuaidaili.com/free/”
這里多說一句,如果缺少爬蟲專案實戰案例教程可以加我的python資源交流裙:巴衣久二五寺久寺二(數字的諧音轉換下可以找到了),一起交流python資源,裙里還有阿里的大牛,還可以和阿里的大牛一起討論,學習.
這次爬取我們采用的是requests第三方庫
Requests 是一個 Python 的 HTTP 客戶端庫,我們可以用它得到HTML原始碼
import requests url="https://www.kuaidaili.com/free/" headers={ "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36" } #這里進行了頭部的偽裝 res=requests.get(url,headers=headers) res.encoding="utf-8" html=res.text
之后我們用xpath實作標簽的遍歷獲取到我們需要的內容
e=etree.HTML(html) ip_list=e.xpath("//tr/td[1]/text()") port_list=e.xpath("//tr/td[2]/text()") #采用zip迭代的方式列印輸出 for ip,port in zip(ip_list,port_list): str="ip:"+ip+"\t埠號:"+port print(str)
小結
本文主要講解了網路爬蟲的結構和應用,以及Python實作爬蟲的案例,希望大家對本文中的網路爬蟲作業流程和Requests實作HTTP請求的方式重點吸收消化,如果有還沒有消化的可以進我的python學.習交.流扣.扣裙:巴衣久二五寺久寺二(數字的諧音轉換下可以找到了)一起交流討論,裙里還有2020最新python入門到高級專案實戰視頻教程和學習資料,進群就可以免費下載.
本文的文字及圖片來源于網路加上自己的想法,僅供學習、交流使用,不具有任何商業用途,著作權歸原作者所有,如有問題請及時聯系我們以作處理,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/119184.html
標籤:其他